✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅ 具体问题可以私信或扫描文章底部二维码。
(1) 本研究基于可持续发展理论,首先明确了森林生态承载力的内涵,并构建了评价指标体系。森林生态承载力的内涵被定义为:在一定时期和一定区域内,森林生态系统的自我维持和自我调节能力,以及森林资源供给和环境承载力能够支持的最大人类活动水平。基于这一内涵,本研究初步构建了森林生态承载力的评价指标体系,包括森林生态弹性力、森林资源供给能力、森林生态环境承载能力和人类活动潜力四个方面,总共包含20项指标。森林生态弹性力主要反映森林在面对环境压力时的恢复能力,森林资源供给能力侧重于评估森林提供生态服务和资源的能力,森林生态环境承载能力则评估森林系统在一定条件下维持生态平衡的能力,而人类活动潜力反映了区域内人类活动对森林生态的压力和利用情况。
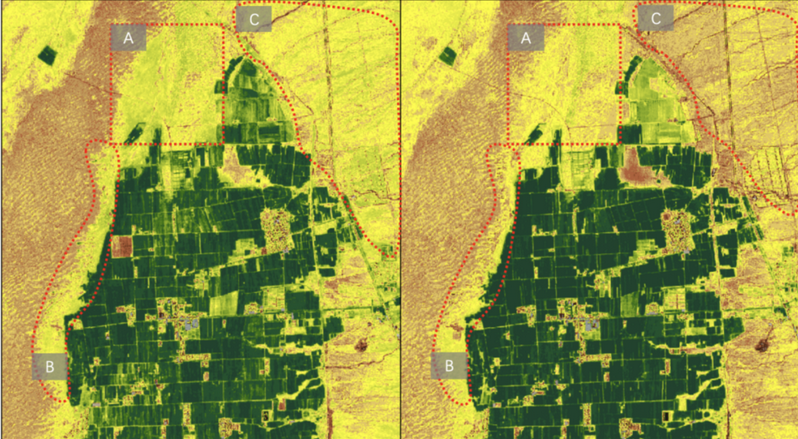
(2) 利用GIS和RS技术对杭州市的森林生态信息进行挖掘是本研究的重点之一。在遥感技术的支持下,通过国产卫星高分六号获取了杭州市的遥感影像数据,并结合样地数据,采用随机森林模型对杭州市的森林郁闭度和森林蓄积量进行了反演。为了确保估算精度,研究对比了多元逐步回归、BP神经网络和随机森林模型的精度表现,最终选择了精度最高的随机森林模型。这些反演数据为杭州市森林生态承载力评价提供了可靠的数据基础。此外,GIS技术被用于计算杭州市的地形、气象等自然地理信息以及森林的固碳释氧功能、水源涵养功能和土壤保持功能等生态服务功能量。通过结合遥感和GIS的技术手段,研究探索了一种快速、高效且覆盖范围广的森林资源信息获取方法,不仅提高了数据获取的时效性,还有效降低了传统森林生态信息调查的成本和复杂性,为森林生态管理提供了一条新的技术路径。
(3) 在评价指标筛选与确定的过程中,本研究采用了病态指数和信息可替代性等方法对原始的20项评价指标进行了筛选,最终将指标数目减少至16项。通过对指标筛选前后森林生态承载力综合评价值的对比,发现其相对偏差绝对值低于5%,证明了筛选结果的可行性和合理性。筛选后的指标体系包括了反映森林生态弹性力的4项指标(坡度、腐殖质厚度、自然度、群落结构),反映森林资源供给能力的5项指标(森林覆盖率、森林单位面积蓄积量、森林郁闭度、中幼林占龄级组成比例、公益林比重),反映森林生态环境承载能力的4项指标(固碳释氧功能、水源涵养功能、土壤保持功能、森林健康等级),以及反映人类活动潜力的3项指标(GDP增长率、人均森林占有量、商品林比重)。通过对指标的有效筛选,降低了评价过程的复杂性,减少了工作量,为今后常态化的森林生态承载力评价工作提供了有力的简化思路与借鉴。
(4) 基于筛选后的16项指标体系,本研究对杭州市森林生态承载力进行了全面的评价与分析。结果表明,杭州市的森林总体上处于强承载状态,但各县(市、区)之间存在显著差异。具体而言,杭州市各县(市、区)的森林生态承载力由高到低依次为:淳安县、临安区、建德市、桐庐县、富阳区、余杭区、中心城区和萧山区。其中,淳安县、临安区、建德市和桐庐县的森林生态承载力均超过杭州市的总体水平,属于强承载状态,而富阳区、余杭区、中心城区和萧山区则低于杭州市的总体水平,仅处于中等承载状态。研究发现,人类活动潜力是导致各区域森林生态承载力差异的主要因素,尤其是在人口密集、经济活动活跃的区域,由于开发压力较大,森林的承载能力相对较低。评价结果在一定程度上反映了各地的主体功能定位,例如,淳安县和临安区由于人类干预较少,森林生态系统得到了较好的保护和恢复,因而承载力较高。基于上述评价结果,本研究从提高森林资源供给能力、增强森林生态环境承载能力以及合理规划人类活动三个方面,有针对性地提出了提高杭州市森林生态承载力的对策与建议,包括加强森林资源保护与管理、加大植被恢复力度、科学规划土地利用以及提高公众生态保护意识等措施。
import geopandas as gpd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
import numpy as np
# 读取森林生态数据
forest_data = gpd.read_file("forest_data.geojson")
# 提取特征和标签
features = forest_data[['slope', 'elevation', 'vegetation_density']]
target = forest_data['carbon_sequestration']
# 训练随机森林模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(features, target)
# 使用模型进行预测
predicted_values = model.predict(features)
# 将预测结果添加到GeoDataFrame中
forest_data['predicted_carbon'] = predicted_values
# 绘制森林固碳功能空间分布图
fig, ax = plt.subplots(figsize=(10, 10))
ax.set_title('杭州市森林固碳功能预测分布')
forest_data.plot(column='predicted_carbon', ax=ax, legend=True, cmap='Greens')
plt.show()
# 保存预测结果为新的GeoJSON文件
forest_data.to_file("predicted_forest_carbon.geojson", driver='GeoJSON')