该项目是一个使用 Flask 构建的 Web 应用程序,旨在执行 Web 爬取、存储提取的数据以及使用矢量数据库启用搜索功能。它集成了各种外部服务和库,包括用于矢量搜索的 Pinecone、用于嵌入的 OpenAI 和用于 Web 抓取的 BeautifulSoup。
建筑学
环境设置
- 环境变量:应用程序使用 dotenv 加载环境变量,以安全地管理 API 密钥等敏感信息。
Flask 应用 www.cqzlsb.com
-
蓝图和路由: Flask 应用程序使用蓝图进行模块化。它注册了两组主要路由(主要路由和通用路由),以处理应用程序的不同部分。
-
端点:
-
/crawl:启动抓取过程。
-
/status:检查爬取任务的状态。
-
/search:使用给定的查询搜索矢量数据库。
-
详细分区细分
初始化和配置
-
Flask 应用程序初始化: Flask 应用程序已实例化,并使用环境变量中的必要 API 密钥进行配置。
-
全局资源初始化:在应用程序上下文中,初始化 Pinecone,并加载嵌入模型以供在整个应用程序中使用。
航线
-
/爬行路线:
-
目的:启动对给定 URL 的抓取过程直到指定深度。
-
过程:
-
接受带有 start_url 和可选深度的 JSON 有效负载。
-
调用start_crawl开始抓取过程并返回响应和状态代码。
-
当用户打开扩展程序时,它会从前端调用抓取api,以便用户一打开扩展程序就可以开始!
-
-
-
-
/status 路线:
-
目的:检索正在进行或已完成的抓取任务的状态。
-
过程:
-
接受 task_id 作为查询参数。
-
调用 get_crawl_status 获取当前状态并将其作为 JSON 响应返回。
-
-
-
/搜索路线:
-
目的:使用提供的查询搜索矢量数据库。
-
过程:
-
接受带有查询的 JSON 负载。
-
验证查询并调用search_with_query执行搜索。
-
以 JSON 响应形式返回搜索结果。
-
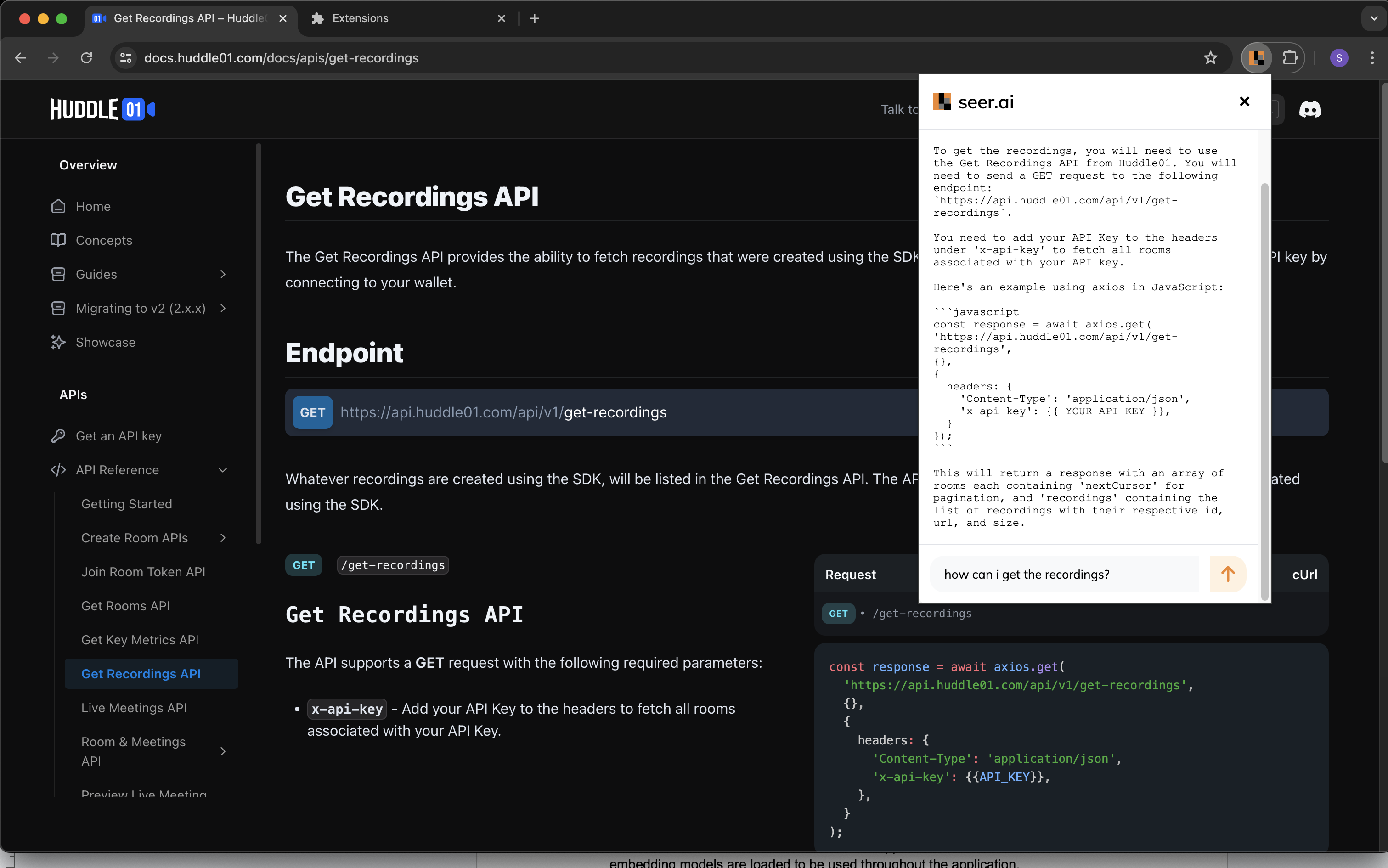
-
-
爬虫逻辑
-
任务管理:在内存字典中管理任务,跟踪每个任务的状态和访问的 URL。
-
抓取过程:
-
基于队列的爬取:使用队列管理要爬取的URL,并通过深度控制来限制爬取的范围。
-
内容提取:使用 BeautifulSoup 从网页中提取文本内容并将其拆分为可管理的块。
-
向量存储:将提取的文本块作为向量存储在 Pinecone 索引中。
-
Pinecone 集成
-
嵌入生成:使用 OpenAI 的 API 为文本内容生成嵌入。
-
索引管理:将向量存储在 Pinecone 中并执行搜索查询。
-
辅助功能:
-
get_embedding:使用 OpenAI 生成嵌入。
-
store_vectors:将文档向量存储在 Pinecone 中。
-
search_with_query:使用查询嵌入搜索 Pinecone 索引。
-
实用函数
-
文本分块:将大文本内容分割成较小的块,以适应标记限制。
-
域名检查:确保被抓取的URL在同一个域内,以避免不必要的外部链接。
-
错误处理和重试:实现失败的 HTTP 请求的重试逻辑和爬取过程中的错误处理。
工作流
-
开始抓取:
-
用户通过 /crawl 端点使用起始 URL 和可选深度启动爬网。
-
应用程序分配唯一的任务ID,并在后台启动抓取过程。
-
该过程提取文本、生成嵌入并将其存储在 Pinecone 中。
-
-
检查状态:
-
用户使用带有任务 ID 的 /status 端点查询爬网的状态。
-
应用程序返回任务的当前状态和访问过的 URL。
-
-
搜索数据:
-
用户通过 /search 端点提交搜索查询。
-
该应用程序为查询生成嵌入,并在 Pinecone 索引中搜索最相关的结果。
-
结果以 JSON 响应形式返回。
-
RAG:根据相似度使用前 3 个块,使用 RAG 实现来回答查询
-
演示:
我们还制作了一个工作演示视频,您可以在下面观看!
结论
该架构为网络爬虫和语义搜索提供了强大的解决方案。它利用 Pinecone 等强大工具进行高效矢量搜索,利用 OpenAI 生成高质量嵌入,而 Flask 则充当网络应用程序的主干,协调不同组件并处理用户交互。