点击下方卡片,关注“自动驾驶Daily”公众号
戳我-> 领取近15个自动驾驶方向路线
今天自动驾驶Daily今天为大家分享CUDA与TensorRT面试一百问。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶Daily技术交流群
自动驾驶之心+自动驾驶之薪+具身智能之心知识星球 | 双十一活动限时7折

CUDA编程入门
1、CUDA核函数嵌套核函数的用法多吗?
答:这种用法非常少,主要是因为启动一个kernel本身就有一定延迟,会造成执行的不连续性。
2、代码里的 grid/block 对应硬件上的 SM 的关系是什么
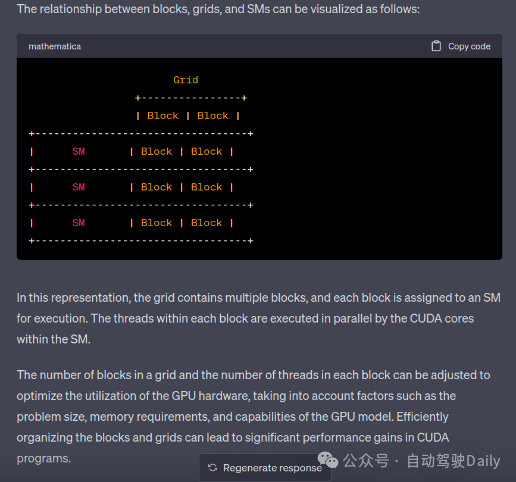
来源:星球内部资料《CUDA与TensorRT面试一百问》,文末扫码获取!
答:首先需要理解grid/block是软件层的概念,而SM是硬件层的概念。所以我们在GPU中是找不到grid/block的,所以只能抽象去理解这个关系。一般来讲一个kernel对应一个grid,分给多个SM去处理。之后每一个SM去处理一个grid中的多个block。这里需要注意的是,block不可以跨越SM去分配,也就是一个block里面的多线程统一由同一个SM中分配资源。因为block中的thread是共享资源的(比如shared memory)。
3、jetson系列,一般都是共享内存,是不是不需要使用cudaMemcpy这个函数了? 要使用其他的memcpy方式吗?
答:关于共享内存在英伟达官方做了一个简短的介绍,链接如下,帮助理解 https://developer.nvidia.com/zh-cn/blog/using-shared-memory-cuda-cc/
对于共享内存的shared-memory-cuda-cc/使用,Jetson系列确实可以直接访问共享内存而无需使用cudaMemcpy函数。首先,理解一下cudaMemcpy函数的功能: (库函数官方介绍)
http://horacio9573.no-ip.org/cuda/group__CUDART__MEMORY_g48efa06b81cc031b2aa6fdc2e9930741.html
从这个函数的介绍,翻译理解一下是将 count 个字节从 src 指向的内存区域复制到 dst 指向的内存区域。是将一个内存空间中的数据复制到另个内存空间中。关于这个函数及相关函数的用法,主要是用于主机内存与GPU内存之间的数据传输,或者是其他内存间的拷贝工作。而共享内存用于 同一个线程块内的线程之间共享数据,所以不涉及到内存数据的转移的话,不用copy函数。故 得出上述结论。。
回答:这里提问者估计混淆了一个概念,你这里想表达的是统一内存(unified memory)而不是共享内存(shared memory)。shared memory无论是不是jetson,只要是GPU一般都会有的概念。而unified memory是Jetson中的概念,表示的是CPU和GPU共享同一片“虚拟”内存(注意这里实际意义上还不是共享同一片物理内存)。所以也就没有了CPU到GPU的数据拷贝过程。使用unified memory的编程方式跟平时有一些差异,你可以看看这篇文章,写的比较详细。以及官方文档 https://developer.ridgerun.com/wiki/index.php?title=NVIDIA_CUDA_Memory_Management#Unified_Memory_Programming_.28UM.29 https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#unified-memory-programming
4、host内存应该不能直接传到share memory吧?肯定要过一次显存,我理解的没问题吧?如果遇到只需要读一次的情况,比如说resize操作,是不是就不需要用到共享内存了呢
答:shared memory中的数据是从显存(global memory)中取出来的,所以需要先过一次显存。默认下kernel中如果没有特殊指定,会跳过shared memory直接从global memory中取数据。所以你说的只读一次的情况是可以不用共享内存的。
5、对这个图有点疑问,按照左边的启动方式,如果d2h1需要等kernel3之后才运行,那为什么kernel1不需要等h2d3之后?
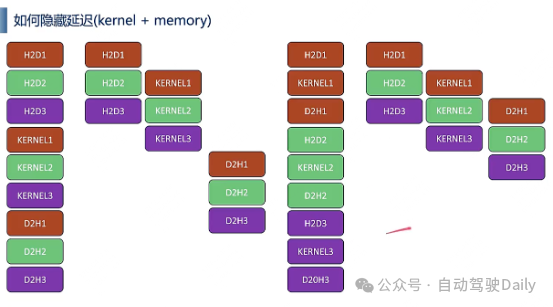
来源:星球内部资料《CUDA与TensorRT面试一百问》,文末扫码获取!
答:这是一个坑也是很让人困惑的地方。之前咨询过NVIDIA那边问为什么会出现这种现象。那边的解释说如果kernel call是连续的,那么即便是多stream,后续的memory copy会等待到最后一个kernel call结束以后再开始调用。估计是资源占用问题导致memory queue队列的signal没有办法issue了。这是一个特殊情况,一般连续kernel call这种方式不被推荐使用。
6、麻烦问一下大家,2.4章节,定义宏的时候,加call与不加call有什么区别呢?
答:第一个用在调用cuda_runtime提供的API函数,所以,都会返回一个cudaError_t类型的变量,需要将变量传入到第一个函数,效验调用API是否正常执行。第二个,使用在自己写的核函数时,自己写的,一般没有返回cudaError_t类型变量,不用传参,如果想知道错误,调用getlastcudaError(),获取系统给你报的错,所以,第二个在函数里面点用了getlastcudaError不用传参。
7、求助一下大家,不知道这块的访存量怎么理解,是不是缺少了cin输入read的feature项呢

答:这个访存量你这么理解,仿存包含read和write的部分。如果说conv的计算主要就是C=A*B的话,A和B的部分是read, C的部分是write。所以说上面的公式分解开的话:
的部分是kernel与input的计算部分,属于read
的部分是output的部分,属于write
8、这两个函数分别在什么情况下使用,区别是什么

来源:星球内部资料《CUDA与TensorRT面试一百问》,文末扫码获取!
答:区别在于错误时候继续传播下去。你看一下这个英语解释就理解了。cudaGetLastError如果检测到最近的call有错误,那么就会报错,但之后会恢复回cudaSuccess。也就是如果出现了错误,及时找到错误。但是cudaPeekAtLastError的话,并不会回复cudaStatus, 一个call如果出错了,其他后续的call都会一直报错,即便其他的call并没有出错。
9、Texture memory 是off chip 还是 on chip?
答:Texture memory是on-chip的memory,可以快速访问的
10、8704个cuda core是怎么算的?int32 Fp32 fp64加起来每个SM 160个cuda core?


答:Ampere架构下有很多个GPU型号,比如说GA100、GA102、GA103等等。他们都是属于Ampere架构下的GPU,只不过配置会有点不同。主要是因为虽然都是Ampere架构但是会针对不同场景。比如服务器端的高配Ampere架构GPU和desktop端的Ampere架构的GPU的CUDA core、Tensor core、SM数量会不一样。
PPT里这个图是Ampere架构下的GA100型号的GPU,使用这个型号GPU的大家比较熟悉的就是A100了。里面的SM的数量会更多一点(108个),并且有针对FP64的CUDA core。但没有很多跟图像处理相关的东西,比如RT core。很明显这种架构就是用来做大量计算的。这也是为什么A100很适合学习,但不适合跑omniverse这种。
后面这个图是GA102型号的GPU,使用这个型号GPU的大家熟悉的就是3080了,主要是用在desktop端。我们可以看到GA102里缩小了FP64计算的部分,但增大了RT(Ray tracing)的部分。很明显是为了desktop端更多元的使用(游戏、图像处理这些)

来源:星球内部资料《CUDA与TensorRT面试一百问》,文末扫码获取!
11、下面图中的这句话不太理解

答:因为是异步执行的,所以两个cudaEventRecord之间的时间间隔间可能会发生其他stream的时间,导致会有一些误差。
12、它去计算8或16位,是硬件电路简单或复杂的方式来实现的,无论乘法器如何设计,结果以一个时钟周期为准,如果cuda core时钟周期内能做一次FMA,就等于2次 FLOPS。老师是这么讲的,这些信息里有啥修正的吗?

来源:星球内部资料《CUDA与TensorRT面试一百问》,文末扫码获取!
答:我重新看了一下这里的PPT。这个地方写的是没有错误的。这里说的1024个FP16计算就是FMA计算,在计算Throughput的时候有一个*2项表示了一个FMA等于两次计算。至于上面画的(256 * 4)指的是一个tensor core在1ck可以做256个FMA,但一个SM中有4个tensor core,所以是4乘以256,这个在下面的公式体现出来了。相反,我发现前面有一个地方打错字了,我修改了一下之后重新上传了。
13、图像数据在GPU显存中的排列顺序是chw还是hwc?
答:你可以选择chw,也可以选择hwc。看你怎么排序都可以。
TensorRT基础入门
1、为什么trtexec转换engine时,采用FP16推理、INT8量化,推理延时可能变得更久?
答:可能原因是:
a. 量化后可能会引入一些多余的计算操作和内部的一些reshape。对于小模型,多余的计算带来的延时并不明显;而reshape会涉及一些内存操作,这个是延时变长的主要原因。对于reshape引起的延时变长,我们的解决办法是让TensorRT不做一些额外的这些操作,但TensorRT内部产生的reshape我们没有办法解决的。
b. 另外,TensorRT有kernel auto tuning的机制,因此选择的kernel不一定是效率最高的。
2、什么是Myelin?
答:这是TensorRT内部的一个概念,负责graph compilation(图编译)和execution backend(执行后端)的内容。
3、constant cache和constant memory的区别?
答:constant cache和constant memory是两个概念,cache更靠近计算单元,所以速度更快。constant cache是以前GPU版本中的概念,比如早期Fermi架构的SM block(左图)。而现在Ampere架构的SM如右图所示。
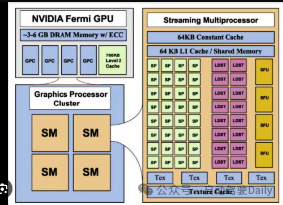
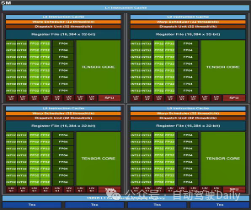
4、在cuda, cudnn, tensorrt版本相同的情况下,可以将其他电脑上转换好的trt直接在自己电脑运行吗?
答:不同的GPU架构针对trt的优化方式不一样,所以移植到另外一个平台可能会不兼容。
5、请教一个问题:对于比较大的模型,对于边缘设备trtexec搜寻时间太长有什么好的方法或者技巧么?(转engin搜寻最优的layer的过程时间过长)
答:创建 engine的时候必须要在推理用的设备上跑,边缘设备上可能会稍微慢一点。但是,如果对于同一个模型进行多次创建engine,或者只对模型部分layer做了修改其他大部分layer没有动(比如在调试或者测试的时候)的话,我们可以在第一次创建的时候把各个layer所对应的trt探索得到的最优tactics,也就是核函数和优化方案以某种方式保存下来。第二次以后再创建模型的时候,读取我们所保存的tactics就可以让trt skip掉已经探索所得到的优化方案。这个就是Timing cache。在trtexec命令行和TensorRT API下都可以指定。你试着参考一下这里。https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#opt-builder-perf
TensorRT模型部署优化
1、模型部署后,用什么手段分析推理性能?
答:可以利用Nsight工具分析模型推理性能。通过该工具可以捕获模型各个kernel运行的时间。针对运行情况,我们再做优化。
2、神经网络中吞吐和延迟的关系?
答:吞吐是用来描述一个硬件设备单位时间内可以完成的计算量;延迟是用来描述一个模型推理所需的时间。延迟又分为计算产生的延迟和数据传输(包括数据同步)造成的延迟。我们可以用nsys和Nsight Compute工具定量分析不同阶段的延时情况。
3、tensorrt量化方法?
答:trt默认和推荐的量化算法是entropy,但具体需要看情况,有时候选择minmax或者percentile会达到更好的效果。这个需要结合op的特点一起考虑。
4、模型导出fp32的trt engine没有明显精度损失,导出fp16损失很明显,可能的原因有哪些?
比较突出的几个可能性就是:对一些敏感层进行了量化导致掉精度比较严重,或者权重的分布没有集中导致量化的dynamic range的选择让很多有数值的权重都归0了。另外,minmax, entropy, percentile这些计算scale的选择没有根据op进行针对性的选择也会出现掉点。
5、onnx模型推理结果正确,但tensorRT量化后的推理结果不正确,大概原因有哪些?
出现这种问题的时候,需要先确认两种模型推理的前处理(例如,对输入的各种预处理需要和pytoch模型的训练预处理完全一致)和后处理是否一致。确认是量化引起的问题时,可能原因有:
a. calibrator的算法选择不对;
b. calibration过程使用的数据不够;
c. 对网络敏感层进行了量化;
d. 对某些算子选择了不适合OP特性的scale计算。
6、采用tensorRT PTQ量化时,若用不同batchsize校正出来模型精度不一致,这个现象是否正常?
答:这个现象是正常的,因为calibration(校正)是以tensor为单位计算的。对于每次计算,如果histogram的最大值需要更新,那么PTQ会把histogram的range进行翻倍。参考链接:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#enable_int8_c

不考虑内存不足的问题,推荐使用更大的batch_size,这样每个batch中包含样本更加丰富,校准后的精度会更好。但具体设置多大,需要通过实验确定(从大的batch size开始测试。一点一点往下减)。需要注意的是batch_size越大,校准时间越长。
7、关于对齐内存访问的疑问:如果使用L1cache,访问的颗粒度为128B,对齐的首地址应该为128B偶数倍,不应该是0B,256B,512B.......吗?
答:实际上这里的偶数倍(even multiple)指的是地址是偶数倍的,并非128B的偶数倍。比较官方的解释可以参考如下链接:https://www.nvidia.com/content/PDF/sc_2010/CUDA_Tutorial/SC10_Fundamental_Optimizations.pdf
8、同一个模型,3090 GPU转换成功,但RTX4000转换失败,该如何解决?(具体错误信息见下图)
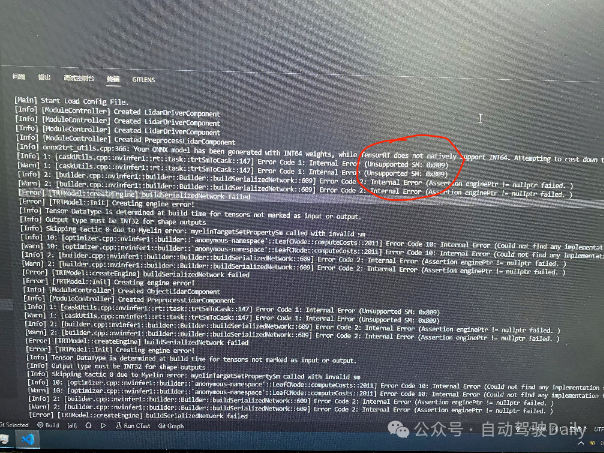
答:此处提示SM相关错误,所以可以检查makefile或CMakeLists.txt中对nvcc编译器option的设定是否存在问题。
9、如何使用nsight或CUDA runtime api分析模型推理性能?
答:通过nsight可以看到核函数的名字(可通过名字推测它是用cuda core或tensor core, fp16还是int8)还有可以查看memory的流动。
10、如何尽量减少GPU和CPU之间的数据交互或内存分配与回收?
答:由于在推理过程中,CPU与GPU之间的数据拷贝耗时较长或出现频繁分配和回收内存的现象,这大大降低了模型推理性能。我们可以采用在推理模型前分配好所需要的最大内存(做到内存复用)以降低内存分配或回收的次数。针对CPU与GPU之间数据相互拷贝问题,我们需要优化代码流程,尽量减少拷贝的次数或寻找更好的方法去掩盖这个动作需要的时间。
11、如果QAT可以使模型尽可能减少量化带来的误差,那么可以不做敏感层分析,直接将整个网络量化为INT8吗?
答:不建议这么做,从经验来看,敏感层量化到INT8精度会下降很多,所以还是有必要进行敏感层分析。
12、模型量化到INT8后,推理时间反而比FP16慢,这正常吗?
答:正常的,这可能是tensorrt中内核auto tuning机制作怪(会把所有的优化策略都运行一遍,结果发现量化后涉及一堆其他的操作,反而效率不高,索性使用cuda core,而非tensorrt core)。当网络参数和模型架构设计不合理时,trt会添加额外的处理,导致INT8推理时间比FP16长。我们可以通过trt-engine explorer工具可视化engine模型看到。
13、请教一下,engine推理的时候,batchsize=1和batchsize=4,推理时间相差也接近4倍合理吗?有什么办法让多batch的推理时间接近单batch吗?比如加大显存?
答:这个可能出现的原因有很多,有可能单个batchsize的推理就已经把GPU资源全部吃满了,所以batchsize=4的时候看似加大了并行度,实际上也可能是在串行。建议把模型推理放在nsight system上分析一下,看看硬件资源占用率。
14、在device固定的情况下呢?有什么参数设置或者增加streams的方式吗?试过把workspace设到最大,只有轻微的提升
答:workspace的大小跟性能提升关联不大,workspace是使用在创建推理引擎时TensorRT选择tactics来进行优化的,workspace越大可以选择的tactics越丰富。但除非特别的小,一般关联不是那么大。试试fp16, int8这种量化参数来试试量化,cuda-graph来试试kernel launch的隐藏,builderOptimizationLevel的等级设置高一点等等。光靠参数优化还是有点局限。可以看看模型架构是否有冗长。
自动驾驶之心+自动驾驶之薪+具身智能之心知识星球 | 双十一活动限时7折
