最近特别火的AI+Search项目,学习并记录下来
开源地址:https://github.com/leptonai/search_with_lepton
项目体验
先进行lepton认证,在https://www.lepton.ai/网站注册账号,下面login时会跳转到该网站给一个认证的Credential字符串,复制过来就可以登录成功(这个字符串似乎生成一次就可以一定时间内多次用
git clone https://github.com/leptonai/search_with_lepton
cd search_with_lepton
pip3 install -U leptonai && lep login
接下来就是获取搜索引擎的密钥,有以下四个方式,看了一下具体情况:
- google0:https://www.searchapi.io/ 免费100条,之后每1000条从4~2 不等,但不同价格也需要交付月费 40 500 不等,但不同价格也需要交付月费40~500 不等,但不同价格也需要交付月费40 500
- google1:https://www.serper.dev/ 免费2500条,之后每1000条从1~0.3 不等,但不同价格也需要交付月费 50 3750 不等,但不同价格也需要交付月费50~3750 不等,但不同价格也需要交付月费50 3750
- google2:https://programmablesearchengine.google.com/ 在自己网站里插入一个是免费的,API收费,
- bing:https://portal.azure.com/ 每个月免费1000条,付费每1000条从15~200$不等,不同价格服务速度和质量有区别
出于简单的目的,我选择使用bing,先开通一个计划(免费,学生,付费)。获取Bing Key流程:在控制台搜索Bing Search V7==>填表开启一个云服务==>转到资源==>密钥和终结点复制密钥
接下来是运行代码。导出密钥,编译前端(node版本至少要大于等于18.17.0),启动后端(对于python3.8 可能需要将search_with_lepton.py第9行替换成from pydantic.typing import)
export BING_SEARCH_V7_SUBSCRIPTION_KEY=xxxxxx
cd web && npm install && npm run build
BACKEND=BING python3 search_with_lepton.py
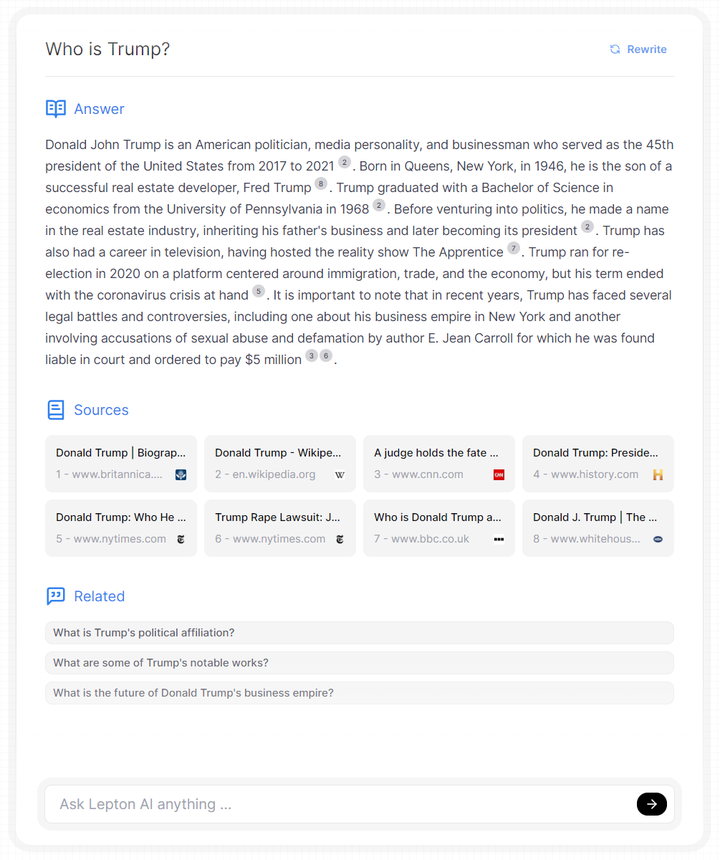
用自己的服务器部署使用了一下,初始界面输入问题得到的页面会有bug,只会显示出Sources,不会显示Answer和Related,后端看有奇怪的报错。不过再次提问就没有问题了,下面展示几个运行结果,先来个英文问题,谁是特朗普,这个问题没有特别强的时效,答得比较详实
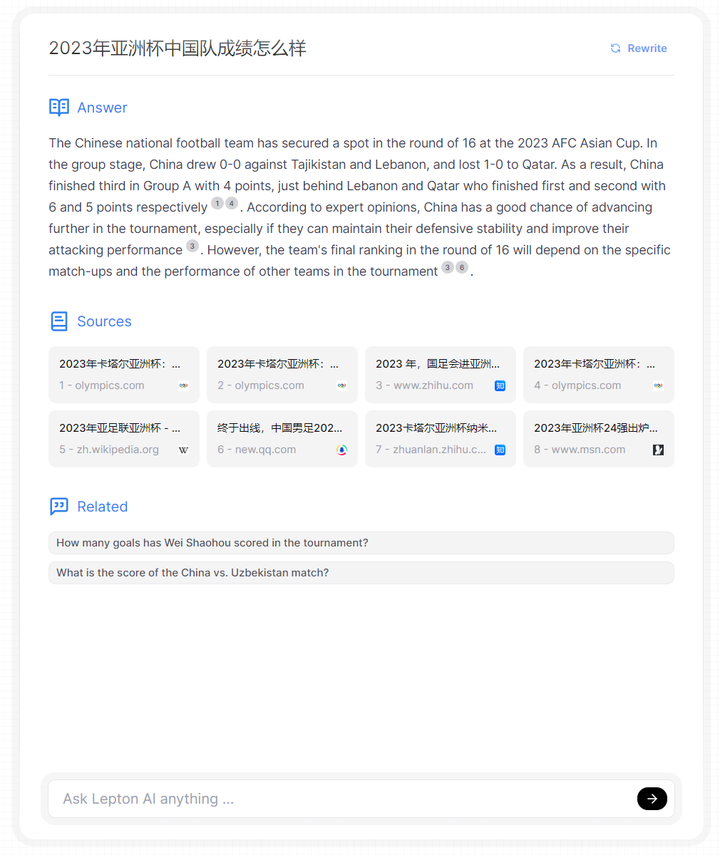
再跟进时事,问一下中国队亚洲杯战绩,准确答对了小组赛的比分,但是被一篇2023U23亚洲杯混淆了(也和我没有指出是卡塔尔亚洲杯有关),说中国队晋级了16强。总的来说时效性还是有的,只是提示词需要更精确一些。
总的来说,响应速度比较快,回答内容也都能跟进最新时事,还有引用,效果真的比较惊艳。
源码解析
1-22行导入必要的包
import concurrent.futures #进程池,线程池,异步操作
import glob #模式字符文件匹配
import json
import os
import re
import threading
import requests
import traceback
from typing import Annotated, List, Generator, Optional #开发过程规定每个数据的类型
from fastapi import HTTPException
from fastapi.responses import HTMLResponse, StreamingResponse, RedirectResponse
import httpx #类似requests的网络请求库,提供同步和异步 API
from loguru import logger #logging的替换品,不需要创建logger对象,开箱即用
import leptonai
from leptonai import Client
from leptonai.kv import KV
from leptonai.photon import Photon, StaticFiles
from leptonai.photon.types import to_bool
from leptonai.api.workspace import WorkspaceInfoLocalRecord
from leptonai.util import tool
24-94行定义一些常量,这里删去了一些注释
#定义搜索的根网址
BING_SEARCH_V7_ENDPOINT = "https://api.bing.microsoft.com/v7.0/search"
BING_MKT = "en-US"
GOOGLE_SEARCH_ENDPOINT = "https://customsearch.googleapis.com/customsearch/v1"
SERPER_SEARCH_ENDPOINT = "https://google.serper.dev/search"
SEARCHAPI_SEARCH_ENDPOINT = "https://www.searchapi.io/api/v1/search"
#定义引用的文章数量,8比较合适
REFERENCE_COUNT = 8
#搜索超时时间5秒
DEFAULT_SEARCH_ENGINE_TIMEOUT = 5
#直接按enter时用的查询
_default_query = "Who said 'live long and prosper'?"
#用户RAG查询的提示词
#第一句话让LLM认清自己的身份以及引用回复的任务要求
#第二句话让LLM回复需要符合准确/长度限制/不重复/不要不懂装懂
#第三句话让LLM引用参考文献
#最后是放置搜索到的文档内容以及用户问题
_rag_query_text = """
You are a large language AI assistant built by Lepton AI. You are given a user question, and please write clean, concise and accurate answer to the question. You will be given a set of related contexts to the question, each starting with a reference number like [[citation:x]], where x is a number. Please use the context and cite the context at the end of each sentence if applicable.
Your answer must be correct, accurate and written by an expert using an unbiased and professional tone. Please limit to 1024 tokens. Do not give any information that is not related to the question, and do not repeat. Say "information is missing on" followed by the related topic, if the given context do not provide sufficient information.
Please cite the contexts with the reference numbers, in the format [citation:x]. If a sentence comes from multiple contexts, please list all applicable citations, like [citation:3][citation:5]. Other than code and specific names and citations, your answer must be written in the same language as the question.
Here are the set of contexts:
{context}
Remember, don't blindly repeat the contexts verbatim. And here is the user question:
"""
#终止词,当遇到以下内容时停止生成
stop_words = [
"<|im_end|>",
"[End]",
"[end]",
"\nReferences:\n",
"\nSources:\n",
"End.",
]
#更多相关问题生成的提示词
#采用回复用户问题与相关问题分开生成的策略,先后发送两个请求给语言模型得到对用户问题的回复和相关的问题
_more_questions_prompt = """
You are a helpful assistant that helps the user to ask related questions, based on user's original question and the related contexts. Please identify worthwhile topics that can be follow-ups, and write questions no longer than 20 words each. Please make sure that specifics, like events, names, locations, are included in follow up questions so they can be asked standalone. For example, if the original question asks about "the Manhattan project", in the follow up question, do not just say "the project", but use the full name "the Manhattan project". Your related questions must be in the same language as the original question.
Here are the contexts of the question:
{context}
Remember, based on the original question and related contexts, suggest three such further questions. Do NOT repeat the original question. Each related question should be no longer than 20 words. Here is the original question:
"""
97-289行实现了各种搜索接口的API调用,最终返回的是一个下面的json列表
[
{
"name": "网页标题",
"url": "网页链接",
"snippet": "网页内容"
},...
]
291-639行定义了一个RAG类,展示了如何使用Lepton AI来实现一个AI搜索引擎,即先搜索文档,再让LLM结合文档给出回复,最后还会使用LeptonAI的KV将用户一次查询中产生的各种数据(查询,回复,文档,相关问题)存储下来。
这里主要展示Bing搜索的例子,删去了一些其他引擎的代码
class RAG(Photon):
# 继承自Photon对象
# Photon对象是leptonai包中定义的一个包含各种网络相关处理的基类
# 可以认为是将fastapi以及其他功能又封装了一层,更加简单实用
requirement_dependency = [
"openai", # for openai client usage.
]
extra_files = glob.glob("ui/**/*", recursive=True)
deployment_template = {
# 大部分工作都由远程API完成,因此只需要一个普通CPU即可完成处理
"resource_shape": "cpu.small",
# 环境配置,一般不需要修改。BACKEND使用LEPTON时会直接调用https://search-api.lepton.run/页面的
"env": {
"BACKEND": "BING",
"GOOGLE_SEARCH_CX": "", #使用Google时需要设置
"LLM_MODEL": "mixtral-8x7b", #指定使用的LLM
"KV_NAME": "search-with-lepton",
"RELATED_QUESTIONS": "true", #是否生成相关问题
"LEPTON_ENABLE_AUTH_BY_COOKIE": "true", #在lapton平台上,允许登录后访问互联网
},
"secret":
"BING_SEARCH_V7_SUBSCRIPTION_KEY",
"GOOGLE_SEARCH_API_KEY",
"SERPER_SEARCH_API_KEY",
"SEARCHAPI_API_KEY",
"LEPTON_WORKSPACE_TOKEN", #lepton工作空间的token,用于访问LLM
],
}
# 指定API访问并行数量
handler_max_concurrency = 16
def local_client(self):
"""
为每个线程绑定自己的openai客户端,防止某些线程异常时互相影响
"""
import openai
thread_local = threading.local()
try:
return thread_local.client
except AttributeError:
thread_local.client = openai.OpenAI(
base_url=f"https://{
self.model}.lepton.run/api/v1/",
api_key=os.environ.get("LEPTON_WORKSPACE_TOKEN")
or WorkspaceInfoLocalRecord.get_current_workspace_token(),
# 连接最高时长10s,读写设置120秒,防止服务器过载
timeout=httpx.Timeout(connect=10, read=120, write=120, pool=10),
)
return thread_local.client
def init(self):
"""
初始化配置
"""
# 登录工作空间
leptonai.api.workspace.login()
self.backend = os.environ["BACKEND"].upper()
if self.backend == "BING":
self.search_api_key = os.environ["BING_SEARCH_V7_SUBSCRIPTION_KEY"]
self.search_function = lambda query: search_with_bing(
query,
self.search_api_key,
)
self.model = os.environ["LLM_MODEL"]
# 用于执行异步任务的执行器,比如更新KV
self.executor = concurrent.futures.ThreadPoolExecutor(
max_workers=self.handler_max_concurrency * 2
)
# 创建KV来存储搜索结果
logger.info("Creating KV. May take a while for the first time.")
self.kv = KV(
os.environ["KV_NAME"], create_if_not_exists=True, error_if_exists=False
)
# 是否需要生成相关问题
self.should_do_related_questions = to_bool(os.environ["RELATED_QUESTIONS"])
def get_related_questions(self, query, contexts):
"""
根据上下文和问题让LLM回复相关问题
"""
# 定义一个后处理函数,将回复的内容转换为字符串列表
def ask_related_questions(
questions: Annotated[
List[str],
[(
"question",
Annotated[
str, "related question to the original question and context."
],
)],
]
):
pass
try:
response = self.local_client().chat.completions.create(
model=self.model,
messages=[
{
"role": "system",
"content": _more_questions_prompt.format(
context="\n\n".join([c["snippet"] for c in contexts])
),
},
{
"role": "user",
"content": query,
},
],
tools=[{
"type": "function",
"function": tool.get_tools_spec(ask_related_questions),
}],
max_tokens=512,
)
related = response.choices[0].message.tool_calls[0].function.arguments #获取函数的参数,也就是相关问题列表
# 我猜测这里的模型使用类似指令微调过,因为LLM直接返回了类似下面的格式化的字符串
# '{"questions": [{"question": "xxx"}, {"question": "xxx"}, {"question": "xxx"}]}'
if isinstance(related, str):
related = json.loads(related)
logger.trace(f"Related questions: {
related}")
return related["questions"][:5]
except Exception as e:
# 有错误时返回空列表
logger.error(
"encountered error while generating related questions:"
f" {
e}\n{
traceback.format_exc()}"
)
return []
def _raw_stream_response(
self, contexts, llm_response, related_questions_future
) -> Generator[str, None, None]:
"""
最原始的LLM调用接口,不需要直接调用,这部分主要为核心函数stream_and_upload_to_kv提供字符串迭代生成
从而让前端可以逐步流式显示内容
"""
# 迭代产生上下文
yield json.dumps(contexts)
yield "\n\n__LLM_RESPONSE__\n\n"
# 迭代产生LLM的问题回复
if not contexts:
yield (
"(The search engine returned nothing for this query. Please take the"
" answer with a grain of salt.)\n\n"
)
for chunk in llm_response:
if chunk.choices:
yield chunk.choices[0].delta.content or ""
# 迭代产生LLM生成的相关问题
if related_questions_future is not None:
related_questions = related_questions_future.result()
try:
result = json.dumps(related_questions)
except Exception as e:
logger.error(f"encountered error: {
e}\n{
traceback.format_exc()}")
result = "[]"
yield "\n\n__RELATED_QUESTIONS__\n\n"
yield result
def stream_and_upload_to_kv(
self, contexts, llm_response, related_questions_future, search_uuid
) -> Generator[str, None, None]:
"""
产生流式响应并更新KV
"""
all_yielded_results = []
for result in self._raw_stream_response(
contexts, llm_response, related_questions_future
):
all_yielded_results.append(result)
yield result
# 更新KV 如果失败就忽略
_ = self.executor.submit(self.kv.put, search_uuid, "".join(all_yielded_results))
# 查询API接口
@Photon.handler(method="POST", path="/query")
def query_function(
self,
query: str,
search_uuid: str,
generate_related_questions: Optional[bool] = True,
) -> StreamingRespons
if search_uuid:
try:
# 有这个uuid则检索KV中的缓存结果直接得到流式回复
# 否则直接开始下面的生成环节
# 根据结果来看只要每次点击rewrite或重新输入问题就会刷新uuid,可以根据需求自行配置
result = self.kv.get(search_uuid)
def str_to_generator(result: str) -> Generator[str, None, None]:
yield result
return StreamingResponse(str_to_generator(result))
except KeyError:
logger.info(f"Key {
search_uuid} not found, will generate again.")
except Exception as e:
logger.erro
f"KV error: {
e}\n{
traceback.format_exc()}, will generate again."
)
else:
raise HTTPException(status_code=400, detail="search_uuid must be provided.")
# 得到查询内容
query = query or _default_query
# 简单的保护措施,将[INST]和[/INST]token去掉
query = re.sub(r"\[/?INST\]", "", query)
# 调用搜索函数得到上下文
contexts = self.search_function(query)
system_prompt = _rag_query_text.format(
context="\n\n".join(
[f"[[citation:{
i+1}]] {
c['snippet']}" for i, c in enumerate(contexts)]
)
)
# 异步调用LLM,拿到两个响应对象llm_response 和 related_questions_future
try:
client = self.local_client()
llm_response = client.chat.completions.create(
model=self.model,
messages=[
{
"role": "system", "content": system_prompt},
{
"role": "user", "content": query},
],
max_tokens=1024,
stop=stop_words,
stream=True,
temperature=0.9,
)
if self.should_do_related_questions and generate_related_questions:
related_questions_future = self.executor.submit(
self.get_related_questions, query, contexts
)
else:
related_questions_future = None
except Exception as e:
logger.error(f"encountered error: {
e}\n{
traceback.format_exc()}")
return HTMLResponse("Internal server error.", 503)
return StreamingResponse(
self.stream_and_upload_to_kv(
contexts, llm_response, related_questions_future, search_uuid
),
media_type="text/html",
)
@Photon.handler(mount=True)
def ui(self): # 绑定UI的路径,按要求编译好web后就会出现ui路径
return StaticFiles(directory="ui")
@Photon.handler(method="GET", path="/")
def index(self) -> RedirectResponse: #访问网址时会重定向到ui下的index.html
"""
Redirects "/" to the ui page.
"""
return RedirectResponse(url="/ui/index.html")
最后就是主函数了,创建rag对象并运行
if __name__ == "__main__":
rag = RAG()
rag.launch()
思考
-
扩展性:如果想打造一个“独特”的AI搜索引擎,思路并不复杂,只需要将以上代码的聊天/搜索接口微调即可。比如将搜索部分换成自己的搜索接口,聊天可以使用国内的ChatGLM/Baichuan/Qwen等厂商或者自己的本地大语言模型接口。这里推荐两个自己有参与的项目,领头人是hiyouga,imitater用于部署自己的本地语言模型,cardinal用于部署RAG应用,后续都会持续更新。可以参考hiyouga:使用本地模型替代 OpenAI:多模型并发推理框架学习
-
个人启发:在大模型时代,对于研究层面,找到一个还没有被充分研究的“冷门”或“全新”的问题可能更重要一些。对于应用层面,基础设施建设可能比软件层面调API做提示工程护城河更高,垂直领域可能比通用领域更难超越,数据的积累和模型的训练测试部署工程可能比模型设计更加重要。
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞或收藏支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索的知识,记得关注我!