目录
概述
随着人工智能技术的不断进步,越来越多的人开始关注和使用AI艺术生成工具。而Stable Diffusion 3作为最新一代的文生图大模型,于2024年6月12日正式开源,以其高质量的图像生成受到了广泛欢迎。那么,如何快速部署Stable Diffusion 3,让它成为您的专属AI艺术家呢?请跟随本文,在百度智能云GPU服务器上部署Stable Diffusion 3。
准备工作
环境信息
本文以百度智能云GPU服务器为例进行安装部署,购买计算型GN5服务器, 配置16核CPU,64GB内存,Nvidia Tesla A10 单卡,搭配100GB SSD数据盘, 安装Windows Server 2012中文操作系统。
-
如果您使用自己的环境部署,需要带 NVIDIA GPU 的实例:建议选用T4、V100、A10等型号的GPU
-
服务器配置:建议最低配置为 8 核 64 G 100G 磁盘,10M 带宽
Stable Diffusion 3.0 模型下载
下载地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
官方在模型下载链接中给出了模型文件,文本编码器,文生图工作流示例以及成品图demo:
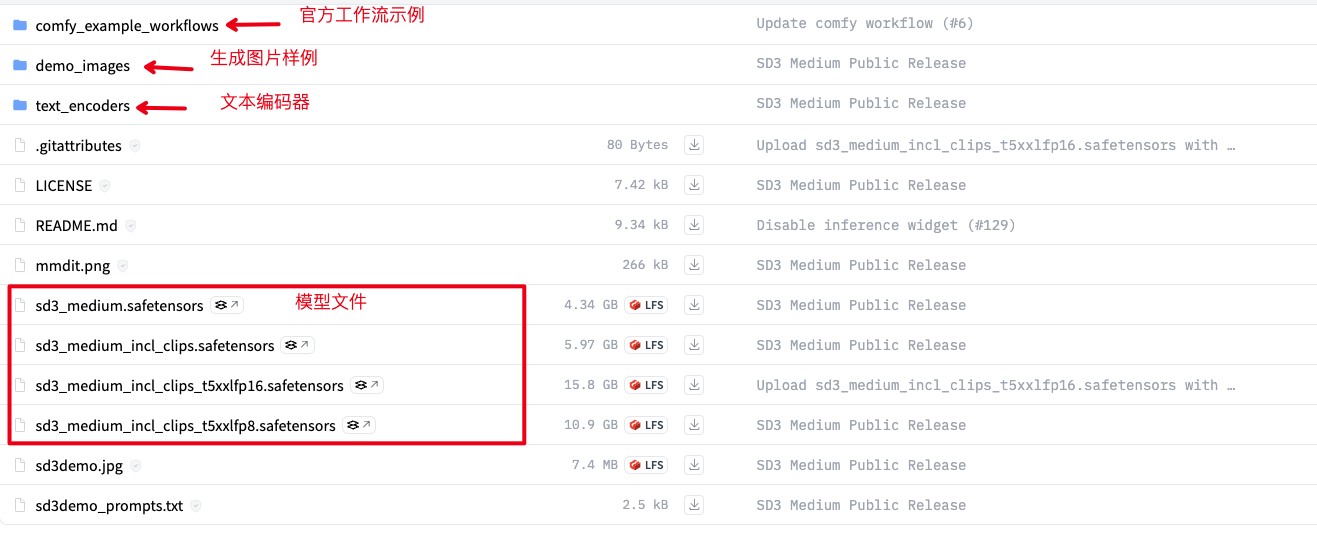
-
text_encoders:文本编码器是 Stable Diffusion 中一个非常重要的部分,是将文本转换为模型能够理解的向量表示的模型,向量中包含了文本描述的语义信息,例如颜色、形状、风格等等,模型会根据这个向量生成相应的图像。如果您使用
sd3_medium.safetensors,需要额外添加文本编码器。 -
comfy_example_workflows:包含三个官方示例工作流。
-
demo_images:样例图片
-
官方提供了4种模型文件:
| 模型文件 |
大小 |
说明 |
| 4.3G |
独立主模型,是 Stable Diffusion 的核心,负责根据文本编码器提供的文本信息生成图像,但它不包含文本编码器(clip 模型),此模型需要配合文本编码器使用; |
|
| 5.97G |
包含 Stable Diffusion 模型和 CLIP ( |
|
| 10.9G |
包含 Stable Diffusion 模型、CLIP 模型 ( |
|
| 15.8G |
包含 Stable Diffusion 模型、CLIP 模型 ( |
注:模型和文本编码器并非全部需要下载,可以结合服务器显卡的性能只下载相应模型即可。
下载ComfyUI启动器
ComfyUI 是一个开源的工作流可视化编排工具,它提供了强大的功能来扩展 Stable Diffusion 的能力。你可以把它想象成 Stable Diffusion 的一个 “控制面板”,让你能够更灵活地控制图像生成过程。
模型部署
解压ComfyUI
解压ComfyUI_windows_portable_nvidia_or_cpu_nightly_pytorch.7z文件,因为模型文件较大,建议放置在数据盘,解压后目录结构如下:
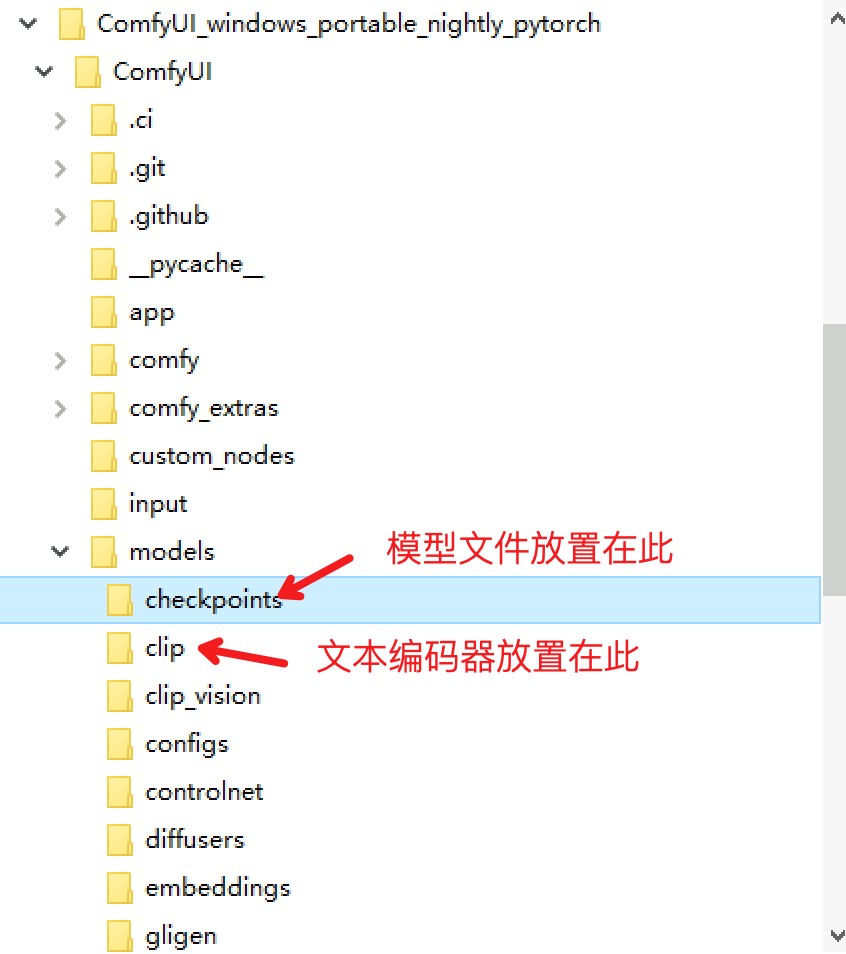
部署模型和文本编码器
将模型文件 sd3_medium.safetensors,sd3_medium_incl_clips.safetensors , sd3_medium_incl_clips_t5xxlfp16.safetensors , sd3_medium_incl_clips_t5xxlfp8.safetensors 放置到 ComfyUI_windows_portable_nightly_pytorch\ComfyUI\models\checkpoints。
将 CLIP (clip_g.safetensors,clip_l.safetensors) 和 T5-XXL (t5xxl_fp16.safetensors,t5xxl_fp8_e4m3fn.safetensors)文件放置到ComfyUI_windows_portable_nightly_pytorch\ComfyUI\models\clip中
注:如使用sd3_medium.safetensors模型则需要下载和放置文本编码器,其他模型不需要。
使用Stable Diffusion 3绘图
启动服务
在ComfyUI_windows_portable_nightly_pytorch目录下包含两个启动脚本:
-
run_cpu.bat: 适用于没有独立显卡,需要CPU来完成计算。
-
run_nvidia_gpu.bat: 适用于独立显卡
启动后会在8188端口完成监听,并自动打开浏览器进入工作流编排界面, 如果你想指定IP和端口进行监听,则需要编辑启动脚本,增加参数 --host 0.0.0.0 --port 7860 来指定监听地址和端口
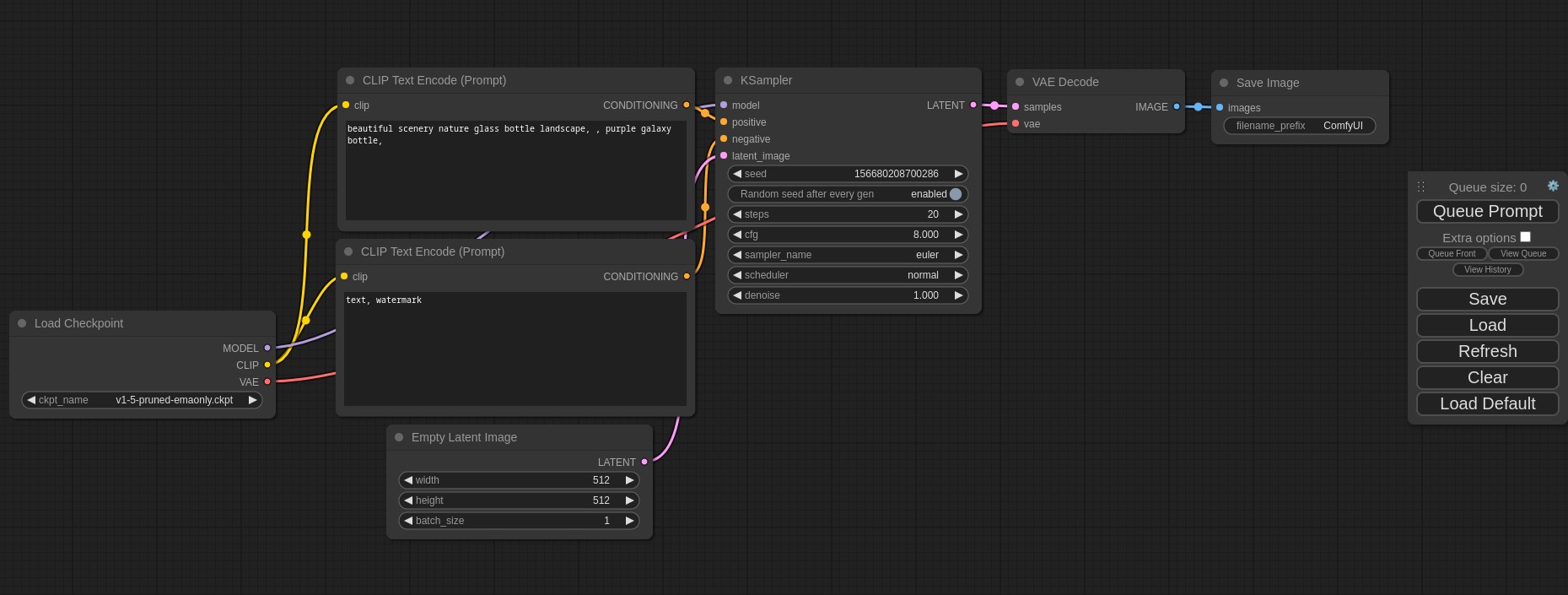
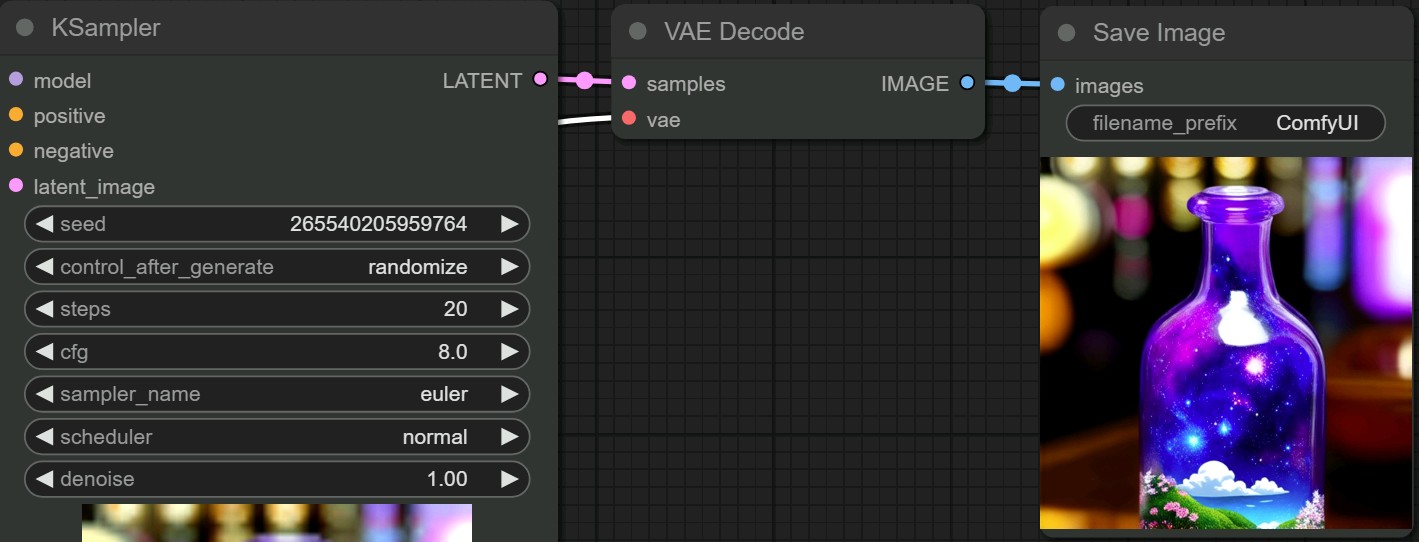
工作流
ComfyUI 将stable diffusion的流程拆分成节点,这些节点可以包括各种任务,如加载检查点模型、输入正反向提示、指定采样器等,使用户能够通过链接不同的节点来构建复杂的图像生成工作流程。
ComfyUI在启动后会加载默认的工作流,通过“Load checkpoint”节点选择加载的模型,在“CLIP Text Encode (Prompt)”输入正向和反向提示词,”Empty Latent Image”节点可以设置图像分辨率以及生成数量 ,点击“Queue Prompt”开始生成图片。
其它节点有更多调整图像生成的参数,这里不做介绍,可以通过ComfyUI官方文档学习。
问题记录
启动器加载模块依赖问题
C:\SD3\ComfyUI_windows_portable_nightly _pytorch). \python_embeded\python. exe -s ComfyUI\main.py --cpu -windows-standalo
e-build
Traceback (most recent call last):
Fi1e "C:\SD3\ComfyUI_windows_portable_nightly_pytorch\ComfyUI\main.py", 1ine 73, in <module>
import comfy.utils
File "C:\SD3\ComfyUI_windows_portable_nightly_pytorch\ComfyUI\comfy\utils.py", 1ine 1, in <module)
import torch
File "C:\SD3\ComfyUI_windows_portable_nightly_pytorch\python_embeded\Lib\site-packages\torch\_init_.py", 1ine 246, i
n <module>
load_d11_libraries()
File "C: SD3\ComfyUI_windows_portable_nightly_pytorch\python_embeded\Lib\site-packages\torch\_init_.py", 1ine 242, i
n _load_d11_1ibraries
raise err
SError: [WinError 126] 找不到指定的模块。 Error 1oading "C:\SD3\ComfyUI_windows_portable_nightly_pytorch\python_embedec
\Lib\site-packages\torch\1ib\fbgemm. d11" or one of its dependencies.
C:\SD3\ComfyUI_windows_portable_nightly_pytorch>pause
解决方案
重装这三个库torch,torchvision,torchaudio,根据操作系统版本,gpu/cpu信息等来指定安装参数:
cd C:\SD3\ComfyUI_windows_portable_nightly_pytorch\python_embeded
.\Scripts\pip3 uninstall torch torchvision torchaudio
.\Scripts\pip3 install torch torchvision torchaudio --index-url
https://download.pytorch.org/whl/cu121
如果运行中缺少pip命令,则先执行如下命令:
.\python.exe .\get_pip.py