文章目录
1. 概述
数据并行(Data Parallelism)是将相同的模型副本放在多个设备上,并将训练数据划分为不同的批次,每个设备处理一部分数据。每个设备独立地计算前向传播和反向传播,然后在每一轮迭代结束时,设备之间同步梯度并更新模型参数。
-
DP(Data Parallelism):最早的数据并行模式,一般采用参数服务器(Parameters Server)这一编程框架,实际中多用于单机多卡
-
DDP(Distributed Data Parallelism):分布式数据并行,采用 Ring AllReduce 的通讯方式,实际中多用于多机场景
基本思想是将训练数据集拆分到多个 GPU 上,每个 GPU 都维护模型的完整副本。在每次训练迭代期间:
- 数据集被分成小批次,每个批次分配给不同的 GPU。每个 GPU 使用其自己的复制模型独立计算其指定批次的梯度。
- 汇总所有 GPU 的梯度,聚合梯度用于更新所有 GPU 上的模型参数。
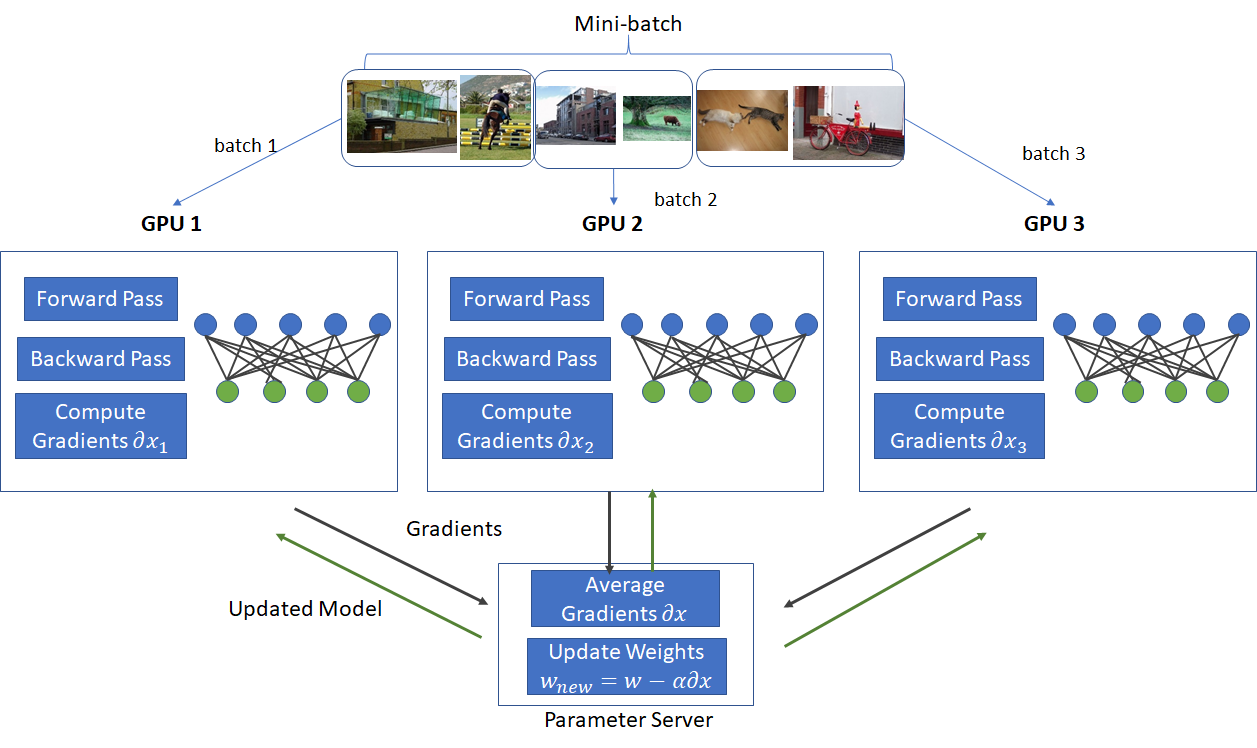
这种方法允许训练随 GPU 数量线性扩展,因为每个 GPU 可以并行处理不同的数据批次。主要优点是,它允许您有效利用多个 GPU 的总内存和计算能力来训练比单个 GPU 更大的模型。
其中,ZeRO-DP 减少内存使用并加速大规模模型的训练,详细讲解请参考:
下面我们看下数据并行如何更新模型状态、参数。
2. 同步与异步更新
2.1 同步更新
同步更新方法中,所有 GPU 的梯度都会被汇总,每次迭代后,模型参数都会在所有 GPU 上同时更新,由于更新是同时应用的,因此模型状态在所有 GPU 上都是同步的,可确保模型状态在所有 GPU 上保持一致。
问题:
如果 GPU 之间的通信速度较慢,则可能会限制训练吞吐量。
2.2 异步更新
异步更新方法中,每个 GPU 都会独立更新其本地模型副本,而无需等待其他 GPU。参数更新会与其他 GPU 异步共享,这可以提高训练吞吐量,但也会导致 GPU 之间的模型状态不一致,可能会影响收敛。
问题: 如果将梯度更新发送到所有其他节点或中央服务器并立即应用,那么就会出现扩展问题。随着 GPU 数量的增加,参数服务器将不可避免地遇到瓶颈。如果没有参数服务器,网络拥塞也会成为问题。即使使用了许多 GPU,我们训练模型的速度也会比预期的要慢。
2.3 异步更新的挑战
选择同步更新还是异步更新通常需要在训练吞吐量和模型收敛之间进行权衡。同步更新通常可实现更稳定的训练,而异步更新速度更快,但可能需要更仔细地调整超参数。
异步更新的关键问题是 GPU 之间模型状态可能不一致。当每个 GPU 独立更新其本地模型副本而不等待其他 GPU 时,可能会导致以下问题:
- 过时:一个 GPU 所做的参数更新可能无法及时传播到其他 GPU。这可能导致某些 GPU 使用与最新更新不同步的“过时”模型参数进行训练。
- 发散:每个 GPU 上的独立更新可能会导致模型参数发散,从而导致副本之间的内部状态不一致。这可能会对模型收敛到稳定解决方案的能力产生负面影响。
- 瓶颈:正如您所指出的,如果没有中央参数服务器,则需要通过分布式网络传达参数更新,这可能会导致拥塞并成为性能瓶颈,尤其是在 GPU 数量增加的情况下。
但是,AllReduce 可以有效地处理这个问题。其中,Ring-AllReduce 是一种称为的去中心化异步算法 AllReduce,Ring-AllReduce 以有向单向环的形式组织节点。
3. AllReduce 的工作原理
AllReduce 是一种常用的分布式计算中的通信模式,尤其在并行计算和深度学习训练中非常关键。它是一个集体通信操作,意味着所有的参与进程都会执行相同的操作,并且每个进程最终都会得到相同的结果。AllReduce 的主要目的是将所有参与节点的数据聚合起来,并将聚合后的结果广播回所有的节点。
AllReduce 的基本步骤:
-
Reduce(归约):在这个阶段,每个参与节点贡献一部分数据(通常是某个局部计算的结果)。这些数据会被收集起来,并通过某种归约运算(比如求和、取平均、最大值、最小值等)合并成一个全局结果。
-
Broadcast(广播):在完成归约之后,所有参与节点都会接收到这个全局结果,从而确保每个节点都拥有相同的最终数据。
下面 AllReduce 工作图:
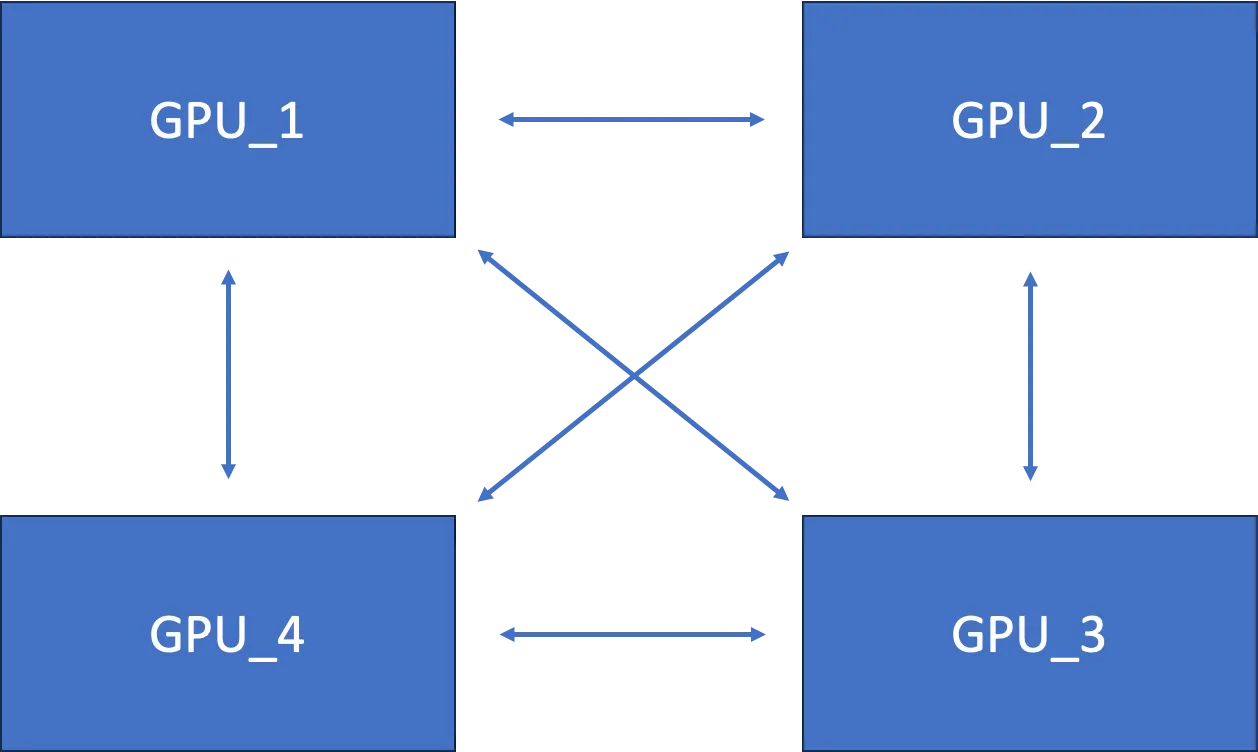
上图算法存在冗余通信
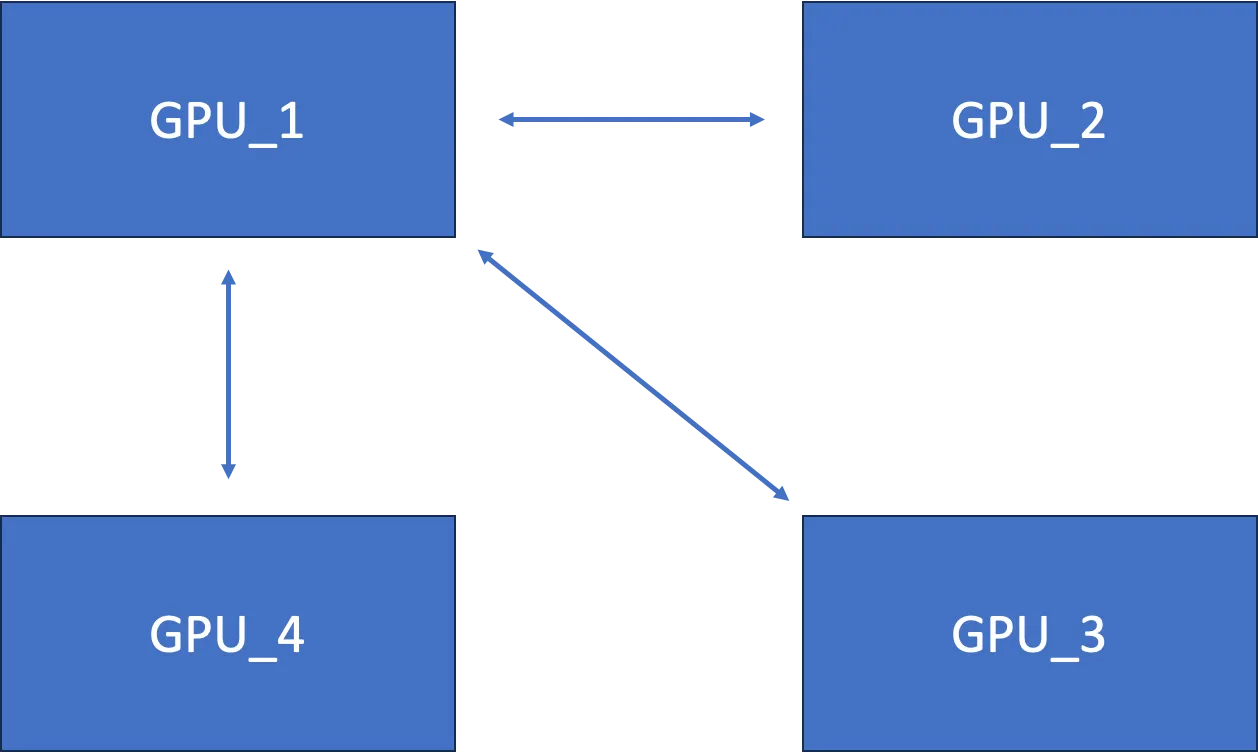
上图算法 GPU_1 随着 GPU 数量的增加而遭遇瓶颈。
4. Ring-AllReduce 的工作原理
尽管 AllReduce 算法存在障碍,但 Ring-AllReduce 为这些挑战提供了一个优雅的解决方案。其主要优点 Ring-AllReduce 是:
- 高效通信:Ring-AllReduce 以环形拓扑结构组织 GPU,允许高效地聚合梯度,每个 GPU 仅需与环中的直接邻居进行通信。
- 去中心化:基于环的通信模式 Ring-AllReduce 消除了对集中式参数服务器的需求。这避免了参数服务器架构可能出现的瓶颈。
- 同步:此类 AllReduce 操作可确保参数更新在所有 GPU 上同步,从而保持一致的模型状态并避免完全异步更新可能出现的分歧问题。
通过使用 Ring-AllReduce,分布式训练系统可以实现异步更新的优势(更快的吞吐量),同时减轻潜在的缺点(不一致的模型状态和发散)。提供的同步 Ring-AllReduce 有助于稳定训练过程并提高收敛性,即使在异步参数更新的情况下也是如此。
Ring-AllReduce 有两个步骤,Scatter-Reduce 和 AllGather。
4.1 Scatter-Reduce
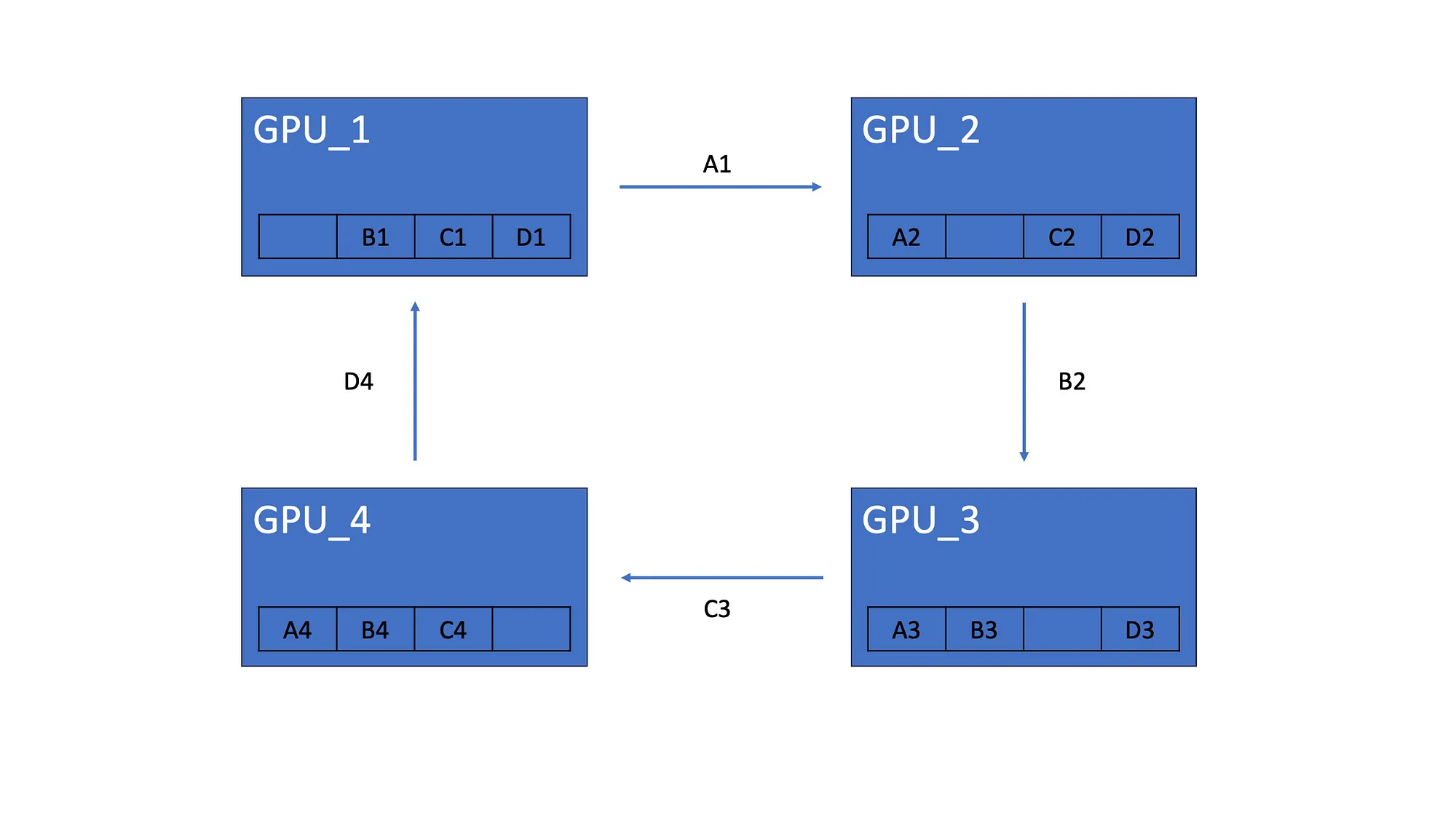
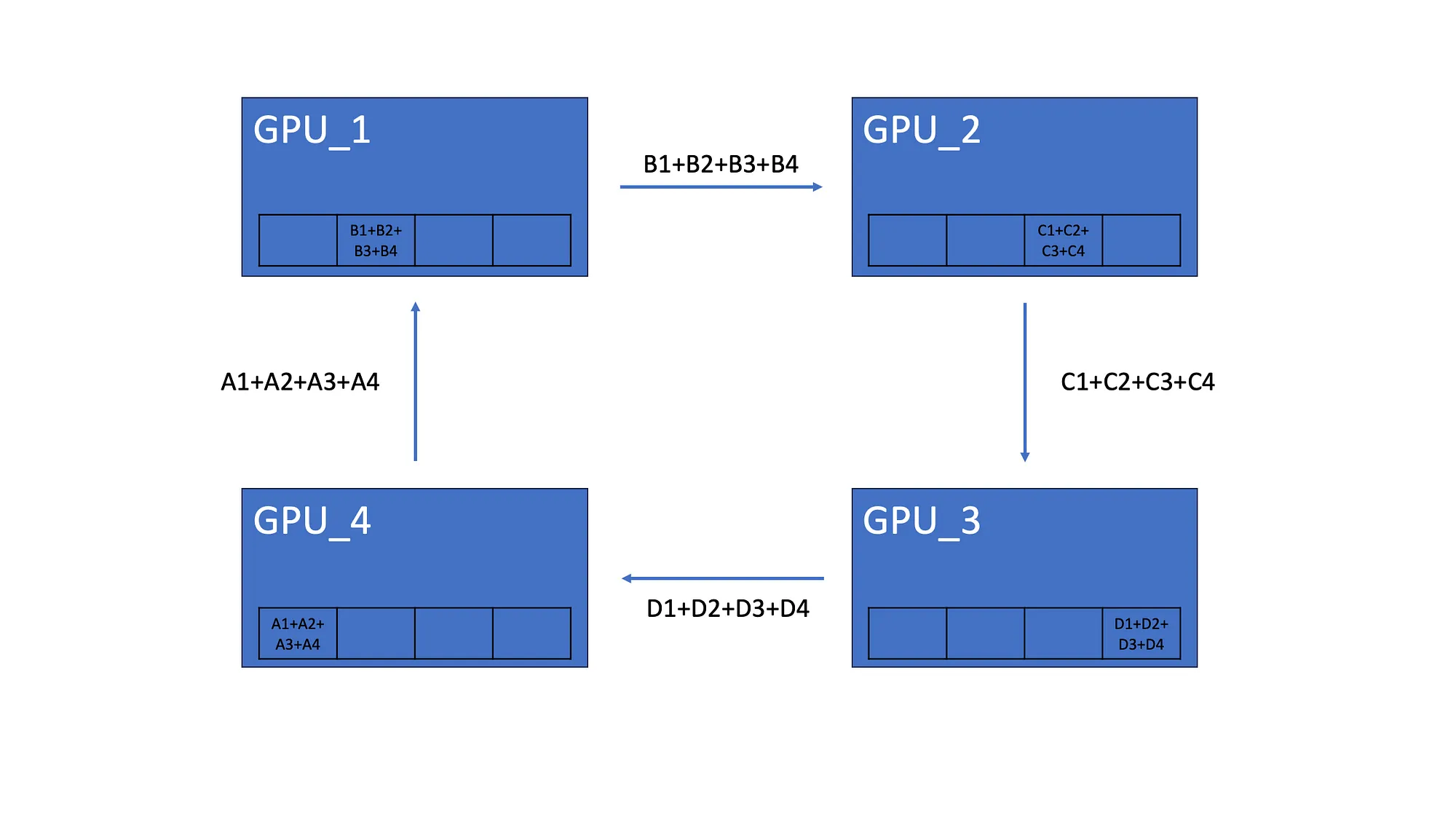
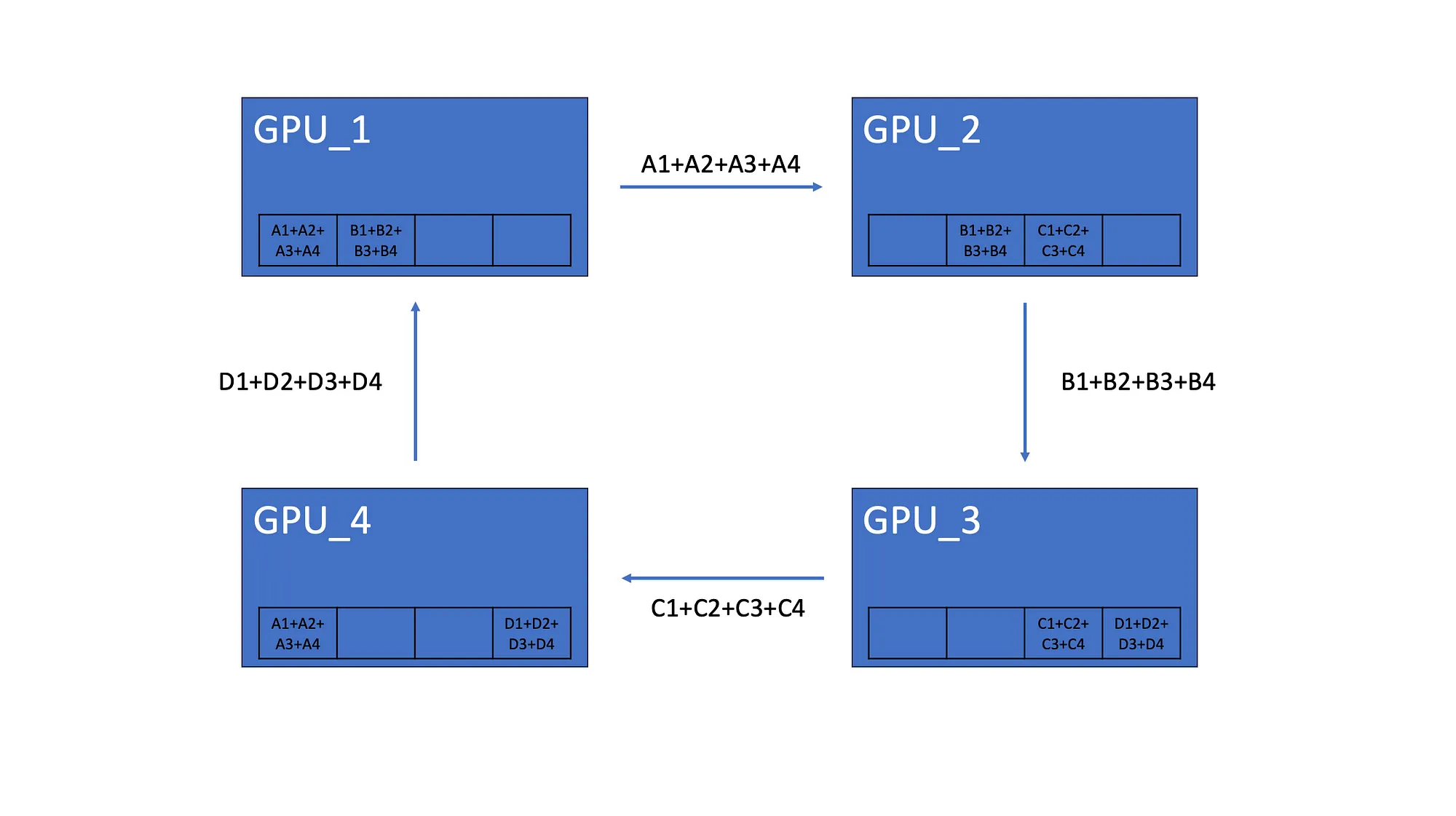
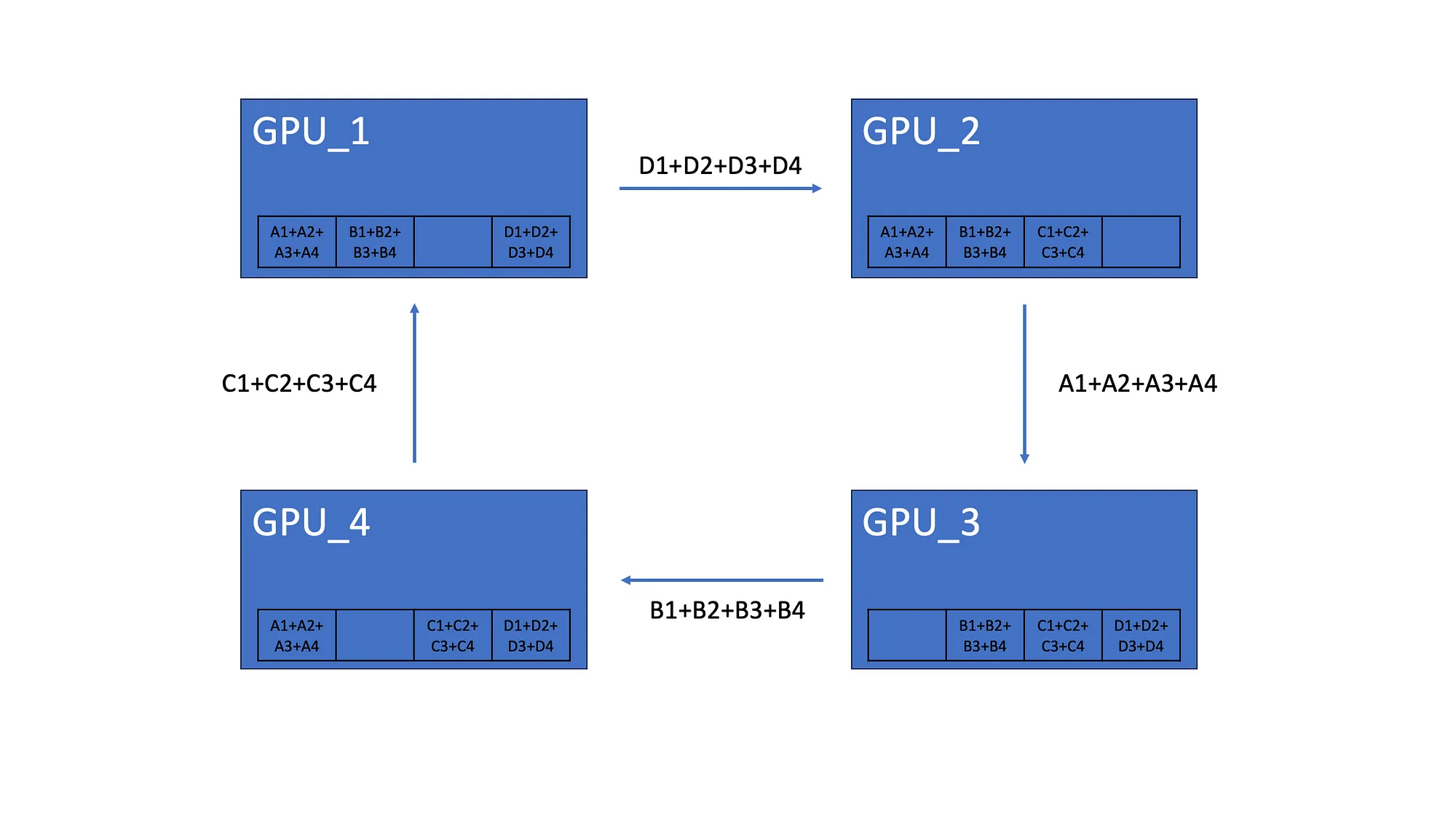
我们假设有 4 个 GPU,每个 GPU 都有相同的模型副本,该模型由 4 个神经元组成。完成梯度计算后,每个模型都有自己的梯度。比如模型的 GPU_1 梯度为 A1、B1、C1、D1:
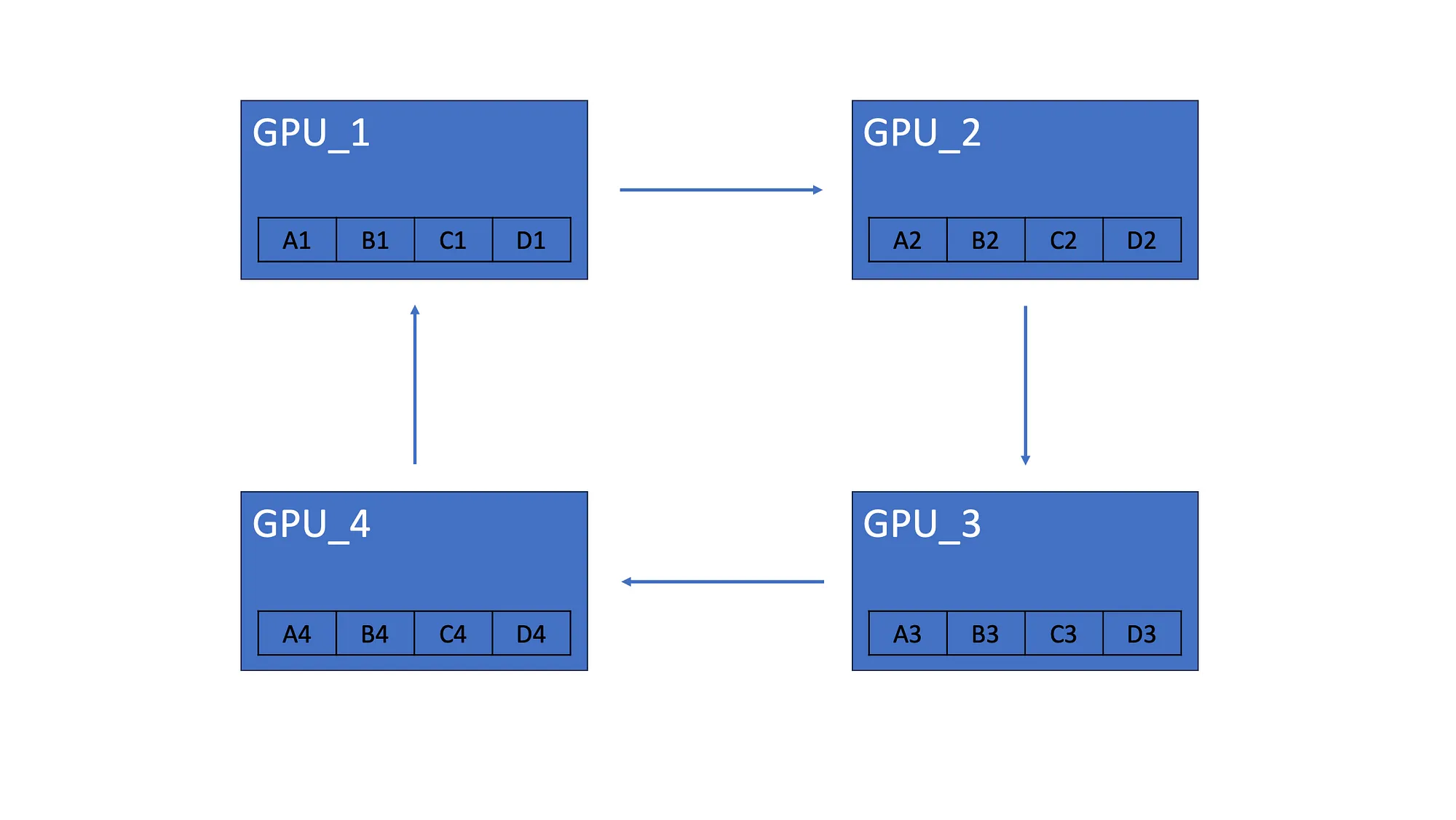
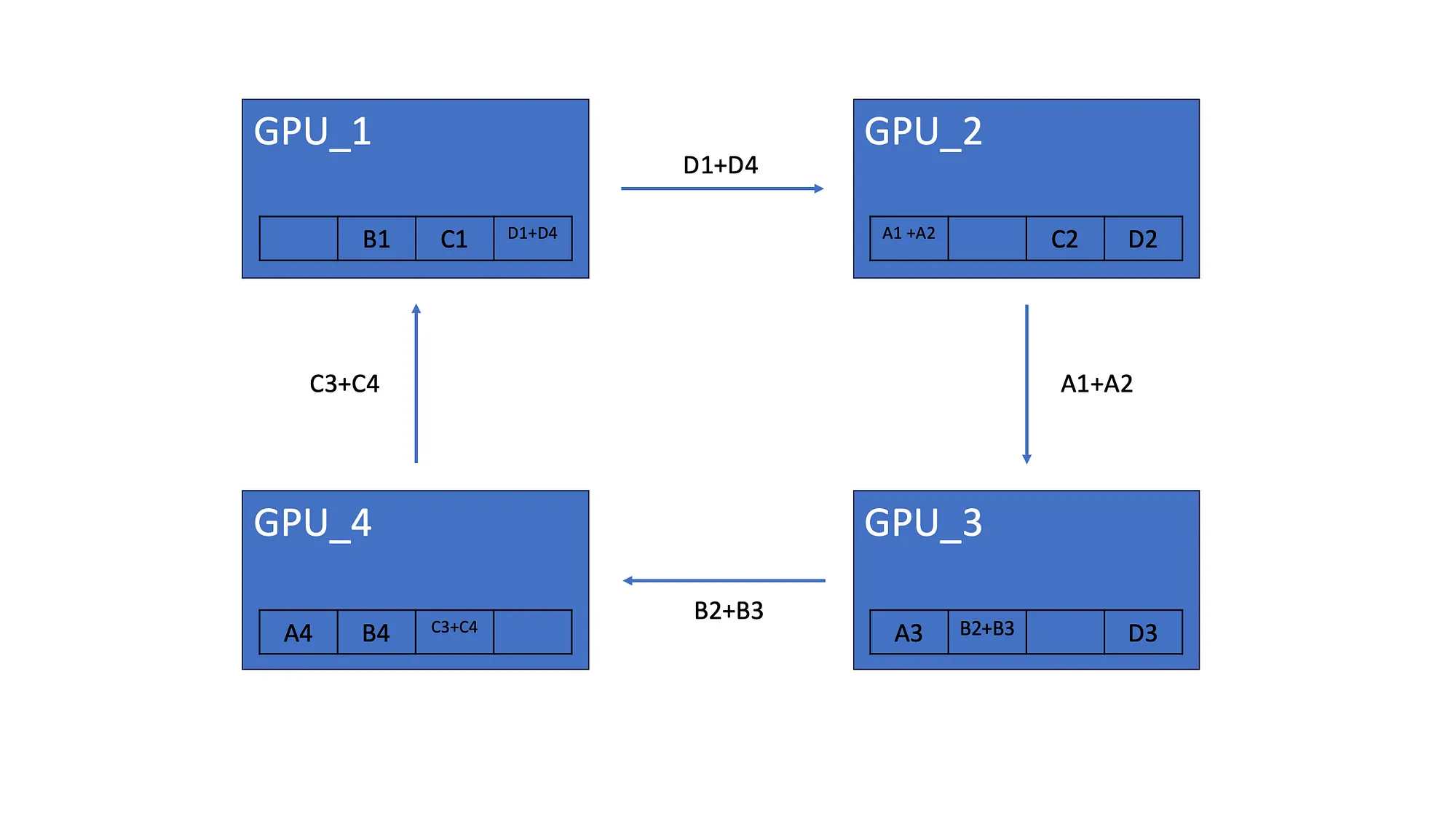
所有 GPU 都会将其梯度的一个元素发送到下一个 GPU。
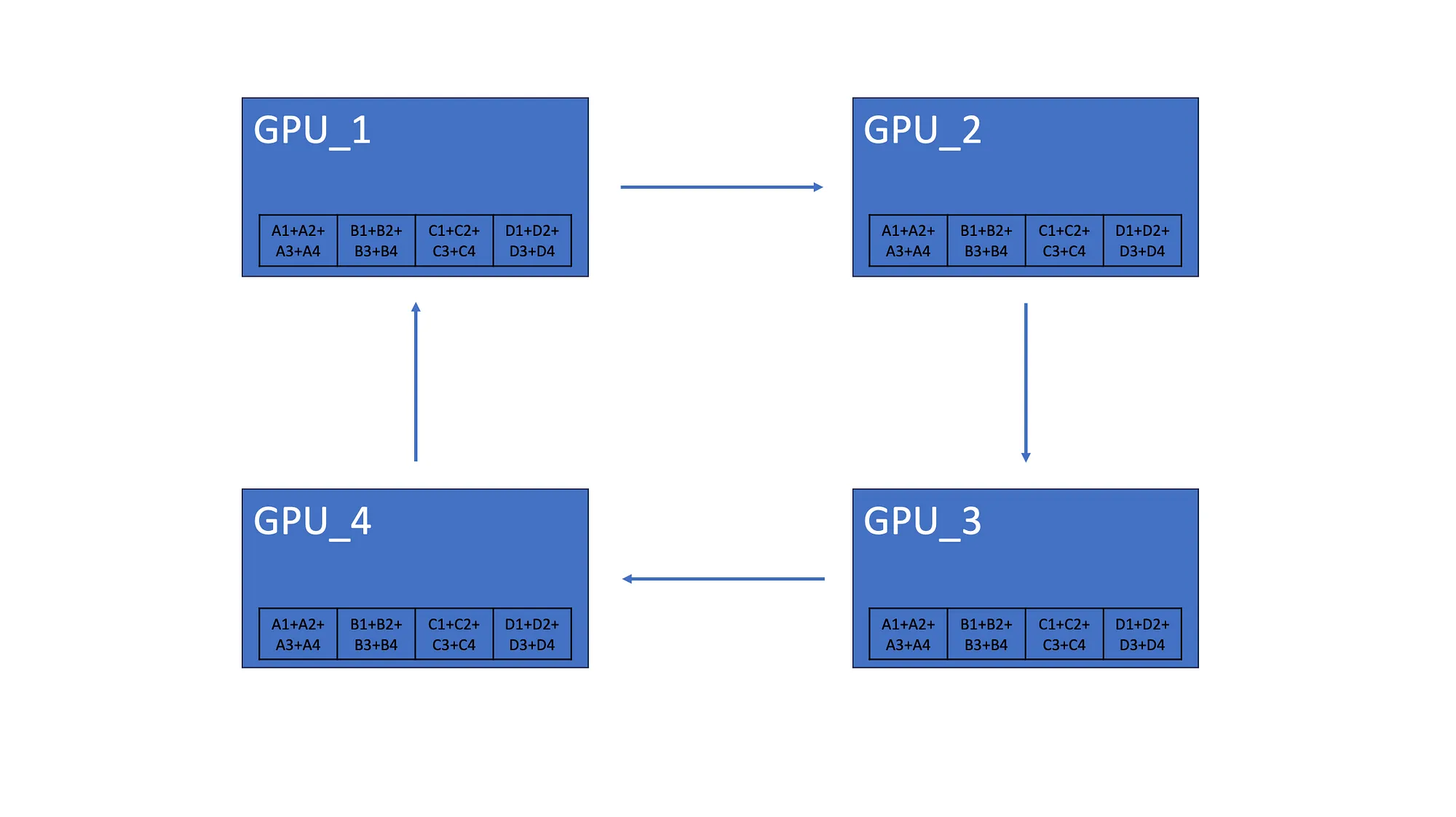
4.2 AllGather
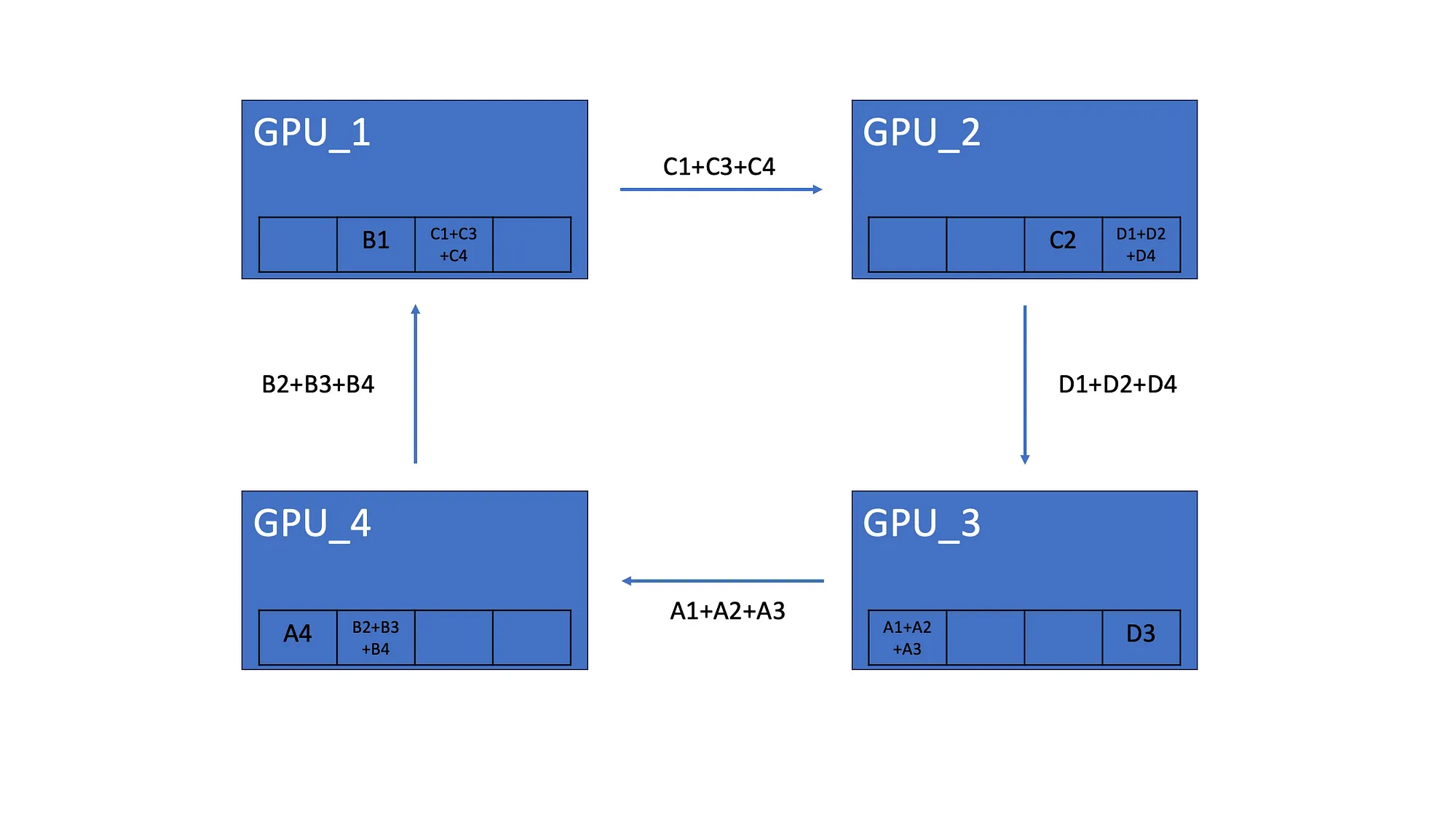
完成后 Scatter-Reduce,每个 GPU 都有分布在所有 GPU 中的梯度元素的总和。如上所示,GPU_1 有来自所有 GPU 的第二个元素的总和。
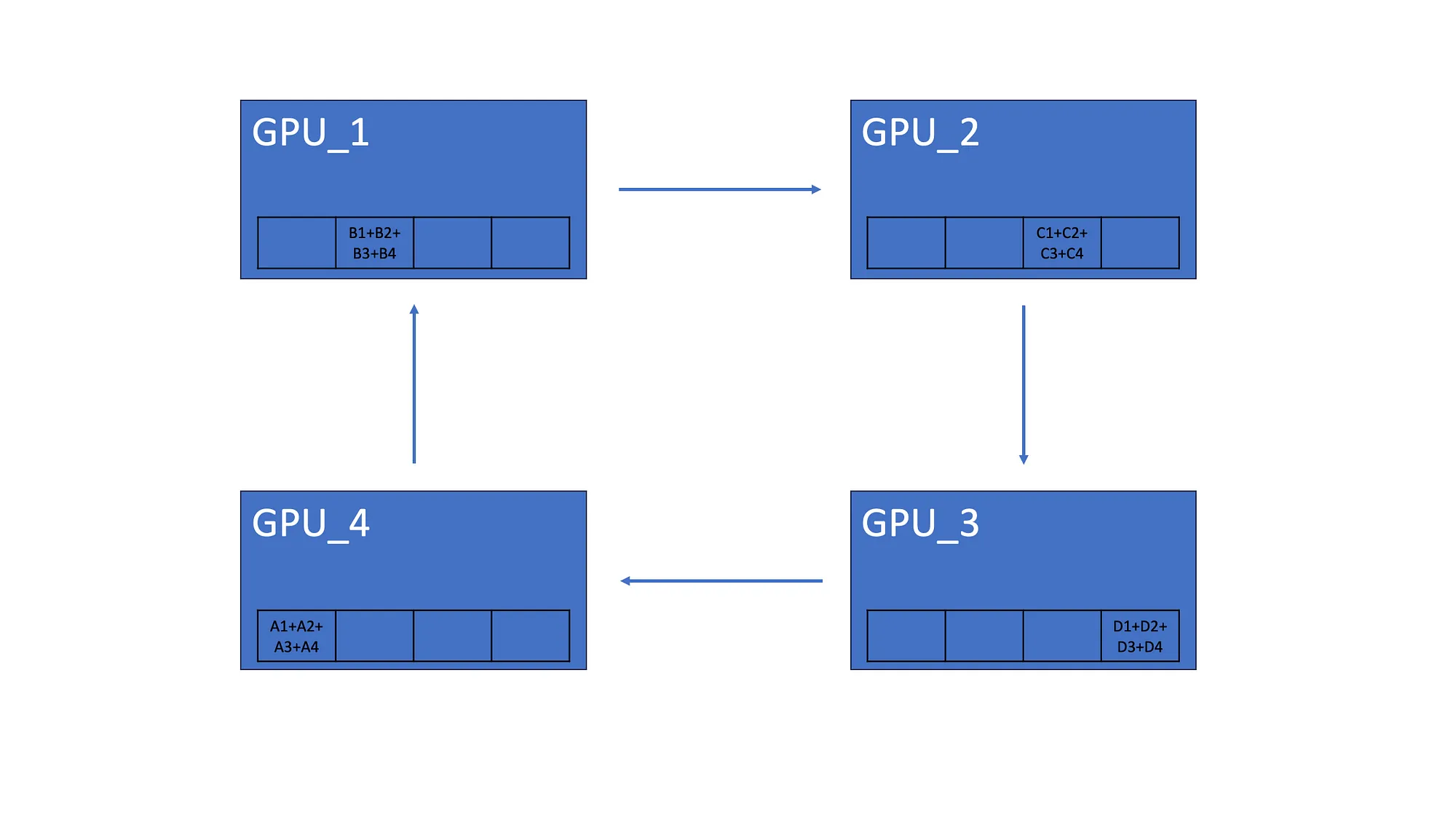
AllGather 让所有 GPU 都具有相同的梯度聚合。因此,第一个 GPU 将其元素总和发送到第二个 GPU。最后,所有 GPU 都具有相同的梯度。
5. 总结
数据并行是分布式训练的核心技术,其中数据集被分成多个 GPU,每个 GPU 都有模型的完整副本,跨 GPU 更新模型状态主要有两种方法:
- 同步更新:在所有 GPU 上聚合梯度并同时更新模型参数
- 异步更新:每个 GPU 独立更新其本地模型,异步共享更新。
异步更新可以提高训练吞吐量,但由于 GPU 之间的模型状态不一致,可能会导致陈旧、发散和瓶颈等问题。
Ring-AllReduce 是一种去中心化异步算法,通过以环形拓扑组织 GPU 来提供有效的解决方案。这允许相邻 GPU 之间进行高效通信,消除对中央参数服务器的需求,并同步参数更新以保持一致的模型状态
Ring-AllReduce 有两个主要步骤。Scatter-Reduce 通过在相邻 GPU 之间传递元素来聚合梯度,AllGather 在所有 GPU 之间共享聚合梯度。
6. 参考
https://medium.com/cloudvillains/data-parallelism-in-machine-learning-training-686ed9ab05fb
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤
