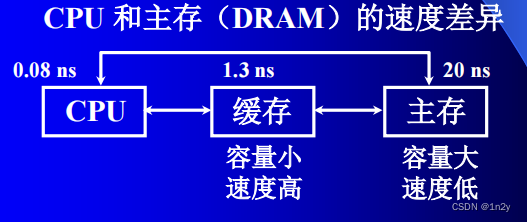
由于程序的转移概率不会很低,数据分布的离散性较大,所以单纯依靠并行主存系统提高主存系统的频宽是有限的。这就必须从系统结构上进行改进,即采用存储体系。
通常将存储系统分为“Cache-主存”层次和“主存-辅存”层次。
1.概述
如何避免 CPU“空等”现象?
为什么 Cache 命中率可以高达 99%?
程序访问的局部性原理
-
空间局部性
在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的。因为指令通常是顺序存放、 顺序执行的,数据一般也是以向量、数组等形式簇聚地存储在一起的。
-
时间局部性
在最近的未来要用到的信息,很可能是现在正在使用的信息;因为程序中存在循环。
-
原因: 数据(数组、结构体)在内存中顺序存放 ;程序各指令的顺序存放,循环体、函数体
高速缓冲技术就是利用局部性原理,把程序中正在使用的部分数据存放在一个高速的、容量较小的Cache 中,使CPU的访存操作大多数针对Cache进行,从而提高程序的执行速度。
体会 Cache 的作用:
void copyij(int d[][1024], int s[][1024])
{
int i, j;
for (i = 0; i < 1024; i++)
for (j = 0; j < 1024; j++)
d[i][j] = s[i][j];
}
void copyji(int d[][1024], int s[][1024])
{
int i, j;
for (j = 0; j < 1024; j++)
for (i = 0; i < 1024; i++)
d[i][j] = s[i][j];
}#include <time.h>
int as[1024][1024], ad[1024][1024];
int main()
{
int i;
clock_t t0; // long (long) int型
for (i = 0; i < 1024*1024; i++)
as[i/1024][i%1024] = i;
t0 = clock(); // clock()返回程序执行至此
copyij(ad, as); // 所花费的CPU时钟数
printf("%ld\n", clock()-t0);
}
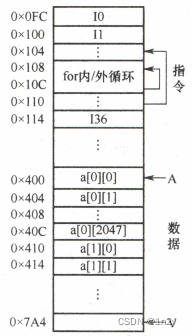
假定数组元素按行优先方式存储,对于上面的两个函数:
1)对于数组a的访问,哪个空间局部性更好?哪个时间局部性更好?
A程序的访问数组a的顺序为a[0][0], a[0][1]…, a[0][N-1];a[1][0], a[1][1]…;访问顺序与存放顺序一致,空间局部性好。
B程序的访问数组a的顺序为a[0][0], a[1][0]…, a[M-1][0];a[0][1], a[1][1]…;访问顺序与存放顺序不一致,每次访问都要跳过N个数组元素,即4N个字节,若主存与Cache的交换单位小于4N,则每次访问都要重装Cache,因而没有空间局部性。
两个程序时间局部性都差,因为每个数组元素都只被访问1次。
2)对于指令访问来说,for循环体的空间局部性和时间局部性如何?
对于for循环体,程序A和B中访问局部性相同。因为循环体内指令按序连续存放,所以空间局部性好;内部循环体指令被重复执行,因此时间局部性好。
在2GHz Pentium4机器上执行两程序,实际时钟周期相差21.5倍
2. cache的基本工作原理
Cache位于存储器层次结构的顶层,通常由SRAM构成,其基本结构如图所示。

-
Cache特点
-
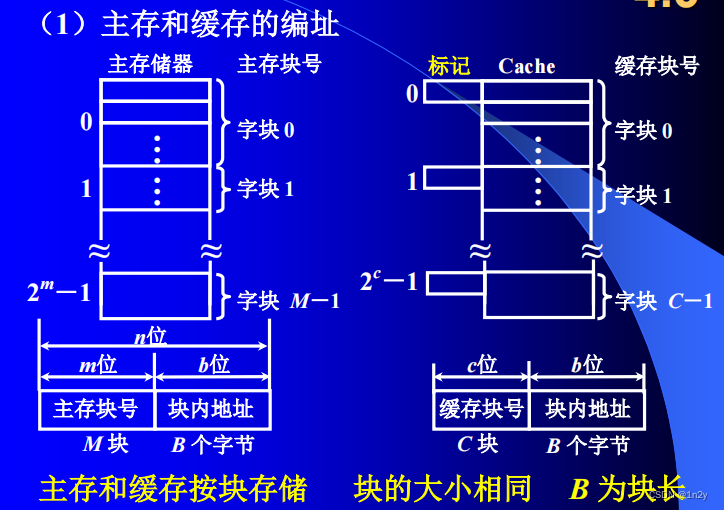
Cache块:Cache和主存都被划分为相等的块,Cache块又称Cache行,每块由若干字节组成,块的长度称为块长(Cache行长)。
由于Cache的容量远小于主存的容量,所以Cache中的块数要远少于主存中的块数,它仅保存主存中最活跃的若干块的副本。
-
Cache按照某种策略,预测CPU在未来一段时间内欲访存的数据,将其装入Cache。
-
Cache工作流程
- 当CPU发出读请求时,若访存地址在Cache中命中,就将此地址转换成Cache地址,直接对Cache进行读操作,与主存无关;
- 若Cache不命中,则仍需访问主存,并把此字所在的块一次性地从主存调入Cache。(地址映射)
- 若此时Cache已满,则需根据某种替换算法,用这个块替换Cache中原来的某块信息。(替换算法)
- 整个过程全部由硬件实现。值得注意的是,CPU与Cache之间的数据交换以字为单位,而Cache与主存之间的数据交换则以Cache块为单位。

Cache性能分析
-
命中率:CPU欲访问的信息已在Cache中的比率称为Cache的命中率。
设一个程序执行期间,Cache的总命中次数为
,访问主存的总次数为
,则命中率
为
可见为提高访问效率,命中率H越接近1越好。 -
平均访问时间:设
为命中时的Cache访问时间,
为未命中时的访问时间,
表示未命中率,则Cache-主存系统的平均访问时间
为
-
根据Cache的读、写流程,实现Cache时需解决以下关键问题:
- 1)数据查找。如何快速判断数据是否在 Cache 中。
- 2)地址映射。主存块如何存放在 Cache 中,如何将主存地址转换为Cache 地址。
- 3)替换策略。Cache满后,使用何种策略对Cache块进行替换或淘汰。
- 4)写入策略。如何既保证主存块和Cache 块的数据一致性,又尽量提升效率。

3. Cache和主存的映射方式
Cache 行中的信息是主存中某个块的副本,地址映射是指把主存地址空间映射到Cache地址空间,即把存放在主存中的信息按照某种规则装入Cache。
由于Cache行数比主存块数少得多,因此主存中只有一部分块的信息可放在Cache中,因此在Cache中要为每块加一个标记,指明它是主存中哪一块的副本。该标记的内容相当于主存中块的编号。为了说明Cache行中的信息是否有效,每个Cache行需要一个有效位。
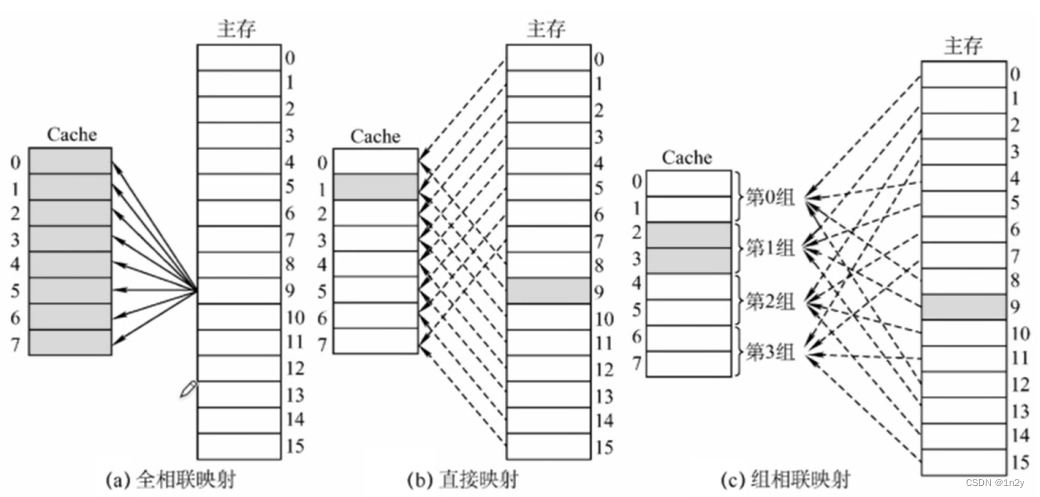
全相联映射
主存中的每一块可以装入Cache中的任何位置,每行的标记用于指出该行取自主存的哪一块,所以CPU访存时需要与所有Cache行的标记进行比较。
-
优点:比较灵活,Cache块的冲突概率低,空间利用率高,命中率也高
-
缺点:标记的比较速度较慢,实现成本较高,通常需采用昂贵的按内容寻址的相联存储器进行地址映射。
-
地址结构:


直接映射
主存块只能放到特定的某个Cache行,若这个位置已有内容,则产生冲突,原来的块被替换(无需替换算法)
直接映射的关系可定义为:
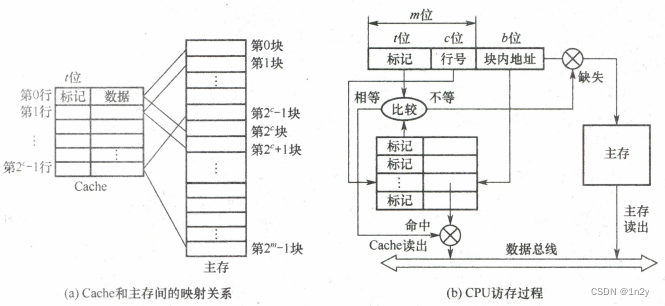
假设Cache有行,主存有
块,在直接映射方式,主存的第0块、第
块、第
块…只能映射到第0行
由此看出,主存块号低c位正好是要装入Cache的行号。给每个Cache设置长为t=m-c的标记(tag),当主存某块调入Cache后,就将其块号的高t位设置在对应Cache行的标记中,如上图所示。
直接映射的地址结构为:![]()
组相联映射
主存块可以放到特定分组中的任意位置。常用的有2路组相联映射,如下图所示。
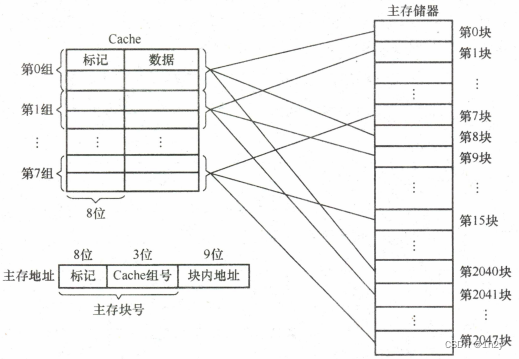
路数越大,即每组Cache行的数量越大,发生块冲突的概率越低,但相联比较电路也越复杂。选定适当的数量,可使组相联映射的成本接近直接映射,而性能上仍接近全相联映射。
组相联映射的地址结构为:![]()
CPU访存过程如下:
- 首先根据访存地址中间的组号找到对应的Cache组;
- 将对应Cache组中每个行的标记与主存地址的高位标记进行比较;
- 若有一个相等且有效位为1,则访问Cache命中,此时根据主存地址中的块内地址,在对应Cache行中存取信息;
- 若都不相等或虽相等但有效位为0,则不命中,此时CPU从主存中读出该地址所在的一块信息送到对应Cache组的任意一个空闲行中,将有效位置1,并设置标记,同时将该地址中的内容送CPU。
4.Cache中主存块的替换算法
全相联映射和组相联映射需要,直接相连映射不需要。从主存向Cache传送一个新块,当Cache或Cache组中的空间已被占满时,就需要使用替换算法置换Cache行。
-
随机算法(RAND)
-
算法:若Cache已满,则随机选择一块替换。
-
特点:实现简单,但完全没考虑局部性原理,命中率低,(实际效果很不稳定)
-
-
先进先出算法(FIFO)
-
算法:若Cache已满,则替换最先被调入Cache的块
-
特点:FIFO依然没考虑局部性原理,最先被调入Cache的块也有可能是被频繁访问的
-
-
近期最少使用(LRU)
-
算法:为每一个Cache块设置一个“计数器”,用于记录每个Cache块已经有多久没被访问了。当Cache满后替换“计数器”最大的
- ①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变;
- ②未命中且还有空闲行时,新装入的行的计数器置0,其余非空闲行全加1;
- ③未命中且无空闲行时,计数值最大的行的信息块被淘汰,新装行的块的计数器置0,其余全加1。
Cache块的总数=
,则计数器只需n位。且Cache装满后所有计数器的值定不重复
-
特点:基于“局部性原理”,近期被访问过的主存块,在不久的将来也很有可能被再次访问,因此淘汰最久没被访问过的块是合理的。LRU算法的实际运行效果优秀,Cache命中率高。
-
最近不经常使用(LFU)算法:为每一个Cache块设置一个“计数器”,用于记录每个Cache块被访问过几次。当Cache满后替换“计数器”最小的。若有多个计数器最小的行,可按行号递增或FIFO策略进行选择
-
新调入的块计数器=0,之后每被访问一次计数器+1。需要替换时,选择计数器最小的一行
-
特点:曾经被经常访问的主存块在未来不一定会用到(如:微信视频聊天相关的块),并没有很好地遵循局部性原理,因此实际运行效果不如LRU
-
-
5.Cache写策略
因为Cache中的内容是主存块副本,当对Cache中的内容进行更新时,就需选用写操作策略使Cache内容和主存内容保持一致。此时分两种情况。
-
写命中
-
写回法:当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存
-
-
减少了访存次数,但存在数据不一致的隐患。
-
每个Cache行必须设直一个标志位(脏位),以反映此块是否被CPU修改过。
-
全写法:当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)
- 访存次数增加,速度变慢,但更能保证数据一致性

-
写不命中
- 写分配法:当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。
- 通常搭配写回法使用。
- 非写分配法:当CPU对Cache写不命中时,只写入主存,不调入Cache。
- 搭配全写法使用。
- 只有“读”未命中时才调入Cache
- 写分配法:当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。
-
多级Cache
现代计算机常采用多级Cache离CPU越近的速度越快,容量越小离CPU越远的速度越慢,容量越大。

-
各级Cache之间常采用**“全写法+非写分配法”**
-
Cache-主存 之间常采用**“写回法+写分配法”**
-