本文收录于专栏:算法之翼
计数布隆过滤器的高级变种:解决动态集合操作中的限制
布隆过滤器(Bloom Filter)是一种高效的空间节省型数据结构,用于判断元素是否属于一个集合。传统布隆过滤器具有较低的误判率,能高效地存储大量数据,但存在一个关键问题:一旦插入了某个元素,便无法删除它。这是因为布隆过滤器的每个 bit 位在插入元素时都会被设置为 1,无法直接判断哪些 bit 位是由某个特定元素触发的。因此,当涉及到需要插入和删除元素的动态集合时,传统布隆过滤器显得有些不足。为了解决这一问题,衍生出了 Counting Bloom Filter(计数布隆过滤器)。
什么是 Counting Bloom Filter
Counting Bloom Filter(CBF)是布隆过滤器的一种扩展,它使用计数器而非简单的 bit 位来表示某个位置的状态。这使得 CBF 能够支持删除操作:当元素插入时,对应位置的计数器增加;当元素删除时,计数器减少。只有当计数器为零时,表示该位置上没有任何元素。
计数布隆过滤器的基本原理
CBF 使用一个计数数组代替传统布隆过滤器的 bit 数组。这个计数数组中的每个单元都可以存储一个较大的值,而不是简单的 0 或 1。通常,计数器使用 4-bit 或 8-bit 存储每个位置上的计数值。CBF 的插入和查询操作与传统布隆过滤器类似,主要的不同体现在删除操作上。
- 插入:将要插入的元素通过多个哈希函数进行哈希,将相应的计数器值加 1。
- 查询:通过哈希函数计算出对应的多个位置,如果所有计数器值均大于 0,则判定该元素存在于集合中。
- 删除:通过哈希函数找到对应位置,将相应的计数器减 1。当计数器降到 0 时,表示该位置没有任何元素映射到此。

Counting Bloom Filter 的优势与劣势
优势
- 支持删除操作:与传统布隆过滤器相比,CBF 最显著的优势是支持删除操作,这是在动态集合中不可或缺的功能。
- 灵活性高:由于使用计数器,CBF 可以处理多个插入、删除操作,适用于对集合频繁变动的应用场景。
劣势
- 空间开销增加:由于需要存储计数器,CBF 的空间复杂度高于传统布隆过滤器。特别是在使用 8-bit 甚至更大的计数器时,所需的内存会显著增加。
- 误判率:CBF 与传统布隆过滤器一样,也存在误判率。随着插入的元素数量增加,哈希冲突的概率增大,从而导致更多的误判。
- 计数器溢出:如果计数器的位数较小,当插入过多的元素时,计数器可能会溢出,导致误删的风险。
Counting Bloom Filter 的应用场景
1. 缓存管理
在缓存替换算法中,CBF 可以用来高效跟踪缓存中存在的元素。因为 CBF 支持删除,所以在缓存替换时,可以快速将已删除的元素从布隆过滤器中移除,避免误判。
2. 数据库去重
CBF 在数据去重操作中表现出色,特别是在需要对海量数据进行频繁插入和删除操作时。例如,在分布式数据库中,它可以用于判断某条记录是否已经被处理或存储。
3. 网络安全
CBF 可以用于检测恶意网络请求。对于频繁出现的恶意 IP 地址或域名,CBF 可以动态地将它们从过滤器中移除或添加,从而提高网络防护的灵活性。
代码实现
以下是一个简单的 Counting Bloom Filter 实现示例,使用 Python 和 bitarray 库来模拟布隆过滤器的基本操作:
from bitarray import bitarray
import mmh3
class CountingBloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.count_array = [0] * size
def _hashes(self, item):
return [mmh3.hash(item, seed) % self.size for seed in range(self.hash_count)]
def add(self, item):
for i in self._hashes(item):
self.count_array[i] += 1
def remove(self, item):
if self.contains(item):
for i in self._hashes(item):
self.count_array[i] -= 1
def contains(self, item):
return all(self.count_array[i] > 0 for i in self._hashes(item))
# 示例使用
cbf = CountingBloomFilter(size=100, hash_count=3)
cbf.add("apple")
print(cbf.contains("apple")) # 输出 True
cbf.remove("apple")
print(cbf.contains("apple")) # 输出 False
在这段代码中,我们实现了 Counting Bloom Filter 的三个核心功能:插入(add)、删除(remove)和查询(contains)。通过 mmh3 哈希函数,我们为每个元素生成多个哈希值并对相应计数器进行操作。

Counting Bloom Filter 的优化与变种
在实际应用中,尽管 Counting Bloom Filter 提供了支持删除操作的功能,但为了进一步提升其效率和性能,一些优化和变种被提出。这些优化主要集中在减少空间开销、降低误判率和提高计数器操作的效率上。
1. Compressed Counting Bloom Filter
Compressed Counting Bloom Filter(压缩计数布隆过滤器) 是针对 Counting Bloom Filter 空间开销较大的问题提出的一种改进。通过对计数器进行压缩编码,可以减少 Bloom Filter 所占用的内存。
压缩的思想是将计数器的增长限制在一定范围内。例如,对于一个频繁插入相同元素的场景,我们不需要无限地增加计数器的值,因此可以采用非线性计数法,如对数计数器,将计数值映射到更小的表示范围中,从而节省存储空间。
2. Spectral Bloom Filter
Spectral Bloom Filter(光谱布隆过滤器) 是一种进一步优化的计数布隆过滤器,主要用于解决重复插入和多次删除的问题。它不仅存储了元素的存在性信息,还存储了元素被插入的次数。因此,Spectral Bloom Filter 可以精确地支持多次删除操作,而不是简单的递减计数器到零。
Spectral Bloom Filter 的一个重要应用是在数据库或多级缓存系统中,可以记录某个元素被访问的频率,帮助优化缓存替换策略。例如,当某个数据项的访问次数减少到一定阈值时,便可以从缓存中移除。

3. Scalable Counting Bloom Filter
Scalable Counting Bloom Filter(可扩展计数布隆过滤器) 是为了解决布隆过滤器在动态环境中容量有限的问题而提出的改进。在传统的布隆过滤器中,滤器的大小是固定的,一旦设置完初始大小,就无法随数据增长而扩展。
Scalable Counting Bloom Filter 通过动态增加新的计数布隆过滤器层来解决容量问题。当一个布隆过滤器饱和时,会创建一个新的更大的布隆过滤器层,并将新的数据插入到该层。这样的结构不仅保持了原有的误判率,还能在存储空间有限的情况下灵活扩展。
4. Dynamic Counting Bloom Filter
与 Scalable Counting Bloom Filter 类似,Dynamic Counting Bloom Filter(动态计数布隆过滤器) 也是为了解决动态数据增长场景中的容量问题。不同的是,Dynamic Counting Bloom Filter 通过增加子过滤器的方式扩展原有的布隆过滤器,并将子过滤器与原过滤器结合在一起。每个子过滤器的大小是可变的,可以根据实际需要动态调整。
5. Hierarchical Counting Bloom Filter
Hierarchical Counting Bloom Filter(分层计数布隆过滤器) 是另一种针对多级数据存储场景的优化。在这种结构中,布隆过滤器被分为多个层级,每一级负责不同的数据范围。例如,在多级缓存系统中,顶层的布隆过滤器可能只负责检测最近访问的数据,而底层的布隆过滤器则负责检测较少访问的数据。通过这种层级划分,可以优化过滤器的查询效率,同时降低空间开销。
Counting Bloom Filter 的实现细节
哈希函数的选择
在实现 Counting Bloom Filter 时,哈希函数的选择至关重要。通常,布隆过滤器使用多个不同的哈希函数来生成多个哈希值。为了减少冲突并均匀分布数据,选择合适的哈希函数可以有效降低误判率。常用的哈希函数包括:
- MurmurHash:一种非加密哈希函数,速度快,冲突率低,常用于各种哈希应用场景。
- FNV Hash:一种高效的哈希函数,适用于对较小的数据块进行哈希计算。
- MD5/SHA:虽然这些哈希函数主要用于加密领域,但在某些场景下,它们也可以用于布隆过滤器的哈希计算,不过速度较慢。
在具体实现中,往往可以通过组合多个哈希函数或对哈希函数的输出进行变换来生成多个哈希值,从而保证不同位置的独立性和分布均匀性。
计数器的位宽设计
Counting Bloom Filter 中计数器的位宽直接影响到内存的使用情况和计数的范围。常见的计数器位宽设计有以下几种:
- 4-bit 计数器:适合较小的数据集,最多支持每个位置被多次插入 15 次。当计数器值超过最大值时,会发生溢出,可能导致误判。
- 8-bit 计数器:每个位置可以存储更大的计数值,适合较大的数据集,最多可以支持 255 次插入操作。
- 16-bit 计数器:适用于非常大的数据集,但空间开销也相应增大,通常用于需要精确记录插入次数的场景。
计数器的选择应根据实际应用场景进行权衡,如果预计数据集的插入次数较多,则应选择更大的计数器;而对于内存空间较为有限的场景,可以采用位宽较小的计数器,同时配合溢出处理机制。
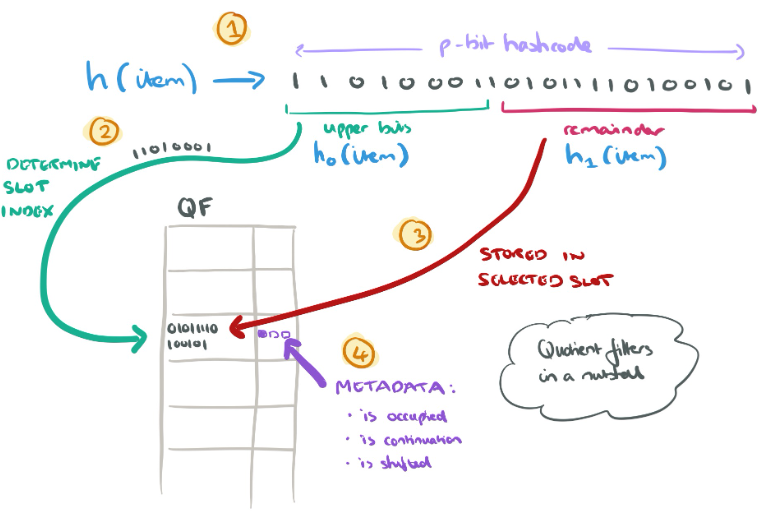
哈希冲突处理
Counting Bloom Filter 由于使用哈希函数,难免会遇到哈希冲突问题。当多个元素映射到相同的位置时,会导致误判的发生。为了解决哈希冲突,常见的处理方法有以下几种:
- 增加哈希函数数量:通过增加哈希函数的数量,可以减少冲突的概率。然而,哈希函数的数量增加会导致查询和插入的时间复杂度上升。
- 增加布隆过滤器的大小:通过增大过滤器的位数组或计数器数组,可以有效降低冲突发生的概率,但会增加内存使用量。
- 调整哈希函数的分布策略:选择更合适的哈希函数,使得哈希值的分布更加均匀,可以降低冲突率。
使用场景中的性能评估
在不同场景下,Counting Bloom Filter 的性能表现差异很大。关键的性能指标包括误判率、查询时间、插入/删除时间以及内存消耗。通过合理配置参数(如哈希函数数量、计数器位宽、过滤器大小等),可以在以下几个场景中达到较优性能:
-
高查询频率场景:在高查询频率的应用中,如 Web 缓存系统或 DNS 服务器,Counting Bloom Filter 的查询时间非常短,因此能够提供快速的查询响应。然而,随着数据量增加,误判率会逐渐上升,因此在这些场景下需要合理控制过滤器的大小。
-
动态集合操作:Counting Bloom Filter 最大的优势之一是支持动态集合操作,如插入和删除。在频繁变动的集合场景中,如数据库中的表格维护、内存管理中的垃圾回收等,CBF 能够有效地处理数据的变化,减少冗余数据。
-
内存受限的场景:对于内存空间较为紧张的应用,如嵌入式系统或 IoT 设备,Counting Bloom Filter 提供了一种相对节省空间的解决方案。

总结
Counting Bloom Filter 是一种在标准布隆过滤器基础上扩展的高级数据结构,通过引入计数器解决了传统布隆过滤器无法删除元素的缺陷。它支持插入、查询和删除操作,广泛应用于网络过滤、数据库管理和缓存系统中。为了进一步提升性能,多个变种如压缩计数布隆过滤器、光谱布隆过滤器、可扩展计数布隆过滤器等被提出。这些优化和变种主要针对空间效率、误判率和动态扩展能力进行改进,使其能够应对更广泛的应用场景。