概念
序列化(Serialization)是将对象的状态消息转换为可以存储或者传输形式的过程。
在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
序列化的方式
- 文本格式:代表有 JSON、XML
- 二进制格式:protobuf
文本格式的两种方式大家应该是早有耳闻,可能对 protobuf 不是很熟,我补充一下:

二进制序列化
- 序列化:将数据结构或对象转换成二进制串的过程
- 反序列化:将在序列化过程中所产生的二进制串转换成数据结构或对象的过程
对于二进制序列化来说,序列化后,数据更小、传输速度会更快。
同时二进制序列化和反序列化的速度也会相对于文本格式的序列化方式更快。
why-serialize 用法演示
基本类型序列化、反序列化
基本类型序列化演示:
#include "DataStream.h"
using namespace why::serialize
int main(){
int a = 123;
double f = 1.23;
string s = "hello baby";
//通过DataStream类对象进行序列化操作
DataStream ds;
ds << a << f << s;
//序列化以后我们可以选择将其保存到某文件中或者将其通过网络进行发送
//假设这里保存到a.out文件当中
ds.save("a.out");
return 0;
}
基本类型反序列化演示:
#include "DataStream.h"
using namespace why::serialize
int main(){
//同样是通过ds对象,调用load方法进行反序列化
DataStream ds;
ds.load("a.out");
int a;
double f;
string s;
ds >> a >> f >> s;
std::cout << a << "," << f << "," << s << std::endl;
return 0;
}
复合类型数据序列化、反序列化
这里的复合类型数据指的是类似于数组、map这种的嵌套了别的类型的数据结构类型。
复合类型数据序列化演示:
int main(){
std::vector<int> v{
1,2,3};
std::map<string, string> m;
m["name"] = "kitty";
m["phone"] = "18928384757";
m["gender"] = "male";
DataStream ds;
ds << v << m;
ds.save("b.out");
return 0;
}
复合类型数据反序列化演示:

int main(){
std::vector<int> v;
std::map<string, string> m;
DataStream ds;
ds.load("b.out");
ds >> v >> m;
for(auto it=v.begin();it!=v.end();++it){
std::cout << *it << std::endl;
}
for(auto it=m.begin();it!=m.end();++it){
std::cout << it->first << "=" << it->second << std::endl;
}
return 0;
}
自定义类类型序列化、反序列化
自定义类类型序列化演示:
#include "DataStream.h"
#include "Serializable.h"
using namespace why::serialize
//自定义类A要进行序列化的话需要继承该接口
class A:public Serializable{
public:
A(){
}
A(const string& name,int age): m_name(name), m_age(age){
}
~A(){
}
void show(){
std::cout << m_name << "," << m_age << std::endl;
}
//通过这个宏来确定这个类的哪些成员变量是需要进行序列化的
SERIALIZE(m_name, m_age);
private:
string m_name;
int m_age;
};
int main(){
A a("haha", 18);
//序列化对象
DataStream ds;
ds << a;
ds.save("c.out");
return 0;
}
自定义类类型反序列化演示:
int main(){
//反序列化对象
DataStream ds;
ds.load("c.out");
A a;
ds >> a;
a.show();
return 0;
}
更复杂的自定义类类型的序列化演示:
//A类实现同上
class B: public Serializable{
public:
B(){
}
void add(const A& a){
m_vector.push_back(a);
}
void show(){
for(auto it = m_vector.begin();it!=m_vector.end();it++){
it->show();
}
}
SERIALIZE(m_vector);
private:
std::vector<A> m_vector;
};
int main(){
B b;
b.add(A("jack", 18));
b.add(A("asd", 123));
b.add(A("dfg", 5));
DataStream ds;
ds << b;
ds.save("d.out");
return 0;
}
更复杂的自定义类类型的反序列化演示:
int main(){
DataStream ds;
ds.load("d.out");
B b;
ds >> b;
b.show();
return 0;
}
与 protobuf 的对比
| protobuf | why-serialize | |
|---|---|---|
| 二进制格式 | 是 | 是 |
| 数据体积 | 小 | 小 |
| 编解码速度 | 快 | 快 |
| 数据类型支持 | 丰富 | 更加丰富 |
| 消息定义文件 | 需要 | 不需要 |
| 需要编译 | 需要 | 不需要 |
| 代码实现 | 复杂 | 简单 |
动手实现why-serialize
思考一个问题:要在网络上传输数据,比如一个整形的数字,该如何做?传输好几个整形的数字呢?又该怎么做?
基本类型序列化 + 反序列化
基本数据类型定义
| 字段类型 | 字段长度(字节) | 底层编码格式 |
|---|---|---|
| bool | 2 | Type(1) + Value(1) |
| char | 2 | Type(1) + Value(1) |
| int32 | 5 | Type(1) + Value(4) |
| int64 | 9 | Type(1) + Value(8) |
| float | 5 | Type(1) + Value(4) |
| double | 9 | Type(1) + Value(8) |
| string | 可变长度 | Type(1) + Length(5) + Value(变长) |
以第一行 bool 类型为例进行解释,bool 类型在经过编码以后该字段所占长度为 2 字节,第一个字节指定类型(bool),然后第二个字节就是实际存储的值。剩下的以此类推,这张表就设定了我们基本数据类型的编解码规范。
对于字符串长度的话,使用第一个字节来存储类型,然后用五个字节来存储长度(因为长度的类型我们设置为了int32,而int32被我们编码成了五个字节),而对于字符串值的话是变长的,无法确定。
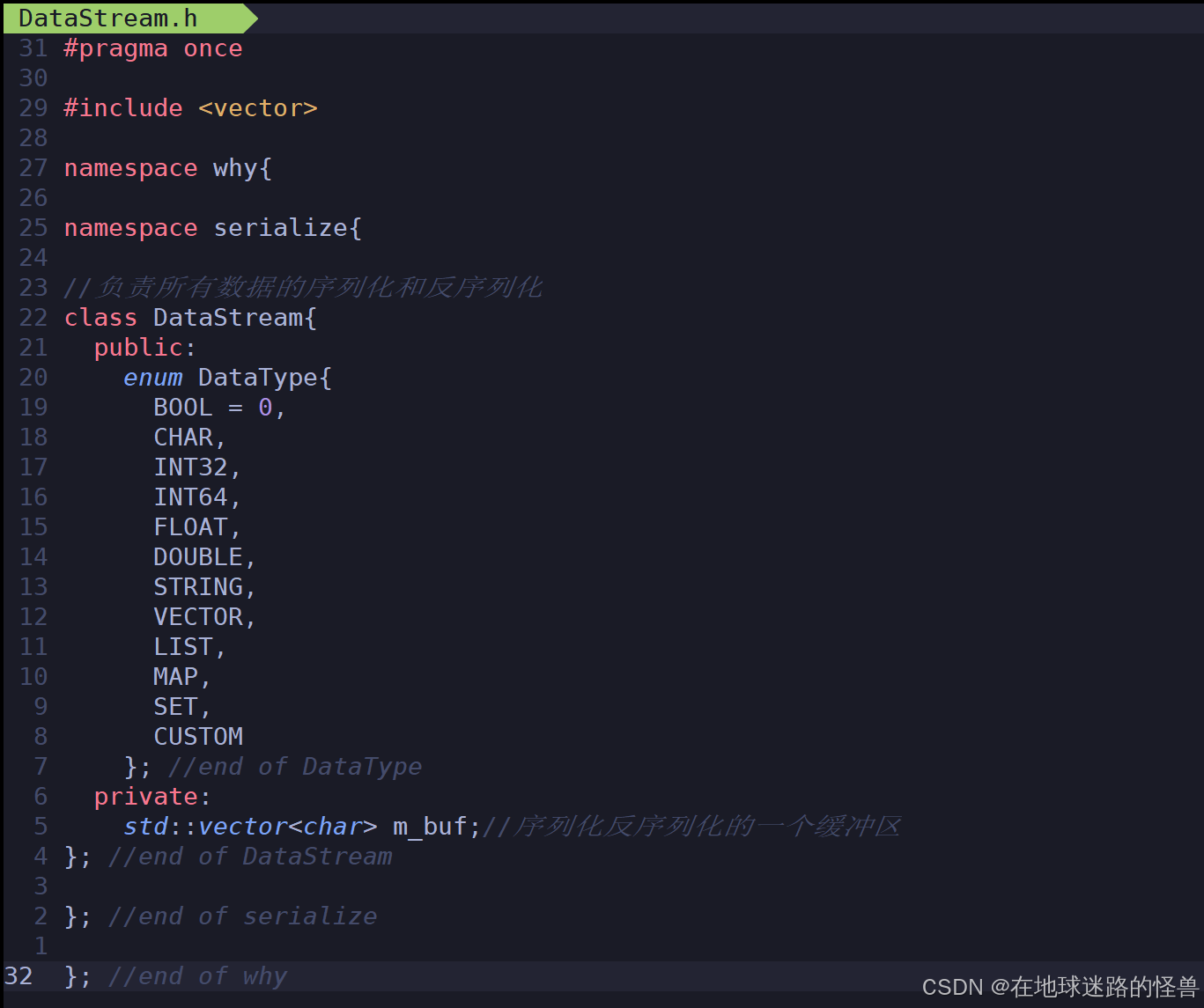
对于底层编码格式的话中的 Type() 类型我们预先设置成了一个枚举类:
enum DataType{
//表示基本类型
BOOL = 0,
CHAR,
INT32,
INT64,
FLOAT,
DOUBLE,
//表示复合类型
STRING,
VECTOR,
LIST,
MAP,
SET,
//表示一种自定义类类型
CUSTOM
};
序列化支持的基本数据类型都在上面的枚举类中了。
基本数据类型编码
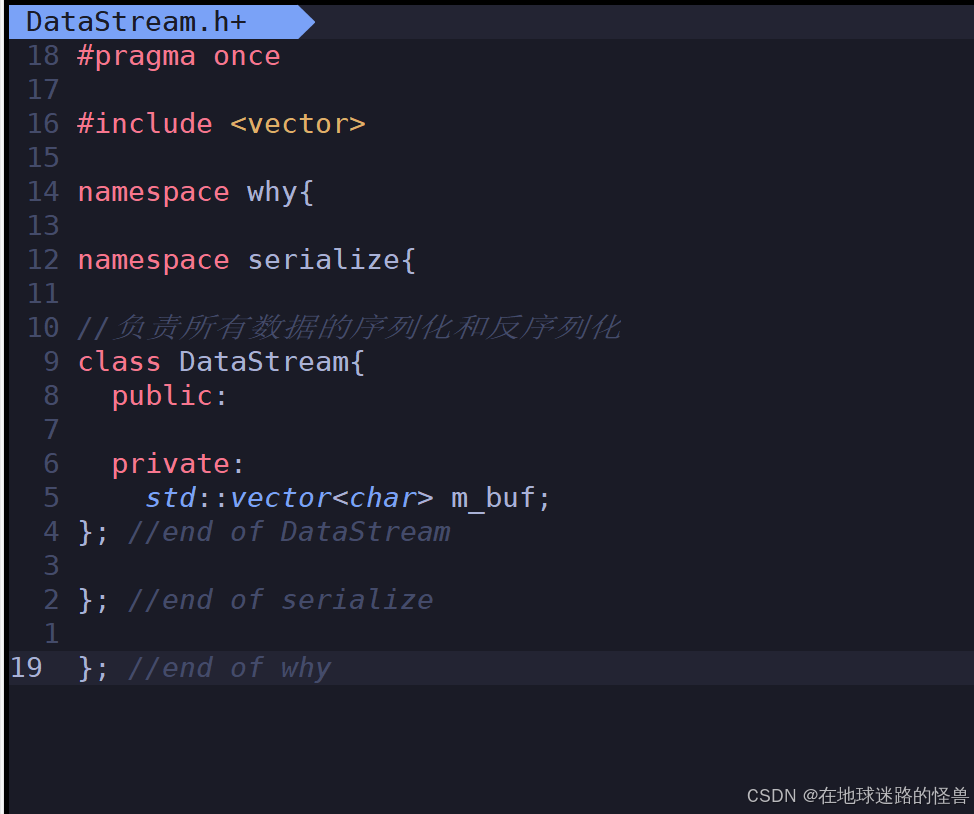
废话不多说,直接开始写代码,先实现 DataStream 这个类,因为其封装了我们所有数据的序列化和反序列化操作。
第一个问题就是,序列化完成以后我们的内容(二进制数据)要存放到哪里呢?这里我们选择一个 vector 中进行存储,相当于序列化和反序列化过程中的一个缓冲区:
然后加入我们的序列化支持的数据类型的枚举定义:
构造函数析构函数不用说肯定是要的,但是在序列化过程中会依赖一个非常非常重要的函数,就是 write(注意不是 Linux 平台的系统调用),我们所有的序列化都是通过 write 这个函数写入到缓冲区 m_buf 中的。
当然这个 write 的肯定是有一系列重载函数的,毕竟要适配众多情况嘛。
先来看其中一个实现:
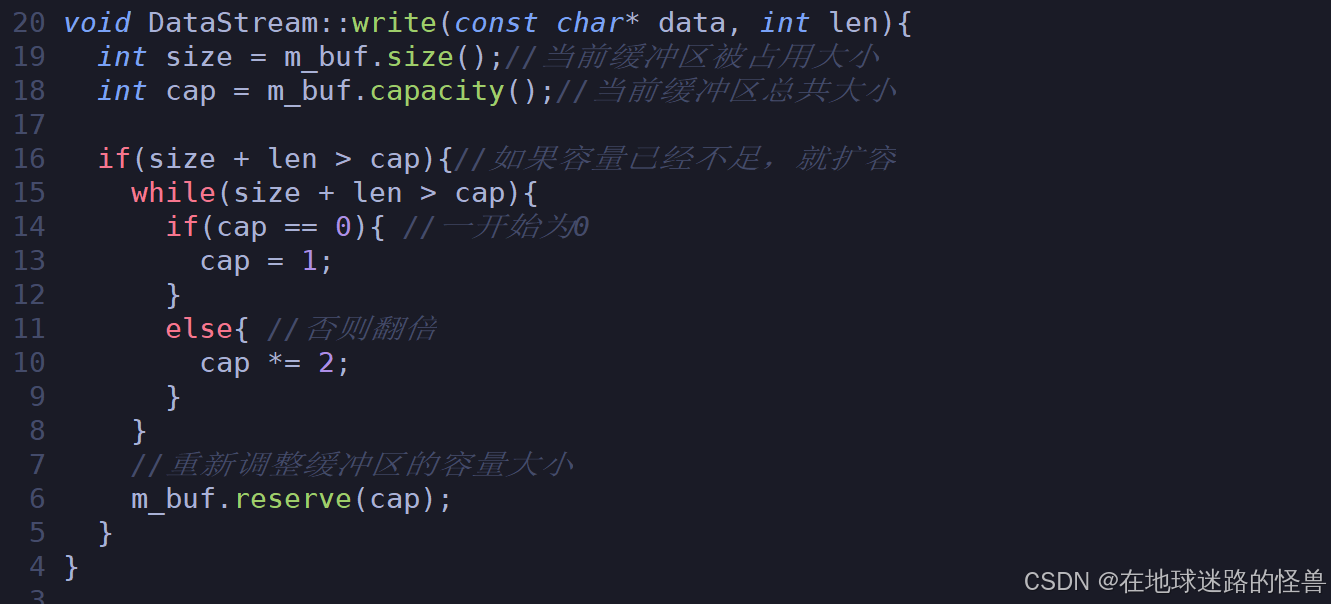
实现到上面的时候我们发现对于这个扩容操作在后面应该还会用到多次,于是我们将这一段扩容操作抽离出来成为一个专门的扩容函数:
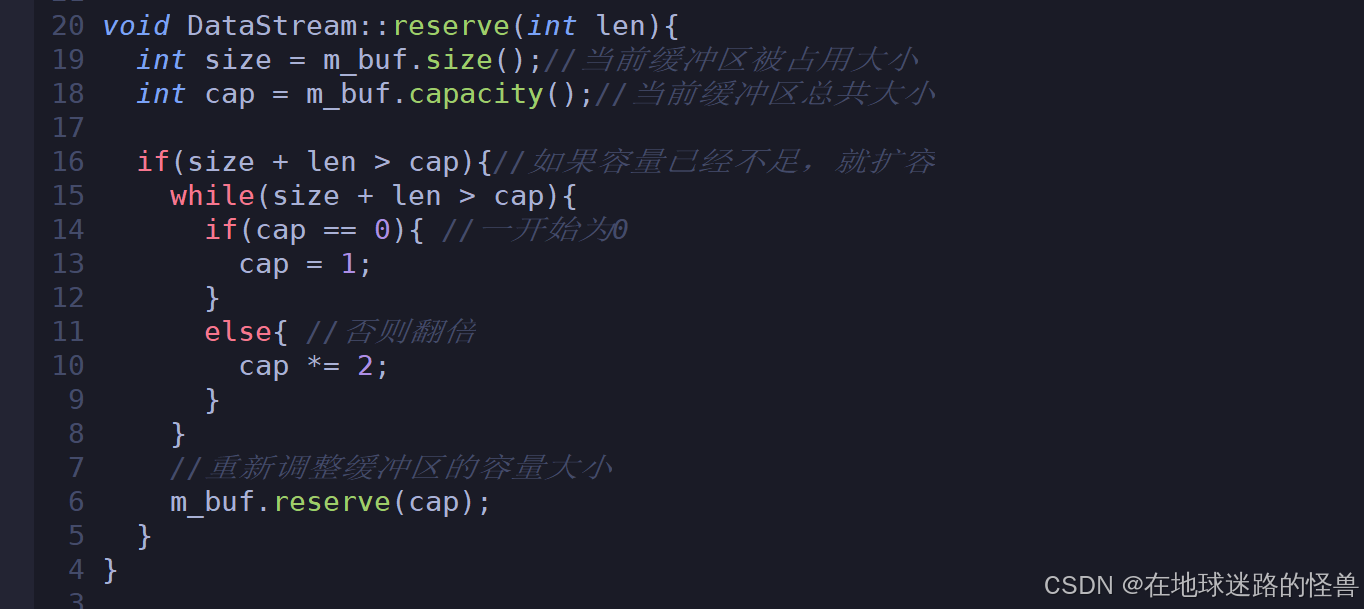
然后继续完成我们的 write 函数:

补充一下 resize 函数:
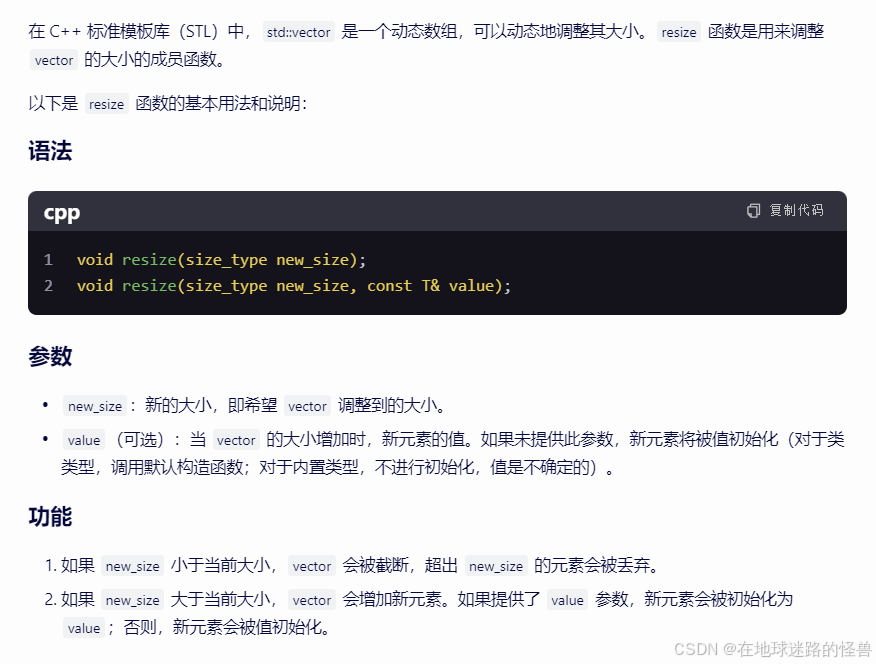
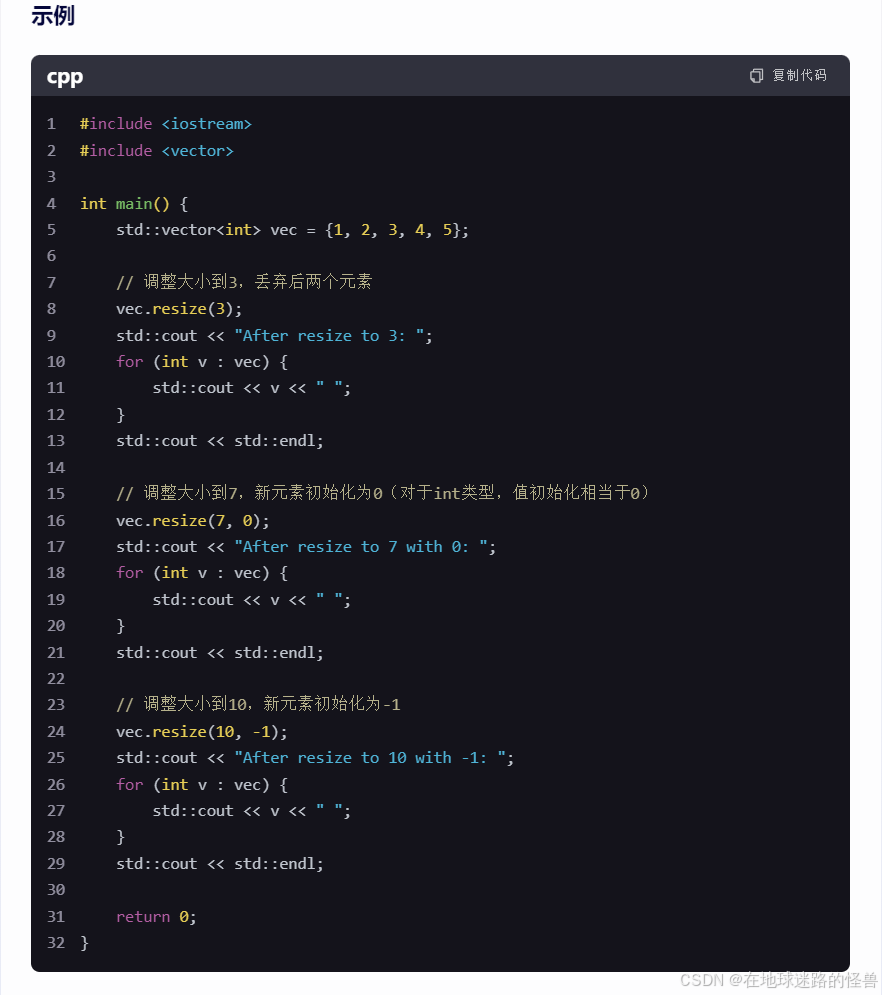
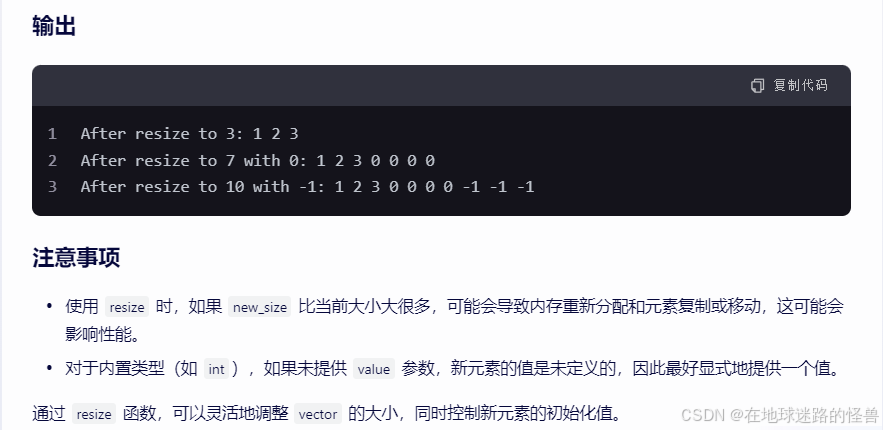
vector 的 capacity 和 size 的区别:

在有了上面的第一个 write 函数之后,后面的重载函数就很好实现了,比如对 bool 类型的值进行序列化:

以此类推,其它基本类型都差不多,重点说一下比较不一样的 string 类型的序列化。
之前我们说过字符串 string 的编码分为三个部分:type+length+value,简称 TLV 编码格式,而这种格式正是 protobuf 底层的编码方式。
事实上前面的什么 int 啊 bool 啊也是 TLV 的编码格式,但因为长度都是固定的,所以就省略了长度这一说,实际上也是 TLV 格式。
实现如下,提供了 C 风格的字符串实现和 C++ 风格的字符串实现:

在完成了所有基本数据类型的序列化函数之后,为了方便打印输出,我们再加一个展示二进制数据的辅助函数 show():
void DataStream::show() const {
int size = m_buf.size();
std::cout << "data size = " << size << std::endl; //打印看数据长度是不是和我们想的一样
int i=0;
while(i < size){
//缓冲区的第一个字节是类型
switch((DataType)m_buf[i]){
case DataType::BOOL:
//对于bool类型来说,第二个字节就是value值
if((int)m_buf[++i] == 0){
std::cout << "false" << std::endl;
}else{
std::cout << "true" << std::endl;
}
++i;
break;
case DataType::CHAR:
std::cout << m_buf[++i] << std::endl;
++i;
break;
case DataType::INT32:
std::cout << *((int32_t*)(&m_buf[++i])) << std::endl;
i += 4;
break;
case DataType::INT64:
std::cout << *((int64_t*)(&m_buf[++i])) << std::endl;
i += 8;
break;
case DataType::FLOAT:
std::cout << *((float*)(&m_buf[++i])) << std::endl;
i += 4;
break;
case DataType::DOUBLE:
std::cout << *((double*)(&m_buf[++i])) << std::endl;
i += 8;
break;
case DataType::STRING:
if((DataType)m_buf[++i] == DataType::INT32){
int len = *((int32_t*)(&m_buf[++i]));
i += 4;
std::cout << std::string(&m_buf[i],len) << std::endl;
i += len;
}
else{
throw std::logic_error("parse string error");
}
break;
default:
break;
}
}
}
现在我们测试时发现都是调用 write 函数进行序列化的:

但我们更希望是可以通过使用 流 的方式来进行这个行为:
ds << n;
所以我们接下来重载一下这种流的运算符:
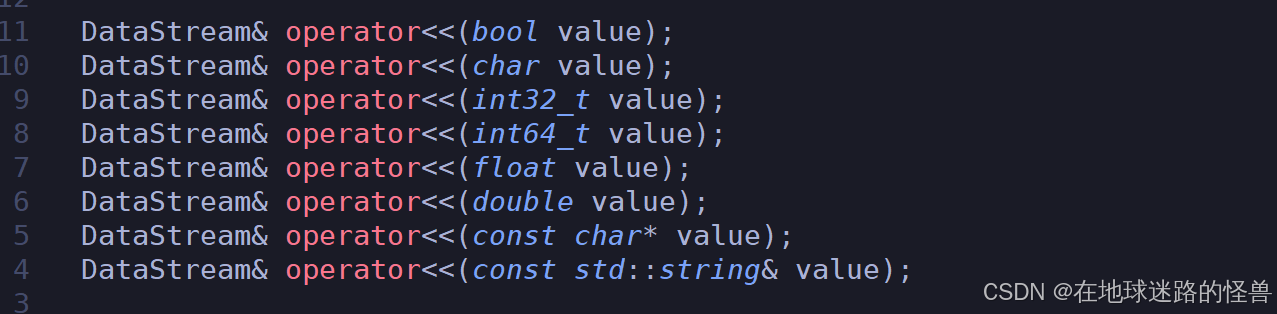
对于反序列化也是一样,我们封装为 read 方法并且一样提供流输出的重载运算符:
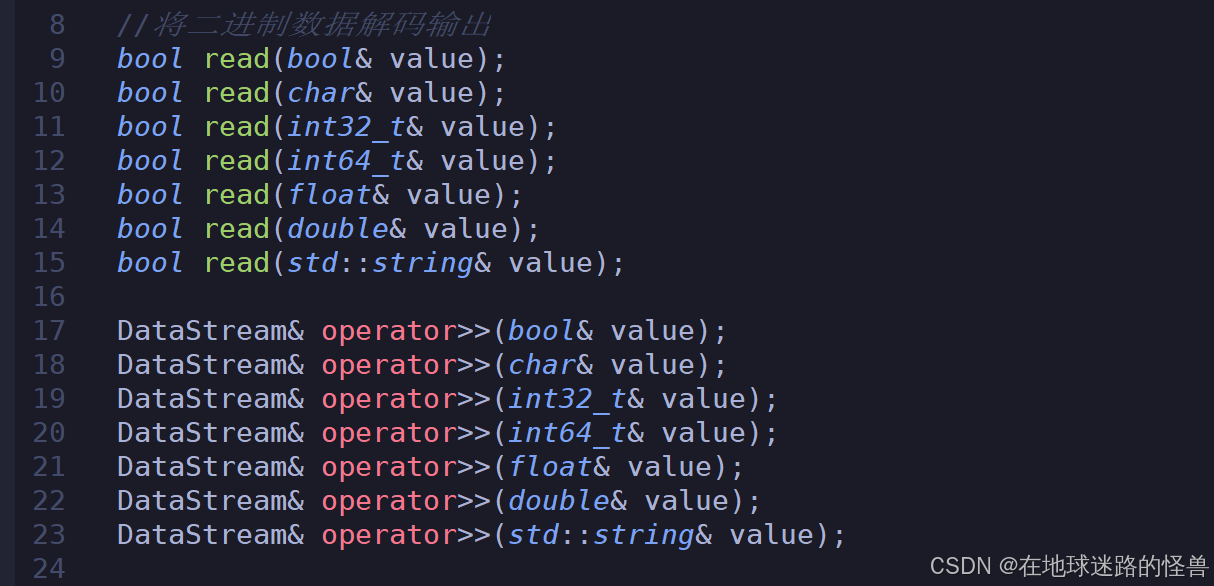
具体实现这里就不展示了,可以自己去看源码,也不复杂的。
测试代码如下:
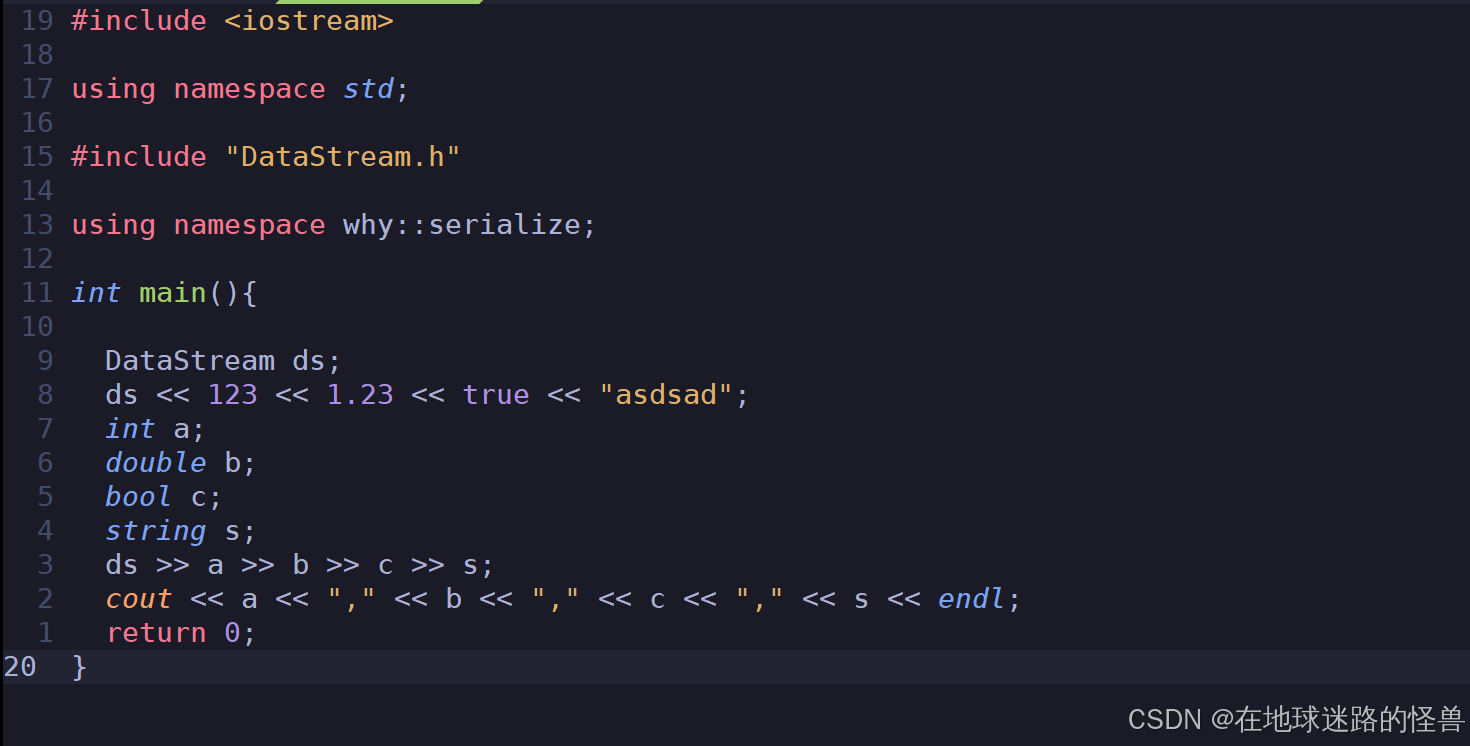
运行结果如下:

复合类型序列化+反序列化
复合数据类型编码:
| 字段类型 | 字段长度 | 底层编码 |
|---|---|---|
| vector | 可变长度 | Type(1) + Length(5) + Value(T+T+T+…) |
| list | 可变长度 | Type(1) + Length(5) + Value(T+T+T+…) |
| map<K, V> | 可变长度 | Type(1) + Length(5) + Value( (K,V) + (K,V) + (K,V) + …) |
| set | 可变长度 | Type(1) + Length(5) + Value(T+T+T+…) |
对于复合数据类型我们使用模板函数来进行实现:
自定义类类型序列化与反序列化
自定义对象类型编码:
| 字段类型 | 字段长度 | 底层编码 |
|---|---|---|
| 自定义类 | 可变长度 | Type(1) + Value( D1 + D2 + D3 + … ) |
对于自定义类类型的编码,Type 依然是表示类类型,而 Value 中的值就是各个类成员字段的顺序。
同时对于任何一个类,如果它想进行序列化的话,我们提供了一个接口类 Serializable ,只要继承于这个类就可以实现序列化。
Serializable 接口类:
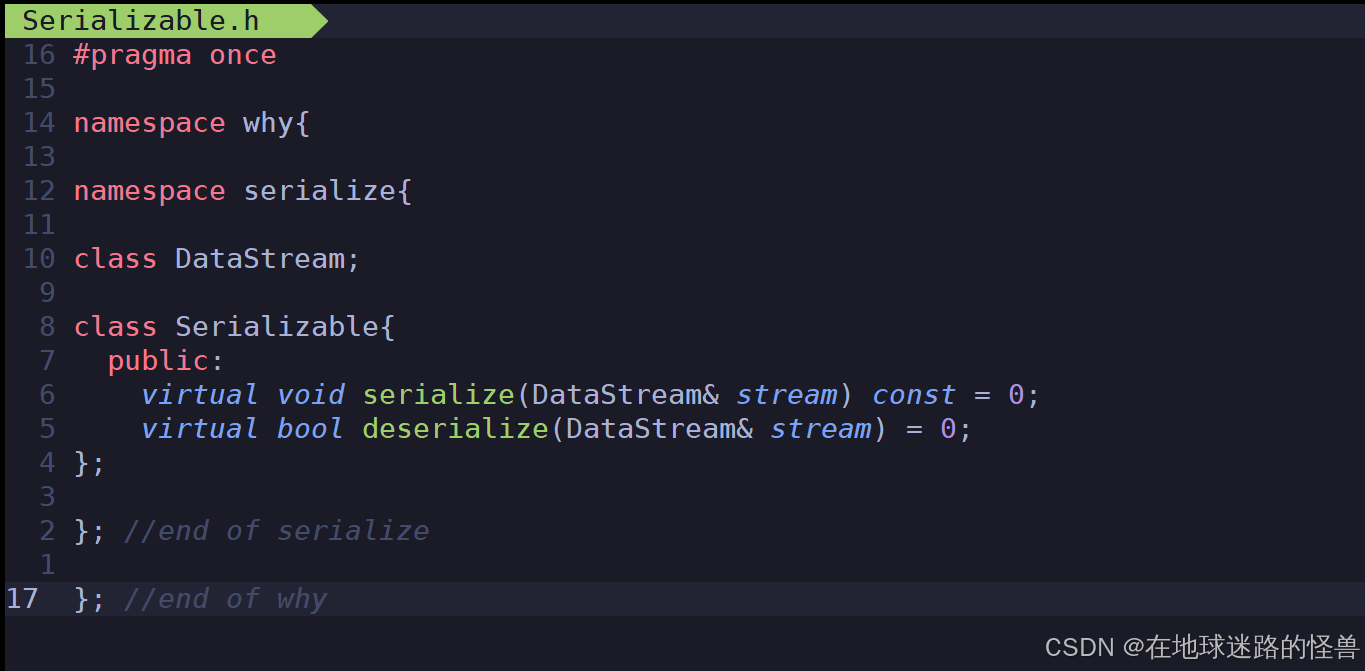
然后在之前所写的函数基础上,再写两个编解码函数即可:


同样重载一下输入输出流运算符:


测试代码如下:
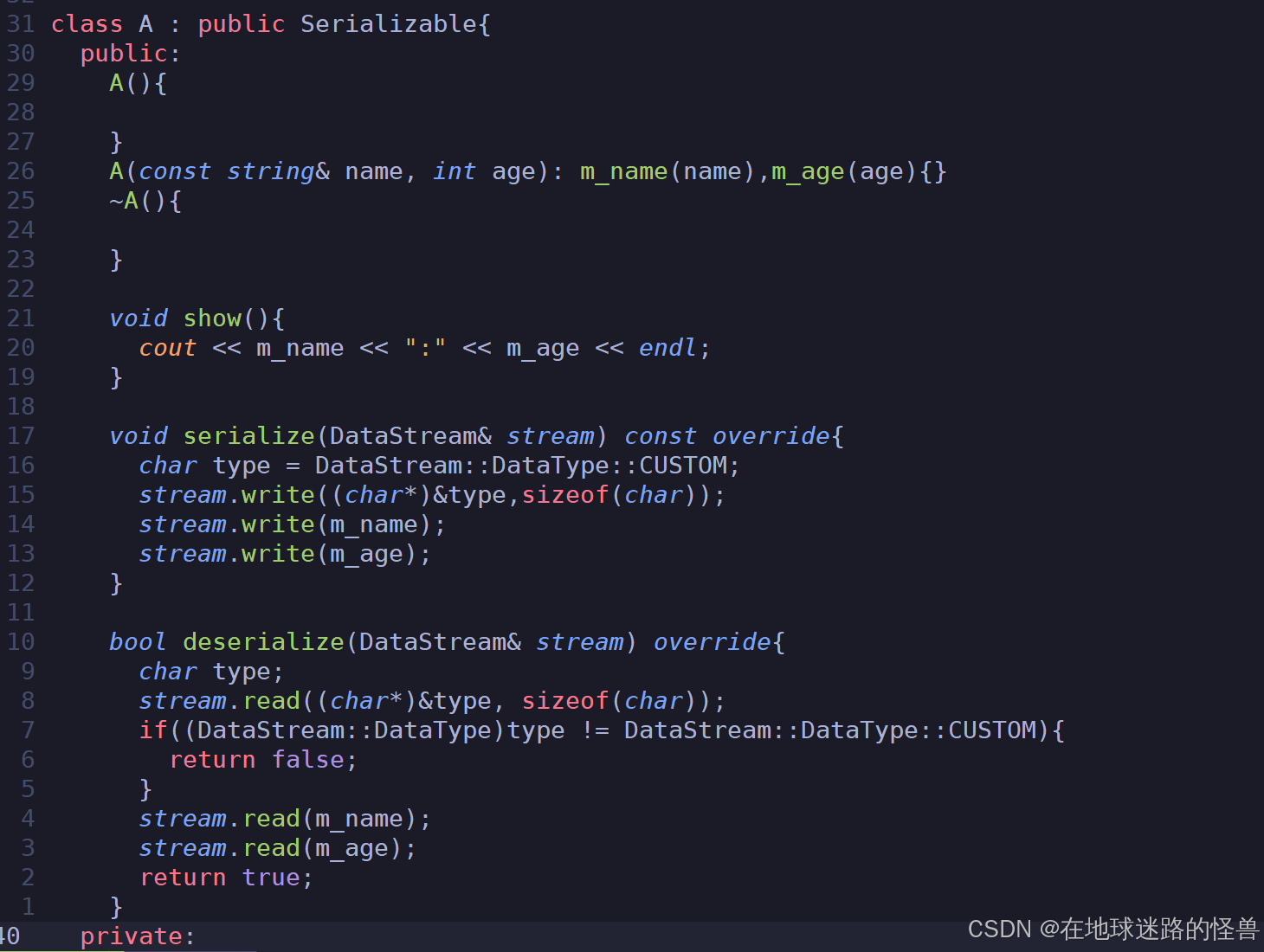
现在我们发现对于每个类都要这么实现一遍太繁琐了,因此我们设置一个宏来封装这个过程:
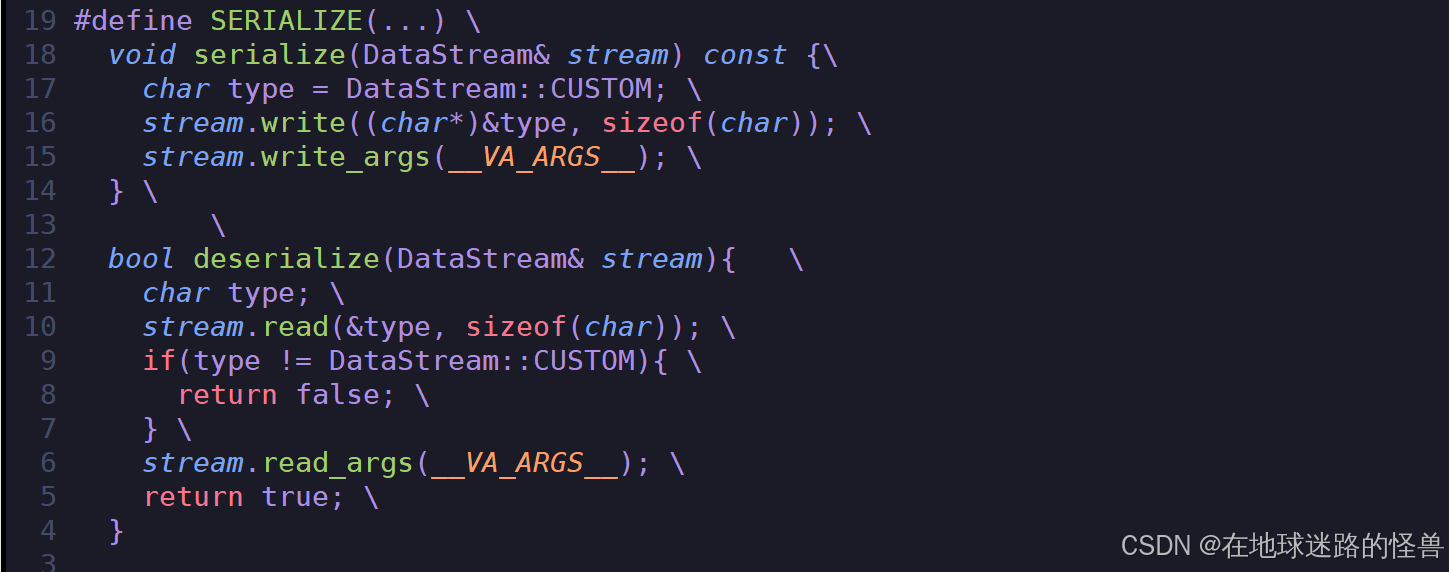
现在我们测试就只需要传入需要序列化的成员变量就可以了,注意到上面的 write_agrs 和 read_args 方法是专门用来处理可变参的,因为自定义类型的成员变量是随机个数的嘛,因此我们需要有这两个处理可变参的函数:
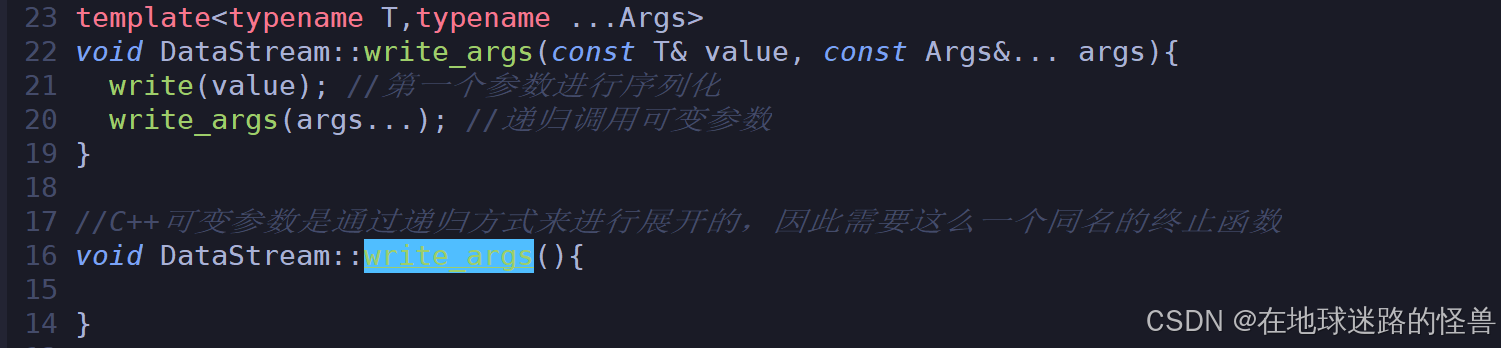
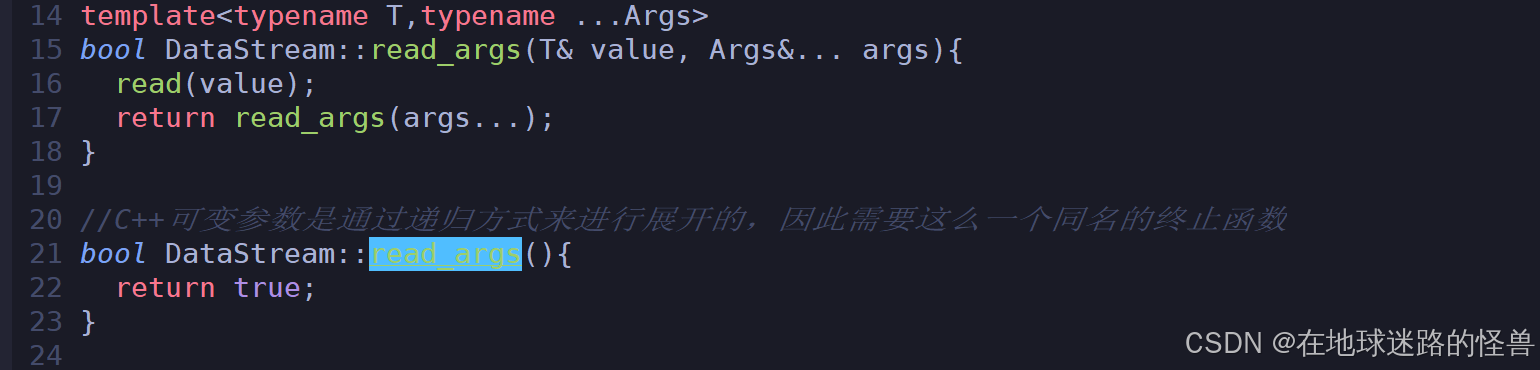
现在我们就可以像一开始说明的那么进行如下实现了:
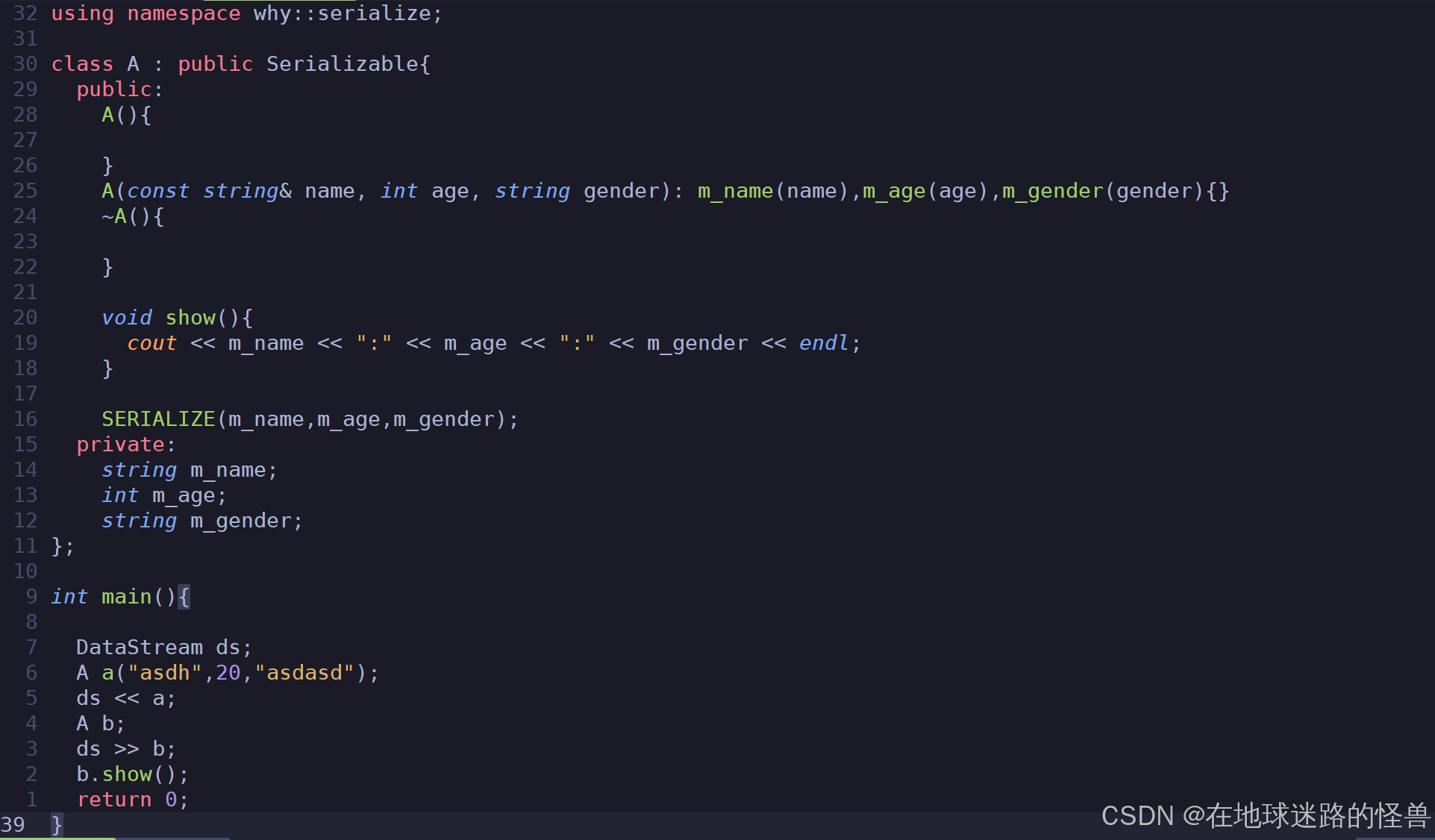
至此所有功能我们就都完成了。
大端与小端的问题
概念介绍
字节序:
字节顺序又被称为端序或尾序(Endianness),在计算机科学领域中,指电脑内存中或在数字通信链路中,组成多字节的字的字节的排列顺序。
小端:
Little-Endian:将低序字节存储在所要存储的起始地址(但是是从低位编址),在变量指针转换的时候地址保持不变,比如 int64* 转到 int32*,对于机器计算来说更加友好和自然。
大端:
Big-Endian:将高序字节存储在所要存储位置的起始地址(但是是从高位编址),内存顺序和数字的书写顺序是一致的,对于人的直观思维比较容易理解,网络字节序统一规定采用 Big-Endian。
检测字节序
方法1、系统提供的宏验证:(__BYTE_ORDER)
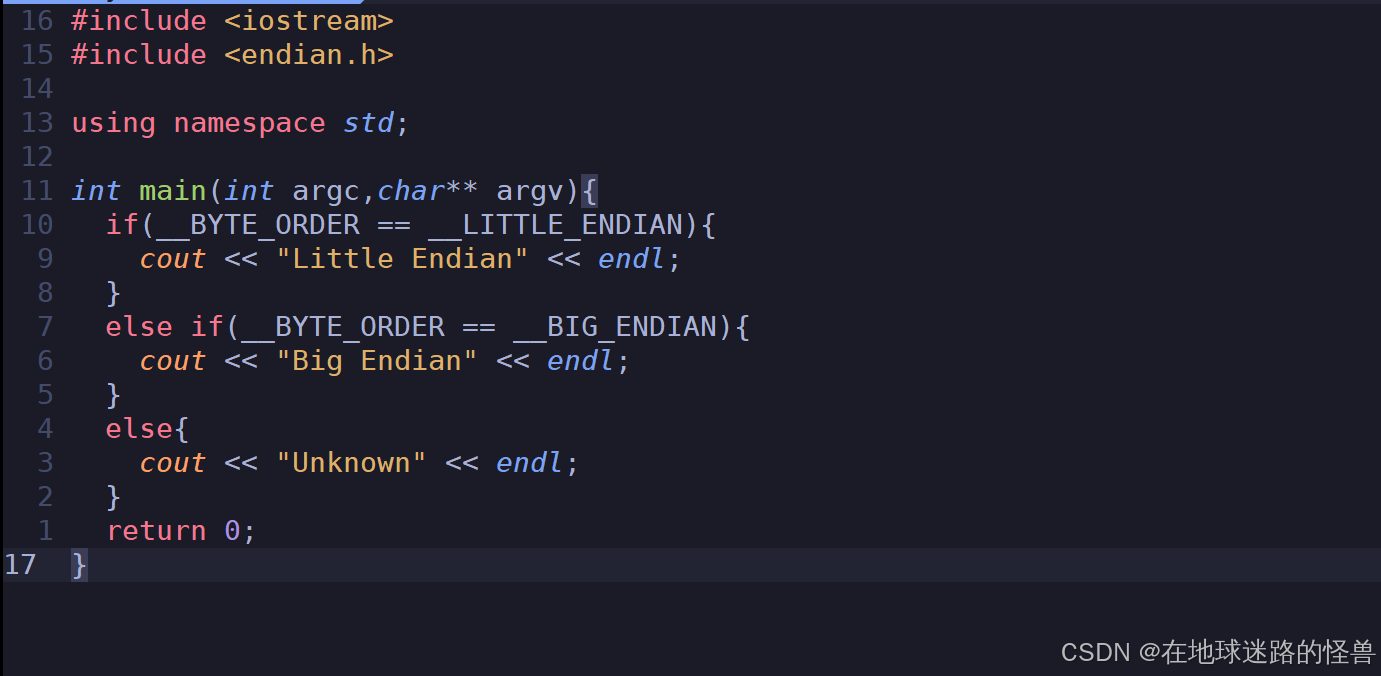
运行如下:

可以知道本地机器是小端字节序。
方法2、通过字节存储地址判断
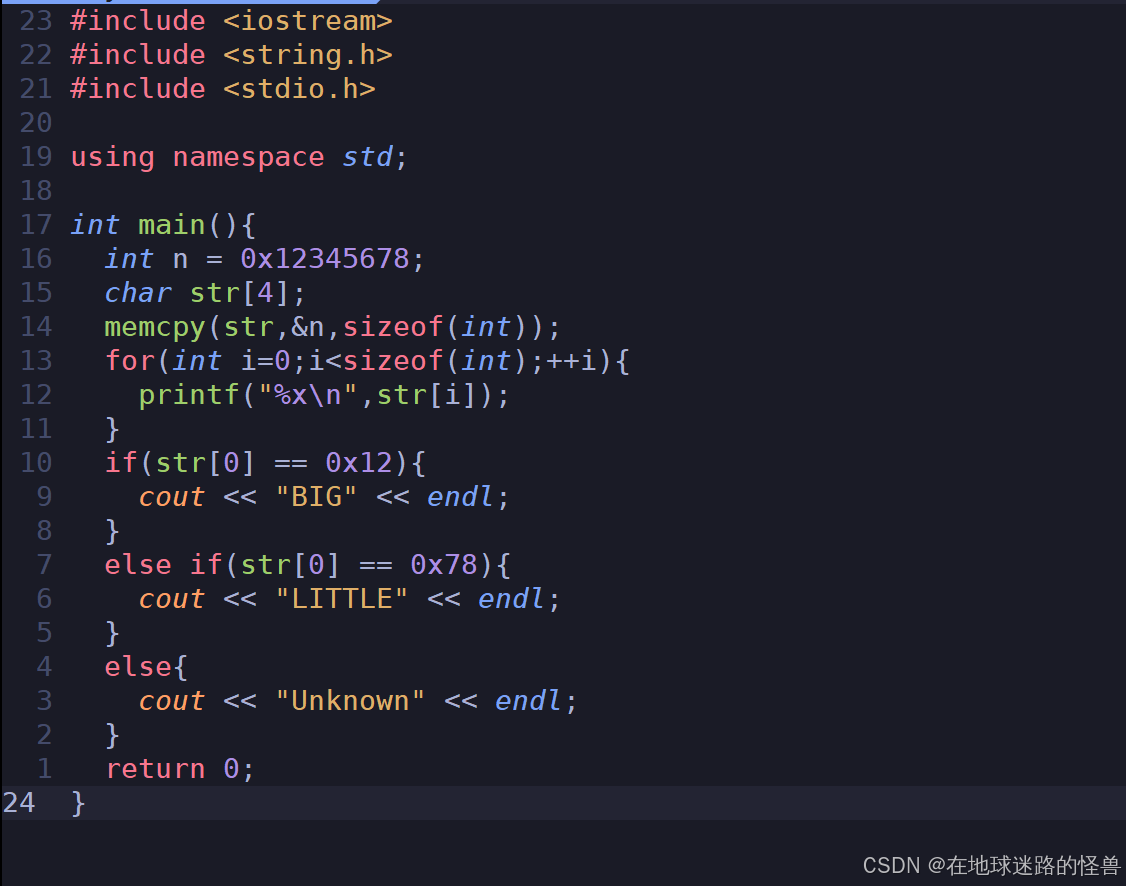
运行如下:

补充一点小知识:
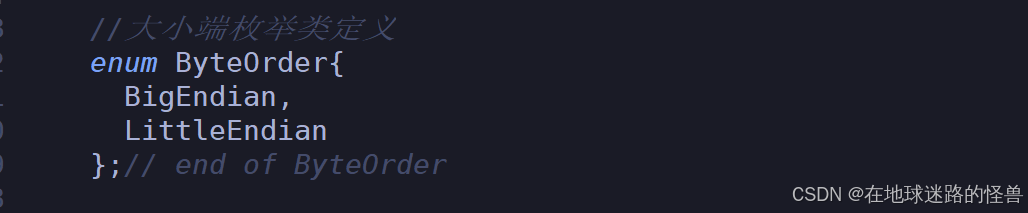
让why-serialize适配大小端问题
先是定义出枚举类:
然后添加一个成员变量来记录大小端,再提供一个 getByteOrder 函数来获取大小端:

实现该函数:
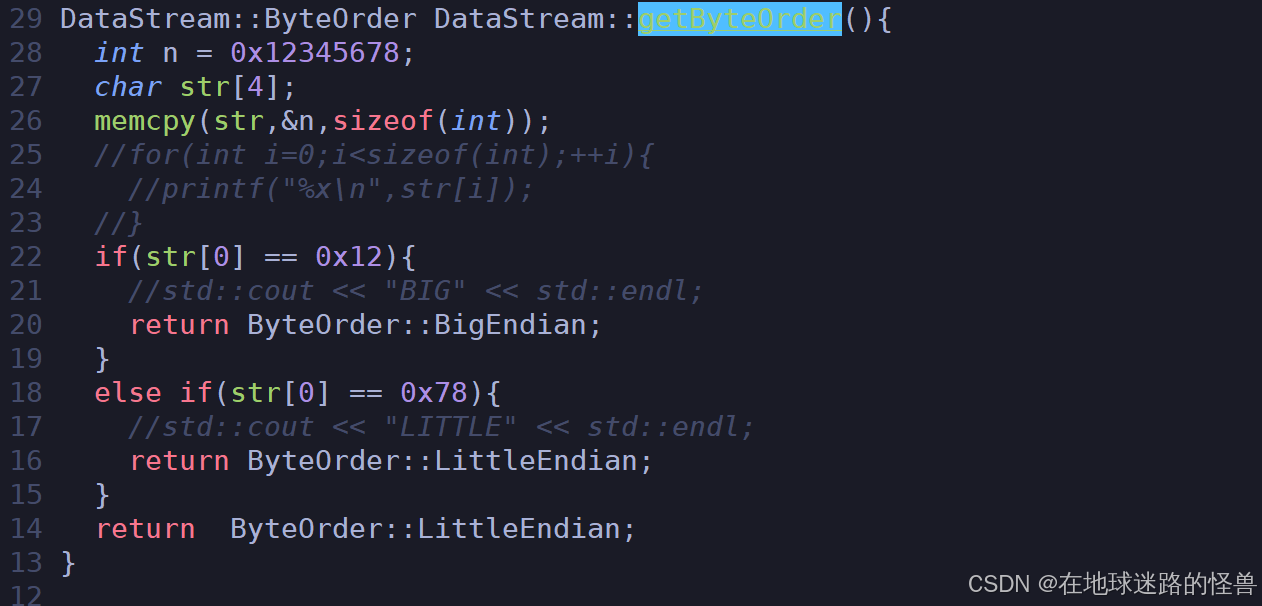
最后因为所谓大小端问题是对整形、浮点型的这种数字会有影响,而对字符啊字符串是没有影响的,因此我们只需要在对数字进行序列化反序列化时进行修改一下即可,以一个为例,其它的都是一样的:

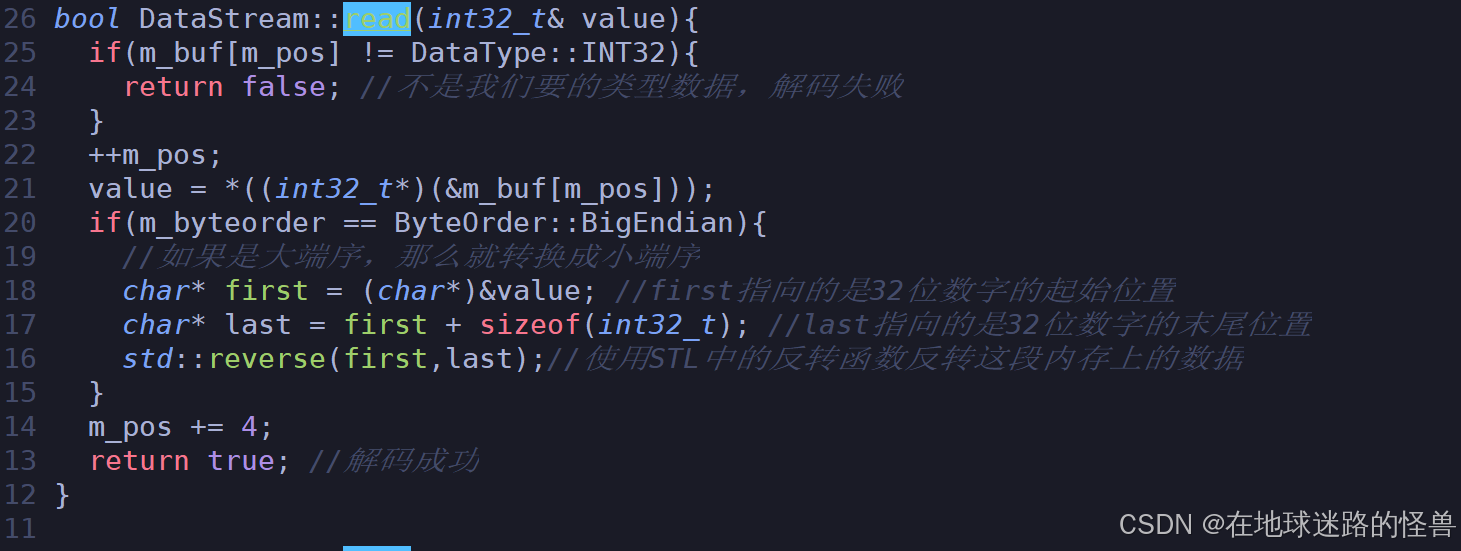
好了至此我们的序列化就结束了。
源码链接
本文源码在gitee上面嗷,有用希望给个 Star~
仓库地址:why-serialize;