1. 概览
数据并行(Data Parallelism):在不同的GPU上运行同一批数据的不同子集;
流水并行(Pipeline Parallelism):在不同的GPU上运行模型的不同层;
模型并行(Model Parallelism):将单个数学运算(如矩阵乘法)拆分到不同的GPU上运行;
数据并行参考:
《训练中的数据并行DP详细讲解》
流水线并行参考:
《流水线并行(Pipeline Parallelism)原理详解》
模型并行(Model Parallelism)是一种将深度学习模型的不同部分分布到多个计算设备(如GPU)上的技术,以提高训练和推理的效率。模型并行特别适合于大型模型,因为这些模型的参数可能超出单个设备的内存容量。
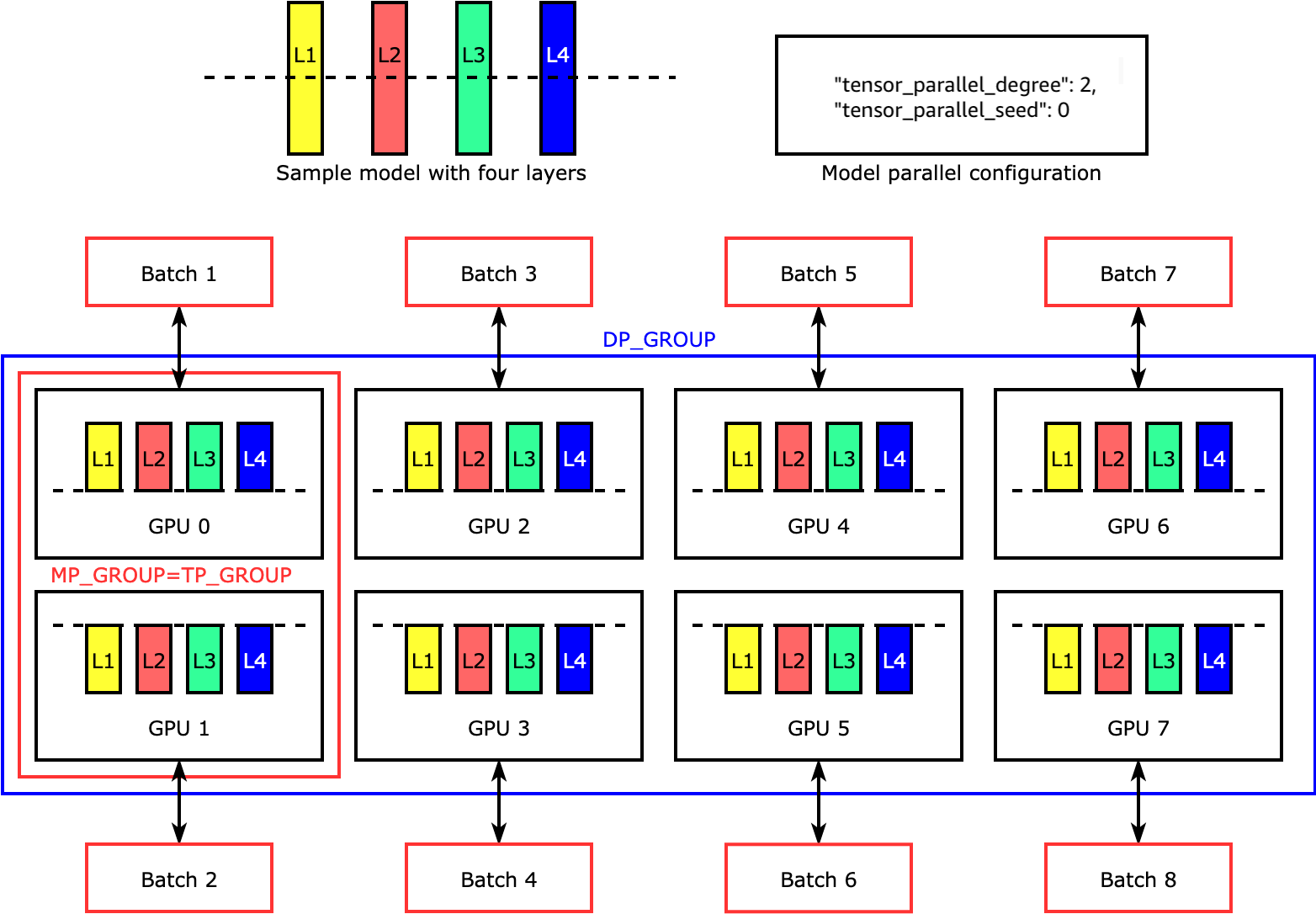
2. 张量并行
张量并行(Tensor Parallelism)最初在 Megatron-LM 论文中提出的,它是一种训练大规模 Transformer 模型的有效模型并行技术。 张量并行是一种模型并行,其中特定模型权重、梯度和优化器状态在设备之间进行分割。
在张量并行中,每个 GPU 仅处理张量的一部分,并且仅为需要整个张量的操作聚合整个张量。

2.1 列划分
将 A 矩阵垂直化为 n 列,则 X 与 A 的矩阵的乘法可以转换为:
X A = X ∣ A 1 , A 2 , . . . , A n ∣ = ∣ X A 1 , X A 2 , . . . , X A n ∣ XA=X|A_1,A_2,...,A_n|=|XA_1,XA_2,...,XA_n| XA=X∣A1,A2,...,An∣=∣XA1,XA2,...,XAn∣
2.2 行划分
对 A 矩阵水平划分为 n 行,则矩阵 X 则需要垂直划分为 n 列,则 X 与 A 的矩阵的乘法可以转换为:
X A = ∣ X 1 , X 2 , . . . , X n ∣ ∣ A 1 , A 2 , . . . , A n ∣ T = X 1 A 1 + X 2 A 2 + . . . + X n A n XA=|X_1,X_2,...,X_n||A_1,A_2,...,A_n|^T=X_1A_1+X_2A_2+...+X_nA_n XA=∣X1,X2,...,Xn∣∣A1,A2,...,An∣T=X1A1+X2A2+...+XnAn
利用这一原理,我们可以更新任意深度的 MLP,而无需 GPU 之间进行任何同步:

并行化多头注意力层因为它们具有多个独立的头,本质上已经是并行的!
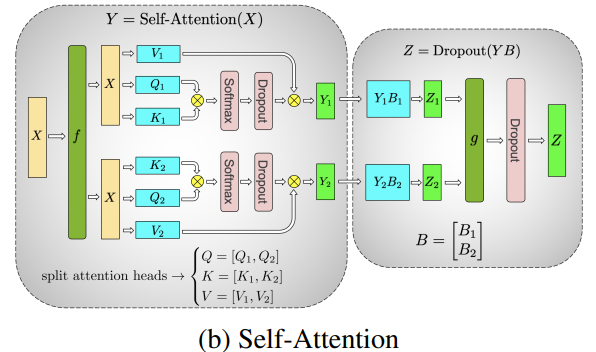
图中表示 Transformer 模型的 MLP 和 Self-Attention 层上 Tensor Parallel 样式的分片,其中 Self-Attention/MLP 中的矩阵乘法通过分片计算进行。
3. 总结
应用场景
- 超大规模模型:当模型的参数量非常大(例如,数十亿参数)时,单个设备无法承载,模型并行能够帮助解决这个问题。
- 复杂模型结构:某些模型的结构可能使得模型并行成为一种合理的选择,例如分层的卷积神经网络(CNN)或变压器(Transformer)模型。
优点
-
能够处理超大规模模型。
-
提高计算资源的利用率。
缺点
-
增加了实现的复杂性。
-
可能导致较高的通信延迟,影响性能。
模型并行是一种重要的技术,特别是在处理复杂和大型深度学习模型时。通过合理地划分模型并优化设备之间的通信,可以显著提高训练和推理的效率。
参考
[1] https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-intro-v2.html
[2] https://siboehm.com/articles/22/pipeline-parallel-training
[3] https://pytorch.org/tutorials/intermediate/TP_tutorial.html
[4] https://huggingface.co/docs/transformers/v4.15.0/parallelism
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤
