小罗碎碎念
这期推文主要想研究一下多组学数据到底如何与算法结合,也就是说,如果我们想做多模态的研究,应该着手做哪些准备?
最近一直在琢磨怎么把多模态的数据整合起来,之前零零散散看了一些文献,但是都没有系统的写过一篇推文来分析多模态的研究到底应该如何开展。
趁着今天周末,我打算把这一部分的内容汇总一下,从论文发表趋势再到数据的收集和处理方法,做一个稍微具体一些的总结。
最后,我会通过一张图,列举目前常用的模型可解释性方法,这样就彻底把一个项目都讲完了。
一、从2015年到2024年(预测)在不同领域的论文发表数量趋势
图表中包括以下几个领域:
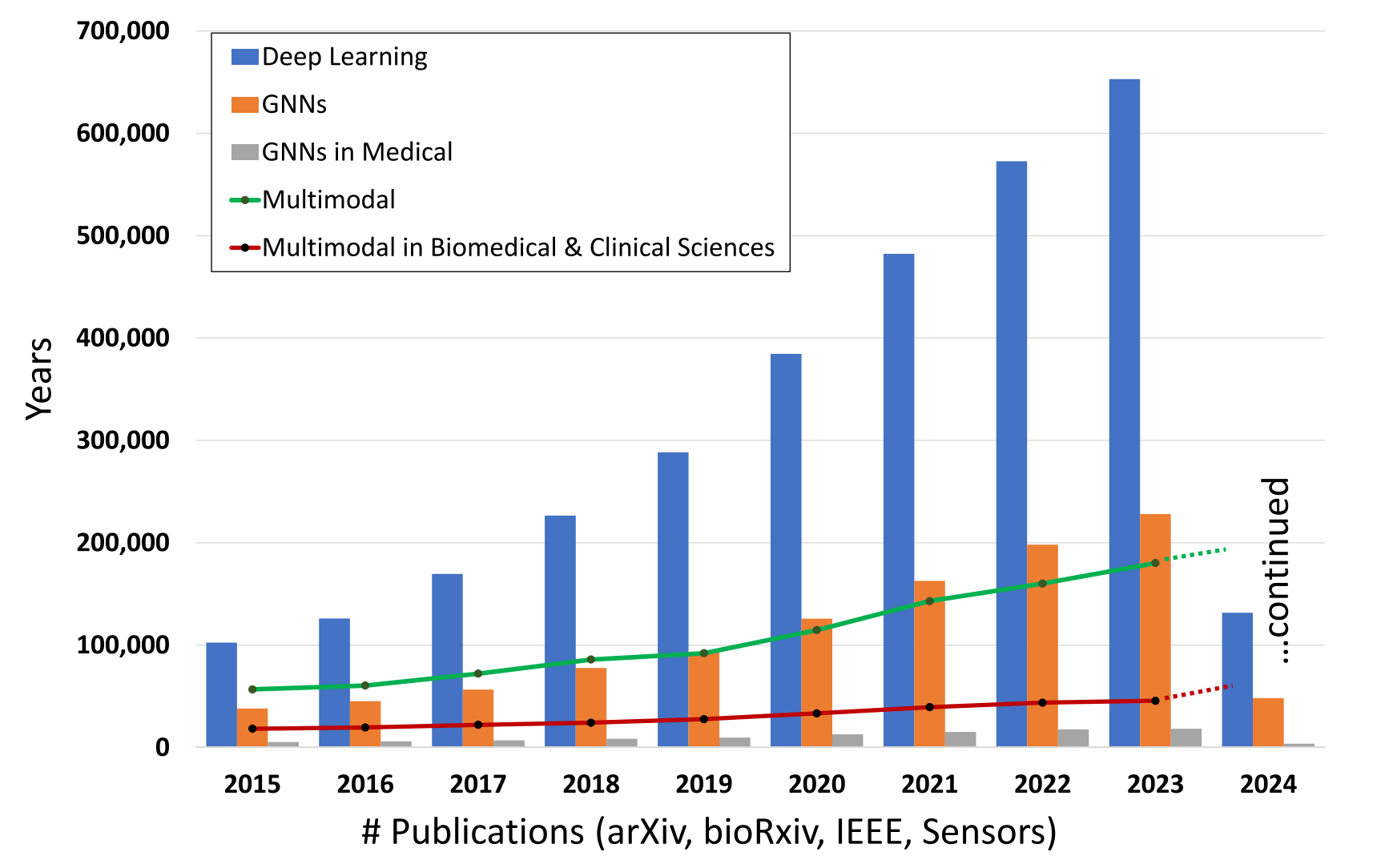
-
深度学习(Deep Learning):用蓝色柱状图表示。可以看到,深度学习的出版物数量从2015年开始逐年增加,尤其是在2021年和2022年达到了高峰,2023年略有下降,但预计2024年会继续增长。
-
图神经网络(GNNs):用橙色柱状图表示。GNNs的出版物数量也在逐年增加,尤其是在2020年之后增长显著,2023年达到一个较高的水平。
-
医学中的图神经网络(GNNs in Medical):用灰色柱状图表示。这个领域的出版物数量相对较少,但也呈现出逐年增长的趋势。
-
多模态(Multimodal):用绿色虚线表示。多模态领域的出版物数量在2015年到2024年间稳步增长,尤其是在2021年之后增长速度加快。
-
生物医学和临床科学中的多模态(Multimodal in Biomedical & Clinical Sciences):用红色虚线表示。这个领域的出版物数量也在逐年增加,但增长速度相对较慢。
从图表中可以看出,深度学习和GNNs是研究的热点领域,出版物数量增长迅速。多模态领域的增长也很明显,尤其是在生物医学和临床科学中的应用。医学中的GNNs虽然起步较晚,但增长趋势表明其在未来可能会有更大的发展空间。
二、多模态数据来源
这张图展示了癌症研究中不同数据类型和分析方法的整合,以及它们在宏观和微观层面上的应用。
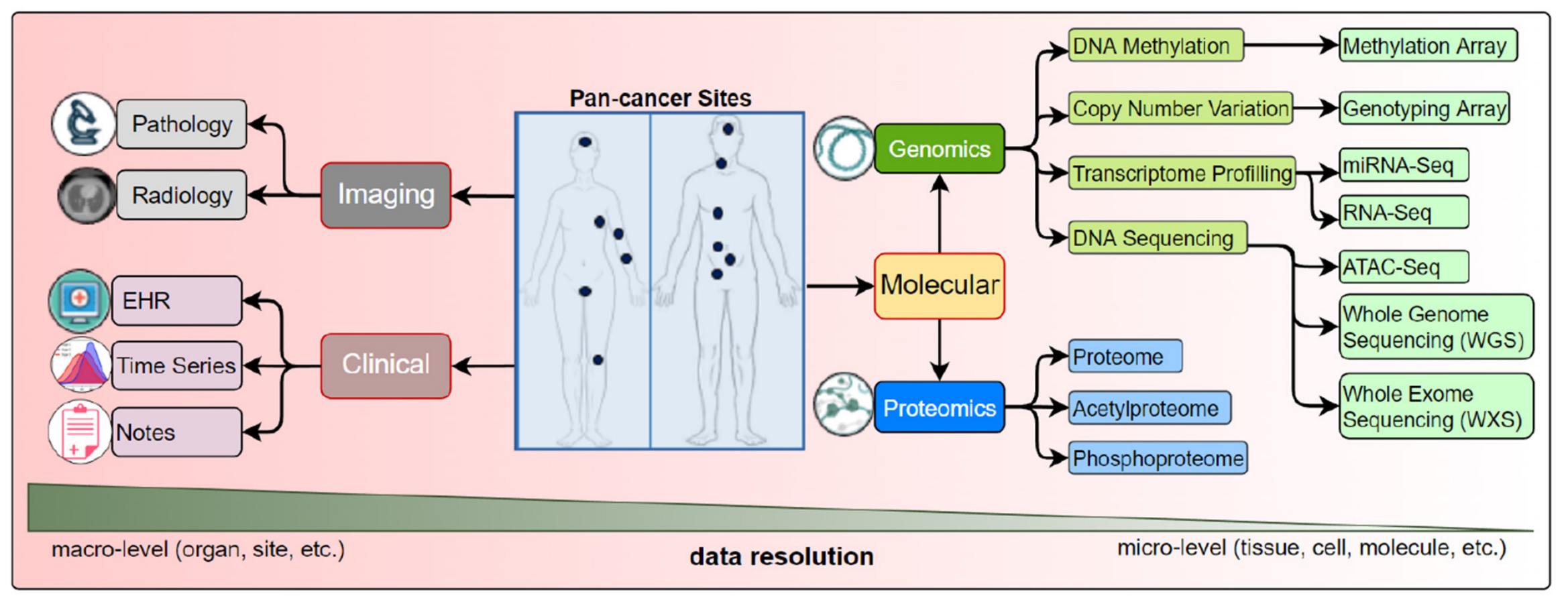
图中分为几个主要部分:
- 数据来源:
- 成像(Imaging):包括病理学(Pathology)和放射学(Radiology),提供癌症的图像数据。
- 临床(Clinical):包括电子健康记录(EHR)、时间序列数据(Time Series)、和笔记(Notes),提供患者的临床信息。
- 数据分辨率:
- 图的底部区分了宏观层面(如器官、部位等)和微观层面(如组织、细胞、分子等)。
- 分析方法:
-
基因组学(Genomics):包括DNA甲基化(DNA Methylation)、拷贝数变异(Copy Number Variation)、转录组分析(Transcriptome Profiling)、DNA测序(DNA Sequencing)。
- DNA甲基化分析可以通过甲基化阵列(Methylation Array)进行。
- 拷贝数变异分析可以通过基因分型阵列(Genotyping Array)进行。
- 转录组分析可以通过miRNA测序(miRNA-Seq)、RNA测序(RNA-Seq)、ATAC-Seq等方法进行。
- DNA测序可以进行全基因组测序(Whole Genome Sequencing, WGS)和全外显子测序(Whole Exome Sequencing, WXS)。
-
蛋白质组学(Proteomics):包括蛋白质组(Proteome)、乙酰化蛋白质组(Acetylproteome)、磷酸化蛋白质组(Phosphoproteome)。
-
- 分子层面:
- 分子层面的分析方法与基因组学和蛋白质组学相关,提供了更细致的生物分子信息。
这张图强调了在癌症研究中,通过整合多种数据类型和分析方法,可以从不同层面上深入理解癌症的生物学特性。这种多维度的分析有助于发现新的生物标志物、理解癌症的分子机制,并为个性化治疗提供依据。
三、多模态数据融合的不同阶段
这张图展示了两种多模态数据融合策略:早期融合(Early Fusion)和晚期及跨模态融合(Late and Cross-modality Fusion)。
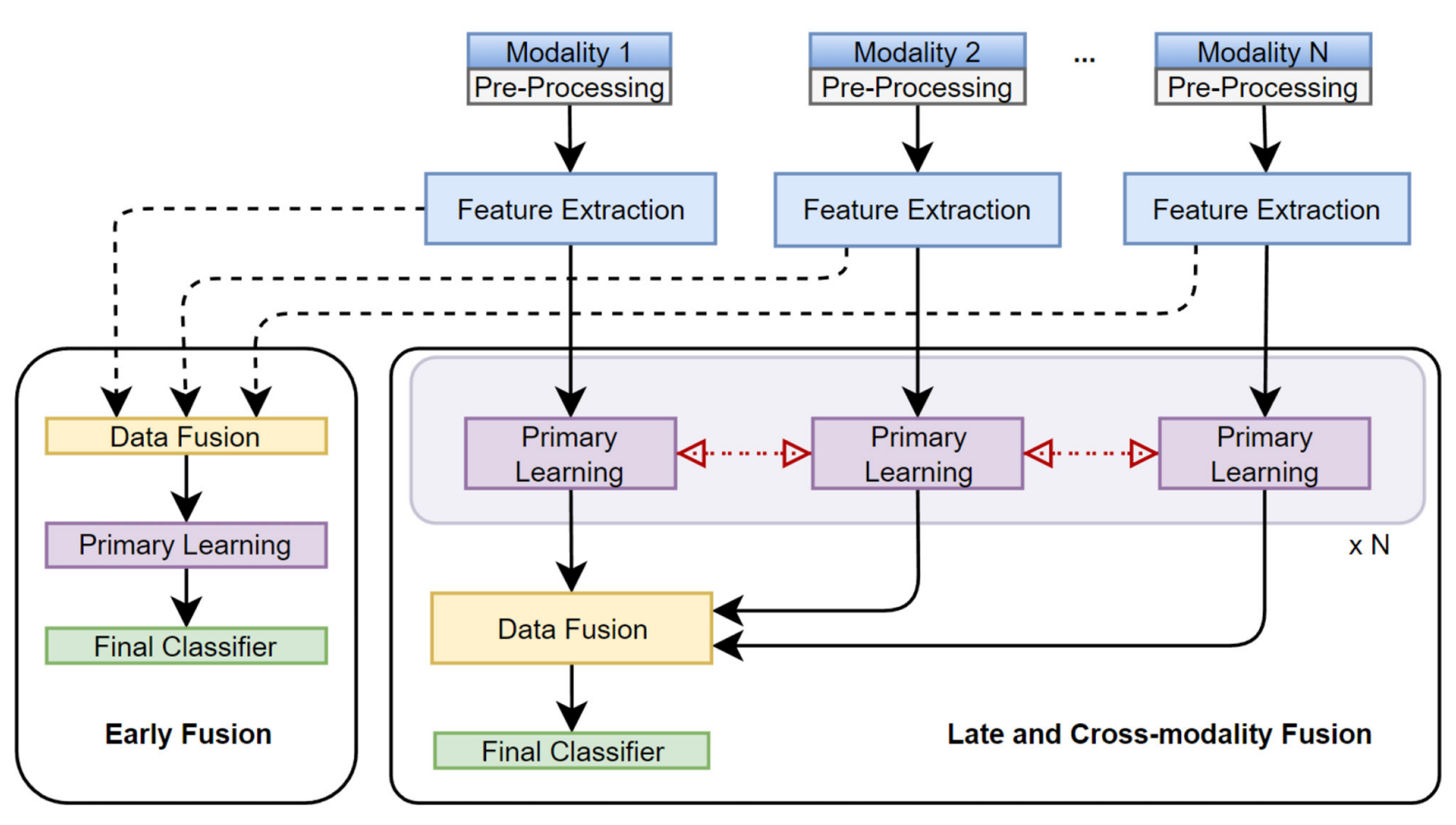
3-1:早期融合(Early Fusion)
- 数据预处理(Pre-Processing):每种模态的数据首先经过预处理,以确保数据的质量和一致性。
- 特征提取(Feature Extraction):从预处理后的数据中提取特征。
- 数据融合(Data Fusion):在特征层面上,将所有模态的特征合并成一个统一的特征集。
- 初级学习(Primary Learning):使用融合后的特征进行初步的模型训练。
- 最终分类器(Final Classifier):基于初级学习的结果,训练最终的分类器进行预测。
3-2:晚期及跨模态融合(Late and Cross-modality Fusion)
- 数据预处理(Pre-Processing):同样,每种模态的数据首先经过预处理。
- 特征提取(Feature Extraction):从预处理后的数据中提取特征。
- 初级学习(Primary Learning):每种模态的特征分别进行初级学习,训练独立的模型。
- 数据融合(Data Fusion):在模型层面上,将所有模态的初级学习结果进行融合。
- 最终分类器(Final Classifier):基于融合后的模型结果,训练最终的分类器进行预测。
3-3:比较
- 早期融合:在特征层面上进行融合,这意味着所有模态的信息在早期阶段就被合并,可能有助于模型更好地理解和利用不同模态之间的互补信息。
- 晚期及跨模态融合:在模型层面上进行融合,允许每种模态独立学习,然后在后期阶段合并这些学习结果。这种方法可能更灵活,因为它允许每个模态的模型专门处理其特定的数据特性,然后在后期阶段整合这些知识。
3-4:应用场景
- 早期融合适用于那些不同模态之间有明显互补性,且特征可以直接合并的场景。
- 晚期及跨模态融合适用于模态之间差异较大,或者每个模态都需要独立处理的场景。
这两种方法各有优势,选择哪种方法取决于具体的应用场景和数据特性。
四种不同的策略,用于在多模态Transformer中融合来自不同数据模态的信息,如下所示:(A) 早期融合。 (B) 晚期融合。 © 分层注意力。 (D) 交叉注意力。
四、多模态融合的不同策略
4-1:早期融合
首先,两种模态的数据经过预处理和特征提取;然后,这些特征在数据融合模块中被整合;接着,融合后的数据被输入到Transformer模型中进行处理;最后,Transformer的输出被送入最终分类器,进行分类决策。
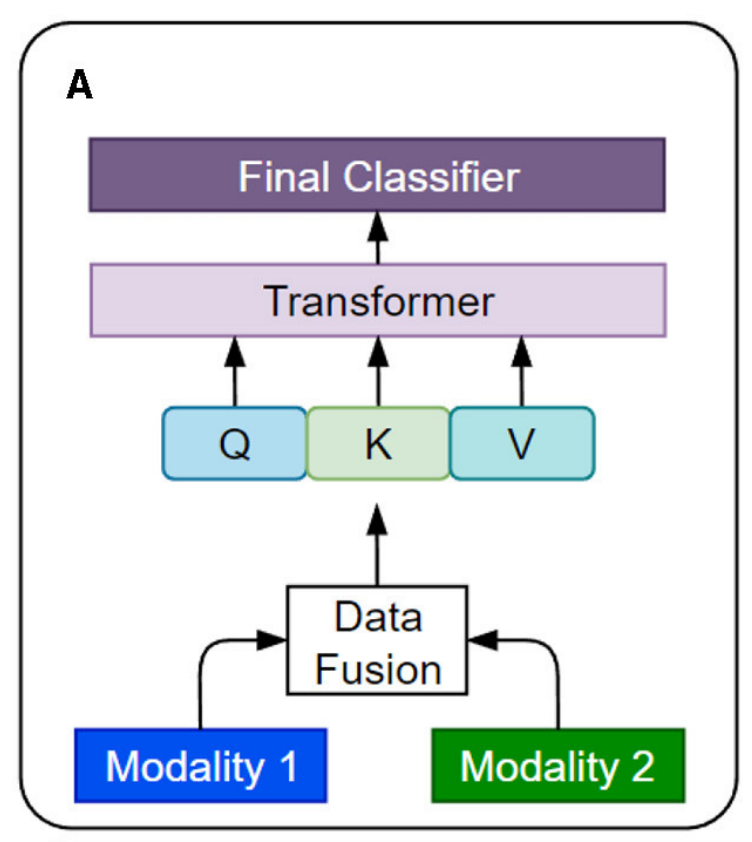
以下是对图中各部分的详细分析:
-
Modality 1 和 Modality 2:
- 这两个方框代表了两种不同的数据模态。
-
Data Fusion:
- 数据融合模块负责将来自两种不同模态的数据整合在一起。这通常涉及到特征提取和转换,以便不同模态的数据可以在后续的Transformer模型中被有效处理。
-
Q, K, V:
- 这些是Transformer模型中的三个关键组件,分别代表Query(查询)、Key(键)和Value(值)。在多模态数据融合的上下文中,这些组件可能用于处理和转换来自不同模态的特征,以便它们可以在Transformer中被有效地利用。
-
Transformer:
- Transformer是一种深度学习模型,最初用于自然语言处理任务,但现在已经广泛应用于各种序列数据处理任务,包括多模态数据融合。它通过自注意力机制来处理输入数据,能够捕捉数据中的长距离依赖关系。
-
Final Classifier:
- 最终分类器是模型的最后一层,它接收Transformer的输出,并根据这些输出进行最终的分类决策。这个分类器可以是一个简单的线性层,也可以是一个更复杂的神经网络结构,取决于具体的任务需求。
这种基于Transformer的多模态数据融合模型能够处理和整合来自不同来源和类型的数据,从而提高分类或其他任务的性能。它特别适用于那些需要综合考虑多种信息源的复杂任务。
4-2:晚期融合
首先,两种模态的数据分别通过各自的Transformer模型进行处理,生成特征表示;然后,这些特征表示在数据融合模块中被整合;接着,融合后的特征表示被输入到最终分类器,进行分类决策。
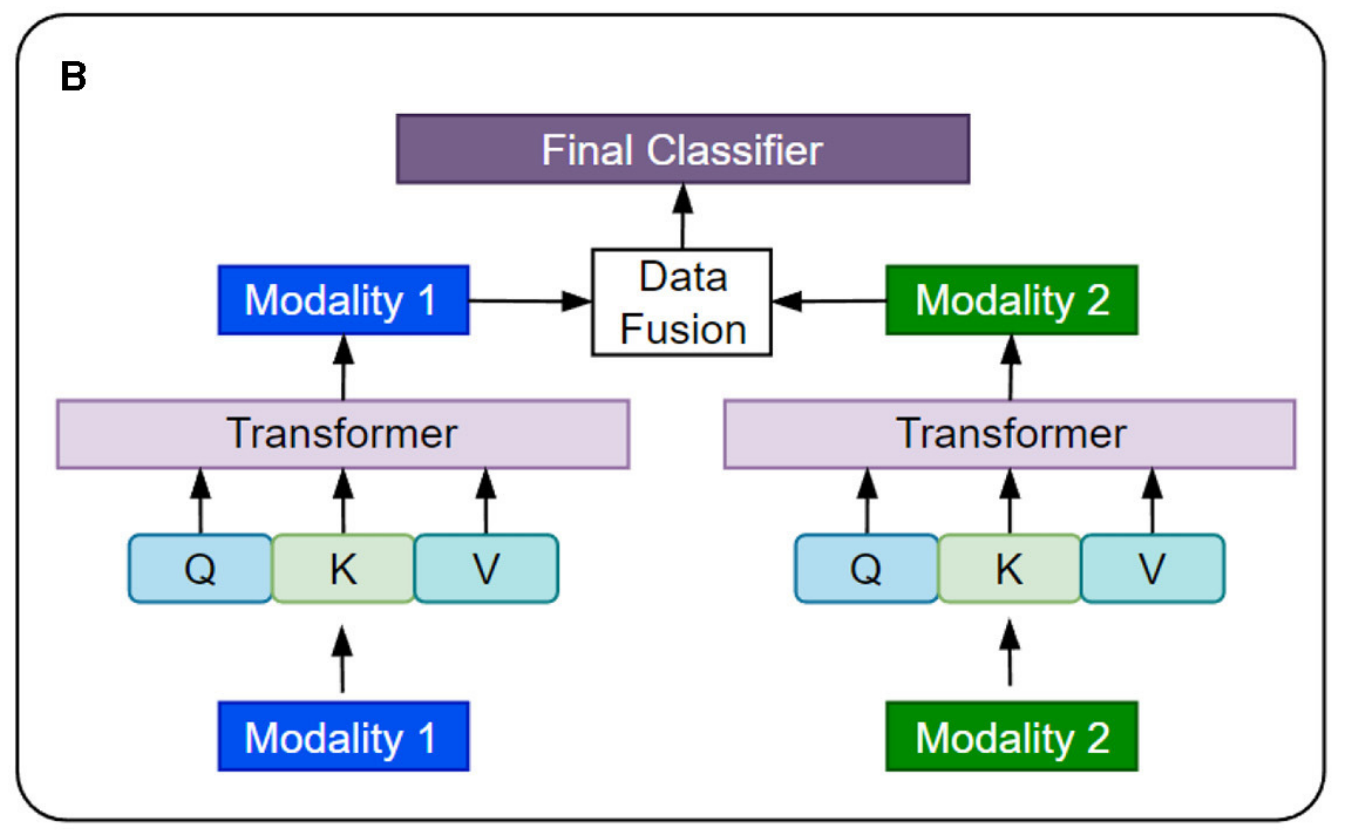
以下是对图中各部分的详细分析:
-
Modality 1 和 Modality 2:
- 这两个方框代表了两种不同的数据模态。
-
Transformer:
- 对于每种模态,都有一个独立的Transformer模型。
- 在这个架构中,每个Transformer模型接收其对应模态的数据,并生成特征表示(Q, K, V),这些特征表示随后用于数据融合。
-
Q, K, V:
- 这些是Transformer模型中的三个关键组件,分别代表Query(查询)、Key(键)和Value(值)。这些组件用于计算注意力权重,从而生成每个模态的特征表示。
-
Data Fusion:
- 数据融合模块负责将来自两种不同模态的特征表示整合在一起。这个模块可以采用多种融合策略,例如简单的特征拼接、加权平均、或者更复杂的融合网络。
- 在这个架构中,数据融合发生在Transformer模型的输出之后,这意味着每个模态的数据已经被Transformer处理并转换为特征表示,这些特征表示随后被融合。
-
Final Classifier:
- 最终分类器是模型的最后一层,它接收数据融合模块的输出,并根据这些输出进行最终的分类决策。这个分类器可以是一个简单的线性层,也可以是一个更复杂的神经网络结构,取决于具体的任务需求。
这种架构允许每个模态的数据独立处理,同时在后期通过数据融合模块整合信息,从而提高模型对多模态数据的理解和分类性能。这种设计特别适用于那些需要综合考虑多种信息源的复杂任务。
4-3:分层注意力
首先,两种模态的数据分别通过各自的Transformer模型进行处理,生成特征表示;然后,这些特征表示在数据融合模块中被整合;接着,融合后的特征表示被输入到最终分类器,进行分类决策。
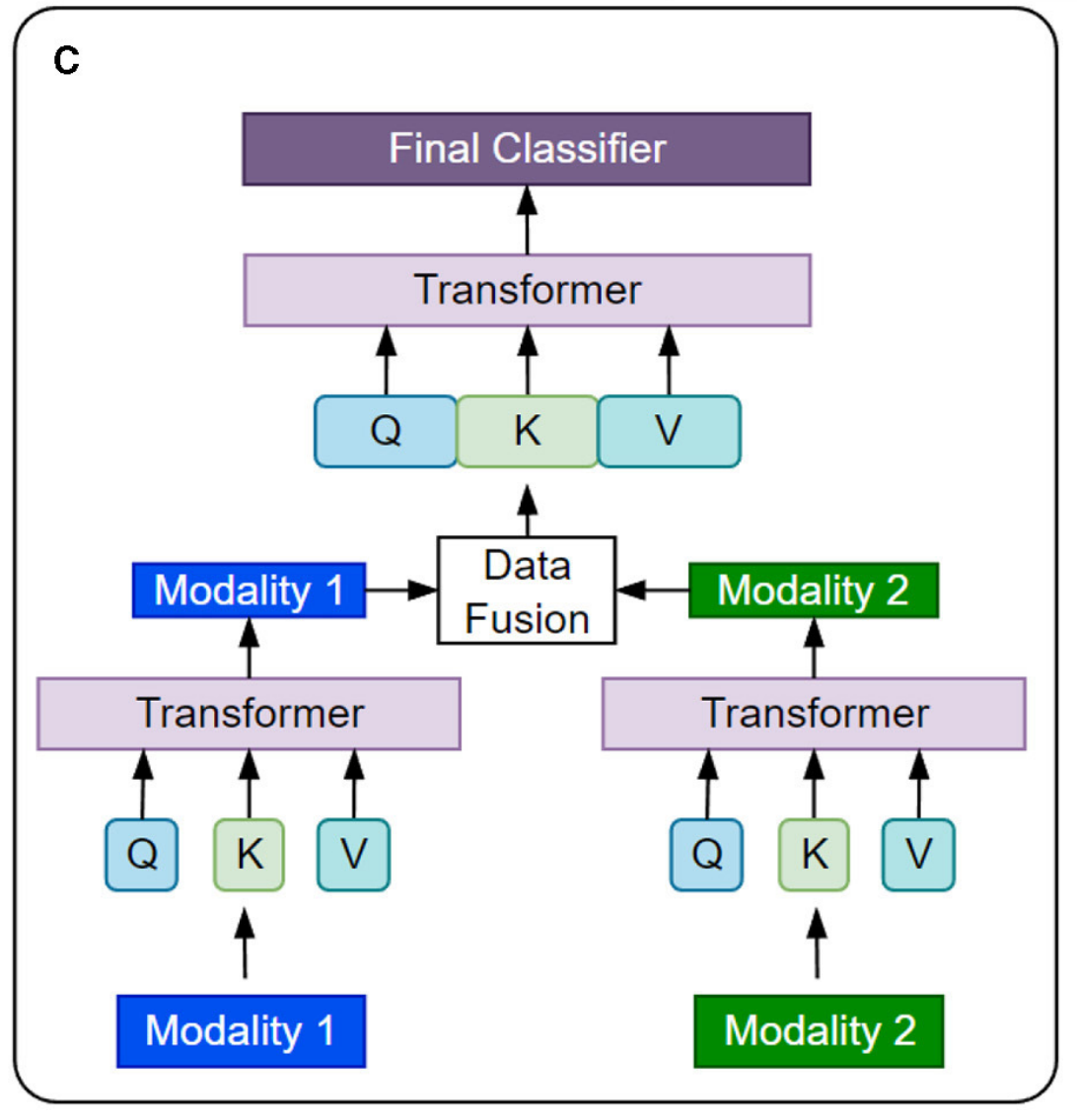
-
Modality 1 和 Modality 2:
- 这两个方框代表了两种不同的数据模态。
-
Transformer:
- 对于每种模态,都有一个独立的Transformer模型。
- 在这个架构中,每个Transformer模型接收其对应模态的数据,并生成特征表示(Q, K, V),这些特征表示随后用于数据融合。
-
Q, K, V:
- 这些是Transformer模型中的三个关键组件,分别代表Query(查询)、Key(键)和Value(值)。这些组件用于计算注意力权重,从而生成每个模态的特征表示。
-
Data Fusion:
- 数据融合模块负责将来自两种不同模态的特征表示整合在一起。这个模块可以采用多种融合策略,例如简单的特征拼接、加权平均、或者更复杂的融合网络。
- 在这个架构中,数据融合发生在Transformer模型的输出之后,这意味着每个模态的数据已经被Transformer处理并转换为特征表示,这些特征表示随后被融合。
-
Final Classifier:
- 最终分类器是模型的最后一层,它接收数据融合模块的输出,并根据这些输出进行最终的分类决策。这个分类器可以是一个简单的线性层,也可以是一个更复杂的神经网络结构,取决于具体的任务需求。
这种架构允许每个模态的数据独立处理,同时在后期通过数据融合模块整合信息,从而提高模型对多模态数据的理解和分类性能。这种设计特别适用于那些需要综合考虑多种信息源的复杂任务。
4-4:交叉注意力
首先,两种模态的数据分别通过各自的Transformer模型进行处理,生成特征表示;然后,这些特征表示在数据融合模块中被整合;接着,融合后的特征表示被输入到最终分类器,进行分类决策。
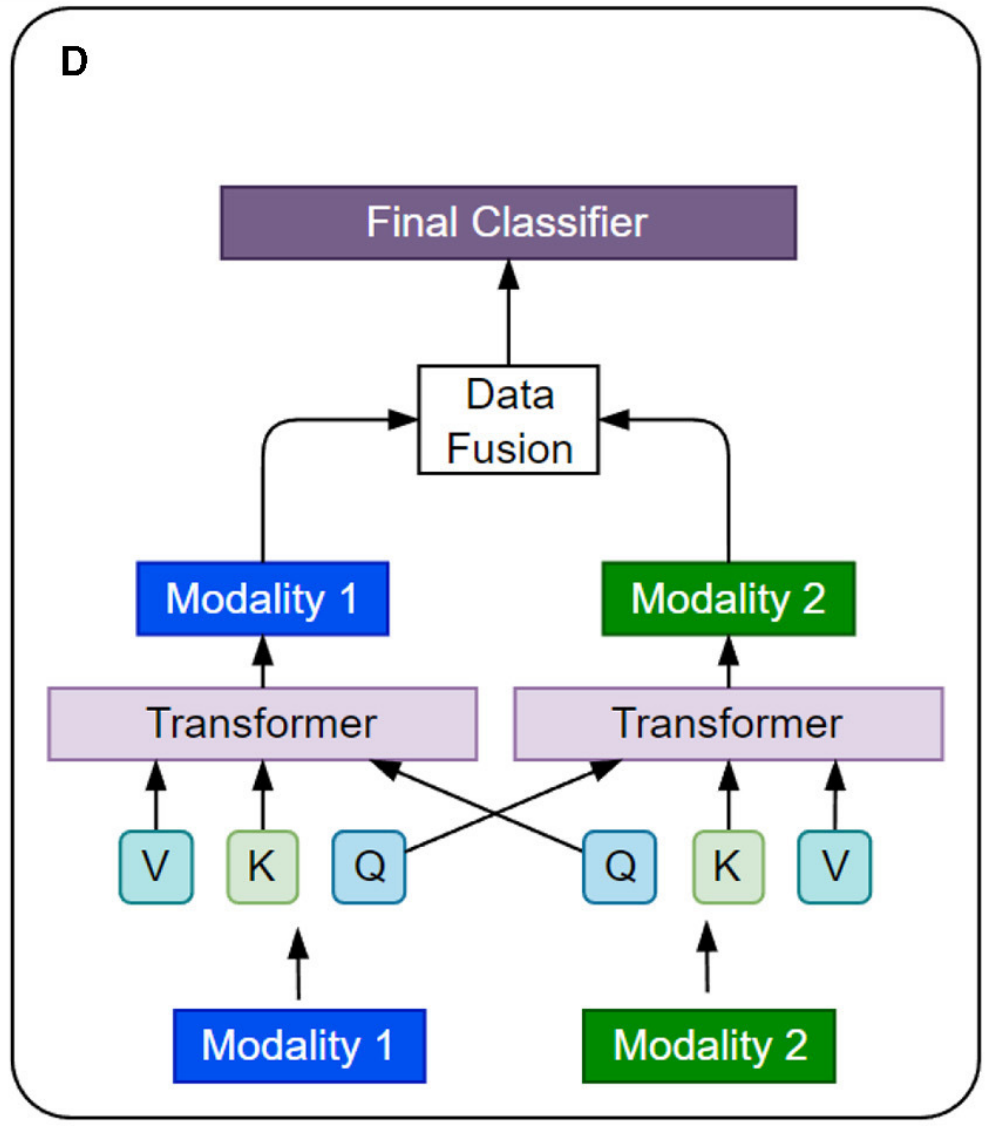
- Modality 1 和 Modality 2:
- 这两个方框代表了两种不同的数据模态。
- Transformer:
- 对于每种模态,都有一个独立的Transformer模型。
- 在这个架构中,每个Transformer模型接收其对应模态的数据,并生成特征表示(Q, K, V),这些特征表示随后用于数据融合。
- Q, K, V:
- 这些是Transformer模型中的三个关键组件,分别代表Query(查询)、Key(键)和Value(值)。这些组件用于计算注意力权重,从而生成每个模态的特征表示。
- 主要区别在于两种模态的Query(查询)进行了交叉。
- Data Fusion:
- 数据融合模块负责将来自两种不同模态的特征表示整合在一起。这个模块可以采用多种融合策略,例如简单的特征拼接、加权平均、或者更复杂的融合网络。
- 在这个架构中,数据融合发生在Transformer模型的输出之后,这意味着每个模态的数据已经被Transformer处理并转换为特征表示,这些特征表示随后被融合。
- Final Classifier:
- 最终分类器是模型的最后一层,它接收数据融合模块的输出,并根据这些输出进行最终的分类决策。这个分类器可以是一个简单的线性层,也可以是一个更复杂的神经网络结构,取决于具体的任务需求。
这种架构允许每个模态的数据独立处理,同时在后期通过数据融合模块整合信息,从而提高模型对多模态数据的理解和分类性能。这种设计特别适用于那些需要综合考虑多种信息源的复杂任务。
五、可解释性分析
在这一部分我会先通过一张图展示几种不同的模型和技术在图像处理和解释中的应用,然后再以乳腺癌为例,具体介绍AI模型的可解释性分析。
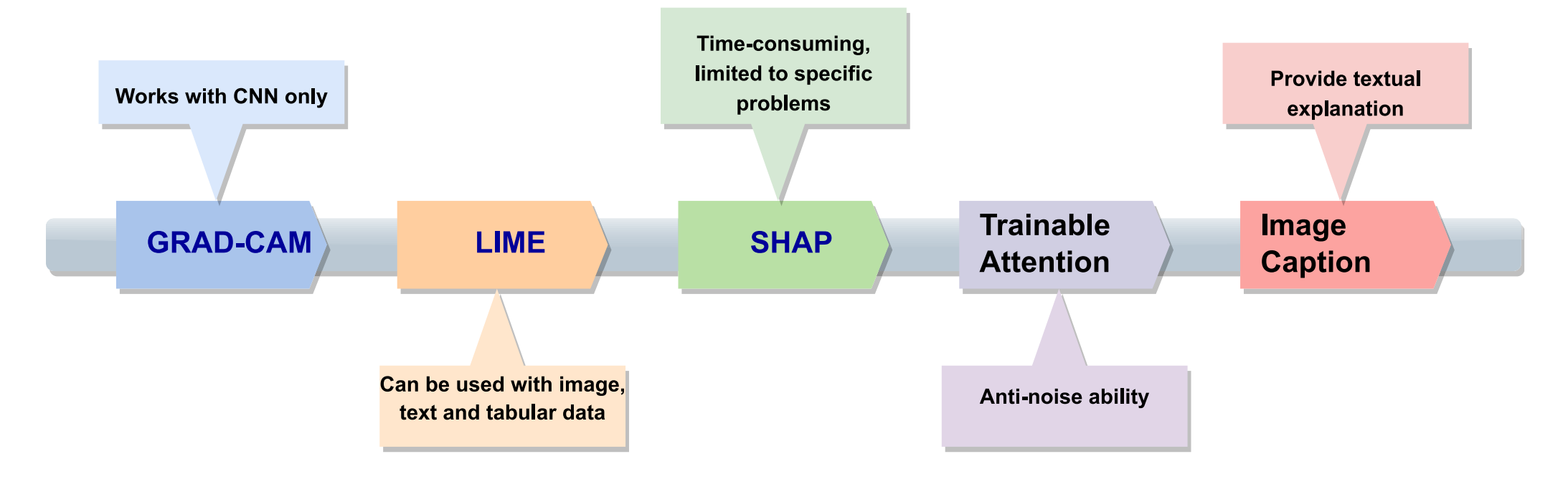
以下是对图中各部分的详细分析:
-
GRAD-CAM:
- 特点:GRAD-CAM是一种可视化技术,用于解释卷积神经网络(CNN)的决策过程。它通过计算特定类别的梯度加权平均来生成类激活图。
- 局限性:GRAD-CAM仅适用于CNN,并且可能无法提供足够的细节来解释模型的决策。
-
LIME:
- 特点:LIME(Local Interpretable Model-agnostic Explanations)是一种模型无关的解释方法,可以用于任何机器学习模型。它通过在模型预测周围生成局部解释来工作。
- 应用:LIME可以用于图像、文本和表格数据,提供模型决策的局部解释。
-
SHAP:
- 特点:SHAP(SHapley Additive exPlanations)是一种基于博弈论的解释方法,用于解释模型的输出。它通过计算每个特征对预测结果的贡献来生成解释。
- 局限性:SHAP方法可能在计算上非常耗时,尤其是对于大型模型或数据集,并且可能限于特定类型的问题。
-
Trainable Attention:
- 特点:可训练的注意力机制是一种深度学习技术,它允许模型学习如何关注输入数据的不同部分。这种机制可以提高模型的性能和解释性。
- 优势:可训练的注意力机制具有抗噪声能力,能够在存在噪声或不相关信息时仍然保持模型的准确性。
-
Image Caption:
- 特点:图像描述(Image Caption)是一种生成模型,用于为图像生成描述性文本。这种技术通常结合了图像识别和自然语言处理。
- 应用:图像描述模型可以提供图像的文本解释,帮助用户理解图像内容。
补充说明
LIME
LIME(局部可解释模型无关解释)主要局限于局部解释,可能无法提供对模型全局行为的全面理解。这一局限性在多模态数据场景中尤为挑战,因为在这种场景中,对模型决策过程的整体视角至关重要。
此外,LIME解释的准确性可能会受到围绕被解释实例生成的扰动的影响,可能无法准确捕捉模型的复杂性。尽管存在这些局限性,LIME在提高肿瘤检测中AI的可解释性方面仍是一个宝贵的工具,特别是在多模态环境中。
通过使复杂模型的预测更加易于理解,LIME显著提高了医疗诊断中AI应用的透明度和可信度。
SHAP
SHAP(沙普利加性解释)是一种常见的方法,它为特定预测的每个特征分配重要性值,从而阐明每个特征对结果的影响。
该工具是模型无关的,意味着它可以应用于任何机器学习模型,提供了极大的灵活性。SHAP提供全局和局部解释,详细洞察整体模型行为以及单个预测。它通过SHAP值准确反映模型预测的变化,确保了一致性和可靠性。此外,SHAP能够巧妙地处理缺失特征,通过将它们的SHAP值设为零。
尽管SHAP具有强大的功能,但它也存在一定的缺点。它计算密集,特别是对于具有大量特征模型的处理,这可能限制了其在实时应用中的可行性。
此外,对于没有技术背景的人来说,解释SHAP值可能会具有挑战性,这可能阻碍其更广泛的普及。尽管如此,SHAP仍然是一个非常有效的工具,特别是在像XGBoost这样的树基模型中,理解每个特征的影响至关重要。
通过增强AI模型的可解释性,SHAP显著提高了这些模型对用户的透明度和可信度,为详细分析提供了一个全面的框架,有助于深入理解特征如何影响结果,从而提高了对机器学习预测的整体信任。
通过使用SHAP分析多模态数据,研究人员可以揭示考虑单一数据类型时可能被忽视的复杂模式和关系。这种整体方法不仅提高了诊断准确性,还有助于识别关键生物标志物和预后因素,最终为乳腺癌患者提供更个性化和有效的治疗策略。尽管存在计算挑战,SHAP提供的详细洞察使其在复杂的多模态乳腺癌诊断领域中成为了一个不可或缺的工具。
类激活映射
类激活映射(CAM)是卷积神经网络(CNN)中的基本工具,它生成热图以可视化图像的重要部分。
Grad-CAM是CAM的扩展,它使用任何目标概念的梯度来产生粗略的定位图,突出预测概念的关键区域,而无需修改或重新训练模型。Grad-CAM是模型无关的,适用于各种CNN模型,在图像分类等任务中非常有价值,在医疗保健中尤其有用。然而,Grad-CAM有时可能产生过于粗略的定位,可能优先考虑临床无关特征,导致假阳性或错误解释。
Grad-CAM++在Grad-CAM的基础上进行了改进,提供了更精细的定位能力,并能突出图像中的多个感兴趣对象,使其更适合解释具有多个对象的实例。尽管有其优势,Grad-CAM++的实施和解释更为复杂。
将Grad-CAM和Grad-CAM++等视觉解释方法整合到多模态数据分析中存在挑战,特别是在确保不同类型数据之间解释的一致性方面。此外,Grad-CAM类方法仅限于CNN模型,这限制了它们在非CNN模型中的应用,可能会使这些环境中的决策过程复杂化。