一、什么是计算机视觉?
计算机视觉,其实就是教机器怎么像我们人一样,用摄像头看看周围的世界,然后理解它。比如说,它能认出这是个苹果,或者那边有辆车。除此之外,还能把拍到的照片或者视频转换成有用的信息,帮我们做决定。整个过程就是为了让机器能看懂图像,然后根据这些图像来做出聪明的选择。
二、计算机视觉实现起来难吗?
人类依赖视觉,找辆汽车轻而易举,毕竟汽车那么大,一眼就能看出来,所以常误以为计算机视觉简单,但实际上,这个过程背后有复杂的视觉处理机制,涉及大脑多通道处理、注意力系统选择性分析、以及反馈机制的调节。
大致的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
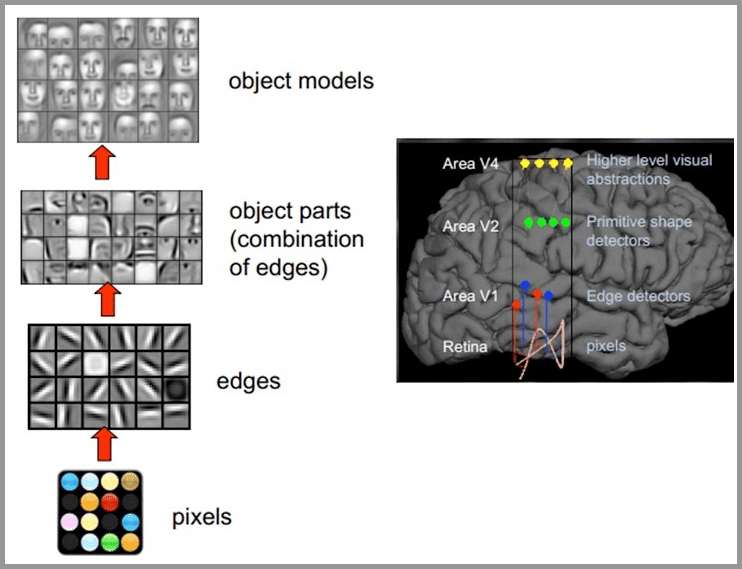
所以,机器的方法也是类似,就像搭积木一样,我们用机器来学习识别图片,就是一层层地搭建神经网络。最下面的几层负责找出图片里最基本的东西,比如边边角角或者颜色块。然后,这些基本特征再被组合起来,形成更复杂一些的特征,就像是用小积木拼成大积木。这样一层一层地往上,每一层都用下一层的特征来构建更高级的特征。最后,到了最顶层,机器就能根据这些层层叠加的特征来决定图片里是啥东西了。
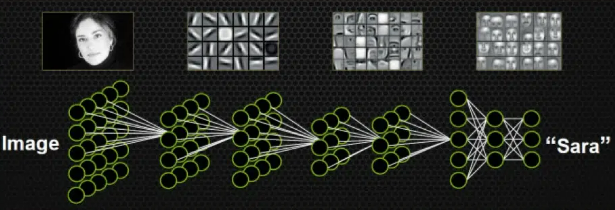
所以要开发高级的人工智能视觉系统,需要模拟人类的视觉机制,包括大脑、眼睛和感官的协同工作,这其实是一个非常有挑战性的任务。
三、学习计算机视觉的挑战
计算机视觉在实现过程中会受到很多因素的影响,比如:
图像噪声
就是指照片里那些乱七八糟、本来不应该出现的斑点或者条纹。这些东西可能是摄像头不够好,或者光线太暗,或者是照片在传过来的时候出了点问题造成的。这些噪声会让照片看起来没那么清楚,质量下降,对计算机视觉来说就像是干扰信号,特别是在计算机要认出照片里是什么东西,或者是要把照片里不同的部分分开来的时候,这些噪声就特别碍事。

复杂场景下的目标检测和跟踪
在那种乱糟糟的环境里,我们想找的东西可能被其他东西挡住了,或者从我们这个角度看过去,它被遮得严严实实的。这种情况让计算机视觉系统非常棘手,因为要在这样的场景里找到并一直盯着目标,难度不小。

特征难以提取
比如我们日常拍照,无论是在白天还是夜晚拍摄,无论是从正面还是侧面,或者是在笑还是在跑,每张照片看起来都会有很大的不同。哪怕你只是把照片旋转一下,像素也会发生很大的变化。
所以,尽管这些照片的内容都是一个人,但在像素层面上,它们之间的差异可能非常大。这对于计算机视觉系统来说,要准确地从这些照片中提取出有用的特征,确实是个不小的挑战。
需要计算的数据量巨大
就拿手机随便拍张照来说,照片的分辨率可能是1000像素宽乘以2000像素高。每个像素点都有红、绿、蓝三个颜色通道,所以一张照片就有1000乘以2000再乘以3,等于600万个数据点。也就是说,光是处理一张照片,就得搞定600万个参数。要是考虑到现在越来越流行的4K视频,那数据量更是惊人,你就能想象这背后的计算量有多大了。
四、计算机视觉的 7 大应用方向
图像分类
简单来说,就是计算机视觉里的一个任务,目的是让计算机能够识别出一张图片里主要是什么。这就像是给图片贴标签,告诉计算机这张图片代表的是什么类别的东西。
比如,你给计算机一张图片,它能够识别出这是一张“狗”的图片,而不是“猫”。或者,它能判断出这是一张“日落”的风景照,而不是“城市街景”。
这个过程就像是我们人类看图说话一样,计算机通过学习大量的图片样本,逐渐学会如何根据图片里的特征来判断图片属于哪个类别。这样,计算机就能像人类一样,对图片进行分类和识别了。

目标检测
目标检测,就是计算机视觉中的一个技术,它能让电脑在图片或者视频里找出我们指定的东西,并且准确地指出这些东西在画面上的哪个位置。这不仅仅是认出图片里有什么,还要能指出这些东西具体在哪儿,就像是给图片里的目标画个小圈圈或者打个小叉叉。

语义分割
就是让计算机能够理解图片中的每一个像素是属于哪个类别的。这就好比是给图片中的每一小块地方都贴上一个标签,告诉电脑这里是天空、那里是建筑物、这边是个人。
语义分割的过程通常包括三个步骤:首先是分类,确定图片中的对象是什么;然后是定位,找到这些对象在图片中的位置;最后是分割,将这些对象从图片中分离出来 。这项技术的核心在于它能够处理像素级别的细节,为每个像素分配一个语义标签,从而实现非常精确的图像理解。
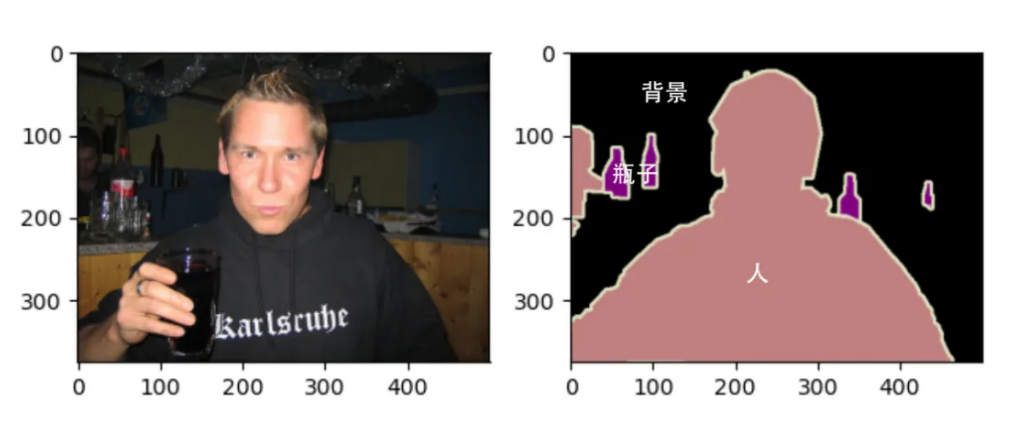
实例分割
实例分割是一种计算机视觉任务,它要求模型不仅要识别出图像中的对象,还要区分对象的不同实例,并对每个实例的每个像素进行标记。这就像是在图像中进行“精细的切割”,不仅要认出图像里都有啥,还要给每个东西都标上名字,哪怕是长得差不多的东西也得区分开。
实例分割可以看作是目标检测和语义分割的结合体。目标检测负责找出图像中的对象并确定它们的位置,而语义分割则负责识别图像中每个像素的类别。实例分割则更进一步,它不仅要识别出每个像素的类别,还要区分出同一类别中不同的实例。

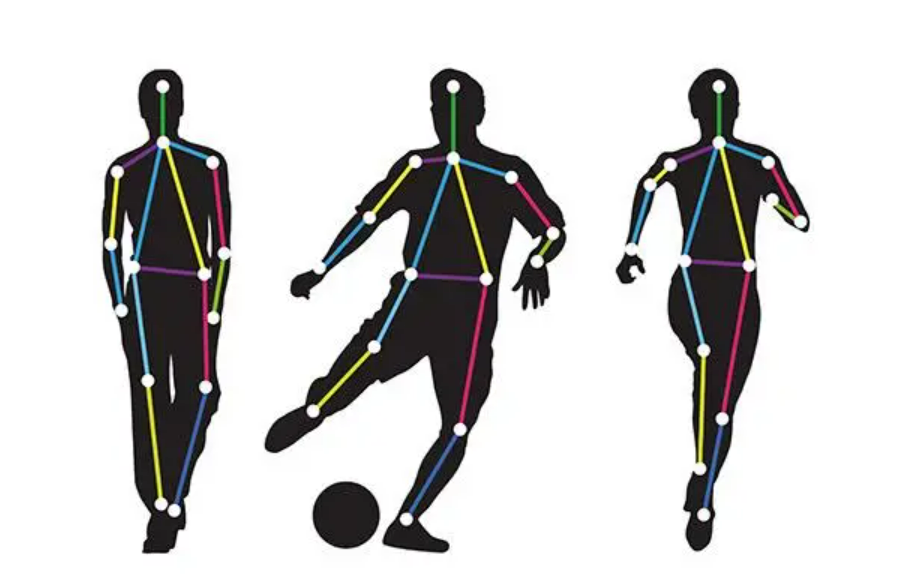
人体关键点检测
就是用电脑来识别图片或视频里人的身体上特定的点,比如肩膀、肘部、手腕、髋关节、膝盖和脚踝这些部位。这些点就像是人体的“关节”,它们在人体动作中扮演着重要的角色。
场景文字识别
就像是给电脑装上了一双能看懂文字的眼睛,让电脑能够在照片或者视频里识别出文字,不管是路标上的指示牌、书籍的封面,还是菜单上的文字,电脑都能把它们“看”懂,并且转换成电子文本。
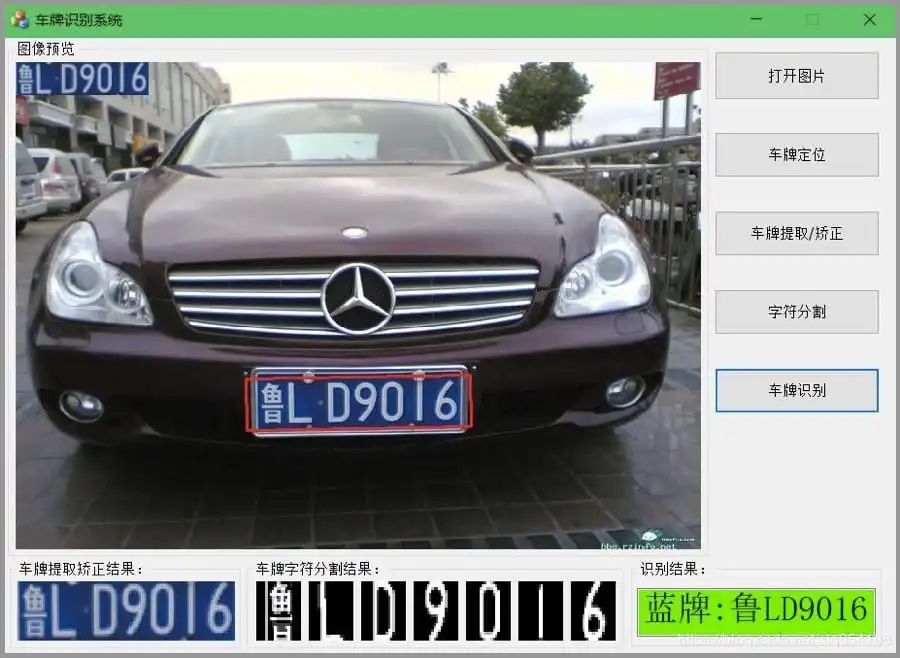
目标跟踪
目标跟踪就是让计算机能够锁定这个人或车,不管他们怎么动,电脑都能在每一帧画面里找到他们,就像用鼠标点着他们不放一样。
在体育比赛中,可以用来追踪运动员的动作;在交通监控中,可以跟踪车辆的流动;或者在电影制作中,可以用来制作特效,让电脑生成的图像能够跟着真实的演员或物体移动。

如上文所见,计算机视觉确实是人工智能领域中一个非常关键的分支,我们生活在一个视觉信息爆炸的时代,照片、视频无处不在,能够从这些数据中提取有用信息的技术当然非常有价值。计算机视觉CV岗,也是招聘网站人工智能算法工程师最热门的一个招聘方向。你可能已经在想:“听着是不错,但我怎么才能掌握这门技术并把它应用于实际工作中呢?”这就是我们推出人工智能课程的原因,就是想帮你把这高大上的知识,变成你手里实实在在的技能。
五、计算机视觉体系化学习路线图
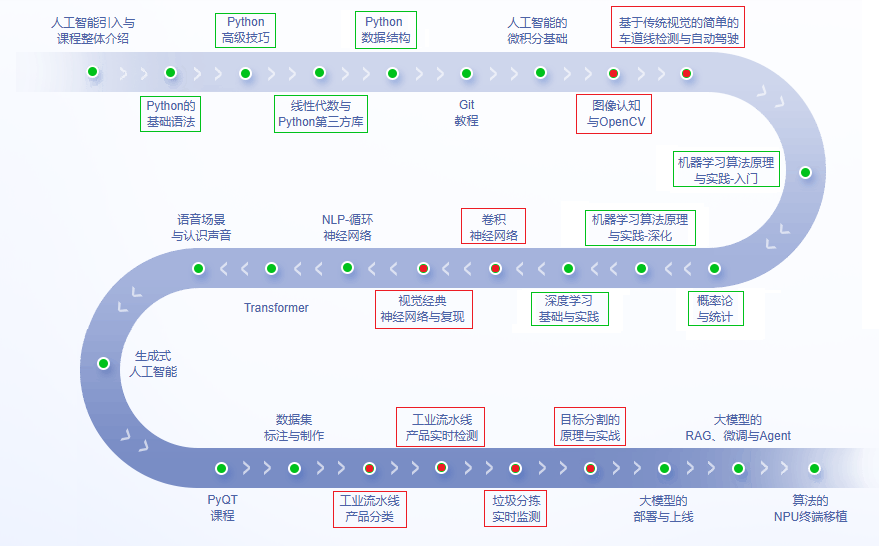
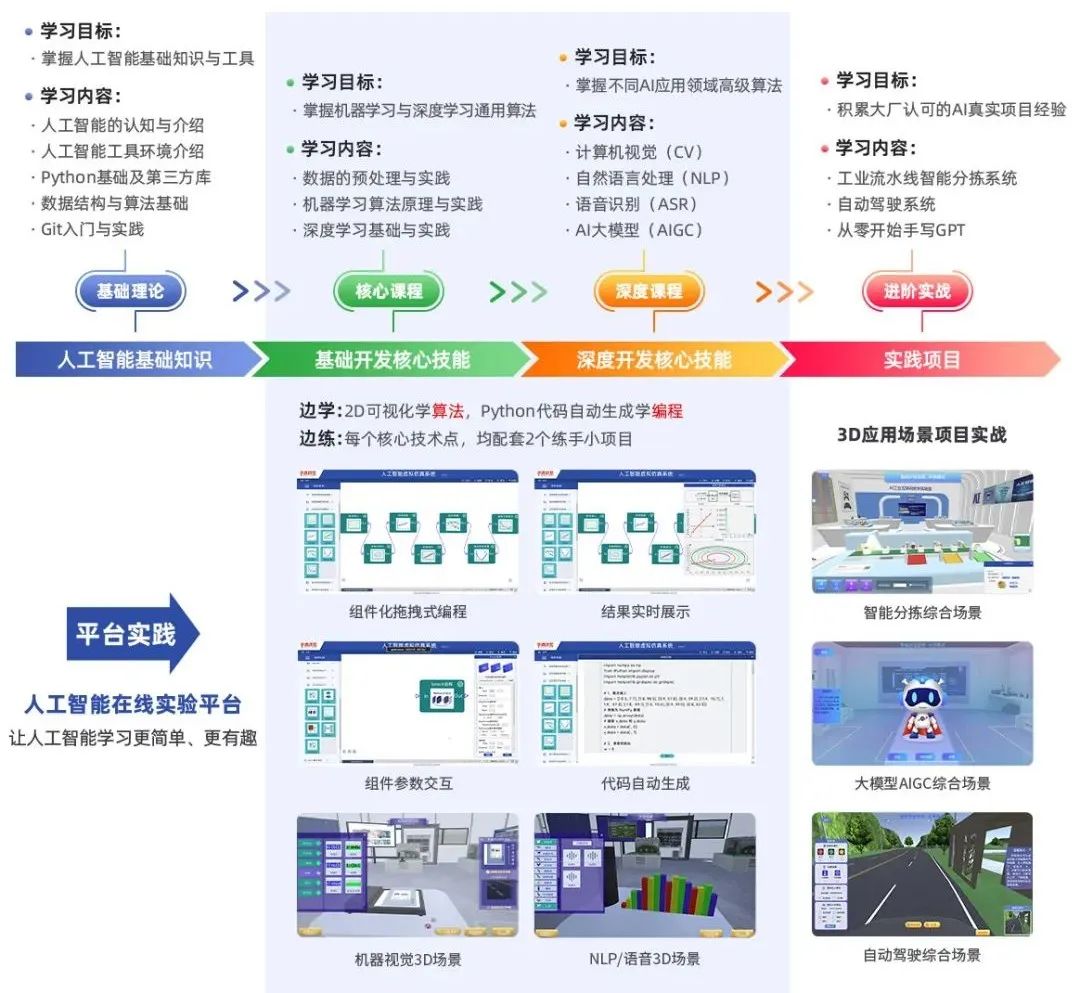
下图是华清远见整个人工智能体系课的学习路径,主要包括前期的基础课程、机器学习和深度学习的通用算法课程、不同AI应用领域的高级算法课程(包括计算机视觉、自然语言处理、大模型等)及综合项目实战课程。整体全体系课程是面向企业招聘,覆盖了90%AI岗位技能。
对于想学习计算机视觉的同学,可以重点学习下图红框和绿框的课程内容,其中红框部分是计算机视觉相关核心技术点,绿框部分是学习计算机视觉之前需要掌握的一些基础知识。按照下图顺序,即可完成计算机视觉从零基础入门到项目实战的完整学习。
所以我们的计算机视觉人工智能课程从基础课程+核心课程+项目课程出发详细讲解,通过算法原理讲解+编程代码实现+项目案例实战的优势,帮助学生真正掌握计算机视觉技术。
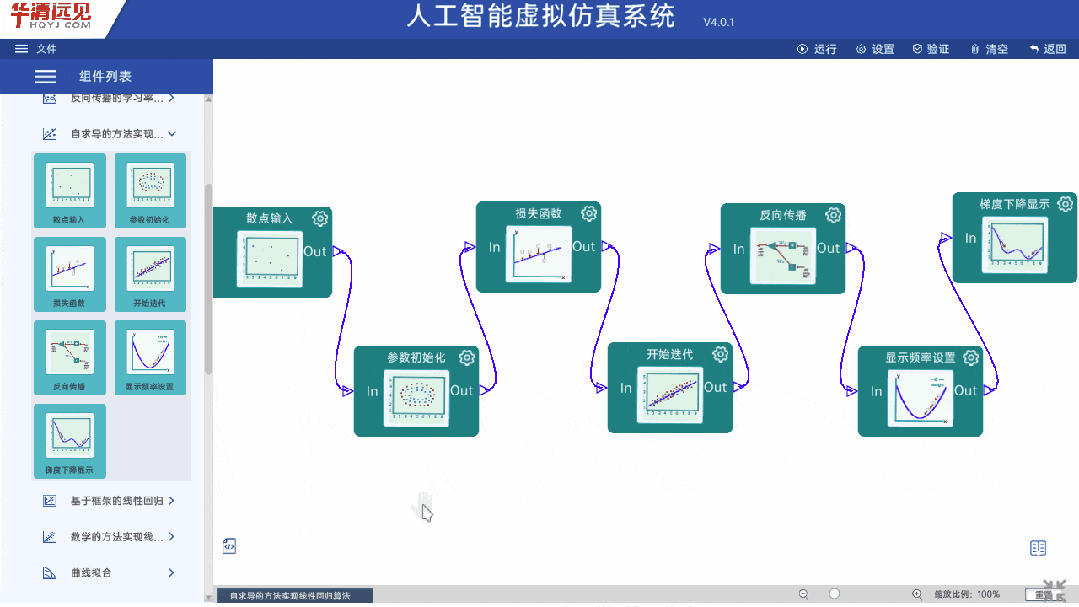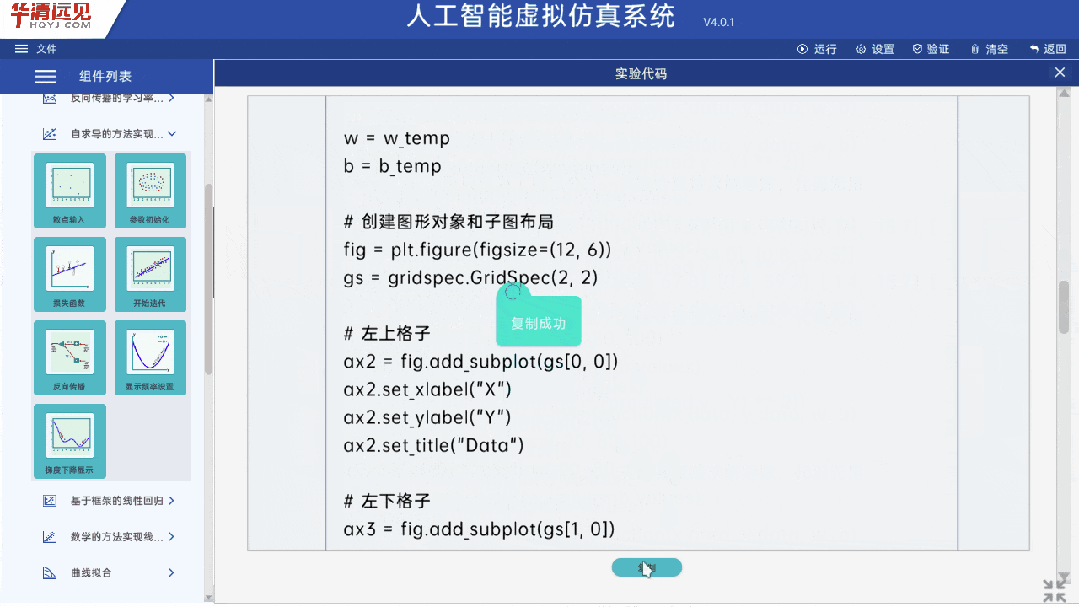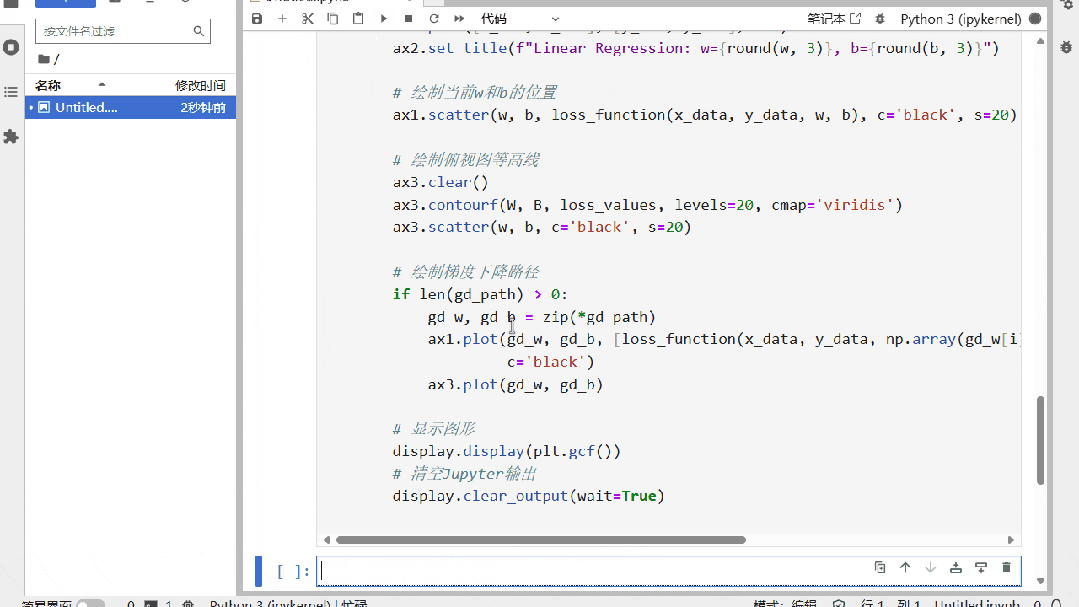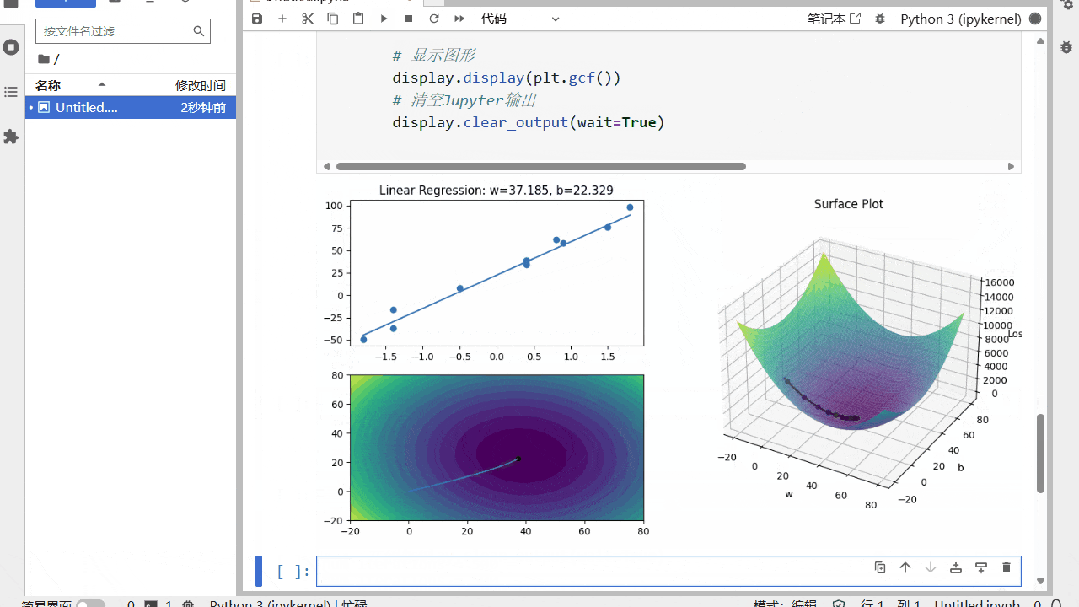
算法原理讲解部分,不同于普遍机构只拿PPT讲解或者单方面动画展示,我们采用图形化交互的方式,将复杂的算法逻辑转化为直观的图像和交互式模型,把算法分解成组件,随意拖动,更改参数,直观“看到”算法的工作原理和过程,真正的讲透、讲懂。让晦涩难懂的算法原理,变得简单易学!

代码讲解部分,有的机构课程,代码编程部分讲的很少,而我们会为每个算法都搭配对应的程序源码,一行一行带你学代码编程。同时我们通过自动生成Python代码的方式来辅助教学,根据实际需求随时生成和讲解代码,动态调整参数,展示代码的可视化变化,理解算法逻辑如何转化为实际代码,并提高学生的编程实践能力,让望而却步的代码编程,变得简单易学活用。
项目案例部分,很多机构课程就是在自己电脑上跑跑,我们会针对每个技术点搭配小项目,让你边学边练。还有3D大型综合场景项目,每个场景里集成了多种算法,项目里每个涉及到的算法都可以单独调试学习,边玩边学,这样就能更深入地理解每个算法是怎么工作的。

华清远见深耕人工智能领域多年,花了3年时间精心打磨的人工智能在线实验平台,实打实解决了学生学习人工智能算法难、编程难、应用场景难三大痛点,大大降低了人工智能教学的难度,使得学生能够在一个高效的环境中学习AI,实现了教育体系与产业实践的无缝对接,有效培养了符合现代产业发展需求的人工智能人才。
可视化的理论教学+支持实操的学习平台+多年行业沉淀的公司,帮助你全面掌握计算机视觉知识,给职业生涯多一份技术保障!
AI体系化学习路线
学习资料免费领
• AI全体系学习路线超详版
• AI体验卡(AI实验平台体验权限)
• 100余讲AI视频课程
• 项目源码《从零开始训练与部署YOLOV8》
• 170余篇AI经典论文