
本文字数:14982;估计阅读时间:38 分钟
作者:Dale McDiarmid
本文在公众号【ClickHouseInc】首发

简介
在构建实时应用程序时,常常需要向数据库发出大量并发请求,以填充页面的各个模块。为了防止在浏览器中暴露数据库凭证,通常会在数据库和客户端之间添加一个 Web 服务器。
尽管这种架构对于某些应用是必须的,但在构建单页应用、原型验证或需要快速迭代的演示时,这样的设置可能显得多余。开发者可以考虑采用“仅客户端”架构,让浏览器直接查询数据库。本文将重点介绍这种“仅客户端”架构的关键数据库考量。
单页应用(SPA)无需重新加载整个页面即可动态更新内容,所有渲染和逻辑都在客户端完成,旨在提供流畅的用户体验,非常适合这种架构。
我们将展示如何在确保数据库安全且避免因请求过多而导致过载的前提下,通过 ClickHouse 实现“仅客户端”应用。为此,我们将利用一些简单却强大的功能,并复用一些配置方案,只需少量 JavaScript,即可在几分钟内为现有应用程序安全添加分析功能。
我们已在多个公开演示中成功采用了这种“仅客户端”方法,包括 ClickPy、CryptoHouse 和 adsb.exposed 等 SPA 应用。不过,我们也理解某些用户需要更高的安全性,并希望通过添加 API 层来减少攻击面。为此,ClickHouse Cloud 提供了查询端点(Query Endpoints)。
背景与传统架构
传统的 Web 应用程序多采用客户端-服务器架构,前端通过 API 与后端服务器交互,后端则负责与数据库的通信。

在这种架构中,开发人员需要构建和维护复杂的后端系统,增加了开发过程的复杂性,延长了迭代周期。此架构的普及主要是为了应对前端直接访问数据库带来的安全问题,因为将数据库直接暴露于公共互联网存在较高风险,因此需要通过安全的 API 通信来加以防护。然而,这种架构的复杂性也会带来更多扩展性方面的挑战——后端服务器需要精细管理和手动调整才能有效应对增长。这使得开发和维护 Web 应用程序的过程变得资源密集且效率较低。
近年来,越来越多的应用开始允许客户端代码直接在浏览器中访问数据库。这一 Web 应用构建方式由 Firebase 推广,尤其是其 Firebase Realtime Database 引入了基于浏览器的访问模式,通过令牌(包括匿名身份验证令牌)管理安全规则。
Firebase 在以前端为驱动的开发社区中广受欢迎,确立了这一实践,其他服务(如 Supabase)也将其应用于 PostgreSQL 数据库。此方法减少了复杂的后端需求,使开发过程更简单,并提升了迭代速度,同时将扩展性交由数据库管理,简化了应用的扩展性设计。
不过,这些数据库服务通常为事务型工作负载优化,适合处理应用状态,但不适合用于大数据集的分析和可视化。幸运的是,通过简单配置,ClickHouse 也可以在此架构中高效部署。
以下是希望在 ClickHouse 中采用仅客户端架构的用户的配置建议。对于希望简化体验的用户,我们推荐使用 ClickHouse Cloud 的查询端点(Query Endpoints),它可以大大降低复杂性,并通过可配置的 REST 端点提供 ClickHouse 快速的分析查询功能。
单页应用中集成 ClickHouse
ClickHouse 拥有多项关键功能,使其能够在仅客户端架构中高效运行:
-
HTTP 接口与 REST API:支持通过 JavaScript 直接使用 SQL 查询 ClickHouse,默认监听端口 8123 或 8443(SSL 版本),后者在 ClickHouse Cloud 中开放。该接口支持 HTTP 压缩与会话管理。
-
输出格式:提供超过 70 种输出格式,包括 20 种 JSON 子格式,便于 JavaScript 解析。
-
查询参数:支持查询模板化,并增强了对 SQL 注入的防护。
-
基于角色的访问控制:管理员可以限制对特定表和行的访问权限。
-
查询复杂性限制:可将用户权限设为只读,并限制查询复杂度及可用资源。
-
配额:限制特定客户端的查询次数,防止恶意客户端导致数据库负载过高。
例如,以下代码展示了如何从 ClickPy 实例查询过去 30 天下载次数最多的 Python 包。此处使用 play 用户并添加 FORMAT JSONEachRow 参数(默认为 TabSeparated),以返回格式化的 JSON 数据。
echo 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSONEachRow' | curl -u play: 'https://clickpy-clickhouse.clickhouse.com' --data-binary @-
{"project":"boto3","c":"27234697969"}
{"project":"urllib3","c":"17015345004"}
{"project":"botocore","c":"15812406924"}尽管这些功能为从浏览器查询 ClickHouse 提供了基本支持,但在将实例暴露于公共互联网时,需要经过细致的配置和管理。
在这些最佳实践中,我们主要关注读取请求。这类请求通常是仅客户端的公开应用中唯一适合的请求类型。同时,我们假设所有客户端(即用户)使用相同的用户名发出查询。不过,这些原则也可以扩展至多个 ClickHouse 用户。
仅允许 HTTPS 连接
对于面向公众的应用程序,应用中用于大多数查询的用户凭证会显示在浏览器中,任何开发人员都可以通过查看网络请求轻松获取。虽然这些凭证通常不属于敏感信息,但应用程序可能允许用户修改查询所用的用户名和密码。这些凭证应通过安全连接(HTTPS)进行保护和传输。有关为开源 ClickHouse 配置 TLS 和开放 HTTPS 接口的具体方法,请点击此处查看【https://clickhouse.com/docs/en/guides/sre/configuring-ssl】。
例如,在类似 ClickHouse play 环境的应用中,用户创建账户后可以修改其用户名和密码。这些用户可能享有更高权限或配额。
ClickHouse Cloud 仅在 8443 端口上提供安全的 HTTP 接口。
启用跨域请求支持
为了确保浏览器能够从不同域名的应用中查询 ClickHouse,需在 ClickHouse 中启用跨域请求。在 ClickHouse Cloud 中,此功能已默认启用。
curl -X OPTIONS -I https://clickpy-clickhouse.clickhouse.com -H "Origin: localhost:3000"
HTTP/1.1 204 No Content
Date: Fri, 27 Sep 2024 13:30:36 GMT
Connection: Close
Access-Control-Allow-Origin: *
Access-Control-Allow-Headers: origin, x-requested-with, x-clickhouse-format, x-clickhouse-user, x-clickhouse-key, Authorization
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Max-Age: 86400开源版用户可以通过修改 config.xml 文件中的相关设置来启用此功能。请根据最佳实践配置,考虑是否仅允许来自您应用域的访问,或允许用户在更广泛的场景中使用 ClickHouse 数据。
<!-- It is off by default. Next headers are obligate for CORS.-->
<http_options_response>
<header>
<name>Access-Control-Allow-Origin</name>
<value>*</value>
</header>
<header>
<name>Access-Control-Allow-Headers</name>
<value>origin, x-requested-with</value>
</header>
<header>
<name>Access-Control-Allow-Methods</name>
<value>POST, GET, OPTIONS</value>
</header>
<header>
<name>Access-Control-Max-Age</name>
<value>86400</value>
</header>
</http_options_response>JSON 格式的常用性
JavaScript 对 JSON 的原生支持使其成为 Web 开发中首选的数据交换格式。ClickHouse 支持 20 多种 JSON 格式,每种格式在细节上略有不同。通常,JSON 格式提供结构化且完整的响应,包括列信息及其类型、数据内容和查询统计信息。我们可以通过 fetch API 进行简单测试:
const credentials = btoa('play:');
const response = await fetch('https://clickpy-clickhouse.clickhouse.com', {
method: 'POST',
body: 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSON',
headers: {
'Authorization': `Basic ${credentials}`,
'Content-Type': 'application/x-www-form-urlencoded'
}
});
const data = await response.json();
console.log(JSON.stringify(data, null, 2));{
"meta": [
{
"name": "project",
"type": "String"
},
{
"name": "c",
"type": "Int64"
}
],
"data": [
{
"project": "boto3",
"c": "27234697969"
},
{
"project": "urllib3",
"c": "17015345004"
},
{
"project": "botocore",
"c": "15812406924"
}
],
"rows": 3,
"rows_before_limit_at_least": 695858,
"statistics": {
"elapsed": 0.057031395,
"rows_read": 1046002,
"bytes_read": 32165070
}
}JSON 格式有多种变体,如 JSONObjectEachRow 和 JSONColumnsWithMetadata,用户可能会发现这些格式在某些情况下更便于解析。这些格式将响应封装在外层 JSON 对象中,因此整个数据都需加载到内存中进行解析。对于较小数据量,这通常不成问题,但对于更大数据量,用户可考虑 EachRow 系列格式,这类格式更适合使用 Streams API 解析,如以下示例所示。这些格式,如 JSONEachRow、JSONCompactEachRow 和 JSONEachRowWithProgress,并不严格遵循 JSON 标准,更类似于 NDJSON。
其他格式包括 TSV 和 CSV 的变体,便于数据下载。对于需要高性能处理大数据的用户,如在 WebAssembly 库(如 Perspective)中渲染数据时,ClickHouse 还支持 Arrow 和 ArrowStream 格式。具体示例请点击此处查看【https://clickhouse.com/blog/streaming-real-time-visualizations-clickhouse-apache-arrow-perpsective】。
查询统计和错误处理
ClickHouse 的 HTTP 接口支持通过响应头发送查询进度统计信息。由于这些信息较难阅读,我们建议使用 JSONEachRowWithProgress 格式来获取查询进度统计。
用户还可以通过 X-ClickHouse-Summary 响应头查看查询摘要信息,包括读取的行数、字节数和执行时间。
echo 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSONEachRow' | curl -i -u play: 'https://clickpy-clickhouse.clickhouse.com' --data-binary @-
HTTP/1.1 200 OK
Date: Fri, 27 Sep 2024 15:02:22 GMT
Connection: Keep-Alive
Content-Type: application/x-ndjson; charset=UTF-8
X-ClickHouse-Server-Display-Name: clickhouse-cloud
Transfer-Encoding: chunked
X-ClickHouse-Query-Id: f05b0e25-8b9d-4d28-ad79-fe31e34acfbf
X-ClickHouse-Format: JSONEachRow
X-ClickHouse-Timezone: UTC
Keep-Alive: timeout=10
X-ClickHouse-Summary: {"read_rows":"1046002","read_bytes":"32165070","written_rows":"0","written_bytes":"0","total_rows_to_read":"1046002","result_rows":"0","result_bytes":"0","elapsed_ns":"45896728"}
{"project":"boto3","c":"27234697969"}
{"project":"urllib3","c":"17015345004"}
{"project":"botocore","c":"15812406924"}需要注意的是,若未包含 wait_end_of_query=1 参数,则返回的汇总统计可能不反映整个查询的执行情况。在未设置该参数的情况下,响应会在查询完成前流式传输并返回头信息。若设置该参数,响应会在查询完成后返回,包含完整的统计信息。不过,这样会导致响应在缓冲区中缓存(可能消耗大量内存),并延迟响应的传输,因此不适合在读取大量数据时使用。
echo 'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3 FORMAT JSONEachRow' | curl -i -u play: 'https://clickpy-clickhouse.clickhouse.com' --data-binary @-
HTTP/1.1 200 OK
Date: Fri, 27 Sep 2024 15:02:22 GMT
Connection: Keep-Alive
Content-Type: application/x-ndjson; charset=UTF-8
X-ClickHouse-Server-Display-Name: clickhouse-cloud
Transfer-Encoding: chunked
X-ClickHouse-Query-Id: f05b0e25-8b9d-4d28-ad79-fe31e34acfbf
X-ClickHouse-Format: JSONEachRow
X-ClickHouse-Timezone: UTC
Keep-Alive: timeout=10
X-ClickHouse-Summary: {"read_rows":"1046002","read_bytes":"32165070","written_rows":"0","written_bytes":"0","total_rows_to_read":"1046002","result_rows":"0","result_bytes":"0","elapsed_ns":"45896728"}
{"project":"boto3","c":"27234697969"}
{"project":"urllib3","c":"17015345004"}
{"project":"botocore","c":"15812406924"}建议用户熟悉错误处理。当查询语法正确时,ClickHouse 会返回结果(除非设置了 wait_end_of_query=1)并使用响应代码 200。如果在查询执行期间(可能在数小时后)发生错误,流可能会终止,返回包含错误信息的负载——详见此示例【https://pastila.nl/?0326f8a4/d1d68e3002b4a710bef9ef0a8ac903ef#Mg/lU+udbyoDt+pe4VCASw==】。这部分需要用户自行处理。
设置 wait_end_of_query=1 只能部分缓解此问题。如果手动处理响应,我们始终建议对响应内容进行检查,以确保其正确性。
推荐使用客户端库
对于大多数用例,我们推荐用户使用官方 Web 客户端。此客户端支持常见的请求格式,并确保会话、压缩、错误处理以及长时间运行的查询都能得到正确管理。它提供了一个简洁的接口来实现流式查询,同时具备类型化接口的优势。
import { createClient } from '@clickhouse/client-web';
void (async () => {
const client = createClient( {
url: 'https://clickpy-clickhouse.clickhouse.com',
username: 'play'
}
);
const rows = await client.query({
query:
'SELECT project, sum(count) as c FROM pypi.pypi_downloads GROUP BY project ORDER BY c DESC LIMIT 3',
format: 'JSONEachRow',
});
const result = await rows.json();
result.map(row => console.log(row));
await client.close();
})();使用查询参数
查询参数允许查询模板化,避免了 SQL 语句的字符串操作,特别适用于界面筛选值变化的情况。用户应优先选择查询参数,以增强对 SQL 注入的防护。Web 客户端提供了便捷接口以支持这一功能。
import { createClient } from '@clickhouse/client-web';
void (async () => {
const client = createClient({
url: 'https://clickpy-clickhouse.clickhouse.com',
username: 'play',
});
const rows = await client.query({
query:
'SELECT sum(count) as c FROM pypi.pypi_downloads WHERE project = {project:String}',
format: 'JSONEachRow',
query_params: {
project: 'clickhouse-connect',
}
});
const result = await rows.json();
result.map(row => console.log(row));
await client.close();
})();最小特权原则
在授予表权限时,建议始终遵循最小特权原则。ClickHouse 遵循这一原则,新用户默认没有任何权限(除非指定了默认角色)。
提示:如果创建仅用于客户端访问的用户,一般不需要设置密码,因为这些凭证在应用中是可见的。要创建无密码用户:
-- oss
CREATE USER play IDENTIFIED WITH no_password;
-- clickhouse cloud
CREATE USER play IDENTIFIED WITH double_sha1_hash BY 'BE1BDEC0AA74B4DCB079943E70528096CCA985F8';通常建议先创建角色,以便在需要时赋予其他用户(假设所有客户端使用相同的用户),并为角色授予以下权限。
首先,确定 Web 用户可访问的表和列,并授予 SELECT 权限。例如,下述配置允许拥有 play_role 角色的用户读取 pypi 数据库中的所有表(和列)。此外,具有此角色的用户只能读取 github 数据库中 events 表的 event_type 和 actor_login 列(需显式指定,不允许 * )。
我们还将该角色授予了之前的 play 用户。
-- create the role
CREATE ROLE play_role;
-- limit read on the columns event_type, actor_login for the github.events table
GRANT SELECT(event_type, actor_login ) ON github.events TO play_role;
-- allow select on all tables in the pypi database
GRANT SELECT ON pypi.* TO play_role;
-- grant the role to the user
GRANT play_role TO play;还可以设置基于行的策略,使用户仅能查看特定表的部分行。点击此处查看更多详情。
设置只读权限和常见查询限制
上述配置创建了一个仅具有 SELECT 权限的受限用户。我们可以通过创建设置配置文件并将其应用于用户角色来进一步限制权限。
在配置文件中,将用户角色的 read_only 设置为 1,以限制用户仅能进行只读操作。这会阻止用户进行会话或设置修改的查询操作。虽然这为用户提供了只读限制,但不会限制其执行复杂查询的能力。为此,我们可以在配置文件中添加查询复杂性限制。
这些设置可以精细控制查询的执行。配置项相当丰富,但我们建议至少设置以下几项:
-
max_execution_time:查询的最大执行时间。
-
max_rows_to_read 和 max_bytes_to_read:每个查询的最大读取行数和字节数。
-
max_result_rows 和 max_result_bytes:每个响应的最大返回行数和字节数。
-
max_memory_usage:查询的最大内存使用量。
-
max_bytes_before_external_group_by:在 GROUP BY 溢出到磁盘前的最大内存限制。
以下是 play.clickhouse.com 的 play 用户的设置示例,具有合理的限制值。
CREATE SETTINGS PROFILE `play` SETTINGS readonly = 1, max_execution_time = 60, max_rows_to_read = 10000000000, max_result_rows = 1000, max_bytes_to_read = 1000000000000, max_result_bytes = 10000000, max_network_bandwidth = 25000000, max_memory_usage = 20000000000, max_bytes_before_external_group_by = 10000000000, enable_http_compression = true
--assign settings profile to the role
ALTER USER play SETTINGS PROFILE play_role需注意的是,这些设置针对每个查询生效。此外,还需要设置配额(见下文)来限制查询总数。
默认情况下,查询超出这些限制会返回错误提示。对于查询集受限的应用来说,这种行为适用,主要目的是阻止滥用查询。在某些场景中,您可能希望达到限制时允许用户接收部分结果,例如 CryptoHouse 中,用户可以运行任意 select 查询并接收当前结果。
要实现部分响应的功能,可在配置文件中将溢出模式设置为 break。例如,设置 result_overflow_mode = 'break' 会在达到 max_result_rows 限制时中断查询执行。
请注意,返回的行数可能超过 max_result_rows,因为执行会在块级别中断,并取决于 max_block_size 和 max_threads 的倍数。
通常,设置 read_overflow_mode=break 也非常有用,这样在读取过多行时会中断执行并返回当前结果。用户可以通过对比摘要统计中的 read_rows 与设定限制来检测中断(并显示警告)。
必要时允许更改部分设置
只读用户(readonly=1)通常无法在查询时修改设置。这一限制通常是合理的,但在某些用例下可能需要调整。例如,Grafana 需要为只读用户修改 max_execution_time 设置。此外,根据结果集大小,您可能希望用户可以选择是否启用响应压缩(需设置 enable_http_compression=1)。
我们不建议使用 readonly=2 以避免用户修改所有设置。相反,可以对特定设置添加约束,允许用户在指定的范围内进行调整。
通过这些约束,可以为数值设置定义 min 和 max 范围。对于接受枚举值的设置,可以通过 changeable_in_readonly 约束将其设为可更改,即使 readonly 设置为 1 也允许在指定范围内调整。否则,readonly=1 时不允许修改设置。
只有在 clickhouse.xml 配置中启用 settings_constraints_replace_previous 后,changeable_in_readonly 才可用。
<access_control_improvements>
<settings_constraints_replace_previous>true</settings_constraints_replace_previous>
</access_control_improvements>以下是一个设置配置示例:
CREATE SETTINGS PROFILE `play` SETTINGS readonly = 1, max_execution_time = 2, enable_http_compression = false此配置阻止用户使用 HTTP 压缩,并将查询执行时间限制为 2 秒。因此,以下查询将会失败:
echo "SELECT sleep(3)" | curl -s -u play: 'https://clickpy-clickhouse.clickhouse.com
' --data-binary @-
Code: 159. DB::Exception: Timeout exceeded: elapsed 2.002346261 seconds, maximum: 2. (TIMEOUT_EXCEEDED) (version 24.6.1.4501 (official build))
echo "SELECT sleep(1) SETTINGS enable_http_compression=1" | curl -u play: 'https://clickpy-clickhouse.clickhouse.com?compress=true' --data-binary @- -H 'Accept-Encoding: gzip' --output -
Code: 164. DB::Exception: Cannot modify 'enable_http_compression' setting in readonly mode. (READONLY) (version 24.6.1.4501 (official build))我们可以修改设置配置,利用约束允许调整这些设置。
ALTER SETTINGS PROFILE `play` SETTINGS readonly = 1, max_execution_time = 10 CHANGEABLE_IN_READONLY min=1 max=60, enable_http_compression = false CHANGEABLE_IN_READONLY上述查询现在可以正常执行:
echo "SELECT sleep(3) SETTINGS max_execution_time=4" | curl -s -u play_v2: 'https://k5u1q15mc4.us-central1.gcp.clickhouse.cloud' --data-binary @-
0
echo "SELECT sleep(1) SETTINGS enable_http_compression=1" | curl -u play_v2: 'https://k5u1q15mc4.us-central1.gcp.clickhouse.cloud?compress=true' --data-binary @- -H 'Accept-Encoding: gzip' --output -
}''ߨ')CN''
')'2'设置查询配额
前述设置仅限制单个查询,而不会控制整体查询吞吐量。即使恶意用户受单次查询限制,他们仍可能发起数千个并发查询,从而耗尽所有可用资源。
为了限制某个用户名的总查询数量,我们可以创建配额并将其分配给特定角色。配额可以限制每单位时间内的查询次数。需要注意,许多用户或客户端可能共享同一用户名。我们希望配额针对每个客户端生效,而不仅限于用户名,否则单一恶意客户端可能会用尽所有用户的配额。
为此,我们将配额基于 IP 地址进行跟踪。这样每个 IP 的查询都会被分别计入配额。例如,以下示例中创建了 play 配额,每分钟最多允许 2 次查询,并将其应用于 play_role 角色。
CREATE QUOTA play KEYED BY ip_address FOR INTERVAL 1 minute MAX queries = 2 TO play_role非 play 用户不受该配额限制,可能导致超额查询:
echo "SELECT sum(number) FROM numbers(1000)" | curl -u play_v2: 'https://k5u1q15mc4.us-central1.gcp.clickhouse.cloud' --data-binary @-
Code: 201. DB::Exception: Quota for user `play_v2` for 60s has been exceeded: queries = 2/1. Interval will end at 2024-09-27 16:52:00. Name of quota template: `play_v2`. (QUOTA_EXCEEDED) (version 24.6.1.4501 (official build))在 ClickHouse Cloud 中,配额设置是按副本应用的。设置配额值时需考虑此影响。
为不同功能分配用户角色
在开发应用时,通常需要为不同功能部分设置不同的查询限制。例如,用于执行查询的用户名可能限制每小时的查询次数,而某些组件可能需要更高频率的更新以显示统计数据,这些数据可能来自物化视图,并需要每秒更新一次,更新频率远高于标准用户。
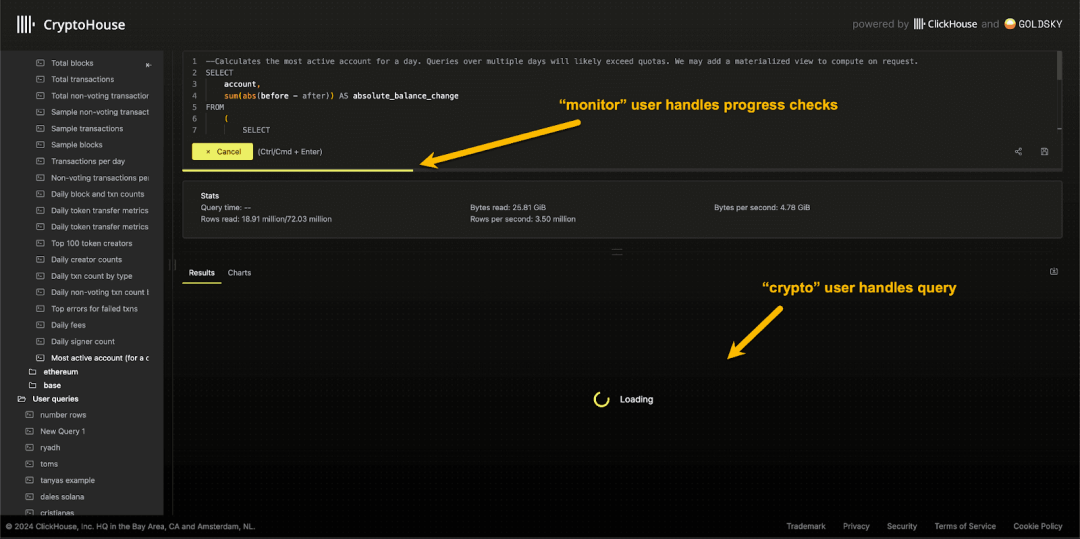
为此,我们建议为不同角色创建用户,并设定相应的配额。例如,在 CryptoHouse 的配置中,用于运行查询的用户 crypto 被限制为每小时 120 次查询,而 monitor 用户用于实时获取查询进度,配额更高,但仅限访问特定表。
物化视图提升查询效率
我们建议开发人员将频繁执行的查询转向物化视图。在 ClickHouse 中,物化视图最简单的形式是一个在向表插入数据时触发的查询。物化视图本身不存储数据,而是对插入的行执行查询,并将结果发送到“目标表”存储。
参考视频【https://youtu.be/QUigKP7iy7Y】
关键在于,物化视图的查询可以将数据聚合成更小的结果集,从而使查询在目标表上执行更快。这种方法将工作从查询时转移至插入时,避免了查询复杂性限制,减少资源需求,并提升用户界面的响应速度。
我们在广受欢迎的 ClickPy 演示中应用了这一技术,让用户可以对 Python 包数据进行分析。示例视图和详细实现请点击此处查看【https://github.com/ClickHouse/Clickpy?tab=readme-ov-file#a-real-example】。
高效利用响应压缩
ClickHouse 的 HTTP 端点支持请求和响应的压缩。对于前文提到的文本格式,我们建议使用 HTTP 响应压缩。由于读取请求通常数据量小,因此在开发仅客户端应用时才有必要启用响应压缩。建议仅在网络出现瓶颈且响应数据较大时启用压缩,以免服务器因 CPU 开销而降低响应速度。请务必进行测试和评估。
若用户启用了 enable_http_compression=1(或在请求中设置),可以在请求头 Accept-Encoding 中指定所需的压缩方法,ClickHouse 支持多种选项。
const client = createClient( {
url: 'https://clickpy-clickhouse.clickhouse.com',
username: 'play',
compression: {
response: true
}
}
);如需压缩,推荐使用支持 gzip 压缩的 ClickHouse JS 客户端,它会自动设置必要的请求头和配置。
预定义 HTTP 接口
开源用户可以利用预定义 HTTP 接口将客户端与 SQL 查询解耦。此功能允许 ClickHouse 暴露一个端点,将用户传入的参数注入到预定义 SQL 查询中,并将结果返回给用户。对于简单的业务应用,这能让客户端只需调用有限的 REST API。前述访问限制和配额管理的原则同样适用于调用用户。
ClickHouse Cloud 的 Query Endpoints
预定义的 HTTP 接口存在局限,尤其是更改或添加端点时需要修改 clickhouse.xml 配置。
一些用户可能也不愿意公开 ClickHouse HTTP 接口。Query Endpoints 通过限制可执行的查询类型,有效减少潜在攻击风险,解决了这些问题。
ClickHouse Cloud 的 Query Endpoints 功能更为高级,采用基于 Token 的身份验证机制。除了支持查询模板化,用户还可以为端点分配角色(从而应用设置限制和配额),并为每个端点配置 CORS 设置。用户可以随时在 ClickHouse Cloud 的控制台中轻松添加或修改这些端点。
参考视频【https://youtu.be/QUigKP7iy7Y】
API 端点不仅简化了接口,还实现了关注点分离。不仅便于更新应用查询而无需修改代码,同时也让团队可以轻松公开分析数据,无需编写 SQL 或直接与其他团队的 ClickHouse 数据库交互。我们提到的所有最佳实践都集成在这些端点中,开发者只需与简单的 REST API 交互。
有关示例,请参考此博客【在 10 分钟内通过 ClickHouse Cloud 查询端点给应用程序增加数据分析功能】。
总结
仅客户端架构【client-only architecture】非常适合小型应用、演示和单页应用,简化了开发过程,并将扩展需求交由数据库管理,从而加快了迭代速度。然而,实现此架构要求目标数据库不仅支持 HTTP 接口,还具备确保安全暴露给客户端的功能。尽管 Firebase 和 Supabase 已将此架构推广用于 OLTP 工作负载,ClickHouse 也具备相应的功能支持,将其应用于实时分析。我们提供了全面的建议,用于配置 ClickHouse 以适应仅客户端架构。对于希望更简化体验的用户,ClickHouse 的 Query Endpoints 可以抽象出大部分复杂性,使用户能够通过简单的 REST 端点利用 ClickHouse 高效的分析查询能力。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:[email protected]

联系我们
手机号:13910395701
满足您所有的在线分析列式数据库管理需求