
文章链接:https://arxiv.org/pdf/2409.13648
Github链接:https://authoritywang.github.io/v3/

亮点直击
- 提出 V 3 V^3 V3,一种通过流式传输高质量Gaussian Splatting来支持在普通设备上渲染全息影像的新方法。
- 展示了一种紧凑的动态高斯表示,将高斯属性嵌入到2D高斯视频中,以便于硬件视频编解码器的使用。
- 提出了一种高效的训练策略,通过运动-外观解耦、残差熵损失和时间损失来保持时间连续性。
- 提出了多平台全息影像播放器,支持实时播放和流媒体。
总结速览
解决的问题
当前动态3DGS方法在移动设备上的流媒体播放面临计算和带宽限制,尽管其渲染质量很高。
提出的方案
引入 V 3 V^3 V3(Viewing Volumetric Videos),通过流式传输动态高斯体,实现高质量移动渲染,将动态3DGS视为2D视频,利用硬件视频编解码器。
应用的技术
采用两阶段训练策略:第一阶段使用哈希编码和浅层MLP学习运动,并通过修剪减少高斯数量以满足流媒体要求;第二阶段使用残差熵损失和时间损失微调其他高斯属性以改善时间连续性。
达到的效果
V 3 V^3 V3实现了高质量渲染和流媒体播放,存储需求紧凑,效果超越其他方法。它是首个在移动设备上流式传输动态高斯的方案,用户体验前所未有,包括平滑滚动和即时分享。
V 3 V^3 V3 表示
给定一组多视角的人类表演视频序列,我们的目标是确保所有人都可以在任何设备上、随时随地无缝体验高质量的自由视角视频(FVV)渲染。为了实现这一目标,我们将动态的3D高斯点序列(3DGS)建模为紧凑的二维高斯视频,这种视频自然支持硬件视频编解码器,能够实现高效的流式传输和解码。通过使用基于着色器的渲染,我们能够在各种便携设备上实现高效渲染。
如图2所示,我们将动态的3DGS序列视为多个二维视频。
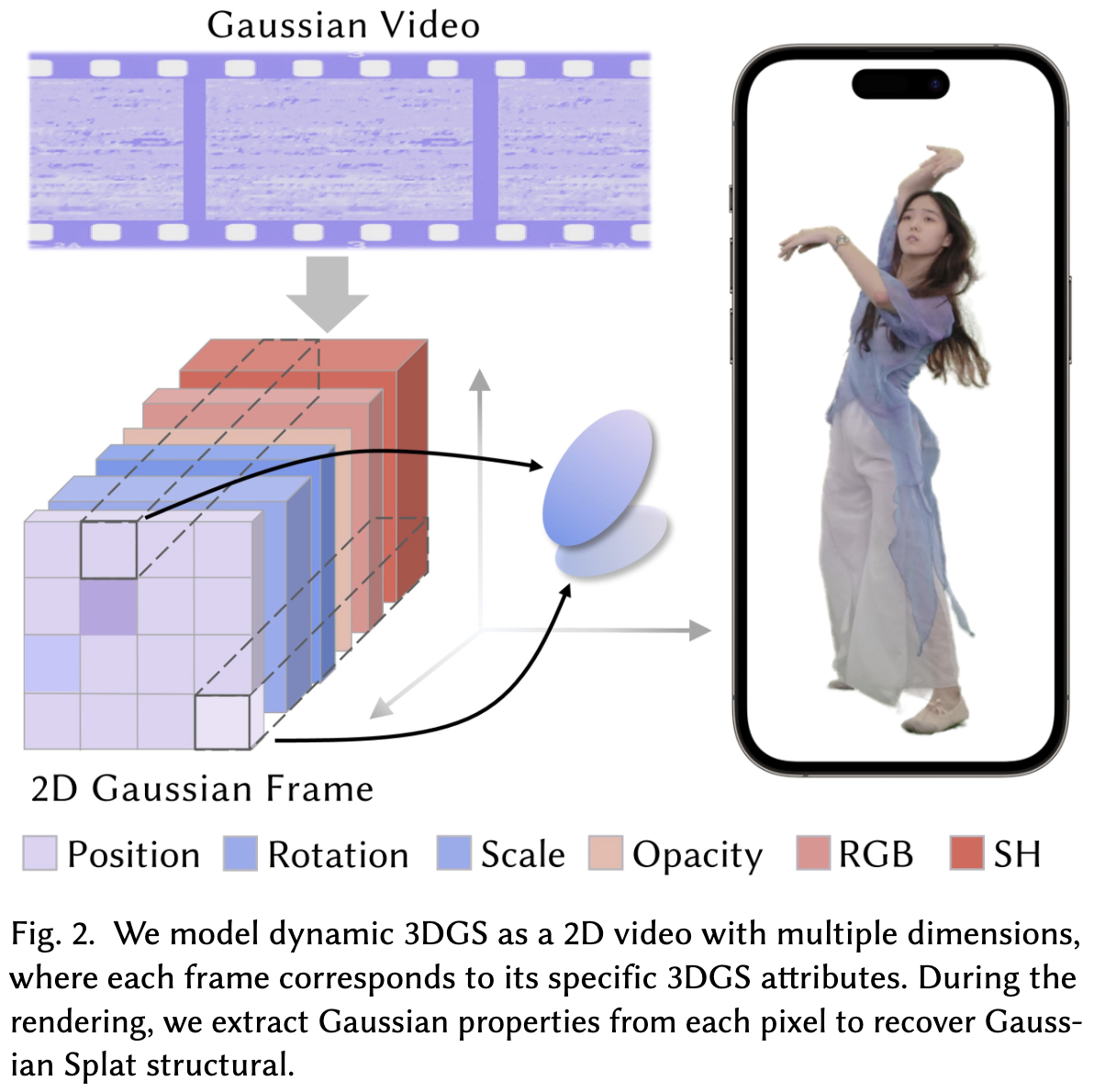
在时间 t t t处,每个高斯点的属性定义为:
- R t :旋转 R_t :旋转 Rt:旋转
- S t :缩放 S_t:缩放 St:缩放
- x t :位置 x_t:位置 xt:位置
- o t :不透明度 o_t:不透明度 ot:不透明度
- c t :颜色 c_t:颜色 ct:颜色
- S H t :球谐函数 SH_t:球谐函数 SHt:球谐函数
3DGS的维度N总数为:
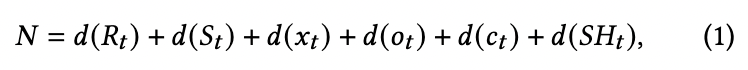
,其中函数 d d d表示特定属性的数量。二维视频的集合可以表示为 V i i = 0 N {V_i}_{i=0}^N Vii=0N,每个二维视频对应于3DGS的单个属性维度。因此,每一帧 I i t I_{it} Iit代表了时间 t t t时的3DGS场景的属性,而不同帧中相同位置的像素值则对应于高斯点的属性值。
在渲染过程中,给定当前帧索引 t t t ,从视频序列中重建当前的3DGS场景。首先,我们从视频中提取二维编码图像${I_{t}i}_{i=0}N ,然后同步遍历所有图像的像素坐标 ,然后同步遍历所有图像的像素坐标 ,然后同步遍历所有图像的像素坐标(u, v)$来构建每个高斯点。以下方程式描述了该过程:

这种方法使得能够在便携设备上高效实时渲染动态3D内容。
这里, I t i I_{t}^i Iti是时间 t t t的二维编码图像, [ u , v ] [u, v] [u,v]是像素坐标中的二维索引,$R_t, S_t, x_t, o_t, c_t, SH_t $ 是时间 t t t高斯点的属性。映射函数 φ \varphi φ 指的是所有图像像素的同步遍历。由于点云是无序的,因此不需要按照特定顺序构建3DGS;我们可以直接按照像素读取顺序构建3DGS,这样可以省去记录映射表的步骤,大大提升了解码速度。
正如3DGS所述,每个高斯点通过投影。

这里, Σ \Sigma Σ, $\Sigma’ $ 是世界坐标和相机坐标下的协方差矩阵。 R R R 是旋转矩阵, S S S 是缩放矩阵, J J J 是投影变换的仿射近似的雅可比矩阵, W W W是视角变换矩阵。通过协方差矩阵,可以获得用于渲染的投影高斯,并且图像平面上像素的颜色可以通过从近到远的N阶高斯的Alpha混合来计算:

其中,计算出的高斯重叠在像素上, c i c_i ci 是每个3D高斯的视角依赖颜色, α i \alpha_i αi 是不透明度乘以3D高斯及其对应的协方差矩阵 Σ ′ \Sigma' Σ′。通过利用我们的二维高斯视频表示,能够在常见设备上以高保真度提供流畅的高斯点流式传输。
V 3 V^3 V3 重建
获取紧凑的 V 3 V^3 V3表示以实现流畅的高质量流媒体传输是具有挑战性的。使用逐帧训练方法会显著增加存储需求,即使经过视频编解码器压缩。这是因为它未考虑相邻帧之间高斯属性的连续性。此外,许多来自前一帧的高斯属性可以重复使用,消除从头开始重新训练的需要。如下图3所示,一种高效的分组训练方案,以生成紧凑的 V 3 V^3 V3表示,同时保持时间一致性。此外,还提出了时间熵损失和时间损失,以进一步增强 V 3 V^3 V3表示的时间连续性。

分组 V 3 V^3 V3训练
给定一系列动态人类表演,将其分成帧组,以支持具有拓扑变换和无限长度的动态场景。为了平衡训练速度和质量,将帧组大小设置为20。在一个帧组中,将第一帧设为关键帧,然后进行静态3DGS重建,并修剪点云以减少存储。对于其余帧,从最后一帧估计运动,然后微调变形模型。通过对每一帧进行顺序优化,可以高效地获得每一帧的时间一致的3DGS模型。
关键帧重建
如下图4所示,在处理每个帧组时,选择第一帧作为关键帧,从NeuS2生成的网格中采样以获取初始点云,并对关键帧进行Gaussian Splatting优化。为了控制存储,将点数限制在100k以下,通过移除低不透明度的点,并根据不透明度对关键帧的喷溅进行排序和修剪。根据compact-SOG,修剪30%最低不透明度的高斯不会影响场景质量。通过迭代修剪和微调属性,可以在保持渲染质量的同时有效控制点的数量。

如下图5所示,应用顺序训练方案,通过运动估计和微调阶段生成后续帧的高斯表示。

快速运动估计
在每个帧组内,致力于保持最终烘焙的2D高斯视频的时间连续性,以实现紧凑存储。为此,旨在将相同表面的高斯原语映射到不同帧的相同编码像素位置,使用哈希编码和浅层MLP快速建模高斯原语随时间的位置信息变化。通过这种方法,确保不同帧之间高斯原语的数量恒定,尽管高斯密集化和修剪可以处理动态场景的外观变化,但可能会导致运动估计的丢失,从而引入抖动伪影。
使用多分辨率哈希网格和浅层MLP来估计每个高斯原语的位置变化。给定分辨率级别为L的哈希网格,可以得到其哈希编码为:

然后,通过一个称为MLP的浅层神经网络,可以高效地估计运动,方法为:

给定帧 t-1 的位置 x 及其多分辨率 h ( x t − 1 ) h(x_{t-1}) h(xt−1),可以通过 x t = x t − 1 + Δ x x_t = x_{t-1} + \Delta x xt=xt−1+Δx 来获得帧 t 的位置。遵循3DGS,这一阶段每帧的损失函数依次为:

其中 λ = 0.2 \lambda = 0.2 λ=0.2。通过这种方式,可以在几秒钟内估计两个帧之间的位置变化,显著减少训练时间并最小化冗余的重新训练。同时,可以生成跨帧的Gaussian Splatting之间的对应关系,减少帧之间的属性差异,从而实现更好的压缩。
时间正则化
为了压缩 V 3 V^3 V3表示,使用视频编解码器将帧之间的残差存储在比特流中。在微调阶段,引入了一个时间损失,以增强时间连续性,从而减少帧之间高斯属性的残差。同时,受到[Chen et al. 2024; Zhang et al. 2024]的启发,在残差上应用了熵损失,旨在表现出低熵特性,使帧之间的残差对量化具有更强的鲁棒性。
残差熵损失
在熵编码过程中,数据根据其出现频率进行编码,频繁出现的值会用更少的位表示。熵损失的目标是将数据推向其分布中心,从而增加重复值的概率,最终减少存储需求。这种方法通过最小化熵来增强数据的可压缩性。
为此,研究者使用了一个损失函数来约束数据的分布。根据统计分析(如下图6所示),帧之间的旋转、缩放、不透明度和球面谐波的残差大致呈现高斯分布。因此,假设这些属性遵循高斯分布,并引入各自可学习的均值 μ \mu μ和标准差 σ \sigma σ。

具体来说,让 y y y 代表其中一个高斯属性, y t ∈ [ R t , S t , o t , c t , S H t ] y_t \in [R_t, S_t, o_t, c_t, SH_t] yt∈[Rt,St,ot,ct,SHt], q i q_i qi 是不同高斯属性的量化区域,可以计算量化残差为:
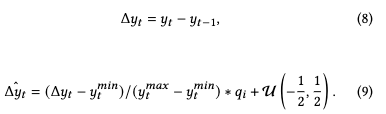
其中 U ( − 1 2 , 1 2 ) U(-\frac1 2, \frac 1 2) U(−21,21) 是对残差的随机均匀噪声,用于模拟舍入操作,从而增强参数对量化的鲁棒性。可以通过计算两个累积分布函数(CDF)之间的差异来近似残差的概率质量函数(PMF),公式如下:

因此,熵损失计算为比特消耗的总和,公式如下:

其中 N N N 是Gaussian Splatting的数量。通过这种方式,每个高斯属性的残差值更接近其正态分布的中心,从而减少时间熵,使 V 3 V^3 V3对量化具有鲁棒性,即使在低比特率下也能保持高质量。
时间损失
为了进一步提高 V 3 V^3 V3的时间一致性,应用时间损失来最小化微调阶段相邻帧之间的差异。在顺序训练过程中,通过使用前一个高斯图像的属性来规范当前高斯图像,从而提高帧间相似性,公式如下:

其中 W W W 和 H H H 是高斯视频的宽度和高度, p p p 是旋转、缩放、不透明度、颜色和球面谐波维度上的像素值。通过以这种方式应用时间平滑,可以进一步减少视频编码过程中的残差,从而节省存储。
总损失
在微调阶段,针对每一帧的总损失函数被公式化如下:

其中 λ e \lambda_e λe 和 λ t \lambda_t λt 是正则项的权重。
将3D高斯转成2D格式
为了利用视频编解码器进行压缩和流传输,需要将高斯数据转换为2D格式。由于点云具有无序和无结构的特性,和VideoRF中使用的体素网格表示不同,这一过程不需要存储2D到3D的映射表来重建3D空间结构。相反,只需确保同一高斯的不同属性在不同图像中存储在相同的索引位置,这样便可以轻松重建点云结构,而无需额外的存储空间来保存对应关系。
量化位设置
由于高斯对点云的位置非常敏感,研究者们需要更精确的位置数据信息。因此,他们选择对位置属性使用uint16进行量化,而其他属性则使用uint8。由于属性是以uint8 PNG图像的形式存储,位置信息被拆分为两个uint8值,分别表示uint16的高8位和低8位。为了确保精度,研究者们对高位的uint8值进行了无损压缩。
2D编码图像分辨率
为了更好地存储高斯,采用自适应分辨率2D格式。在同一帧组内,高斯的数量在各帧之间保持一致。在进行视频压缩时,以边长为8的2D格式存储高斯更为编解码友好,从而进一步减少存储需求。能够容纳所有高斯的最小正方形2D格式,同时确保正方形的边长是8的倍数,从而最小化空网格空间。这种方法最终导致编解码友好的视频压缩格式。
压缩QP设置
在视频编解码中,压缩对高斯渲染质量的影响因属性而异。在H.264编解码中,研究者们可以调整QP(Q步长)系数以控制压缩率,较高的QP会导致更大的压缩损失和更少的存储需求。他们在实验中逐渐增加目标属性的QP,并监测其他属性的变化,以观察当QP超过某个阈值时渲染质量是否急剧下降。结果表明,当QP超过22时,高斯的RGB、缩放和旋转属性会显著出现压缩损失。
因此,研究者们提出了一种基于阈值的调整策略:当QP小于22时,所有属性都使用相同的QP值进行压缩;当QP超过22时,RGB、缩放和旋转属性则以固定的QP 22进行压缩,而其他属性的QP可以进一步增加。这一策略使得他们能够实现额外的压缩,减少存储需求,同时保持可接受的渲染质量。
Morton排序
受到SOG的启发,使用Morton顺序对点云的位置进行排序,然后将高斯烘焙成2D格式。对于无序的3D高斯点云,将每个点的坐标从浮点数转换为范围为221的整数,然后计算其Morton码并进行排序。由于Morton排序将空间上接近的点映射到2D编码图像上的相邻位置,并且考虑到在3D高斯中相互靠近的点具有相似的属性,Morton排序有效地将相似点靠近放置在图像上,增强了2D编码图像的空间一致性,这更有利于视频编解码处理。
V 3 V^3 V3播放器
多个平台上实现了 V 3 V^3 V3播放器,包括桌面、笔记本和移动设备。对于烘焙的2D高斯,使用FFmpeg利用H.264编码器获取多个2D高斯视频并将其上传到资源服务器。解码过程中,获取高斯视频流并使用OpenCV进行H.264视频的硬件解码,以获得2D高斯图像。
在桌面和笔记本平台上,利用多线程:线程1处理视频获取和解码,线程2对解码后的图像进行逆量化,并将其重建为高斯点云结构以进行渲染。在移动设备上,使用Swift实现查看器,也采用多线程策略。为了最大化硬件资源的利用,使用Metal的计算着色器将图像转换回高斯点云。对于渲染pipeline,使用Metal着色器实现alpha混合,从而消除对CUDA设备的需求,使得跨设备渲染成为可能。
V 3 V^3 V3播放器支持从网络流式传输全息影像和实时解码与渲染,包含自由视角调整、时间轴拖动以及播放/暂停操作等功能。如下图7所示,支持在各种移动设备上自由观看全息影像,随时随地提供身临其境的高质量全息影像观看体验。

实验结果
研究者们评估了 V 3 V^3 V3在多个场景中的重建性能,使用ReRF、Actors-HQ数据集和新捕获的动态数据,帧率为30 fps,分辨率为3840 × 2160,视角为81个。使用单个NVIDIA GeForce RTX3090训练模型。在阶段1中,为哈希网格设置了16个级别和每级4个特征,每层64个神经元和2个隐藏层用于浅层MLP。在阶段2中,将正则项的权重设置为 λ e \lambda_e λe为1e-4, λ t \lambda_t λt为1e-3,适用于所有序列。如下图8所示, V 3 V^3 V3在各种复杂的人类场景中实现了卓越的重建效果。它能够处理复杂的动作,如舞蹈、拳击和动画角色动作。支持实时流式传输,渲染人类中心场景的长序列FVV视频,提供沉浸式人类动态表演观看体验。

比较
将 V 3 V^3 V3与当前最先进的方法进行比较,包括VideoRF、3DGStream、HumanRF和NeuS2。这些方法在Actors-HQ和ReRF数据集上进行评估,比较内容包括渲染质量、训练时间和存储容量。
如下图9所示,基于神经体素网格的VideoRF和NeuS2在细纹理区域产生模糊效果。尽管HumanRF能够表示动态场景,但其细节恢复能力较差。3DGStream 在处理大幅度运动的场景时表现不佳,因为它主要依赖神经变换缓存来获取帧间变换,却未能对前一帧的高斯进行细化,使得处理复杂序列变得困难。此外,每帧需要查询MLP以获取变换,这限制了高效的全息影像流。

相较之下, V 3 V^3 V3在流媒体实时播放的同时,实现了最逼真的人类渲染效果,纹理细节更为清晰,优于其他方法。
定量比较
使用PSNR、SSIM、训练时间和存储大小等指标进行定量比较。在选择比较数据时,选择了包含大幅度运动变换的ReRF数据集和Actors-HQ数据集。在ReRF数据集中,遵循VideoRF中使用的比较方法来评估Kpop场景。对于Actors-HQ数据集,使用论文中描述的测试方法来评估Actor8,序列1。
如下表1和图11所示,本文的方法在两个数据集的质量和存储上均优于其他方法。能够确保在较低存储容量下最小化质量退化。在训练时间方面,本文的方法仅次于3DGStream。值得注意的是,与可流式播放的方法(如VideoRF和3DGStream)相比,本文的方法在保持高质量的同时需求更小的存储空间。此外,本文的方法训练速度更快,更适合处理长序列,从而提高了生产力。


评估
消融研究
研究者们进一步验证了本文方法中各个组件的有效性。定性和定量结果如下图12和图10所示。注意,在图12中,所有图形都是在大约600KB的存储条件下获得的。研究者们分析了残差熵损失、时间损失、基于哈希的运动估计、微调和帧组分段模块的影响。结果表明,如果不使用基于哈希的运动估计,可能会导致几何形状不正确和模糊的外观。经过点云扭曲后,如果不进行微调,某些细节(如衣物纹理)将难以重建。没有帧组分段策略,长序列训练的结果将遭受显著损失。禁用时间损失或残差熵损失会导致视频编解码不友好,从而在相同存储条件下降低质量。


多平台运行时分析
对 V 3 V^3 V3播放器在多个平台上的运行时进行了分析。测试平台包括配备Intel I9-10920X处理器和NVIDIA GeForce RTX 3090 GPU的Ubuntu PC,配备Apple M2处理器的Apple iPad,以及配备A15 Bionic处理器的Apple iPhone。如下表2所示,列出了渲染pipeline每个线程的时间消耗。对于下载线程,所有平台在内部网络设置下大约耗时10毫秒。至于解码线程,桌面的多线程解码结合CUDA内存复制耗时13毫秒。在Apple移动设备上,统一内存架构消除了内存复制的需求,通过计算着色器的并行解码,时间消耗与桌面相当。在渲染线程方面,配备CUDA设备的桌面实现超过400 FPS,而使用Metal的移动设备也能以良好的FPS进行渲染。由于这三个部分异步并行操作,使用渲染时间来计算FPS。设计良好的异步播放pipeline确保实时的全息影像获取、下载和渲染,为各种设备提供沉浸式的全息影像观看体验。

训练运行时分析
研究者们还分析了训练时间和烘焙时间,如下表3所示。关键帧重建,包括从NeuS2生成初始点云、3DGS训练、点云修剪和微调,平均总耗时192.6秒。运动估计将训练500次,耗时7.2秒。在微调阶段,将额外进行2000次迭代以优化高斯属性,耗时41.7秒。在一个包含20帧的帧组中,每帧的重建平均耗时56.1秒。烘焙过程,包括属性量化、Morton排序,以及使用FFmpeg进行H.264编码为2D高斯视频,平均每帧仅需0.5秒。由于将帧组大小设置为20,本文的方法可以在一分钟内生成高质量场景,为全息影像的快速生成提供可能。

分组策略
为了探索 V 3 V^3 V3训练的最佳分组策略,在同一数据集上进行了消融研究。考虑到训练和推理的效率,在决定分组策略时,平衡训练时间和存储需求至关重要。由于视频编解码通过减少多个帧之间的冗余来实现压缩,因此随着组长度的增加,每帧的存储需求减少。此外,由于优化关键帧耗时较长,较大的组可以减少每帧的平均训练时间。然而,连续帧之间的变形可能会积累误差,导致后续帧的质量下降。因此,较大的组大小可能会导致渲染质量降低。为了探索最佳组长度,进行了帧组大小为10、15、20、25和30帧的训练。如下图13和表4所示,实验结果表明,虽然随着帧组大小的增加,存储需求减少,但训练时间和渲染质量也会下降。为了在存储效率、训练速度和渲染质量之间取得平衡,选择了20帧的帧组大小进行训练。

结论
V 3 V^3 V3,一种新颖的方法,使得通过2D网格高斯流式传输和观看高质量的全息影像成为可能。创新性地将3D高斯属性烘焙为2D高斯视频流,利用视频编解码器实现高效压缩,然后流式传输到移动设备进行渲染。此外,引入了一种高效的训练策略,采用残差熵损失和时间损失以保持高质量,同时确保时间一致性,并增强视频编码的友好性。实验表明,能够在相对较短的训练时间内实现紧凑且高质量的动态模型。通过这种方法,相信能够在全息影像的移动化方面迈出重要一步,提供前所未有的随时随地流式传输和观看全息影像的体验,支持无缝视频滚动和分享功能。
参考文献
[1] V 3 V^3 V3: Viewing Volumetric Videos on Mobiles via Streamable 2D Dynamic Gaussians