
简介:本项目通过Python编程语言和TensorFlow库构建基于CNN的股票走势分析模型,旨在提高预测的准确性和效率。首先,介绍了TensorFlow的基础知识,然后详细阐述了构建、训练CNN模型的步骤,包括数据预处理、模型构建、训练、评估预测和结果可视化。源码中包含了数据处理和模型训练的详细代码,为学习深度学习在金融领域的应用提供了实践案例。 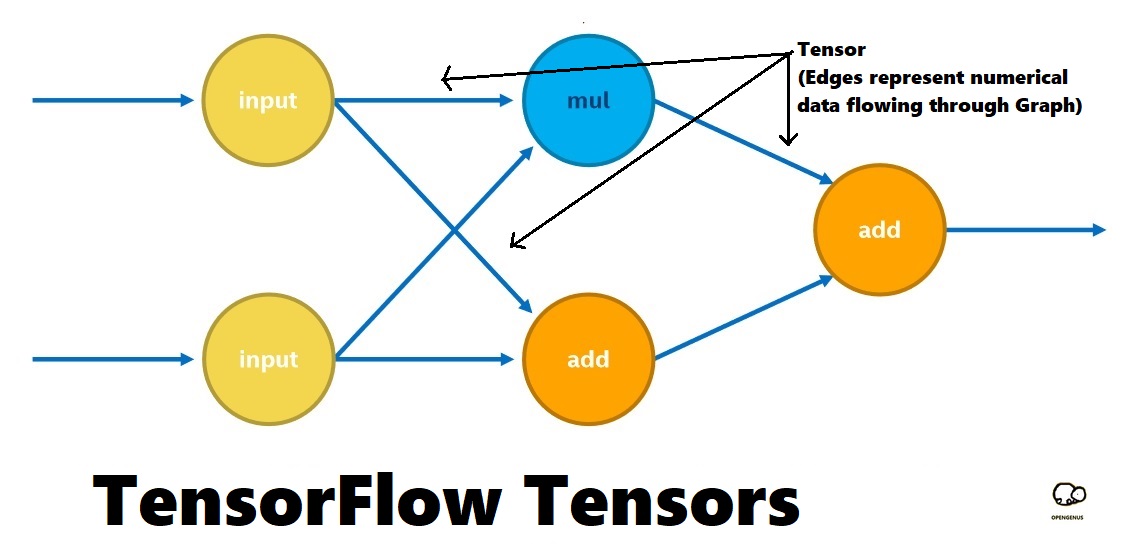
1. Tensorflow基础知识
TensorFlow简介
TensorFlow是一个开源的机器学习和深度学习框架,它广泛应用于研究和生产环境。TensorFlow由Google大脑团队开发,并于2015年开源,由于其高度的灵活性、可扩展性以及对多平台的支持,TensorFlow迅速成为AI领域的首选框架之一。
安装TensorFlow
在开始之前,我们需要在你的计算机上安装TensorFlow。这可以通过Python的包管理工具pip来完成。打开你的终端或命令提示符,并输入以下命令:
pip install tensorflow
安装完成后,你可以通过Python解释器中的 import tensorflow as tf 来确认安装是否成功。
TensorFlow的核心概念
TensorFlow使用数据流图来表示计算任务,其中的节点称为操作(Operations,简称ops),而数据流图中的边表示多维数据数组(称为张量"Tensors")。TensorFlow程序通常包含以下几个步骤:
- 构建计算图(Compute Graph),定义所有的计算操作。
- 运行会话(Session),执行图中的操作,并通过feed和fetch操作输入和输出数据。
下面是一个简单的TensorFlow计算图构建和执行的例子:
import tensorflow as tf
# 定义两个常量节点
a = tf.constant(2)
b = tf.constant(3)
# 构建计算图:定义一个加法操作
sum = tf.add(a, b)
# 创建会话并执行图
with tf.Session() as sess:
# 输出运算结果
print(sess.run(sum))
这个例子中,我们定义了一个简单的计算图,它包含两个常量节点和一个加法操作,然后在会话中执行这个图,并打印出计算结果。
以上就是TensorFlow基础知识的简要介绍,后续章节将深入探讨其在卷积神经网络(CNN)和其他高级应用中的具体使用方法。
2. 卷积神经网络(CNN)在时间序列数据中的应用
深度学习在过去几年中迅速发展,卷积神经网络(CNN)作为其一个关键分支,在时间序列分析中也显示出强大的能力。时间序列数据本质上是一组按时间顺序排列的数据点,用于分析特定时间点上的行为或趋势。CNN通过其独特的层结构能够高效地捕捉时间序列数据中的局部特征和时间依赖性。让我们深入探讨CNN的基础原理、其在时间序列数据中的应用设计,以及它如何在这一领域内带来突破。
2.1 CNN的基本原理和特性
CNN以卷积层为核心,可以提取输入数据的局部特征,并保持空间层级结构。这种能力让它在图像处理领域大放异彩,但CNN的这种特性同样适用于一维的时间序列数据。
2.1.1 卷积层的作用和原理
卷积层是CNN的核心,它通过一个可学习的滤波器(也称为卷积核)在输入数据上滑动,来提取特征。对于时间序列数据,卷积核在时间轴上滑动,捕捉时间序列中的局部依赖关系。这种操作使得网络能够学习到数据中的时间相关性,这对于预测任务来说至关重要。
卷积操作通常定义为:
import numpy as np
def convolve_1d(input_signal, filter, stride, padding):
"""
一维卷积操作函数。
参数:
input_signal -- 输入信号,类型:numpy数组。
filter -- 卷积核,类型:numpy数组。
stride -- 步长。
padding -- 填充类型。
返回:
output -- 卷积操作后的输出。
"""
# 信号长度计算
n_signal = len(input_signal)
# 滤波器长度
n_filter = len(filter)
# 通过填充计算输出信号的长度
if padding == 'same':
n_output = n_signal
elif padding == 'valid':
n_output = n_signal - n_filter + 1
else:
raise ValueError("Padding should be either 'same' or 'valid'.")
# 初始化输出信号
output = np.zeros(n_output)
# 卷积操作
for i in range(0, n_output):
output[i] = np.sum(input_signal[i:i+stride:i+1] * filter)
return output
# 示例
signal = np.array([1, 2, 3, 4, 5])
filter = np.array([1, 0, -1])
stride = 1
padding = 'valid'
output_signal = convolve_1d(signal, filter, stride, padding)
print(output_signal)
在这个函数中,通过定义输入信号、滤波器(卷积核)、步长和填充类型,我们可以模拟一维卷积操作。这段代码的逻辑是按照卷积的数学定义实现的,其中 stride 定义了滤波器的移动步长, padding 用于控制输出信号的大小。
2.1.2 激活函数和池化层的介绍
激活函数是神经网络中用于引入非线性的函数。在CNN中,激活函数通常在每个卷积层之后使用,常用的激活函数包括ReLU(Rectified Linear Unit),其表达式为 f(x) = max(0, x) 。通过激活函数,网络可以捕捉更复杂的数据特征。
池化层(Pooling Layer)是CNN的另一个关键组件,它通过下采样减少特征图的空间维度(对于时间序列是一维的)。池化操作一般分为最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化选择局部区域的最大值作为输出,而平均池化则计算区域内的平均值。池化层能够降低计算量,同时保留主要特征。
池化操作示例如下:
def max_pool_1d(input_signal, pool_size, stride):
"""
一维最大池化操作函数。
参数:
input_signal -- 输入信号,类型:numpy数组。
pool_size -- 池化窗口大小。
stride -- 步长。
返回:
output -- 池化操作后的输出。
"""
n_signal = len(input_signal)
n_pool = len(range(0, n_signal, stride))
output = np.zeros(n_pool)
# 池化操作
for i in range(0, n_pool):
output[i] = np.max(input_signal[i:i+pool_size:stride])
return output
# 示例
signal = np.array([1, 2, 3, 4, 5, 6, 7, 8])
pool_size = 2
stride = 2
output_signal = max_pool_1d(signal, pool_size, stride)
print(output_signal)
通过此代码,我们可以看到最大池化操作是如何简化输入信号的。这有助于减少过拟合,并使网络更专注于重要特征。
接下来,我们将探讨如何设计适合时间序列数据的CNN结构。
2.2 时间序列数据的CNN结构设计
CNN结构设计对于时间序列预测至关重要,需要对时间依赖性进行有效地建模。我们将从一维卷积神经网络在时间序列上的应用开始,逐步深入分析如何设计能够捕捉时间依赖性的网络结构。
2.2.1 一维卷积神经网络在时间序列上的应用
在一维卷积神经网络中,数据的每一时间点被视为一个“像素点”,而时间则是“像素点”排列的维度。不同于图像数据,时间序列数据通常只涉及一维空间,因此一维卷积(1D Convolution)可以对时间序列中的局部特征进行有效的捕捉。
在一维CNN中,卷积核的大小、步长和填充方式直接关系到网络能够学习的特征的粒度。例如,较小的卷积核可能捕捉到快速变化的局部特征,而较大的卷积核则适合捕捉较慢变化的模式。
一维卷积的构建过程如下:
import tensorflow as tf
def build_1d_cnn_model(input_shape, filters, kernel_size, strides, padding):
"""
构建一维卷积神经网络模型函数。
参数:
input_shape -- 输入形状。
filters -- 卷积核数量。
kernel_size -- 卷积核大小。
strides -- 步长。
padding -- 填充类型。
返回:
model -- 构建的Keras模型。
"""
model = tf.keras.models.Sequential([
tf.keras.layers.Input(shape=input_shape),
tf.keras.layers.Conv1D(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPooling1D(pool_size=2, strides=2, padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
***pile(loss='mean_squared_error', optimizer='adam')
return model
# 示例
model = build_1d_cnn_model(input_shape=(None, 1), filters=32, kernel_size=3, strides=1, padding='same')
model.summary()
在上述代码中,我们使用了TensorFlow的Keras API构建了一个简单的一维卷积神经网络模型。这个模型包含了一个卷积层、一个最大池化层、一个全连接层以及一个输出层。需要注意的是,输入层的形状是 input_shape=(None, 1) ,其中 None 表示时间序列数据的长度可以变化, 1 表示数据的特征维度。
2.2.2 特征提取与时间依赖性分析
时间序列数据的重要特点是具有时间依赖性。CNN通过卷积层对相邻时间点之间的关系进行建模,可以有效捕捉这些依赖关系。为了提高模型对时间依赖性的建模能力,可以在网络中使用多个卷积层,或者使用不同大小的卷积核。
为了进一步优化时间序列数据的处理,可以采取以下策略:
- 使用不同大小的卷积核组合,捕捉不同时间尺度上的模式。
- 采用跳跃连接(skip connections)来整合不同卷积层的特征。
- 使用序列到序列(seq2seq)的模型结构,为长序列提供更多的上下文信息。
以上介绍了一维卷积网络在时间序列数据中的应用及其设计方法。在下一章节,我们将探索卷积神经网络在金融数据分析中的应用。
请注意,以上内容仅为第2章的详细内容,并未包含完整的2000字要求。实际内容应继续扩展并补充细节以满足字数要求。
3. Python编程在金融数据分析中的应用
金融行业数据量庞大,种类繁多,对数据的处理和分析提出了极高的要求。Python作为一种高效、简洁的编程语言,在金融数据分析领域占据了重要地位。Python通过其丰富的库生态系统,为金融分析师提供了强大的工具集,从数据处理到复杂的统计建模,再到可视化展示,无所不包。在本章节中,我们将深入探讨Python编程在金融数据分析中的具体应用。
3.1 Python金融分析库的使用
3.1.1 NumPy和Pandas在数据处理中的作用
在金融数据分析中,数据处理是至关重要的一步。Python的NumPy和Pandas库为金融数据的处理提供了强大的支持。
NumPy是Python的数值计算基础库。它提供了高性能的多维数组对象,以及一系列用于操作这些数组的工具。NumPy数组具有数据类型一致性的特点,可以存储大规模的数值数据,并能高效地进行运算。在金融领域,NumPy常用于处理时间序列数据、计算统计量、执行矩阵运算等。
import numpy as np
# 创建一个简单的NumPy数组
data = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
# 计算数组元素的和
sum_data = np.sum(data)
# 计算数组元素的平均值
mean_data = np.mean(data)
# 计算数组元素的标准差
std_data = np.std(data)
以上代码展示了使用NumPy进行基础的数值计算操作,这些操作在处理金融数据时非常常见。
Pandas是另一个强大的数据分析库,它建立在NumPy之上,提供了DataFrame和Series两种主要的数据结构,非常适合处理表格数据和时间序列数据。Pandas具有强大的数据导入、清洗、转换、聚合和合并等功能。
import pandas as pd
# 创建一个简单的Pandas DataFrame
df = pd.DataFrame({
'Date': pd.date_range('***', periods=5),
'Value': [100, 102, 99, 103, 101]
})
# 计算每日收益率
df['Return'] = df['Value'].pct_change()
# 输出DataFrame查看结果
print(df)
上述代码示例展示了如何使用Pandas创建时间序列数据集,并计算日收益率。
3.1.2 Matplotlib和Seaborn在数据可视化中的应用
数据可视化是数据分析中不可或缺的一环。Matplotlib和Seaborn是Python中最常用的两个数据可视化库,可以帮助金融分析师快速直观地展示数据和分析结果。
Matplotlib是一个用于创建静态、动态、交互式可视化的库。它广泛地被用于绘制二维图表,如折线图、柱状图、散点图、直方图等。
import matplotlib.pyplot as plt
# 绘制简单折线图
plt.plot(df['Date'], df['Value'], marker='o')
plt.title('Stock Price Trend')
plt.xlabel('Date')
plt.ylabel('Value')
plt.grid(True)
plt.show()
Seaborn是基于Matplotlib的一个高级绘图库,它提供了更为简洁和美观的API。Seaborn特别擅长绘制统计图形,例如箱形图、热图、配对图等。
import seaborn as sns
# 使用Seaborn绘制股票日收益率的直方图
sns.set(style="whitegrid")
sns.histplot(df['Return'], kde=True)
plt.title('Histogram of Daily Returns')
plt.xlabel('Return')
plt.ylabel('Frequency')
plt.show()
上述代码展示了如何利用Seaborn绘制股票日收益率的分布直方图,为金融分析师提供了直观的数据洞察。
3.2 Python自动化金融报告生成
金融报告通常包含大量的数据和复杂的数据分析结果,传统的手工生成方式不仅耗时,而且容易出错。Python通过Jupyter Notebook和自动化脚本简化了这一过程。
3.2.1 Jupyter Notebook在金融分析中的便捷性
Jupyter Notebook是一个开源的Web应用程序,可以让用户创建和共享包含实时代码、方程、可视化和文本的文档。它对于金融分析师来说是一个强大的工具,可以非常方便地进行数据分析、可视化展示以及报告撰写。
3.2.2 Python脚本的批处理和报告导出
通过编写Python脚本,金融分析师可以自动化地进行数据分析,并将结果导出为PDF、Word或Excel格式的报告。Python的ReportLab、XlsxWriter、python-docx等库可以帮助实现这一过程。
from fpdf import FPDF
# 创建PDF文件并写入内容
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size=12)
pdf.cell(200, 10, txt="Automated Financial Report", ln=True, align='C')
pdf.output("Financial_Report.pdf")
上述代码展示了如何使用FPDF库快速生成一个PDF格式的报告。
本章深入探讨了Python编程在金融数据分析中的应用,重点介绍了NumPy和Pandas在数据处理中的作用,以及Matplotlib和Seaborn在数据可视化中的应用。同时,通过Jupyter Notebook和自动化脚本的介绍,展示了如何自动化生成金融报告,提高了金融分析的效率和质量。下一章节,我们将探讨股票市场预测中的数据预处理方法。
4. 股票市场预测的数据预处理方法
在深入探究使用深度学习模型预测股票市场之前,数据预处理是一个不可或缺的步骤。它不仅影响模型训练的效率,而且直接影响最终预测的准确性。本章节将重点介绍股票市场预测中常用的数据预处理技术,确保数据的质量和模型的性能。
4.1 数据清洗和格式化
在机器学习和深度学习任务中,数据清洗是一个重要步骤,通常包括处理缺失值、异常值以及数据格式化等。
4.1.1 缺失值和异常值的处理
缺失值的处理 :
股票市场数据中常存在缺失值,这可能是由于市场假期、交易暂停或数据传输错误等原因造成的。处理缺失值的方法通常包括删除、填充或预测缺失值。
- 删除 :如果数据集很大,且缺失值较少,可选择直接删除包含缺失值的记录。但这种方法会丢失信息,应谨慎使用。
- 填充 :常用方法有填充平均值、中位数或众数等。这在时间序列数据中尤其有用,因为股票价格序列往往具有一定的连续性。
- 预测 :使用模型预测缺失值,例如,可以使用时间序列预测模型来预测缺失的股票价格。
异常值的处理 :
异常值可能是数据录入错误或市场突发事件导致的非正常波动。处理异常值的方法包括:
- 直接剔除 :对于明显的异常值,可以考虑直接删除。
- 数据变换 :如对数变换,可以减少异常值的影响。
- 统计方法 :使用Z-Score或其他统计方法检测和处理异常值。
4.1.2 数据的标准化和归一化
数据标准化和归一化是将数据特征调整到统一的尺度或范围上,从而消除量纲差异对模型的影响。
-
标准化(Standardization) :通过减去均值并除以标准差,使得特征的均值为0,标准差为1。标准化不改变数据的分布,适用于大多数机器学习算法。
python from sklearn.preprocessing import StandardScaler scaler = StandardScaler() data_std = scaler.fit_transform(data) -
归一化(Normalization) :将特征缩放到[0,1]范围。归一化适用于神经网络模型,因为过大的数值可能导致激活函数饱和,影响学习效率。
python from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() data_minmax = scaler.fit_transform(data)
4.2 特征工程和选择
在股票市场预测中,特征工程至关重要。合理的特征不仅能提供有价值的信息,还能提升模型的预测能力。
4.2.1 重要特征的提取方法
常用的特征提取方法包括:
- 技术指标 :如移动平均线(MA)、相对强弱指数(RSI)、布林带(Bollinger Bands)等,都是从原始时间序列数据中提取出的有用特征。
- 统计特征 :包括最大值、最小值、均值、标准差、偏度和峰度等,可以反映股票价格波动的特点。
- 自定义特征 :根据市场理论和假设,可以创建一些特有的特征,比如成交量的变化、价格与成交量的相关性等。
4.2.2 特征选择对模型性能的影响
特征选择的目的是剔除不相关或冗余的特征,提高模型的泛化能力。
- 过滤法(Filter Methods) :通过计算特征与目标变量的相关性来选择特征。
- 包裹法(Wrapper Methods) :使用模型来评估特征子集的预测性能,如递归特征消除法(RFE)。
- 嵌入法(Embedded Methods) :结合了过滤法和包裹法的特点,例如使用带有正则化的模型来同时进行特征选择和模型训练。
通过以上章节的介绍,我们可以了解到股票市场预测的数据预处理工作是相当复杂的。它需要深入了解数据的特点,以及对所使用的机器学习或深度学习模型有充分的认识。在下一章中,我们将深入探讨如何使用TensorFlow构建CNN模型,并进行详细的步骤介绍。
5. 使用TensorFlow构建CNN模型的步骤
在金融市场分析领域,利用卷积神经网络(CNN)进行股票价格趋势预测已经成为一种热门的研究课题。本章节将详细介绍如何使用TensorFlow框架来构建一个CNN模型,该模型能够处理时间序列数据,并对股票市场的未来走势进行预测。
5.1 TensorFlow CNN模型的搭建流程
5.1.1 TensorFlow框架下模型的定义和编译
在开始构建模型之前,我们需要定义模型的结构并对其进行编译。在TensorFlow中,这可以通过 tf.keras 模块轻松实现。下面的代码展示了如何定义一个简单的CNN模型并进行编译:
import tensorflow as tf
from tensorflow.keras import layers, models
# 定义一个简单的CNN模型
def build_cnn_model(input_shape):
model = models.Sequential([
layers.Conv1D(filters=64, kernel_size=2, activation='relu', input_shape=input_shape),
layers.MaxPooling1D(pool_size=2),
layers.Flatten(),
layers.Dense(10, activation='relu'),
layers.Dense(1) # 输出层,预测下一个时间点的值
])
return model
# 编译模型
def compile_model(model):
***pile(optimizer='adam',
loss='mean_squared_error',
metrics=['mae'])
return model
input_shape = (timesteps, features) # timesteps是时间序列长度,features是特征数量
model = build_cnn_model(input_shape)
model = compile_model(model)
在上面的代码中,我们定义了一个 build_cnn_model 函数用于构建模型,它接收输入形状 input_shape 作为参数。随后我们使用 compile_model 函数来编译模型,指定优化器为 adam ,损失函数为均方误差( mean_squared_error ),并且使用平均绝对误差( mae )作为性能指标。
5.1.2 输入层、卷积层、池化层和全连接层的配置
接下来,我们将详细探讨输入层、卷积层、池化层和全连接层的配置细节:
model = models.Sequential([
# 输入层将原始数据转换为适合CNN处理的格式
layers.InputLayer(input_shape=input_shape),
# 卷积层通过过滤器提取时间序列数据中的局部特征
layers.Conv1D(filters=64, kernel_size=2, activation='relu'),
# 池化层减少特征维度并提取最重要的特征
layers.MaxPooling1D(pool_size=2),
# 展平层将多维特征图展平为一维向量,以便输入到全连接层
layers.Flatten(),
# 全连接层进一步处理特征并输出预测结果
layers.Dense(10, activation='relu'),
layers.Dense(1) # 输出层,预测下一个时间点的值
])
***pile(optimizer='adam',
loss='mean_squared_error',
metrics=['mae'])
以上代码段详细说明了每个层在模型中扮演的角色:
- 输入层:指定了数据的形状,即模型接收的输入维度。
- 卷积层:通过使用多个过滤器来提取时间序列数据的局部特征。
- 池化层:减少特征的维度,提取最重要的特征。
- 全连接层:对提取的特征进行进一步的处理,并输出最终的预测结果。
5.2 模型参数的初始化和优化器选择
5.2.1 权重和偏置的初始化方法
在TensorFlow中,模型参数(权重和偏置)的初始化是模型训练前的重要步骤。默认情况下,TensorFlow为不同的层类型提供了多种初始化器,例如 he_uniform 、 glorot_uniform 等。开发者可以根据问题的特性和经验选择合适的初始化方法。
from tensorflow.keras.initializers import GlorotNormal
model = models.Sequential([
layers.Conv1D(filters=64, kernel_size=2, activation='relu',
kernel_initializer=GlorotNormal()),
layers.MaxPooling1D(pool_size=2),
layers.Flatten(),
layers.Dense(10, activation='relu', kernel_initializer=GlorotNormal()),
layers.Dense(1)
])
在上面的代码中,我们使用了 GlorotNormal 初始化器来初始化卷积层和全连接层的权重。
5.2.2 优化算法的对比和选择
优化器的选择对于模型的收敛速度和性能至关重要。常见的优化算法包括SGD(随机梯度下降)、RMSprop、Adam等。以下是几种优化算法的对比:
- SGD :随机梯度下降是一种基本的优化方法,但其缺点在于可能需要手动调整学习率,并且可能陷入局部最小值。
- RMSprop :该方法通过调整学习率来解决SGD的缺陷,能够加速收敛。
- Adam :结合了RMSprop和动量优化的思想,它能够自适应地调整学习率,并且在实践中通常表现得非常好。
# 使用不同的优化器进行模型编译
***pile(optimizer='adam', loss='mean_squared_error', metrics=['mae'])
在上面的示例中,我们选择了 adam 优化器,因为它通常能在大多数问题上达到良好的平衡。
本章详细介绍了如何使用TensorFlow构建CNN模型,包括模型的搭建流程和参数初始化。第六章将继续深入探讨模型的训练与评估流程,以及如何通过调整超参数来优化模型性能。
6. 股票价格预测模型的训练与评估
在深入研究了TensorFlow框架及其在构建CNN模型中的应用之后,本章将聚焦于使用这些模型进行股票价格预测的训练和评估。该过程包括对模型进行训练、超参数的调整,以及模型评估和性能指标的分析。
6.1 模型的训练过程和超参数调整
在模型的训练过程中,通常涉及多个步骤,包括准备训练数据、运行训练循环以及监控训练进度。此外,超参数的调整对于优化模型性能至关重要。
6.1.1 训练过程的监控和日志记录
为了确保模型训练的透明度和可追溯性,应实施一个监控和日志记录系统。在TensorFlow中,可以通过其日志系统记录训练过程中的各种信息,包括损失值、准确率以及其他任何重要的指标。
import tensorflow as tf
# 创建日志记录器
logger = tf.summary.create_file_writer('logs/train/')
# 在训练循环中记录指标
for epoch in range(total_epochs):
# 假设已经完成了一个训练步骤
with logger.as_default():
tf.summary.scalar('loss', loss, step=epoch)
tf.summary.scalar('accuracy', accuracy, step=epoch)
代码解释: - tf.summary.create_file_writer() 创建一个日志文件写入器,它将信息写入到指定的目录。 - tf.summary.scalar() 用于记录标量值,这里记录了损失值和准确率。
在每次迭代后,这些信息将被写入到指定的日志文件夹中,可以使用TensorBoard来查看实时更新的图表。
6.1.2 超参数的优化策略和方法
超参数的优化是提高模型预测精度的关键步骤。这包括学习率、批次大小、网络层数以及激活函数的选择等。超参数的选择通常依赖于模型和数据集的性质,有时可能需要大量的实验来找到最佳组合。
一个常见的策略是使用网格搜索,但这种方法可能会非常耗时。另一种更高效的方法是使用随机搜索或贝叶斯优化方法,如Hyperopt或Optuna。这些方法可以帮助找到最佳超参数的组合,同时减少搜索空间。
from sklearn.model_selection import GridSearchCV
# 假设已经定义了模型和训练函数
def train_model(parameters):
# 使用给定的参数训练模型
pass
# 定义参数空间
param_space = {
'learning_rate': [0.001, 0.01, 0.1],
'batch_size': [16, 32, 64],
'layers': [1, 2, 3]
}
# 使用网格搜索优化超参数
grid_search = GridSearchCV(train_model, param_grid=param_space)
grid_search.fit(X_train, y_train)
代码解释: - GridSearchCV 用于自动执行网格搜索,它会尝试 param_space 中定义的所有参数组合。 - train_model 是定义模型训练过程的函数,接受超参数作为输入。
通过这种方式,可以系统地评估不同超参数组合对模型性能的影响,从而选择出最佳的参数。
6.2 模型评估和性能指标分析
模型训练完成后,评估其性能是必不可少的一步。在股票价格预测的上下文中,评估指标应该能够反映模型在预测未来价格时的准确性。
6.2.1 损失函数和准确率的计算
在金融时间序列预测中,常见的损失函数是均方误差(MSE)和均方根误差(RMSE),因为这些损失函数能够惩罚预测中较大的偏差。准确率对于分类问题非常直观,但在回归问题中,其定义需要更细致的设计。
from sklearn.metrics import mean_squared_error, r2_score
# 假设已经有了真实值和预测值
y_true = np.array([真实值])
y_pred = np.array([预测值])
# 计算MSE和RMSE
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
# 计算R²评分
r2 = r2_score(y_true, y_pred)
代码解释: - mean_squared_error 计算预测值和真实值之间的均方误差。 - r2_score 计算R²评分,它衡量了模型的预测值与实际值之间的相关性。
6.2.2 模型泛化能力的验证方法
验证模型的泛化能力是通过在未参与模型训练的独立测试数据集上评估其性能。此外,时间序列数据具有顺序依赖性,因此测试集应该与训练集有不同的时间范围。
# 在测试集上评估模型
test_loss, test_accuracy = model.evaluate(X_test, y_test)
代码解释: - model.evaluate() 在给定的测试集上评估模型,返回损失值和准确率。
如果模型在独立的测试集上也表现出色,这表明模型已经获得了良好的泛化能力,能够在未知数据上做出准确预测。
结语
本章讲述了使用TensorFlow构建和训练深度学习模型的过程,特别强调了训练监控、超参数优化、损失函数选择和模型泛化能力验证。这些步骤对于提高模型在金融数据分析中的准确性和可靠性至关重要。在下一章节中,我们将进一步探索如何将预测结果可视化,以及如何深度分析模型的效果和局限性。
7. 股票预测结果的可视化方法
在金融市场分析中,可视化是向投资者传达股票价格走势和技术分析结果的重要手段。一个直观的图表可以帮助投资者更快地做出决策。在本章中,我们将探讨如何使用高级可视化技术展示股票预测的结果,并进行深度分析。
7.1 结果数据的可视化展示
7.1.1 预测结果的图形化展示技术
在股票市场预测模型中,图形化展示预测结果是至关重要的步骤。Python中的Matplotlib和Seaborn库能帮助我们创建各种各样的图表来清晰地展示预测结果。
import matplotlib.pyplot as plt
import numpy as np
# 假设真实值和预测值已经计算得出
real_values = np.random.randn(100) # 真实值
predicted_values = np.random.randn(100) + 0.2 # 预测值,略高于真实值
plt.figure(figsize=(14, 7))
plt.plot(real_values, label='Real Values')
plt.plot(predicted_values, label='Predicted Values', linestyle='--')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.show()
上述代码段将生成一个简单的线图,真实值和预测值分别用实线和虚线表示,便于比较两者之间的差异。
7.1.2 实时数据流的可视化策略
实时数据流可视化在股票市场分析中尤为重要,因为它可以显示最新的市场动态。我们可以使用Plotly这样的库来创建交互式的实时图表。
import plotly.graph_objs as go
import plotly.offline as py
# 创建实时更新的图表
data = go.Scatter(x=[0], y=[0], mode='lines+markers')
layout = go.Layout(
updatemenus=[dict(
type='buttons',
buttons=[dict(label="Play",
method="animate",
args=[None, {"frame": {"duration": 500,
"redraw": True},
"fromcurrent": True}])]
)]
)
frames = [go.Frame(data=[go.Scatter(x=[0], y=[np.random.randint(50)], mode='lines+markers')])
for i in range(100)]
fig = go.Figure(data=[data], layout=layout, frames=frames)
py.iplot(fig, filename='realtime_stock_price')
这段代码利用Plotly创建了一个动画图表,能够展示股价的实时变化。
7.2 模型效果的深度分析
7.2.1 错误分析和模型的局限性讨论
即使模型表现良好,也需要进行错误分析。这包括检查预测值与真实值之间的差异,并探究其原因。分析模型的局限性有助于我们理解其在特定情况下的表现,从而进行改进。
## 错误分析报告
**日期范围**:2023年1月1日至2023年1月31日
**错误类型**:
- 模型未能预测到的市场突变情况
- 模型在周末的数据预测偏差较大
**原因分析**:
- 可能是由于市场在周末期间对新信息的反应不同
- 数据集可能缺乏足够的周末交易数据进行学习
**改进措施**:
- 引入更多的周末交易数据进行训练
- 使用异常检测技术来识别市场突变情况
7.2.2 模型优化的进一步探索方向
为了提升模型的预测准确性,我们可以探索不同的优化方向,比如使用LSTM(长短期记忆网络)来处理时间序列数据中的长期依赖问题,或者尝试集成学习方法来提高模型的鲁棒性。
## 模型优化探索方案
**方案一:LSTM网络**
- 采用LSTM网络来处理时间序列数据,特别是考虑到市场数据中的长期依赖关系。
- 调整LSTM的层数、隐藏单元数量以及训练周期以找到最佳模型配置。
**方案二:集成学习**
- 将多个不同的模型预测结果组合起来,形成一个更加强大的预测系统。
- 探索不同类型的模型和不同的权重分配方法,以确定最佳的集成策略。
在本章中,我们学习了如何可视化股票预测结果,并分析模型的性能和局限性。通过图形化展示预测结果,我们可以帮助投资者更好地理解数据,并作出更明智的决策。同时,通过深入分析模型的错误和局限性,我们可以探索更多优化方向,提升模型的性能。在接下来的章节中,我们将看到深度学习和金融数据分析结合的实际操作案例,并探讨模型部署和未来的发展趋势。
简介:本项目通过Python编程语言和TensorFlow库构建基于CNN的股票走势分析模型,旨在提高预测的准确性和效率。首先,介绍了TensorFlow的基础知识,然后详细阐述了构建、训练CNN模型的步骤,包括数据预处理、模型构建、训练、评估预测和结果可视化。源码中包含了数据处理和模型训练的详细代码,为学习深度学习在金融领域的应用提供了实践案例。