小罗碎碎念
在临床相关的人工智能(AI)模型发展方面,传统上需要大量标注数据集,这使得AI的进步主要围绕大型中心和私营企业展开。所以,在这期推文中,我会介绍一些已经商用的模型,并且为计划进军这个领域的商业同行提供一些建议。
数据的可用性也决定了AI应用的发展:大多数研究聚焦于常见癌症类型,而忽略了罕见疾病。然而,随着基础模型(foundation models,FMs)的出现,这一范式正在改变,使得可以使用更小的数据集训练更加强大和健壮的AI系统【1】。
所以我们如何用更小的数据集(即更少的成本和更短的时间)去搭建一个适合我们研究领域的模型呢?又或者说,有没有一个通用的套路来快速的验证我们提出的假说呢?
为了解决上面两个问题,我挑选了几篇高分文献,并且把其中关键的部分揉合在一起,不再像之前那样,只是推荐,而没有系统的归纳总结。写作不易,希望能对大家有所启发!!
一、AI在组织病理学图像分析中的应用
在组织病理学图像分析中,AI流程通常包括两个部分:特征提取和特定任务的预测。
图像编码器用于将病理图像压缩成低维特征向量。在此基础上,可以为特定任务(如癌症检测、生存结果预测或治疗反应)训练预测模型。
自2022年以来,由于自监督学习的推动,组织病理学的AI应用进入了一个新时代。这种方法使得可以在不需要任何标注数据的情况下高效训练特征提取器。这些大量的数据进而使得可以训练包含数十亿参数的更大、更全面的模型。以这种方式训练的模型被称为基础模型(FM)。
FMs对组织学图像中的形态模式有全面的理解,因此与在自然图像上预训练的模型相比,使用更少的训练样本就能训练出更准确的预测模型【1】。这种训练方法在本质上类似于人类学习,具有组织学一般知识的专家比非专家使用更少的样本就能解读特定的病理发现。
此外,未标注数据集自然具有高度可变性,包括不同的组织、疾病、扫描仪和制备协议。总的来说,使用FM作为训练特定任务模型的基线,显著提高了计算病理学模型的性能和泛化能力【2】,同时减少了结果预测模型中的任何偏差【3】。
二、基础模型的发展和应用
过去几年中,一波FMs已经进入组织病理学图像分析领域。
CTransPath是最早广泛使用的FM之一【4】。这些早期的FMs是使用公开可用的数据集(如癌症基因组图谱TCGA)构建的,而后续的研究则使用了带有更多数据和参数的私有数据集。
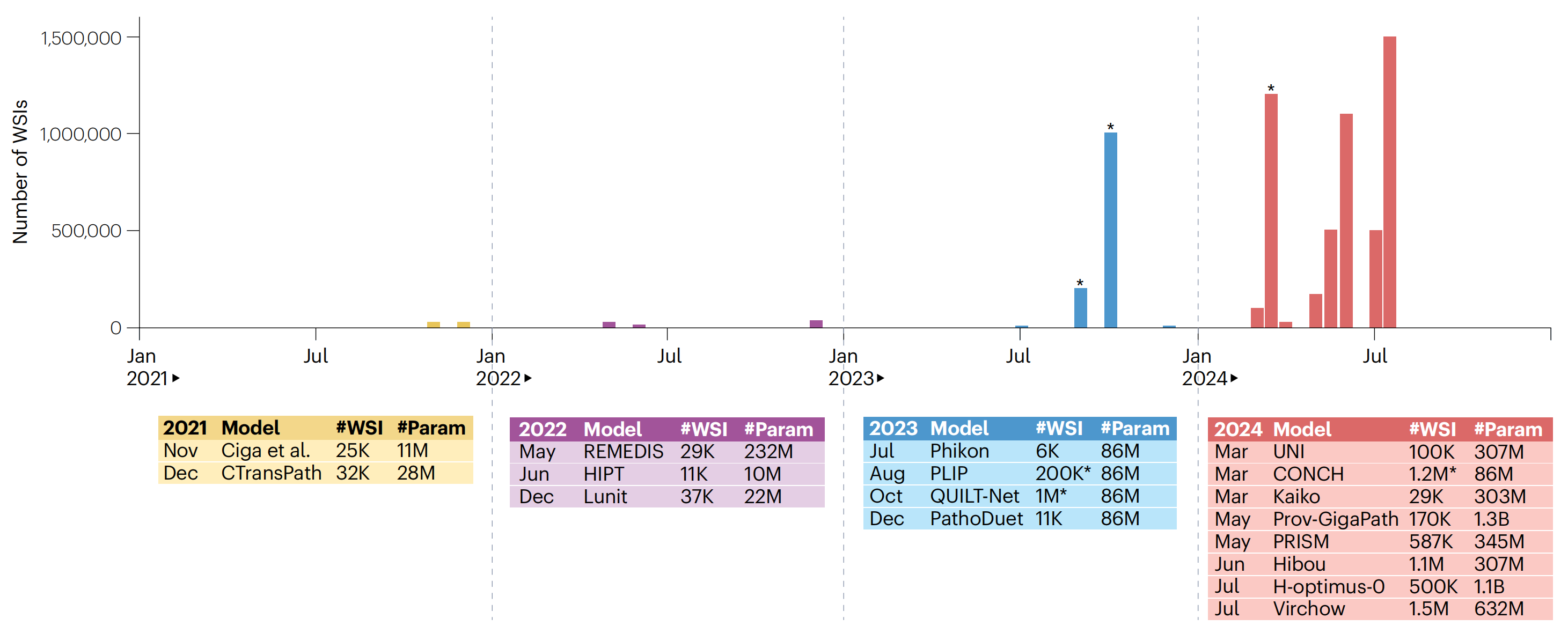
尽管FM的开发通常仅限于资源丰富的机构(由于对数据可用性、数据存储和计算能力的高要求),但有几个小组公开发布了他们的预训练模型。这种开放性使得研究人员能够从私有数据集上的大规模预训练中受益。
在最近发表在《nature medicine》上的一篇文章中,Vorontsov等人【5】介绍了另一个名为“Virchow”的FM。
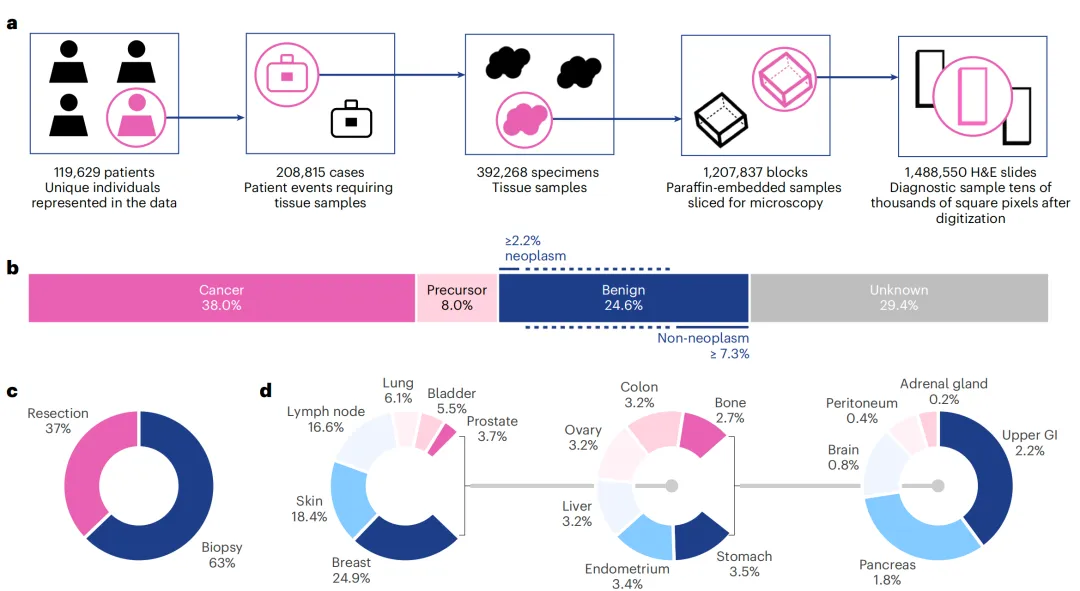
在所有可用的FMs中,Virchow拥有最多的参数和最广泛的训练集。Virchow在来自100,000名患者的数据上训练,包括大约1.5百万张恶性和非恶性组织的全切片图像,这些数据来自纪念斯隆-凯特琳癌症中心(MSKCC)。
Virchow模型通过自监督学习算法训练,能够生成数据表示(嵌入),这些嵌入能够很好地泛化到多种预测任务,从而构建一个跨多种组织类型的泛癌症模型。在九种常见和七种罕见癌症类型的队列上进行测试时,基于Virchow的泛癌症模型在性能上超越了或与所有其他测试的FMs相当。
最重要的是,Virchow模型可以处理罕见肿瘤类型或不常见的诊断任务,例如预测特定的基因组变化、临床结果和治疗反应,先不说效果如何,至少作者已经考虑到这一方面,那么就是方法和思路的一个创新!!
尽管使用了更少的特定任务标签进行训练,但相同的泛癌症检测模型在性能上几乎与临床级商业模型(特别是Paige Prostate、Paige Breast和Paige Breast Lymph Node)相匹配,甚至在检测某些罕见癌症变体时超过了它们。
我们大部分团队是无法具备商业级模型的开发能力的,但是Virchow的作者比较良心,为这一部分人提供一个开发临床级AI的可能,同时也给我们研究罕见疾病提供了一个新的思路!!(这就非常适合用来申请大型的项目啊,参考我上个月发的推文)
并且Virchow的发表,还给我们提供另外一个信息——仅增加数据集大小可能不再能带来实质性的性能提升——因为训练了1.5百万张图像的Virchow和训练了100,000张图像的另一个名为UNI1的FM在性能上差距不大。
那么我们更关心的问题来了,**既然堆数据不好使了,下一步应该做什么呢?**我个人认为,进一步调整模型架构,优化训练数据的质量,充分考虑到不同中心数据之间的差异性并尽可能消除这种数据不平衡带来的影响才是我们下一阶段研究的重点。
还有一点很关键,也是我推文中频繁出现的——多模态/多组学——我们想要提升模型的性能,就必须要整合额外的数据类型,如临床报告或分子信息(测序,也就是基因组学、蛋白组学……),只有这样,我们才能保证模型更接近临床落地的可能。
三、商业开发会促进医学AI发展
其实这段时间也有不少商业的前辈和我沟通,想要进军医学AI和病理AI行业,那么我觉得Virchow模型算是一个不错的切入点,因为它是允许商业再利用的。我个人也是赞同商业开发的,因为这样一定程度上会促进技术的进步,也能有更多的人关注这个领域。
这部分的商业价值是毋庸置疑的,所以作为数据的原始生产者——医院——自然也不会放弃这个大好的机会,越来越多的头部医院开始布局医学AI,这都是利好的消息,但是也意味着卷的程度越来越明显。
基础模型肯定是为少部分人准备的,他们享受了最好的资源,理应承担更大的风险,但是开源与否的权利还是在于他们,我们要做好他们不开源或者隐藏部分技术的心里建设,要早日掌握自己的核心技术。
我们能做的,或者说迫切要做的,就是在目前已经开源的模型基础上,构建一个可以使用几百或者几千名患者就能训练并且取得良好效果的模型。为什么要实现一个这样的目标?一方面是基层的医院没有办法提供头部医院那样的数据,另一方面是我们的模型如果在小样本数据集的表现都优秀,那么大数据集的表现,几乎是会更好的(除非你扩大数据时导致了原始数据污染,加入了很多噪声)
四、开放获取和模型评估的重要性
开放获取对于创新和人工智能模型的评估至关重要。然而,现有的开源概念不能总是直接应用于人工智能系统。特别是,病理学中的FMs通常作为开放权重模型发布(所以,最关键的就是那一系列权重文件)——这种方法意味着尽管这些模型可以作为特征编码器使用,但它们的训练数据仍然是私有的,这阻碍了重新训练和验证可重复性的尝试。
还有一点很头疼,就是文章的投稿到发表时间,这中间的间隔太大了,就会导致我们看到的研究,他的思路其实已经不是最新的了。比如说我前两天分享的郑大那篇文章,人家21年投稿,24年发表,用的模型我们现在可能部分新手都没听过。
这里我只想表达一个观点,看文章不能只看方法和结果,发表的时间和团队成员,也是一个不可忽略的内容!!
五、未来发展
从最开始的仅用普通的HE图像进行基础模型的训练,再到现在各种格式的图像、文本都加入进来,再一次验证了我的观点——多模态、自监督模型的开发将是未来一段时间亟需攻克的难题。
文本信息和图像信息一起处理,一定是未来的趋势,因为这是Transformer架构底层就决定的。我们未来或许真的可以实现,给模型输入一张普通的切片,它就能输出各种各样目前需要复杂检查才能得出的报告。
不妨畅想一下未来,我们可以一起打造一个医院的智能化信息系统,从收集数据开始就由AI接管,这样模型的训练数据自然而然就统一了,并且收集数据的速度也会有一个质的飞跃,那时又将开启下一轮的竞争。
参考文献
-
- Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 30, 850–862 (2024).
-
- Wagner, S. J. et al. Transformer-based biomarker prediction from colorectal cancer histology: a large-scale multicentric study. Cancer Cell 41, 1650–1661.e4 (2023).
-
- Vaidya, A. et al. Demographic bias in misdiagnosis by computational pathology models. Nat. Med. 30, 1174–1190 (2024).
-
- Wang, X. et al. Transformer-based unsupervised contrastive learning for histopathological image classification. Med. Image Anal. 81, 102559 (2022).
-
- Vorontsov, E. et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nat. Med. https://doi.org/10.1038/s41591-024-03141-0 (2024).
-
- Lu, M. Y. et al. A multimodal generative AI copilot for human pathology. Nature https://doi.org/10.1038/s41586-024-07618-3 (2024).
-
- Derraz, B. et al. New regulatory thinking is needed for AI-based personalised drug and cell therapies in precision oncology. NPJ Precis. Oncol. 8, 23 (2024).