II 基本概念和算法
一、基本概念与三要素
1.1 什么是数据?
数据:数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。数据是计算机程序加工的原料。
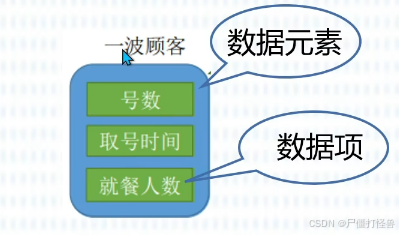
1.2 数据元素、数据项
数据元素、数据项:数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。一个数据元素可由若干数据项组成,数据项是构成数据元素的不可分割的最小单位。
1.3 三要素
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。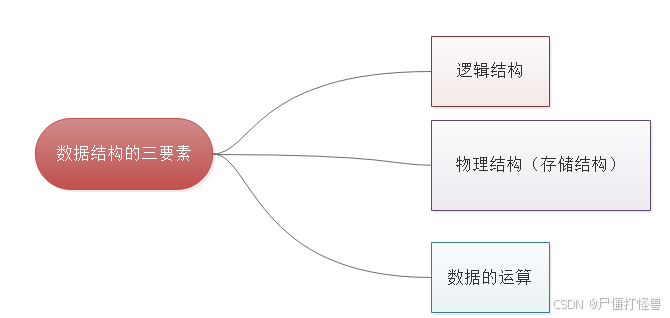
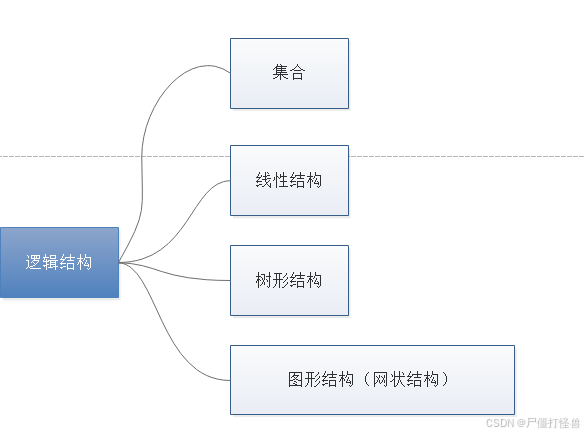
逻辑结构
-
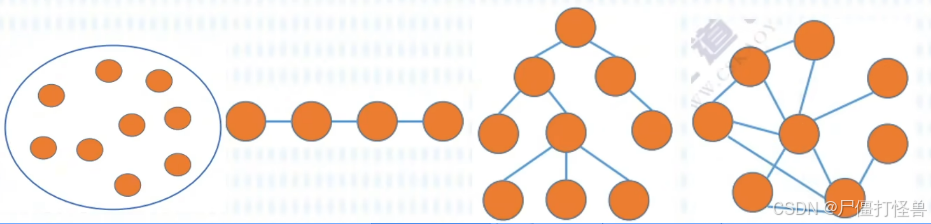
集合:各个元素同属一个集合,别无其他关系。
-
线性结构:数据元素之间是一对一的关系。除了第一个元素,所有元素都有唯一前驱;除了最后一个元素,所有元素都有唯一后继。
-
树形结构:数据元素之间是一对多的关系。
-
图结构:数据元素之间是多对多的关系。
 物理结构(存储结构)
物理结构(存储结构)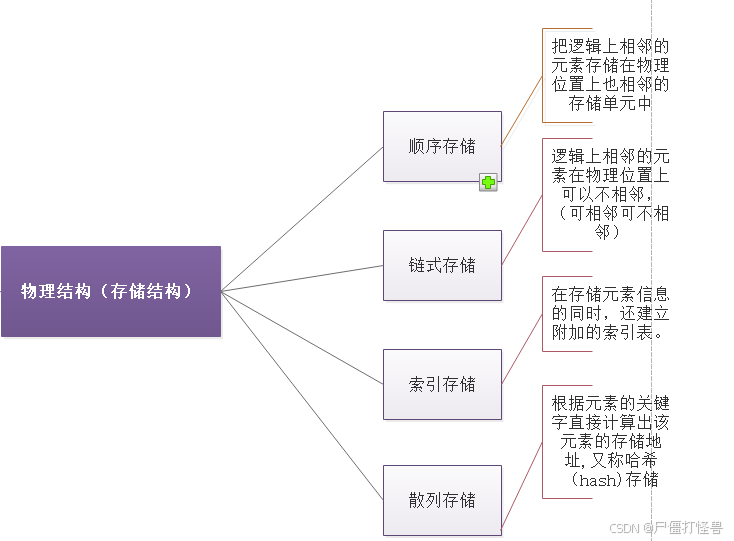
二、算法
2.1 什么是算法


海底捞排队系统的数据结构—队列
已实现的基本操作:
- 队头元素出队;
- 新元素入队;
- 输出队列长度;
- 交换第i号和第j号的位置。
要解决的现实问题—-带小孩的顾客优先就餐(涉及一个算法:
- 执行基本操作2(新顾客取号)
- 依次对比前一桌的信息,如果前一桌没有小孩,则使用基本操作4交换位置。
2.2 五个特性
- 有穷性:一个算法必须总在执行有穷步之后结束,且每一步都可在有穷时间内完成。
- 确定性:算法中每条指令必须有确切的含义,对于相同的输入只能得出相同的输出。
- 可行性:算法中描述的操作都可以通过已实现的基本运算执行有限次来实现。
- 输入:一个算法有0个或多个输入,这些输入取自某个特定的对象的集合。
- 输出:一个算法有一个或多个输出,这些输出是与输入有着某种特定关系的量。
2.3 算法效率的度量

算法表白—“爱你n编”
//算法1 逐步递增性爱你
void loveYou(int n){
//n 为问题规模
(1) int i = 1;
(2) while(i<=n){
(3) i++;
(4) printf("I love you %d\n",i);
}
(5) printf("I love You More Than %d \n",n);
}
int main(){
loveYou(3000);
}
语句频度
(1) 1次
(2) 3001次
(3)(4) 3000次
(5)1次
T(3000)=1+3001+2*3000+1
时间开销与问题规模n的关系:
T 1 ( n ) = 3 n + 3 T_1(n)=3n+3 T1(n)=3n+3
T 2 ( n ) = n 2 + 3 n + 1000 T_2(n)=n^2+3n+1000 T2(n)=n2+3n+1000
T 3 ( n ) = n 3 + n 2 + 9999999 T_3(n)=n^3 +n^2 +9999999 T3(n)=n3+n2+9999999
简化:
T 1 ( n ) = O ( n ) T 2 ( n ) = O ( n 2 ) T 3 ( n ) = O ( n 3 ) T_1(n)=O(n)\\ T_2(n)=O(n^2)\\ T_3(n)=O(n^3) T1(n)=O(n)T2(n)=O(n2)T3(n)=O(n3)
2.4 空间复杂度
无论问题规模怎么变,算法运行所需的内存空间,都是固定的常量,算法空间复杂度为 S ( n ) = O ( 1 ) 注: S 表示“ S p a c e " S(n)=O(1)_{注:S表示“Space"} S(n)=O(1)注:S表示“Space"
算法原地工作–算法所需内存空间位常量
只需关注空间大小与问题规模相关的变量
函数递归调用带来的内存开销:
S(n)=O(n)
空间复杂度= 递归调用的深度
O ( 1 ) < O ( l o g 2 n ) < O ( n ) < O ( n 2 ) < O ( n 3 ) < O ( 2 n ) < O ( n ! ) < O ( n n ) O(1)<O(log_2n)<O(n)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n) O(1)<O(log2n)<O(n)<O(n2)<O(n3)<O(2n)<O(n!)<O(nn)
三、线性表
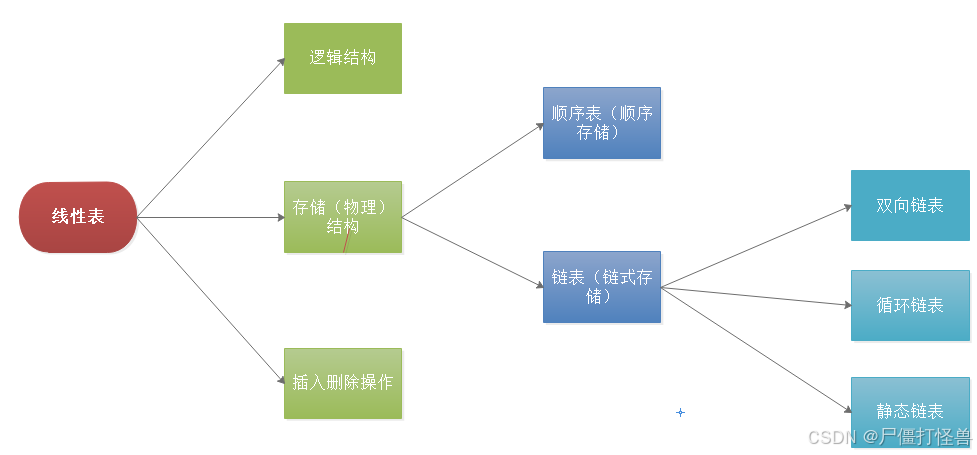
3.1 定义
线性表是具有相同数据类型的n(n>0)个数据元素的有限序列,其中n为表长,当 n=0时,线性表是一个空表。若用L命名线性表,则其一般表示为:
L = ( a 1 , a 2 , . . . , a i , a i + 1 , . . . , a n ) L=(a_1,a_2,...,a_i,a_i+1,...,a_n) L=(a1,a2,...,ai,ai+1,...,an)
几个概念:
- a i a_i ai是线性表中“第i个”元素线性表中的位序
- a 1 a_1 a1是表头元素, a n a_n an是表尾元素。
- 除第一个元素外,每个元素有且仅有一个直接前驱,除最后一个元素外,每个元素有且仅有一个直接后继。

3.2 存储结构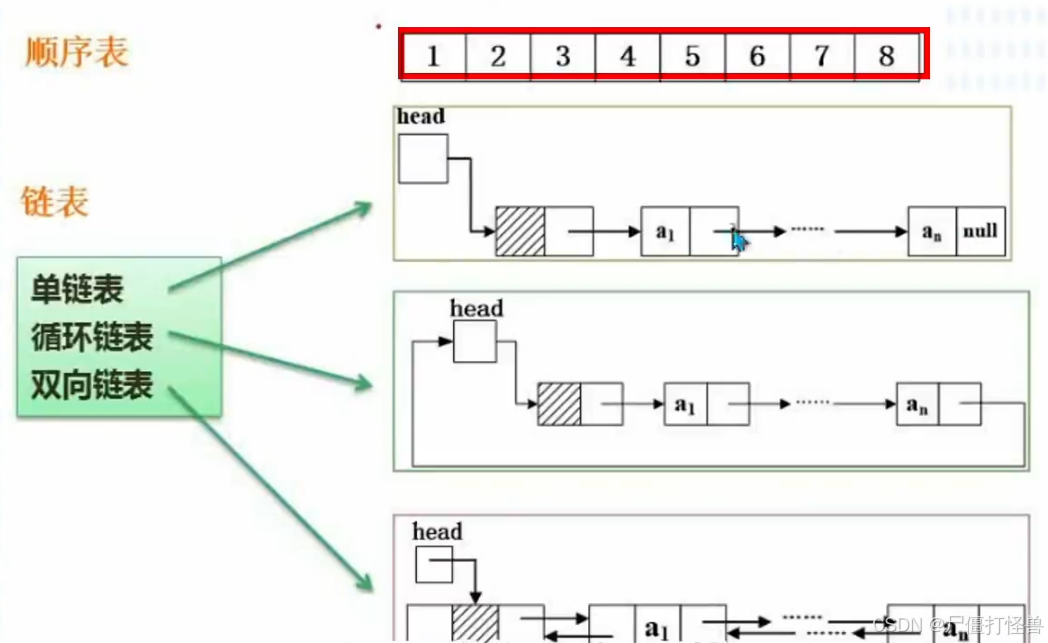
| 性能类别 | 具体项目 | 顺序存储 | 链式存储 |
|---|---|---|---|
| 空间性能 | 存储密度 | =1,更优 | <1 |
| 容量分配 | 事先确定 | 动态改变,更优 | |
| 时间性能 | 查找运算 | O ( n 2 ) O(\frac{n}{2}) O(2n) | O ( n 2 ) O(\frac{n}{2}) O(2n) |
| 读运算 | O(1)更优 | O( n + 1 2 \frac{n+1}{2} 2n+1)最好情况为1,最坏情况为n | |
| 插入运算 | O( n 2 \frac{n}{2} 2n)最好情况为0,最坏情况为n | O(1)更优 | |
| 删除运算 | O( n − 1 2 \frac{n-1}{2} 2n−1) | O(1)更优 |
3.3 插入删除操作
- 顺序存储:插入元素前要移动元素以挪出空的存储单元,然后再插入元素。删除元素时同样需要移动元素。以填充被删除元素的存储单元。
- 链式存储:
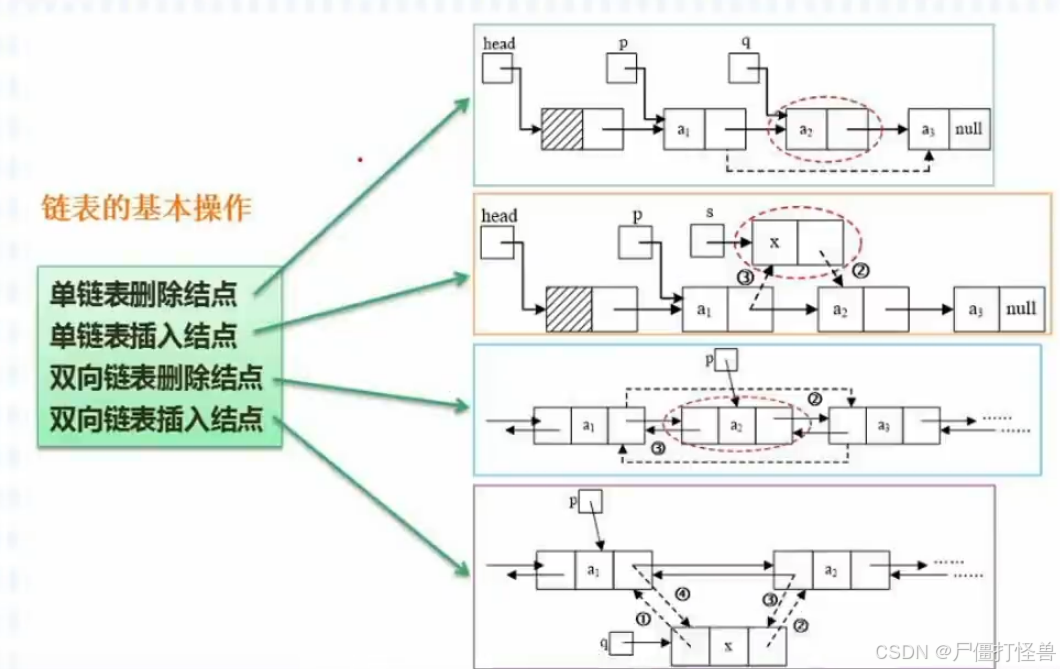
四、栈和队列
线性表是具有相同数据类型的n(n>0)个数据元素的有限序列,其中n为表长,当 n=0时,线性表是一个空表。若用L命名线性表,则其一般表示为:
L = ( a 1 , a 2 , . . . , a i , a i + 1 , . . . , a n ) L=(a_1,a_2,...,a_i,a_i+1,...,a_n) L=(a1,a2,...,ai,ai+1,...,an)
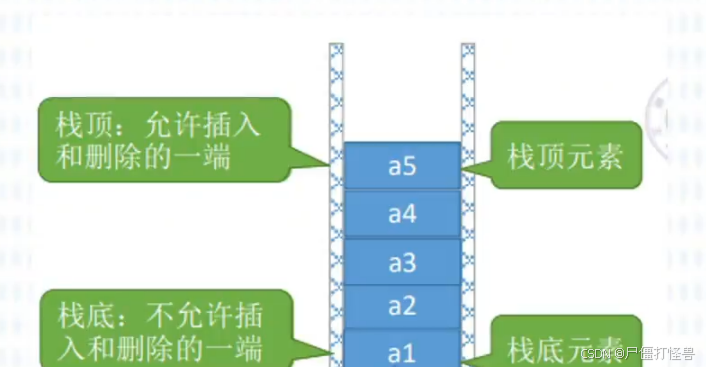
- 栈(Stack)是只允许在一端进行掺入或删除操作的线性表。
- 循环队列
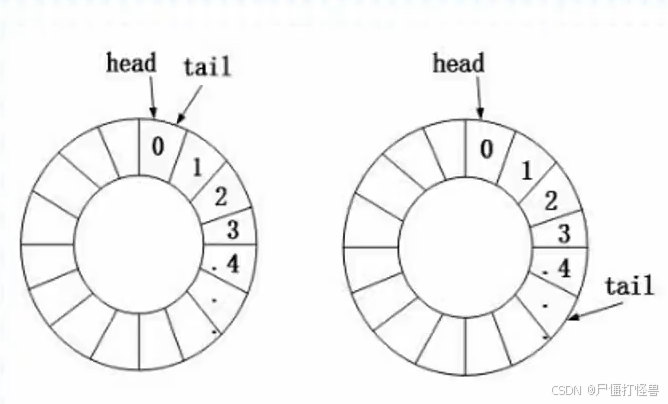
队空条件:head=tail
队满条件:(tail_1)%size=head
输出受限的双端队列是指元素可以从队列的两端输入,但是只能从队列的一端输出,如下图所示,若有 e 1 , e 2 , e 3 , e 4 e_1,e_2,e_3,e_4 e1,e2,e3,e4依次进入输出受限的双端队列,则得不到输出序列()

A. e 4 , e 3 , e 2 , e 1 e_4,e_3,e_2,e_1 e4,e3,e2,e1 B. e 4 , e 2 , e 1 , e 3 e_4,e_2,e_1,e_3 e4,e2,e1,e3
C. e 4 , e 3 , e 1 , e 2 e_4,e_3,e_1,e_2 e4,e3,e1,e2 D. e 4 , e 2 , e 3 , e 1 e_4,e_2,e_3,e_1 e4,e2,e3,e1
答案:D
五、串、数组、矩阵和广义表
5.1 串
串是仅由字符构成的有限序列,是取值范围受限的线性表。一般记为 S = ′ a 1 a 2 a n ′ S='a_1 a_2~~~a_n' S=′a1a2 an′,其中S是串名, a 1 a 2 a 3 a_1 a_2a_3 a1a2a3是串值。
- 空串:长度为零的串,空串不包含任何字符。
- 空格串:由一个或多个空格组成的串。
- 子串:由串中任意长度的连续字符构成的序列。含有子串的串称为主串。子串在主串中的位置指子串首次出现时,该子串的第一个字符在主串中 的位置。空串是任意串的子串。
- 串相等:指两串长度相等且对应位置上的字符也相同。
- 串比较:两个串比较大小时以字符的
ASCII码作为依据。比较从挨揍从两个串的第一个字符开始进行,字符的ASCll码值大者所在的串为大;若其中一个串先结束,则以串比较大着为大。
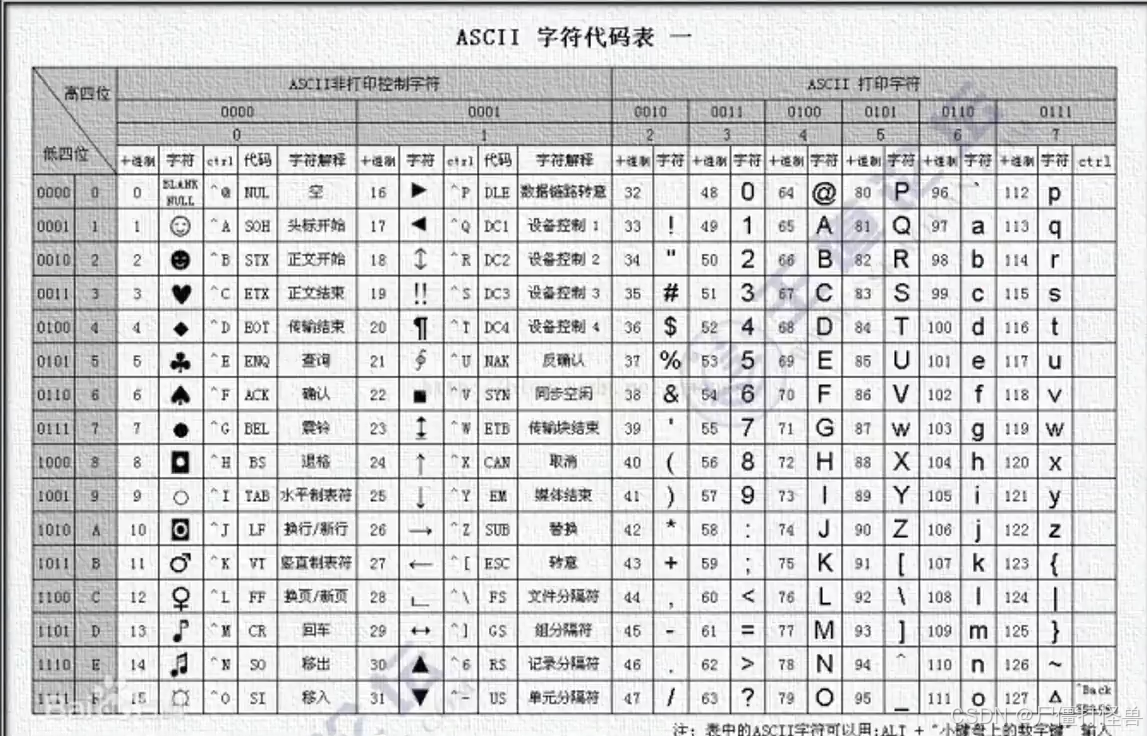
ASCII 字符代码表
1、对串进行的基本操作有以下几种:
- 赋值操作
StrAssign(s,t):将串t的值赋给串s - 连接操作
Concat(s,t):将串t的值连接在串s的尾部,形成一个新串 - 求串长
StrLength(s):返回串s 的长度 - 串比较
StrConpare(s,t):比较串s的长度 - 求子串
SubString(s,start,len):返回串s从start开始的、长度为len的字符序列
2、串的存储结构
-
串的顺序存储:定长存储结构
-
串的链式存储:快链
子串的定位操作通常称为串的模式匹配,它是各种串处理系统中最重要的运算之一,子串也称为模式串。
5.2 数组
| 数组类型 | 存储地址计算 |
|---|---|
| 一维数组a[n] | a[i]的存储地址为:a+i*len |
| 二维数组a[m] [n] | a[i] [j]的存储地址(按行存储)为:a+(i*n+j)*lena[i] [j]的存储地址(按列存储)为: a+(j*n+i)*len |
已知5行5列的二维数组a中的各元素占两个字节,求元素a[2] [3] 按行有限存储的存储地址?
a+(2*5+3)*2=a+26
5.3 稀疏矩阵

设有如下所示的下三角矩阵A[0…8,0…8],将该三角矩阵的非零元素(即行下标小于列下标的所有元素)按行优先压缩存储在数组M[1…m]中,则元素
A[i,j](0<=i<=8,j<=i)存储在数组M的()中

A. M [ i ( i + 1 ) 2 + j + 1 ] M[\frac{i(i+1)}{2}+j+1] M[2i(i+1)+j+1]
B. M [ i ( i + 1 ) 2 + j ] M[\frac{i(i+1)}{2}+j] M[2i(i+1)+j]C. M [ i ( i − 1 ) 2 + j ] M[\frac{i(i-1)}{2}+j] M[2i(i−1)+j]
D. M [ i ( i − 1 ) 2 + j + 1 ] M[\frac{i(i-1)}{2}+j+1] M[2i(i−1)+j+1]解:直接代入 a 0 , 0 , a 1 , 0 a_{0,0},a_{1,0} a0,0,a1,0测试,即可得出结果:A
5.4 广义表
广义表是n个元素组成的有限序列,是线性表的推广。
通常用递归的形式进行定义,记作: L S = ( a 0 , a 1 , . . . , a n ) LS=(a_0,a_1,...,a_n) LS=(a0,a1,...,an).
注:其中LS是表名, a i a_i ai是表元素,它可以是表(称作子表),也可以是数据元素(称为原子)。其中n是管仪表的长度(也就是最外层包含的元素个数),n=0的广义表为空表;而递归定义的重数就是广义表的深度,直观地说,就是定义中所含括号的重数(原子的深度为0,空表的深度为1)。
基本运算:取表头head(LS)和取表尾tail(LS)
若有LS1=(a,(b,c),(d,e)),head(LS1)=a,tail(LS1)=((b,c),(d,e))
例1:有广义表
LS1=(a,(b,c),(d,e)),则其长度为?深度为?长度为3,深度为2
例2:有广义表
LS1=(a,(b,c),(d,e)),要将其中b字母取出,操作就为?tail(LS1) = ((b,c),(d,e))
head(tail(:S1))=(b,c)
head(head(LS1(tail(LS1))))=b