目录
注意前几道题的红字,根据决策树判断dfs中是否需要写循环,2种情况就不写,超过两种就需要写
题目一:全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1] 输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1] 输出:[[1]]
这道题就是穷举的题,穷举也就是枚举
这种类型的题,第一步就是画出决策树:

上述画叉的就是剪枝操作,最后一行省略空间,只花了第一个,后面省略了
第二步设计代码即可:
需要设置三个全局变量,分别是ret、path、check
ret是一个vector<vector<string>>,用于存储最终结果
path是记录每一次的路径
check是一个bool类型的数组,用于检查是否出现重复数字,存储的nums数组中对应下标的数字是否重复使用
细节问题:
1、path在回溯时,需要将这一次的最后一个数字pop掉
2、在回溯时,check数组也同样需要将最后一个数字恢复为false
3、递归出口,判断出是叶子结点时直接将结果添加入ret中即可
根据决策树可以得知,每一次不止有2种情况,所以在dfs中需要for循环
代码如下:
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
bool check[7];
vector<vector<int>> permute(vector<int>& nums)
{
dfs(nums);
return ret;
}
void dfs(vector<int>& nums)
{
if(path.size() == nums.size())
{
ret.push_back(path);
return;
}
// 每次都遍历一遍nums的数字
for(int i = 0; i < nums.size(); i++)
{
if(check[i] == false)
{
path.push_back(nums[i]);
check[i] = true;
dfs(nums);
// 回溯后进行恢复现场的操作
path.pop_back();
check[i] = false;
}
}
}
};题目二:子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3] 输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0] 输出:[[],[0]]
解法一:每种情况都考虑到,最终取叶子结点的值
这道题同样,第一步画出决策树,可以考虑nums中的每一位是否选择:

×1表示不选1,√1表示选1,最后一列后面的都省略了,左边表示不选,右边表示选
第二步:设计代码
这里只需要两个全局变量ret和path了,不需要check判断是否剪枝
这里由于每层选择的数是不同的,所以需要传入nums的下标 pos,表示该选nums数组中的第几个的数了
每次进入dfs,都会判断是否选择 nums[pos] 这个数
如果不选,继续下一次的dfs
如果选,就将path加上这个数,也进行下一次的dfs
细节问题:
本题没有剪枝,所以只需要研究回溯与递归出口的细节问题
回溯的细节:如果本次选择了这个数,那么回溯回来以后,需要恢复现场,如果没选就不需要处理
递归出口:当 i 递增到和 nums 数组一样大时,就说明到最后一层了,此时将结果存入ret中即可
根据决策树可以得知,每一次只有两种情况,选或者不选,所以在dfs中不需要for循环,只需要判断是执行选还是不选的情况即可
代码如下:
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
vector<vector<int>> subsets(vector<int>& nums)
{
// 从0下标开始
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos)
{
if(pos == nums.size())
{
ret.push_back(path);
return;
}
// 选
path.push_back(nums[pos]);
dfs(nums, pos + 1);
// 回溯后恢复现场
path.pop_back();
// 不选
dfs(nums, pos + 1);
}
};解法二:按结果的个数分类
解法二的决策树,是按照最终结果的个数画的,且每次dfs递归时,只会递归大于当前最后一个数的值,不会递归小的数

此时很明显比解法一少进行了很多次dfs,而全局变量也是需要ret和path
此时传入dfs的参数,除了nums还需要有pos,表示该从nums数组中下标为pos的数开始枚举了,前面的不用管
细节问题:
同样,这种解法也没有剪枝操作,因为每次的pos就已经限制了不符合的情况
回溯时也需要注意恢复现场
递归出口这里不需要添加了,因为可以发现,每一次进入dfs都是最终的一个结果,所以每次进入后就直接将当前的path尾插到ret中即可
代码如下:
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
vector<vector<int>> subsets(vector<int>& nums)
{
// 从0下标开始
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos)
{
// 每次进入dfs都统计当前的结果
ret.push_back(path);
// 从pos下标的下一个位置开始统计
for(int i = pos; i < nums.size(); i++)
{
// 将nums[i]加入path中
path.push_back(nums[i]);
dfs(nums, i + 1);
// 回溯需要恢复现场
path.pop_back();
}
}
};题目三:找出所有子集的异或总和再求和
一个数组的 异或总和 定义为数组中所有元素按位 XOR 的结果;如果数组为 空 ,则异或总和为 0 。
- 例如,数组
[2,5,6]的 异或总和 为2 XOR 5 XOR 6 = 1。
给你一个数组 nums ,请你求出 nums 中每个 子集 的 异或总和 ,计算并返回这些值相加之 和 。
注意:在本题中,元素 相同 的不同子集应 多次 计数。
数组 a 是数组 b 的一个 子集 的前提条件是:从 b 删除几个(也可能不删除)元素能够得到 a 。
示例 1:
输入:nums = [1,3] 输出:6 解释:[1,3] 共有 4 个子集: - 空子集的异或总和是 0 。 - [1] 的异或总和为 1 。 - [3] 的异或总和为 3 。 - [1,3] 的异或总和为 1 XOR 3 = 2 。 0 + 1 + 3 + 2 = 6
示例 2:
输入:nums = [5,1,6] 输出:28 解释:[5,1,6] 共有 8 个子集: - 空子集的异或总和是 0 。 - [5] 的异或总和为 5 。 - [1] 的异或总和为 1 。 - [6] 的异或总和为 6 。 - [5,1] 的异或总和为 5 XOR 1 = 4 。 - [5,6] 的异或总和为 5 XOR 6 = 3 。 - [1,6] 的异或总和为 1 XOR 6 = 7 。 - [5,1,6] 的异或总和为 5 XOR 1 XOR 6 = 2 。 0 + 5 + 1 + 6 + 4 + 3 + 7 + 2 = 28
示例 3:
输入:nums = [3,4,5,6,7,8] 输出:480 解释:每个子集的全部异或总和值之和为 480 。
这道题其实就是在题目二子集的基础上完成的,题目二可以得到所有子集,此题也就是将每一个子集都异或一遍,再将所有子集异或的结果相加即可
所以依旧有两种方法求子集,下面就列举效率高一些的解法:
代码如下:
class Solution
{
public:
int path;
int ret;
int subsetXORSum(vector<int>& nums)
{
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos)
{
ret += path;
for(int i = pos; i < nums.size(); i++)
{
path ^= nums[i];
dfs(nums, i + 1);
// 回溯恢复现场
path ^= nums[i];
}
}
};题目四:全排列II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2] 输出: [[1,1,2], [1,2,1], [2,1,1]]
示例 2:
输入:nums = [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
这道题与全排列的那道题的区别就是:
这道题会有重复元素,而全排列I中没有重复元素
所以此题相比于全排列那道题,需要多做一步剪枝的操作
①在选择每一个位置的数时,相同的数只能选择一次
②与上面的全排列一样,每一个数只能使用一次,所以还是创建一个check数组
而因为有重复元素,为了方便比较重复元素,我们需要先将数组排序,这时重复元素就会在一起了
第二个剪枝和上面的操作一样,下面来具体讨论第一种情况的剪枝:
此题有两种策略,第一种策略是只考虑合法的情况,第二种策略是只考虑不合法的情况:
只考虑合法的情况:
既然合法,那么第二种情况为:check[i] == false,而第一种情况需要考虑三个点:
①i == 0,表示是当前位置选择的第一个数,此时是合法的
②nums[i] != nums[i - 1],两个数不相等时也是合法的
③如果两个数相等,但是不在同一层, 也是合法的,判断是否在同一层的方法就是前一个数已经使用过了,也就是 check[i - 1] == true,此时再这一层也是可以使用的
所以整体的判断语句就是:
check[i] == false && ( i == 0 || nums[i - 1] != nums[i] || check[i - 1] == true)
只考虑不合法的情况:
与上面的分析过程相反,这里就不多赘述了
check[i] == true || (i != 0 && nums[i - 1] == nums[i] && check[i - 1] == false)
下面的代码就写只考虑合法的情况,不合法的情况也是几乎一样的,只是判断语句变了,代码如下:
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
bool check[9];
vector<vector<int>> permuteUnique(vector<int>& nums)
{
// 开始dfs前将数组排序
sort(nums.begin(), nums.end());
dfs(nums);
return ret;
}
void dfs(vector<int>& nums)
{
if(path.size() == nums.size())
{
ret.push_back(path);
return;
}
// 每次都选一个数字
for(int i = 0; i < nums.size(); i++)
{
// 只考虑合法的情况
if(check[i] == false && (i == 0 || nums[i] != nums[i - 1] || check[i - 1] == true))
{
check[i] = true;
path.push_back(nums[i]);
dfs(nums);
// 恢复现场
path.pop_back();
check[i] = false;
}
}
}
};题目五:电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

示例 1:
输入:digits = "23" 输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]
示例 2:
输入:digits = "" 输出:[]
示例 3:
输入:digits = "2" 输出:["a","b","c"]
这道题同样先画出决策树,假设是示例一的 "23":

后面的就没画了,只要看出来决策树是什么方式画的就能理解了,与上面的全排列比较相似
同样是在叶子结点这里统计结果
这道题不同的是,需要解决数字与字符串的映射关系,就先在全局创建一个字符串数组,分别映射即可
接着就和上面的问题一样,进行全排列即可,只不过这里的全排列,每一个位置是不同的字符,其余就和全排列没有区别
代码如下:
class Solution
{
public:
// 给出字符串数组映射每一个数字对应的字符串
string hash[10] = {"","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"};
vector<string> ret;
string path;
vector<string> letterCombinations(string digits)
{
// 处理特殊情况
if(digits.empty()) return ret;
dfs(digits, 0);
return ret;
}
void dfs(const string& digits, int pos)
{
if(pos == digits.size())
{
ret.push_back(path);
return;
}
for(auto ch : hash[digits[pos] - '0'])
{
path.push_back(ch);
dfs(digits, pos + 1);
// 回溯恢复现场
path.pop_back();
}
}
};题目六:括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3 输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
输入:n = 1 输出:["()"]
首先需要想明白什么是有效的括号组合?
1、左括号的数量 = 右括号的数量
2、从头开始的任意一个子串,左括号的数量 >= 右括号的数量
这里就需要思考一下决策树怎么画,很简单,如果n = 2,那么就说明需要 4 个位置填括号,每个位置都可以选择 ( 或是 ) ,这时需要考虑剪枝的情况:
①左括号添加的数量必须是小于 n 的,因为假设 n = 2,那么就有4个位置,左右括号各为2个才是正确,所以左括号不可能大于 n ,左括号 > n 就可以剪枝了
②而右括号也是需要满足条件的,右括号必须是 <= 左括号的,因为一个左括号搭配一个右括号才是正确的,不可能存在没有左括号,只有一个右括号的情况,如果 右括号大于左括号也就需要剪枝了
所以本题需要创建5个全局变量,分别是:
左括号数量left、右括号数量right、括号组合个数n、当前的括号组合path、最终的结果ret
递归出口就是当右括号等于n时说明括号匹配成功
代码如下:
class Solution
{
public:
vector<string> ret;
string path;
int left,right,n;
vector<string> generateParenthesis(int _n)
{
n = _n;
dfs();
return ret;
}
void dfs()
{
if(left == right && right == n)
{
ret.push_back(path);
return;
}
path += '(';
left++;
if(left <= n) dfs();
path.pop_back();
left--;
path += ')';
right++;
if(right <= left) dfs();
path.pop_back();
right--;
}
};题目七:组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2 输出: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]
示例 2:
输入:n = 1, k = 1 输出:[[1]]
这道题同样是先画决策树,决策树就是确定有k个位置,每个位置选择[1, n]之间的数,这里需要考虑剪枝的操作,因为(1,2)和(2,1)是重复的,所以当我们第一个位置选1,第二个位置选2后,第二种选法,第一个位置选2时,第二个位置就不能选1了,只能从2后面的3开始选,因为会重复
所以在dfs中,传入一个参数,表示该第几个数了,每次从当前的数后面开始选
代码如下:
class Solution
{
public:
vector<vector<int>> ret;
vector<int> path;
int n, k;
vector<vector<int>> combine(int _n, int _k)
{
n = _n, k = _k;
dfs(1);
return ret;
}
// pos指该枚举数字几了,从1开始,一直到数字n
void dfs(int pos)
{
if(path.size() == k)
{
ret.push_back(path);
return;
}
// 从pos开始,枚举到n,体现了剪枝操作
for(int i = pos; i <= n; i++)
{
path.push_back(i);
dfs(i + 1);
// 恢复现场
path.pop_back();
}
}
}; 题目八:目标和
给你一个非负整数数组 nums 和一个整数 target 。
向数组中的每个整数前添加 '+' 或 '-' ,然后串联起所有整数,可以构造一个 表达式 :
- 例如,
nums = [2, 1],可以在2之前添加'+',在1之前添加'-',然后串联起来得到表达式"+2-1"。
返回可以通过上述方法构造的、运算结果等于 target 的不同 表达式 的数目。
示例 1:
输入:nums = [1,1,1,1,1], target = 3 输出:5 解释:一共有 5 种方法让最终目标和为 3 。 -1 + 1 + 1 + 1 + 1 = 3 +1 - 1 + 1 + 1 + 1 = 3 +1 + 1 - 1 + 1 + 1 = 3 +1 + 1 + 1 - 1 + 1 = 3 +1 + 1 + 1 + 1 - 1 = 3
示例 2:
输入:nums = [1], target = 1 输出:1
此题在动态规划章节也写过,最佳解法是动态规划,使用dfs时间复杂度比较高,效率比较低
这道题和子集那道题非常相似,决策树的层数就是数字的个数,每一层的每个数都会分为两个情况,+ 或 -,所以下面有两个版本,将path写到全局,与path写进参数
写到全局的path时间复杂度比较大,因为加减法也是很耗时的
写进参数,就不需要恢复现场进行加减法, 也不需要传入dfs前加减法,每次回退到上一层自动就恢复到没有加减之前的操作了
path作为全局变量的代码如下:
class Solution
{
public:
int ret, path, target;
int findTargetSumWays(vector<int>& nums, int _target)
{
target = _target;
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int i)
{
if(i == nums.size())
{
if(path == target) ret++;
return;
}
// +
path += nums[i];
dfs(nums, i + 1);
path -= nums[i]; // 恢复现场
// -
path -= nums[i];
dfs(nums, i + 1);
path += nums[i]; // 恢复现场
}
};path作为dfs函数的参数的代码如下:
class Solution
{
public:
int ret, target;
int findTargetSumWays(vector<int>& nums, int _target)
{
target = _target;
dfs(nums, 0, 0);
return ret;
}
void dfs(vector<int>& nums, int i, int path)
{
if(i == nums.size())
{
if(path == target) ret++;
return;
}
// +
dfs(nums, i + 1, path + nums[i]);
// -
dfs(nums, i + 1, path - nums[i]);
}
};题目九:组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates =[2,3,6,7],target =7输出:[[2,2,3],[7]] 解释: 2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。 7 也是一个候选, 7 = 7 。 仅有这两种组合。
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
解法一:依次选每个位置的数
先画一个决策树,每次选时从上一个选的数开始选,不需要重头选,因为重头选会导致出现重复的结果:

画了一部分决策树,可以看出来有两个地方需要剪枝:
第一、每次需要从上一次的数开始选择,不要选前面的数,例如第二层,第二个数2不选1,因为会和第一个数1选2重复
第二、如果最终加的数值大于target了,也就不需要继续了,因为已经大于target了,再加只会更大,不可能等于target了
代码如下:
class Solution
{
public:
int target;
vector<vector<int>> ret;
vector<int> path;
vector<vector<int>> combinationSum(vector<int>& nums, int _target)
{
target = _target;
dfs(nums, 0, 0);
return ret;
}
void dfs(vector<int>& nums, int pos, int num)
{
// num > target 剪枝
if(num >= target)
{
if(num == target) ret.push_back(path);
return;
}
// 从pos位置开始,剪枝
for(int i = pos; i < nums.size(); i++)
{
path.push_back(nums[i]);
dfs(nums, i, num + nums[i]);
path.pop_back(); // 恢复现场
}
}
};解法二:每个数列举n次
解法二就是依次枚举每一个数, 每一个数都枚举k次,每次都加一倍的该数,直到超过target为止,当第一个数枚举完毕,再枚举第二个数的情况
代码如下:
class Solution {
int target;
vector<int> path;
vector<vector<int>> ret;
public:
vector<vector<int>> combinationSum(vector<int>& nums, int _target)
{
target = _target;
dfs(nums, 0, 0);
return ret;
}
void dfs(vector<int>& nums, int pos, int sum)
{
if(sum == target)
{
ret.push_back(path);
return;
}
if(sum > target || pos == nums.size())
return;
// 枚举个数
for(int k = 0; k * nums[pos] + sum <= target; k++)
{
if(k) path.push_back(nums[pos]);
dfs(nums, pos + 1, sum + k * nums[pos]);
}
// 恢复现场
for(int k = 1; k * nums[pos] + sum <= target; k++)
{
path.pop_back();
}
}
};题目十:字母大小写全排列
给定一个字符串 s ,通过将字符串 s 中的每个字母转变大小写,我们可以获得一个新的字符串。
返回 所有可能得到的字符串集合 。以 任意顺序 返回输出。
示例 1:
输入:s = "a1b2" 输出:["a1b2", "a1B2", "A1b2", "A1B2"]
示例 2:
输入: s = "3z4" 输出: ["3z4","3Z4"]
这道题当遇到数字不变,在遇到字母时,则分为两种情况,变或不变
所以不论是数字还是字母都有不变的情况,所以代码可以分为变和不变
根据决策树可以得知,只有两种情况,所以在dfs中不需要for循环,只需要判断是执行变还是不变的情况即可
代码如下:
class Solution
{
public:
vector<string> ret;
string path;
vector<string> letterCasePermutation(string s)
{
dfs(s, 0);
return ret;
}
void dfs(string& s, int pos)
{
if(pos == s.size())
{
ret.push_back(path);
return;
}
// 不变
path.push_back(s[pos]);
dfs(s, pos + 1);
path.pop_back();
// 变
if(s[pos] < '0' || s[pos] > '9')
{
// 得到变化后的字母,递归
char ch = change(s[pos]);
path.push_back(ch);
dfs(s, pos + 1);
path.pop_back(); // 恢复现场
}
}
char change(char ch)
{
if(ch >= 'a' && ch <= 'z') ch -= 32;
else ch += 32;
return ch;
}
};题目十一:优美的排列
假设有从 1 到 n 的 n 个整数。用这些整数构造一个数组 perm(下标从 1 开始),只要满足下述条件 之一 ,该数组就是一个 优美的排列 :
perm[i]能够被i整除i能够被perm[i]整除
给你一个整数 n ,返回可以构造的 优美排列 的 数量 。
示例 1:
输入:n = 2
输出:2
解释:
第 1 个优美的排列是 [1,2]:
- perm[1] = 1 能被 i = 1 整除
- perm[2] = 2 能被 i = 2 整除
第 2 个优美的排列是 [2,1]:
- perm[1] = 2 能被 i = 1 整除
- i = 2 能被 perm[2] = 1 整除
示例 2:
输入:n = 1 输出:1
此题同样是先画决策树,确定每一个位置的数,每次不能选重复的,所以创建一个bool类型的check数组,保证每次不会选到重复的数字
并且每次得知选的数字不重复后,再判断该数字是否能够满足题目中的条件,如果能满足其中一个,就进入dfs,如果不能满足,就剪枝
由于此题并不需要返回满足题意的数组,所以就不需要创建一个vector<int>的数组path,只需要判断是否满足条件即可
代码如下:
class Solution
{
public:
int ret, n;
bool vis[16];
int countArrangement(int _n)
{
n = _n;
dfs(1);
return ret;
}
void dfs(int pos)
{
// 下标从1开始,所以下一层变为n + 1时就退出
if(pos == n + 1)
{
ret++;
return;
}
for(int i = 1; i <= n; i++)
{
if(vis[i] == false && (pos % i == 0 || i % pos == 0))
{
vis[i] = true;
dfs(pos + 1);
vis[i] = false; // 恢复现场
}
}
}
};题目十二:N皇后
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例 1:
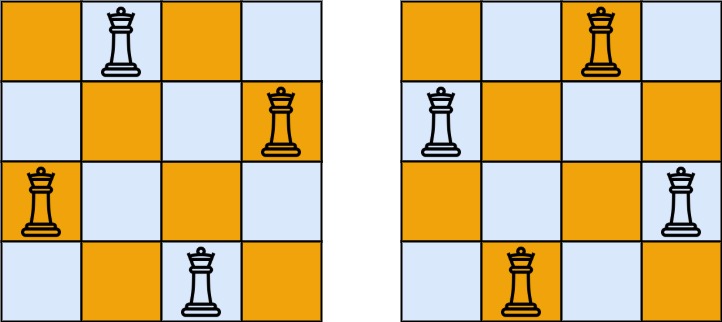
输入:n = 4 输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]] 解释:如上图所示,4 皇后问题存在两个不同的解法。
示例 2:
输入:n = 1 输出:[["Q"]]
这道题可是非常经典的题了,决策树也比较好画,只需要每次考虑其中一行的情况:
也就是第一次考虑第0行,可以放几个位置,第二次在第0行位置的基础上,考虑第1行有几种情况,以此类推
每次放的时候,无脑循环判断该位置所在的列、主对角线、副对角线是否有元素,如果有就进行剪枝操作,不用判断这一行是否有其他元素, 因为我们的决策树就保证了一行只会有一个元素
无脑判断该位置是否能填皇后即可,最主要看下面的方式,如果快捷地判断:
解法一:每次都无脑判断新皇后的位置是否符合题意
class Solution
{
public:
vector<vector<string>> ret;
vector<string> path;
int n;
vector<vector<string>> solveNQueens(int _n)
{
n = _n;
// 最开始将path每个位置都置为.
path.resize(n);
for(int i = 0; i < n; i++)
path[i].append(n, '.');
dfs(0);
return ret;
}
void dfs(int row)
{
if(row == n)
{
ret.push_back(path);
return;
}
for(int col = 0; col < n; col++)
{
// 如果符合题意就将该位置填为皇后
if(check(col, row))
{
path[row][col] = 'Q';
dfs(row + 1);
path[row][col] = '.';
}
}
}
// 无脑比较皇后的位置是否符合题意
bool check(int col, int row)
{
for(int r = 0; r < path.size(); r++)
{
for(int c = 0; c < n; c++)
{
if(path[r][c] == 'Q' && (c == col || (abs(row - r) == abs(col - c))))
{
return false;
}
}
}
return true;
}
};解法二:设置三个bool类型数组判断新皇后位置是否符合题意
设置三个bool类型的数组,分别用于判断一个位置所在的列、主对角线、副对角线是否有其他皇后
bool checkCol[10]用于判断某列是否有皇后,bool checkDig1[20]、bool checkDig2[20]用于判断主对角线、副对角线是否有其他皇后
checkCol比较简单,每次将皇后的列对应插入,以后判断新皇后的列在不在checkCol中即可
checkDig1和checkDig2是根据斜率计算的,因为主对角线和副对角线上,每一个位置都在同一条线上,表达式是:y = kx + b,其中主对角线的 k = 1,副对角线的 k = -1,即:
y = x + b,y = -x + b
y - x = b,y + x = b
根据上面的式子可以得出:
主对角线:纵坐标 - 横坐标是定值
副对角线:纵坐标 + 横坐标是定值
所以每次放入一个皇后时,将该皇后的 纵坐标 +/- 横坐标 的值放入checkDig1和checkDig2中,以后判断新皇后的 纵坐标 +/- 横坐标 在不在checkDig1和checkDig2中即可
需要注意的是 纵坐标 - 横坐标 可能是负数,所以这里统一向上平移 n 哥单位,就可以保证为正数了
代码如下:
class Solution
{
public:
vector<vector<string>> ret;
vector<string> path;
bool checkCol[10], checkDig1[20], checkDig2[20];
int n;
vector<vector<string>> solveNQueens(int _n)
{
n = _n;
// 最开始将path每个位置都置为 .
path.resize(n);
for(int i = 0; i < n; i++)
path[i].append(n, '.');
dfs(0);
return ret;
}
void dfs(int row)
{
if(row == n)
{
ret.push_back(path);
return;
}
// 尝试在这一行的某个位置放皇后
for(int col = 0; col < n; col++)
{
// 如果符合题意就将该位置填为皇后
int dig1 = col - row + n;
int dig2 = col + row;
// 剪枝
if(!checkCol[col] && !checkDig1[dig1] && !checkDig2[dig2])
{
checkCol[col] = checkDig1[dig1] = checkDig2[dig2] = true;
path[row][col] = 'Q';
dfs(row + 1);
path[row][col] = '.';
checkCol[col] = checkDig1[dig1] = checkDig2[dig2] = false;
}
}
}
};题目十三:有效的数独
请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)
注意:
- 一个有效的数独(部分已被填充)不一定是可解的。
- 只需要根据以上规则,验证已经填入的数字是否有效即可。
- 空白格用
'.'表示。
示例 1:

输入:board = [["5","3",".",".","7",".",".",".","."] ,["6",".",".","1","9","5",".",".","."] ,[".","9","8",".",".",".",".","6","."] ,["8",".",".",".","6",".",".",".","3"] ,["4",".",".","8",".","3",".",".","1"] ,["7",".",".",".","2",".",".",".","6"] ,[".","6",".",".",".",".","2","8","."] ,[".",".",".","4","1","9",".",".","5"] ,[".",".",".",".","8",".",".","7","9"]] 输出:true
示例 2:
输入:board = [["8","3",".",".","7",".",".",".","."] ,["6",".",".","1","9","5",".",".","."] ,[".","9","8",".",".",".",".","6","."] ,["8",".",".",".","6",".",".",".","3"] ,["4",".",".","8",".","3",".",".","1"] ,["7",".",".",".","2",".",".",".","6"] ,[".","6",".",".",".",".","2","8","."] ,[".",".",".","4","1","9",".",".","5"] ,[".",".",".",".","8",".",".","7","9"]] 输出:false 解释:除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。 但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。
这道题并不是回溯的题目,只是为了下一道题解数独做铺垫
这道题就是让我们判断上面所填的数字是否是有效的数独,而下面的题是填充数独
与上一题的思想一样,在判断某一行某一列是否出现重复数字时,可以采用设置bool类型的数组,设置为 bool row/col[9][10],第一个表示第几行/列,第二个表示该数是否出现过
最主要的就是 9 × 9 的小方格中是否有重复数字,这里我们可以将3个位置看做一个整体,如下所示:

相当于获得了一个 3 × 3 的数组来存储这个9宫格,即 grid[3][3] 想找每一个数字的下标对应这个数组的位置
只需要将数字的下标除3,得到的值就是对应的位置,例如右下角的9,下标是 [8, 8],横纵坐标都除3,得到 [2, 2],计算出了在 3 × 3 的数组中对应的 (2, 2) 的位置
那么解决了这个问题,如何处理9宫格数字重复的问题也很简单,在 grid[3][3] 的基础上,再加上一维的数组,也就是 grid[3][3][10],表示某个9宫格中是否出现了某个数字
代码如下:
class Solution
{
public:
bool col[9][10], row[9][10], grid[3][3][10];
bool isValidSudoku(vector<vector<char>>& board)
{
for(int i = 0; i < 9; i++)
{
for(int j = 0; j < 9; j++)
{
if(board[i][j] != '.')
{
int num = board[i][j] - '0';
// 判断是否是有效的
if(!col[i][num] && !row[j][num] && !grid[i/3][j/3][num])
{
col[i][num] = row[j][num] = grid[i/3][j/3][num] = true;
}
else return false;
}
}
}
return true;
}
};题目十四:解数独
编写一个程序,通过填充空格来解决数独问题。
数独的解法需 遵循如下规则:
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
示例 1:
输入:board = [["5","3",".",".","7",".",".",".","."],["6",".",".","1","9","5",".",".","."],[".","9","8",".",".",".",".","6","."],["8",".",".",".","6",".",".",".","3"],["4",".",".","8",".","3",".",".","1"],["7",".",".",".","2",".",".",".","6"],[".","6",".",".",".",".","2","8","."],[".",".",".","4","1","9",".",".","5"],[".",".",".",".","8",".",".","7","9"]] 输出:[["5","3","4","6","7","8","9","1","2"],["6","7","2","1","9","5","3","4","8"],["1","9","8","3","4","2","5","6","7"],["8","5","9","7","6","1","4","2","3"],["4","2","6","8","5","3","7","9","1"],["7","1","3","9","2","4","8","5","6"],["9","6","1","5","3","7","2","8","4"],["2","8","7","4","1","9","6","3","5"],["3","4","5","2","8","6","1","7","9"]] 解释:输入的数独如上图所示,唯一有效的解决方案如下所示:

这道题与上道题的思路一样,设置三个bool类型的数组,统计每一行、每一列、每一个九宫格是否出现重复数字
首先需要初始化,先将数独中的数字放入这三个bool类型的数组中,然后再遍历出现 . 的位置,开始dfs
代码如下:
class Solution
{
public:
bool grid[3][3][10], row[9][10], col[9][10];
void solveSudoku(vector<vector<char>>& board)
{
// 初始化
for(int i = 0; i < 9; i++)
{
for(int j = 0; j < 9; j++)
{
if(board[i][j] != '.')
{
int num = board[i][j] - '0';
row[i][num] = col[j][num] = grid[i/3][j/3][num] = true;
}
}
}
dfs(board);
}
bool dfs(vector<vector<char>>& board)
{
for(int i = 0; i < 9; i++)
{
for(int j = 0; j < 9; j++)
{
if(board[i][j] == '.')
{
// 填数
for(int num = 1; num <= 9; num++)
{
if(!row[i][num] && !col[j][num] && !grid[i/3][j/3][num])
{
row[i][num] = col[j][num] = grid[i/3][j/3][num] = true;
board[i][j] = '0' + num;
if(dfs(board) == true) return true;
// 恢复现场
row[i][num] = col[j][num] = grid[i/3][j/3][num] = false;
board[i][j] = '.';
}
}
// 如果走到这,说明9个数字都放不进去,返回false
return false;
}
}
}
// 走到这说明每个位置都遍历了一遍,没有返回false,返回true
return true;
}
};题目十五:单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
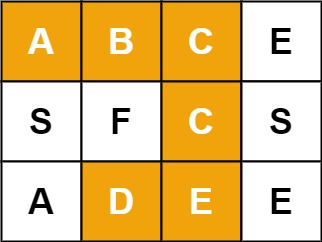
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED" 输出:true
示例 2:
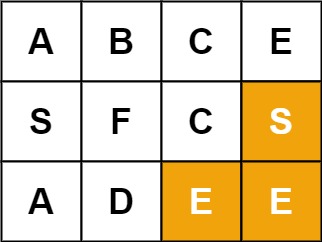
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE" 输出:true
示例 3:

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB" 输出:false
z这道题也是先画决策树,即先在全数组中找符合word[0]的字符,列举出来,然后再在这些列举出来的字符下面,继续寻找符合word[1]的字符位置,这里寻找时,只能在上下左右寻找,且不能找重复的位置
所以与bfs一样,也需要设置一个bool数组vis,来每次判断某个位置是否已经选择过了
代码如下:
class Solution
{
public:
bool vis[7][7];
int dx[4] = {0,0,-1,1};
int dy[4] = {-1,1,0,0};
int m, n;
bool exist(vector<vector<char>>& board, string word)
{
m = board.size(), n = board[0].size();
// 最开始找符合word的第一个字符在board中的位置
for(int i = 0; i < m; i++)
{
for(int j = 0; j < n; j++)
{
if(board[i][j] == word[0])
{
vis[i][j] = true;
if(dfs(board, i, j, word, 1)) return true;;
vis[i][j] = false;
}
}
}
return false;
}
bool dfs(vector<vector<char>>& board, int i, int j, string word, int pos)
{
if(pos == word.size())
{
return true;
}
// 与bfs一样,创建dx和dy方便找上下左右位置的数
for(int k = 0; k < 4; k++)
{
int a = i + dx[k];
int b = j + dy[k];
if(a >= 0 && a < m && b >= 0 && b < n && !vis[a][b] && board[a][b] == word[pos])
{
vis[a][b] = true;
if(dfs(board, a, b, word, pos +1)) return true;
vis[a][b] = false;
}
}
// 走到这说明没有找到对应word的字符,返回false
return false;
}
};题目十六:黄金矿工
你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源分布,并用大小为 m * n 的网格 grid 进行了标注。每个单元格中的整数就表示这一单元格中的黄金数量;如果该单元格是空的,那么就是 0。
为了使收益最大化,矿工需要按以下规则来开采黄金:
- 每当矿工进入一个单元,就会收集该单元格中的所有黄金。
- 矿工每次可以从当前位置向上下左右四个方向走。
- 每个单元格只能被开采(进入)一次。
- 不得开采(进入)黄金数目为
0的单元格。 - 矿工可以从网格中 任意一个 有黄金的单元格出发或者是停止。
示例 1:
输入:grid = [[0,6,0],[5,8,7],[0,9,0]] 输出:24 解释: [[0,6,0], [5,8,7], [0,9,0]] 一种收集最多黄金的路线是:9 -> 8 -> 7。
示例 2:
输入:grid = [[1,0,7],[2,0,6],[3,4,5],[0,3,0],[9,0,20]] 输出:28 解释: [[1,0,7], [2,0,6], [3,4,5], [0,3,0], [9,0,20]] 一种收集最多黄金的路线是:1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7。
这道题也就是要求,每一步都必须走到大于0的位置也就是有黄金的位置,且只能每个位置走一次,不能走等于0的位置,最终求走过的位置收集最多的黄金数
与上一题的思路大致相同,先找每一个非0位置,接着从这个位置开始dfs每一个可能的结果,取最大的那一个
代码如下:
class Solution
{
public:
int dx[4] = {0,0,-1,1};
int dy[4] = {-1,1,0,0};
bool vis[16][16];
int ret, m, n;
int getMaximumGold(vector<vector<int>>& grid)
{
m = grid.size(), n = grid[0].size();
// 每次都找一个非0位置,接着dfs,直到遍历完全部非0位置为止
for(int i = 0; i < m ; i++)
{
for(int j = 0; j < n; j++)
{
if(grid[i][j] != 0)
{
vis[i][j] = true;
dfs(grid, i, j, grid[i][j]);
vis[i][j] = false;
}
}
}
return ret;
}
void dfs(vector<vector<int>>& grid, int i, int j, int tmp)
{
// 每次进入下一层都更新结果
ret = max(ret, tmp);
for(int k = 0; k < 4; k++)
{
int x = i + dx[k];
int y = j + dy[k];
if(x >= 0 && x < m && y >= 0 && y < n && !vis[x][y] && grid[x][y])
{
vis[x][y] = true;
dfs(grid, x, y, tmp + grid[x][y]);
vis[x][y] = false;
}
}
// 不需要函数出口,当上下左右没有位置时,自动退出函数
}
};题目十七:不同路径III
在二维网格 grid 上,有 4 种类型的方格:
1表示起始方格。且只有一个起始方格。2表示结束方格,且只有一个结束方格。0表示我们可以走过的空方格。-1表示我们无法跨越的障碍。
返回在四个方向(上、下、左、右)上行走时,从起始方格到结束方格的不同路径的数目。
每一个无障碍方格都要通过一次,但是一条路径中不能重复通过同一个方格。
示例 1:
输入:[[1,0,0,0],[0,0,0,0],[0,0,2,-1]] 输出:2 解释:我们有以下两条路径: 1. (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2) 2. (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2)
示例 2:
输入:[[1,0,0,0],[0,0,0,0],[0,0,0,2]] 输出:4 解释:我们有以下四条路径: 1. (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2),(2,3) 2. (0,0),(0,1),(1,1),(1,0),(2,0),(2,1),(2,2),(1,2),(0,2),(0,3),(1,3),(2,3) 3. (0,0),(1,0),(2,0),(2,1),(2,2),(1,2),(1,1),(0,1),(0,2),(0,3),(1,3),(2,3) 4. (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2),(2,3)
示例 3:
输入:[[0,1],[2,0]] 输出:0 解释: 没有一条路能完全穿过每一个空的方格一次。 请注意,起始和结束方格可以位于网格中的任意位置。
这道题虽然是一道困难题目,但是与前两道题的思路以及代码是非常相似的
这道题是规定了两个位置,一个开始一个结束,要求从开始位置到结束为止,必须经过每一个无障碍位置,求有多少条满足题意的路径
思路就是先遍历一遍,计算出无障碍位置有多少个,接着从开始位置dfs到结束为止,判断经过位置的个数是否是无障碍位置的个数,最终返回结果
代码如下:
class Solution
{
public:
int dx[4] = {0,0,-1,1};
int dy[4] = {-1,1,0,0};
bool vis[21][21];
int count, ret, m, n;
int uniquePathsIII(vector<vector<int>>& grid)
{
m = grid.size(), n = grid[0].size();
int bx = 0, by = 0;
for(int i = 0; i < m; i++)
for(int j = 0; j < n; j++)
{
if(grid[i][j] == 0) count++;
if(grid[i][j] == 1)
{
bx = i;
by = j;
}
}
// 将初始与结束位置也算进去
count += 2;
vis[bx][by] = true;
dfs(grid, bx, by, 1);
return ret;
}
void dfs(vector<vector<int>>& grid, int i, int j, int path)
{
if(grid[i][j] == 2)
{
// 判断是否合法
if(path == count) ret++;
return;
}
// 每次都上下左右四个位置判断
for(int k = 0; k < 4; k++)
{
int x = i + dx[k];
int y = j + dy[k];
if(x >= 0 && x < m && y >= 0 && y < n && !vis[x][y] && grid[x][y] >= 0)
{
vis[x][y] = true;
dfs(grid, x, y, path + 1);
vis[x][y] = false;
}
}
}
};[递归/搜索/回溯]综合练习题到此结束