【语义分割|代码解析】CMTFNet-5: CNN and Multiscale Transformer Fusion Network 用于遥感图像分割!
【语义分割|代码解析】CMTFNet-5: CNN and Multiscale Transformer Fusion Network 用于遥感图像分割!
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz
论文地址:https://ieeexplore.ieee.org/document/10247595
前言
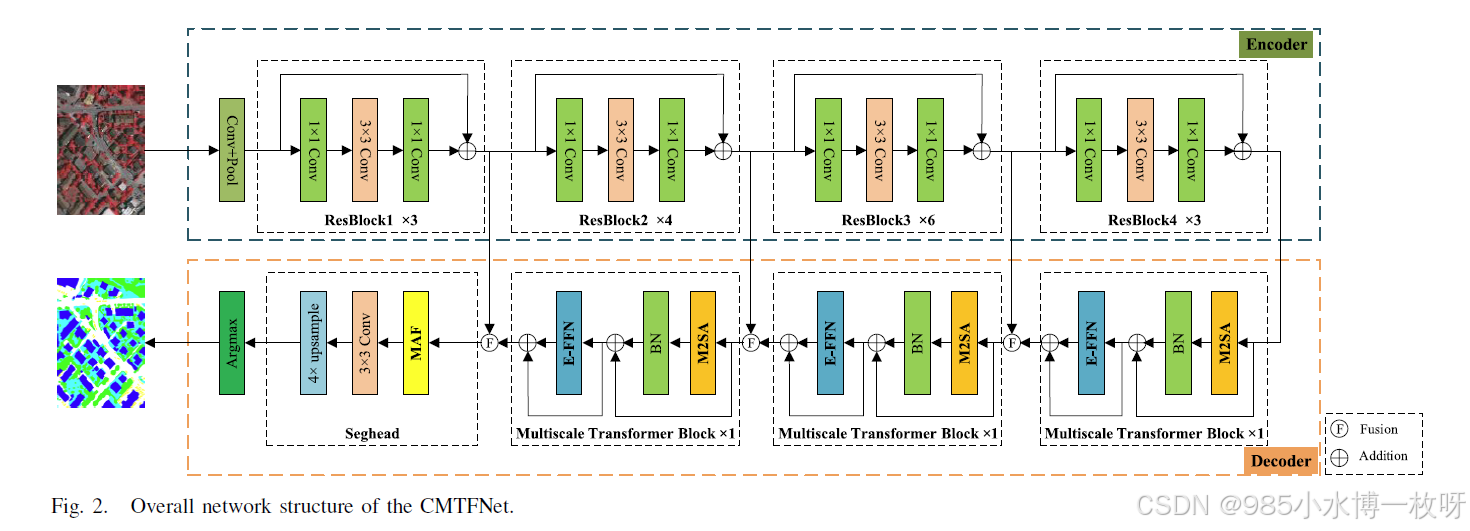
**这段代码定义了一个卷积和多尺度Transformer融合网络(CMTFNet),用于遥感图像的语义分割。该网络由主干网络(backbone)和解码器模块组成。**下面是代码的逐行解释:
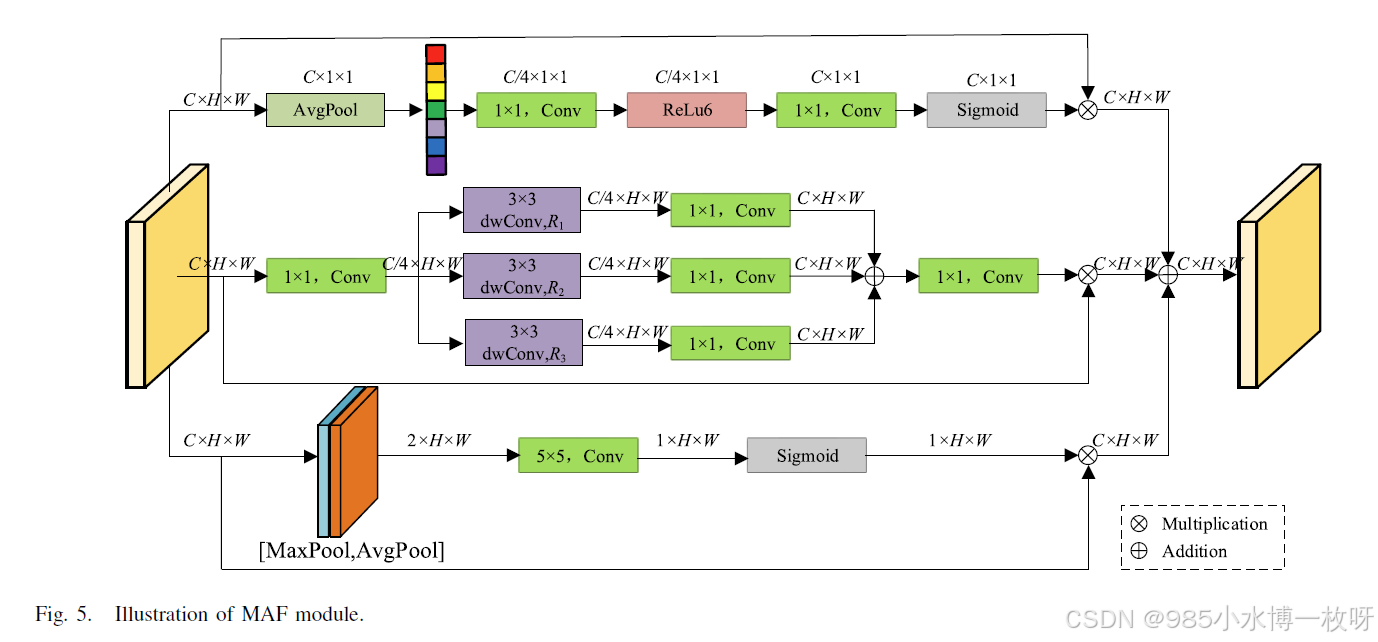
1. 类 MAF
class MAF(nn.Module):
def __init__(self, dim, fc_ratio, dilation=[3, 5, 7], dropout=0., num_classes=6):
super(MAF, self).__init__()
MAF是一个模块,负责多尺度自适应特征提取。dim是输入特征图的通道数。fc_ratio用于减少通道数。dilation控制膨胀卷积的大小,分别为3、5和7。dropout用于随机丢弃连接,以减少过拟合。num_classes是分割任务中的类别数。
多尺度卷积层
self.conv0 = nn.Conv2d(dim, dim//fc_ratio, 1)
self.bn0 = nn.BatchNorm2d(dim//fc_ratio)
conv0是1x1卷积,减少通道数为dim // fc_ratio。bn0进行批归一化。
self.conv1_1 = nn.Conv2d(dim//fc_ratio, dim//fc_ratio, 3, padding=dilation[-3], dilation=dilation[-3], groups=dim//fc_ratio)
self.bn1_1 = nn.BatchNorm2d(dim//fc_ratio)
self.conv1_2 = nn.Conv2d(dim//fc_ratio, dim, 1)
self.bn1_2 = nn.BatchNorm2d(dim)
conv1_1是一个3x3卷积,采用膨胀因子dilation[-3](即3),实现多尺度卷积。bn1_1对卷积后的特征图进行批归一化。conv1_2将通道数恢复为dim。
后续conv2_*和conv3_*层的配置相似,只是膨胀因子不同(分别为5和7),以提取多尺度特征。
其他特征处理层
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(dim, dim//fc_ratio, 1, 1),
nn.ReLU6(),
nn.Conv2d(dim//fc_ratio, dim, 1, 1),
nn.Sigmoid()
)
avg_pool用于生成全局平均池化的特征。fc是一个全连接层结构,用于生成通道注意力。
空间注意力
self.s_conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=5, padding=2)
self.sigmoid = nn.Sigmoid()
s_conv使用5x5卷积提取空间注意力。sigmoid激活生成空间注意力图。
输出头
self.head = nn.Sequential(SeparableConvBNReLU(dim, dim, kernel_size=3),
nn.Dropout2d(p=dropout, inplace=True),
Conv(256, num_classes, kernel_size=1))
head是输出层,用于生成最终的分割结果。
2. 类 Decoder
class Decoder(nn.Module):
def __init__(self, encode_channels=[256, 512, 1024, 2048], decode_channels=512, dilation=[[1, 3, 5], [3, 5, 7], [5, 7, 9], [7, 9, 11]], fc_ratio=4, dropout=0.1, num_classes=6):
super(Decoder, self).__init__()
Decoder类负责解码不同尺度的特征,以进行精确分割。encode_channels是主干网络的各层输出通道数。decode_channels是解码过程中使用的通道数。
解码过程
self.Conv1 = ConvBNReLU(encode_channels[-1], decode_channels, 1)
self.Conv2 = ConvBNReLU(encode_channels[-2], decode_channels, 1)
Conv1和Conv2将编码特征图的通道数转换为解码通道数。
self.b4 = Block(dim=decode_channels, num_heads=16, mlp_ratio=4, pool_ratio=16, dilation=dilation[0])
b4是一个带有多头注意力的块,用于处理特征图。
self.p3 = Fusion(decode_channels)
self.b3 = Block(dim=decode_channels, num_heads=16, mlp_ratio=4, pool_ratio=16, dilation=dilation[1])
p3融合特征图,b3进一步提取特征。
b2和p2等同理,逐层解码特征。
3. 类 CMTFNet
class CMTFNet(nn.Module):
def __init__(self, encode_channels=[256, 512, 1024, 2048], decode_channels=512, dropout=0.1, num_classes=6, backbone=ResNet50):
super().__init__()
CMTFNet是主网络结构,包含主干网络(backbone)和解码器(decoder)。
def forward(self, x):
h, w = x.size()[-2:]
res1, res2, res3, res4 = self.backbone(x)
x = self.decoder(res1, res2, res3, res4, h, w)
return x
- 将输入图像传入主干网络获取多层特征(
res1至res4),并通过解码器获取分割输出
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz