说明
Softmax回归是用来做分类的,它是逻辑回归(Logistic regression)的拓展,后者只针对二分类(当然,我们可以用“一对一”和“一对多”的思路将逻辑回归应用于多分类任务),而softmax回归可直接用来做多分类。
关于分类问题,我在本专栏机器学习_墨@#≯的博客-CSDN博客之前的博文中聊过:感知机[1]、SVM[2]、逻辑回归[3],读者可以移步了解。有了之前工作的铺垫,本文对softmax回归的论述会更简化。 本文的目的在于捋清楚有关Softmax回归的基本理论,并在理论的指导下进行简单的多分类实践。
Blog
2024.10.29 博文第一次写作
目录
一、Softmax回归概述
1.1 Softmax回归概述以及逻辑回归的回顾
Softmax回归也称为多项逻辑回归,是逻辑回归的广义形式,可以用于解决多类别的分类问题。 Softmax回归可以把输入特征映射到多个类别的概率分布上,从而预测(给出)样本属于每个类别的概率。
回顾一下逻辑回归[3]:在逻辑回归中,我们用sigmoid函数将样本特征映射到(0 1)区间内,我们给逻辑回归构建的模型是:
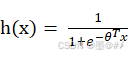 (1-1)
(1-1)
式中,θ为各特征的权值构成的向量,x为样本特征构成的向量。h(x)取值在(0 1)区间,假设其值为P,我们可以设定:
 (1-2)
(1-2)
且P就是样本属于类别1的概率。
上述模型下,我们只能对样本进行二分类,如果有3种及以上类别,我们无法基于上述模型进行直接的分类。有没有可以直接进行多分类的方法?Softmax回归就是为解决这个问题而诞生的。
1.2 Softmax回归的模型、优化准则以及优化算法
我还是以模型、优化准则(或损失函数)、优化算法这机器学习的三要素来对Softmax回归进行详细介绍。【读者可以注意到:从本专栏的第一篇博文[4]引入机器学习三要素后,我在后续的博文中对各类问题的探讨主要就是围绕这三要素进行拆解的,这三点对于我们理解各类模型和算法至关重要!】
关于模型:Softmax回归中,我们引入了softmax函数对样本特征做映射,首先介绍一下softmax这个函数,该函数的表达式为:
![]() (1-3)
(1-3)
输出y和输入的x一一对应,其中:
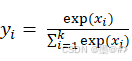 (1-4)
(1-4)
从上式可知,输出的yi是一个在(0 1)区间内的概率值,且所有的yi相加之和为1。(其实就是一个把全部的输入求指数后再归一化的过程)。
如何把上述函数用到多分类问题上? Softmax回归下,假设有K个类别,此时,我们可以构建K组权值参数(其实有点类似逻辑回归一对多思路求解多分类问题时,我们要构建K个分类器),对于每个样本,在K组参数下(‘K个分类器下’)可以得到K个输出值,然后我们将这K个值输入到softmax函数中,进而得到该样本属于每个类别的概率值,最后,我们认为其中最大概率值对应的类别为该样本所属的类别。
用数学语言表达如下:假设单个样本的特征所构成的向量为:
![]() (1-5)
(1-5)
上式中,n为样本特征数,为了方便将截距引入到参数矩阵中,我们加入了![]() ,k组参数(各特征对应的权值)为:
,k组参数(各特征对应的权值)为:
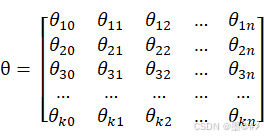 (1-6)
(1-6)
线性模型下,有:
![]() (1-7)
(1-7)
此时可以得到由k个y值构成的向量Y,我们把Y输入到softmax函数,得到概率值P:
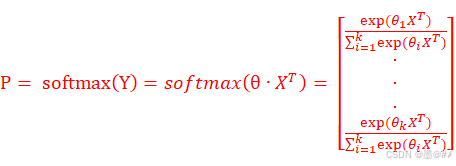 (1-8)
(1-8)
随后,对P取最大值对应的类即为该样本所属的类别:
![]() (1-9)
(1-9)
以上,算是解决了softmax回归的模型问题。
关于优化准则(或损失函数):我们给Softmax回归设计的优化准则(损失函数)为:
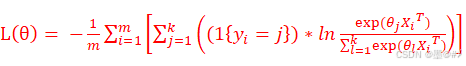 (1-10)
(1-10)
式中,假设一共有k个类别(分别是:1、2、3…K);m为训练集的样本数量;yi是训练样本i所属的真实类别;表达式 ![]() 会输出0或1两种结果,当 yi==j 时,该表达式为1,否则为0;如式(1-6)所示,θ其实是一个k*(n+1)的矩阵,式(1-10)中的 θj 表示第j行的θ值。
会输出0或1两种结果,当 yi==j 时,该表达式为1,否则为0;如式(1-6)所示,θ其实是一个k*(n+1)的矩阵,式(1-10)中的 θj 表示第j行的θ值。
至于为什么要设计成上面的样子,和逻辑回归里我们所设计的损失函数类似,这里头涉及到比较高级和繁琐的数学推导,不做展开。
关于优化算法:还是使用梯度下降法来求解参数值,对式(1-10)求θj 的偏导(注意:这里是针对整行的θ值!),经过化解后,最终可以得到迭代公式为:
Repeat:
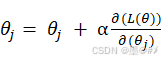 (1-11)
(1-11)
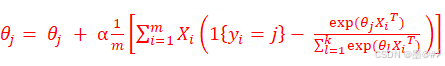 (1-12)
(1-12)
式中,α为学习率。具体的推导过程,读者可以参考[5],(过程不是很复杂)。
有了模型、优化准则、优化算法后,我们就可以编程求解了。
二、基于softmax回归的多分类实践
2.1 数据集说明
本章我将使用在之前的SVM博文[6]、逻辑回归博文[3]、以及聚类的博文[8]中都用到的UCI里的Iris鸢尾花卉数据集[7]作为多分类的实践对象。(该数据集读者可以从[7]的链接中下载,不过我也和代码一并上传到了第五章的链接中)。关于该数据集比较细致的介绍读者可以参考我博文[8]中2.1节的内容。
总之,该数据集一共有150个样本,分为三类,每类有50个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)。
后续使用时,我将分别随机地从各个类中挑选38个样本作训练集,剩下的12个样本作为测试集。进行模型的训练和分类实践。
2.2 多分类实践
整个代码的实现流程如下图所示:

图2.1 Softmax回归的典型处理流程
在本章的实践中,我预设学习率为0.05;θ值随机初始化为一个3*5的矩阵;迭代次数预设为1000次。(读者可以在我后文提供的代码的基础上做一些其它参数下的尝试) 得到的结果如下:
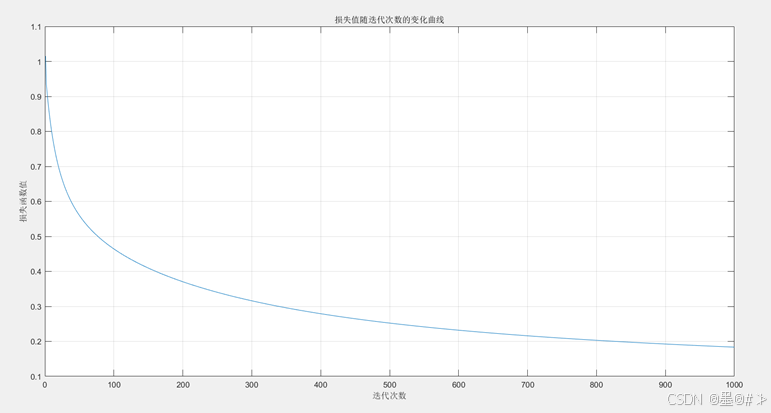
图2.2 损失值随迭代次数的变化曲线
从上图可以看到明显的收敛趋势。分类的结果不是很好可视化(我在逻辑回归[3]里有一些尝试),这里直接给出模型参数的结果以及分类的结果:

图2.3 模型参数结果

图2.4 模型对训练集以及测试集的分类结果
结果符合预期,验证了理论以及所编代码的正确性。我在博文[3]中得到的准确率也为1,这两结果似乎都优于在[6]中使用SVM进行分类的结果。(更细节的对比,读者可以自行基于这三篇博文和所提供的代码做进一步的探讨)。
三、总结
本文对Softmax回归做了探讨和实践。首先对Softmax回归的概念做了基本介绍;随后从模型、优化准则、优化算法三个方面对Softmax实现多分类的原理和方法进行了阐述;最后,在前述理论的指导下,自编代码实践了对UCI里的Iris(鸢尾花卉)数据集的分类。
本文的工作进一步丰富了专栏:机器学习_墨@#≯的博客-CSDN博客的工具箱!为后续更复杂的深度学习等内容的理解和实践打下了基础。
四、参考资料
[1] 感知机及其实践-CSDN博客
[2] SVM及其实践1 --- 概念、理论以及二分类实践-CSDN博客
[3] Logistic回归(分类)问题探讨与实践-CSDN博客
[4] 机器学习系列篇章0 --- 人工智能&机器学习相关概念梳理-CSDN博客
[5] softmax回归(Softmax Regression)-CSDN博客
[6] SVM及其实践2 --- 对典型数据集的多分类实践-CSDN博客
[7] UCI Machine Learning Repository
[8] (毫米波雷达数据处理中的)聚类算法(2) – DBSCAN算法及其实践-CSDN博客