大家好呀,我是前端创可贴。

从这一章开始,我们将基于官方标准规范开始研究 HTML,掀开它神秘的面纱,看看它究竟是何方神圣。
前言
HTML 全名叫做 Hyper Text Markup Language,即超文本标记语言。啥叫“超文本”?引用一下维基百科的解释:
Hypertext is text displayed on a computer display or other electronic devices with references (hyperlinks) to other text that the reader can immediately access. Hypertext documents are interconnected by hyperlinks, which are typically activated by a mouse click, keypress set, or screen touch. Apart from text, the term "hypertext" is also sometimes used to describe tables, images, and other presentational content formats with integrated hyperlinks. Hypertext is one of the key underlying concepts of the World Wide Web, where Web pages are often written in the Hypertext Markup Language (HTML). As implemented on the Web, hypertext enables the easy-to-use publication of information over the Internet.
翻译过来大概就是,超文本是显示在计算机显示器或其他电子设备上的文本,并且可以通过超链接去访问别的文本,以此建立连接。除了文本之外,超文本有时也用于描述带有集成超链接的表格、图像和其他表示内容格式。超文本是万维网的关键基础概念之一,超文本可以在 Internet 上方便地发布信息。
用大白话说,超文本就是可以和其他文档互相连接的文本,并且文本可以并不仅仅是普通的文字,还可以是表格、图片、音视频等等。
HTML 是 World Wide Web(万维网)的核心标记语言,其实一开始 HTML 设计出来主要是用于语义化的描述科学文献的,目的是为了方便科学家之间共享研究成果。
但是其整体设计的强适应性和扩展性,让其在后续的很多年里扩展了许多功能,可以用于描述很多其他类型的文档甚至是应用,完全超出了当初设计时的目标。
这个跟 JavaScript 的发展还是有点像的,一开始都是出于一些小的目标而创建的,随着时代的发展,他们都越来越壮大,最终成为构建 Web 的基石。

历史
在 HTML 诞生的最初前 5 年(1990-1995),HTML 经历了很多修订和扩展,一开始主要是由 CERN(欧洲核子研究组织) 负责,然后交给了 IETF(国际互联网工程任务组)。
随着我们熟悉的 W3C(World Wide Web Consortium)组织的创建,HTML 交给了 W3C 维护。第一次尝试扩展 HTML 发生于 1995 年,并以失败告终,即 HTML 3.0,然后于 1997 年完成了更加务实的版本,即 HTML 3.2。并且在同年晚些时候,HTML4 也出现了。
第二年,W3C 决定不再发展 HTML,而是研究基于 XML 的替代品,称为 XHTML。在 XHTML 1.0 以后呢,W3C 致力于让 XHTML 基于其模块化,能够更容易被他人扩展。同时,W3C 还在忙着新的语言,该语言与之前的 HTML 和 XHTML 都不兼容,即 XHTML2。(好好好,W3C 脚踏两只船是吧)
在 2004 年的 W3C 研讨会上,Mozilla 和 Opera 联合向 W3C 提交了 HTML5 工作的一些基本原则,但是提议被拒绝了,理由是该提议与之前选择的网络发展方向相冲突,W3C 的员工和成员投票决定继续开发基于 XML 的替代品。

此后不久,苹果、Mozilla 和 Opera 联合宣布,他们将以 WHATWG (Web Hypertext Application Technology Working Group)为名成立新组织,继续努力发展 HTML,并将草案移到了 WHATWG 站点。版权由三个供应商共同拥有,并允许对规范进行重用。
在 2006 年,W3C 表示有兴趣参与 HTML5 的开发,并在 2007 年成立了一个工作组,与 WHATWG 合作开发 HTML5 规范。苹果、Mozilla 和 Opera 允许 W3C 在 W3C 的版权下发布规范(W3C 你们好好看看,这才叫热爱),同时在 WHATWG 网站上保留限制较少的版本。

之后的几年里,两个组织都在一起工作。但是在 2011年,两个小组得出结论,他们的目标不同:W3C 想要发布一个最终版本的 HTML5(W3C 你们能别作妖了吗),而 WHATWG 想要继续致力于推动 HTML 的标准,不断维护规范。
而后到了 2019 年,WHATWG 和 W3C 签署了一项协议,共同开发 HTML 的唯一版本,也就是我们目前看的官方规范。
纵观历史我们可以看到,其实 W3C 很早就“嫌弃”HTML 了,总是想着发展 HTML 的替代品将其取代,但是以苹果、Mozilla 和 Opera 为首的浏览器厂商,对 HTML 不离不弃,宁愿与 W3C 这种官方组织作对,也要努力推动 HTML 的发展。后面 W3C 看到 HTML5 发展的不错,又“厚着脸皮”想和 WHATWG 一起开发 HTML5 的规范。但是终究死心不改,总想着发布一个最终版本的 HTML5 以此结束它的发展。从 1998 年到 2019 年前后这么多年里,W3C 总是想着能结束 HTML 的发展,但是它却又是 HTML 的官方组织,HTML 能发展到现在,我们大家真的需要感谢那些浏览器厂商前辈们,没有他们的坚持,或许我们现在用的早就不是 HTML 了,来让我们一起:

大家提到 W3C 就想到他是 HTML 的官方组织,但是其实他就是个渣男,总嫌弃自己女朋友还想着找小三,有人替他照顾女朋友了,他又后悔了企图上演“燃冬”剧情,但是心里总是还想着终结女朋友的发展,但是没想到女朋友的事业发展蒸蒸日上,只能妥协做出让步。以后大家再看到 W3C,请大家一起向它抛出鄙视的眼神:

设计原则
序列化执行脚本
为了避免向 web 开发者暴露多线程的复杂性,HTML 和 DOM API 被设计为,脚本无法检测到其他脚本的同步执行。即使使用了 worker,但是其实它可以被看作是在全局中完全序列化的执行所有脚本。
虽然 worker 可以开启新的线程(其实是创建了一个 agent,其包含了一个新的执行线程,agent 在下面简单的介绍了一下)执行脚本,不会阻塞主线程,做到并发执行,但是其实 worker 并不是真正意义上的多线程,像 Java、C++ 这样的语言的多线程是可以共享内存的,worker 是做不到的,只能通过 postMessage 进行消息传递。所以虽然 worker 可以做到脚本在不同的线程中运行,但它们之间的交互是通过消息传递顺序化的,因此不会出现多线程竞争和同步问题,这种设计简化了并发编程,Web 开发者不必直接面对复杂的多线程编程挑战。因此从逻辑上讲,所有脚本的执行行为可以被看作是全局上的序列化执行,而不是传统意义上的多线程并发执行。

有一个例外,就是 SharedArrayBuffer 类,使用 SharedArrayBuffer 对象,就可以观察到在其他 agent 中的脚本正在同步执行,因为他们共享了一块内存,在同一块内存进行数据的读写。
上面的 agent 是个啥呢?简单介绍一下,agent 由一组 ECMAScript 执行上下文、一个独享的执行上下文栈、一个运行时执行上下文、一个 Agent Record 和一个执行线程组成。可以理解为,agent 就是一个 JavaScript 代码的执行环境。
在 web 平台上有下面 5 种 agent 的类型:
Similar-origin window agent:可能含有几个Window对象,可以互相访问,要么直接访问要么通过document.domain。例如同源的窗口或标签页,他们之间就可以通过 postMessage 进行访问。每个窗口或标签页也都会创建一个 agent。
Dedicated worker agent:含有一个DedicatedWorkerGlobalScope对象。新建dedicated worker时会创建这个agent。很多人看到这个dedicated worker比较陌生,其实有个同家族的shared worker大家应该比较熟悉,dedicated worker只能被调用它的脚本访问,而shared worker可以被多个脚本访问。
Shared worker agent:含有一个SharedWorkerGlobalScope对象,新建shared worker时创建这个agent。
Service worker agent:含有一个ServiceWorkerGlobalScope对象,新建service worker时创建这个agent。
Worklet agent:含有一个WorkletGlobalScope对象。该 agent 是一种较轻量的脚本执行环境,与上面的 Workers 类似。Worklet 提供了一个高效的、低延迟的机制来执行特定类型的任务,比如音频处理、动画、和自定义渲染。
说到 agent 很多人都不熟悉,但是它其实跟一个我们大家都知道的一个概念有很大关系,就是 event loop,后续在 JavaScript 系列篇中再详细介绍~

可扩展性
HTML 有很多可扩展性机制用来安全的添加语义化。
- 开发者可以通过 class 属性扩展元素,根据现有的 HTML 元素和属性来创建自己的元素,以此让浏览器和其他工具就算不知道开发者的扩展,依然可以很好的支持它。这就是微格式(microformats)的策略。
-
- 微格式就是在 web 页面上语义化(就是根据标准给元素添加指定 class 类名或 rel 属性)地标记数据,能够被例如搜索引擎、浏览器和其他应用所理解。微格式是有标准的,目前最新的标准是 microformats2,根据标准里定义的写法,在元素上加上指定的 class 或者 rel 属性,再通过 parser 即可解析出 HTML 微格式所代表的数据。
- 开发者可以通过自定义的
data-*=""属性在 HTML 元素上保存自定义数据,浏览器永远都不会触碰到这种数据,而脚本可以寻找这些元素然后获取数据。
-
- 使用过 Vue 的小伙伴对这个属性是不是很眼熟:
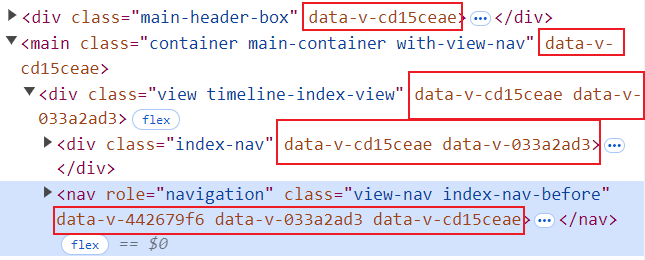
-
- 平时开发里我们也可以给元素加上
data-*的属性,在 CSS 里通过属性选择器即可访问到这些元素,也可以通过 JavaScript 获取属性值。
- 平时开发里我们也可以给元素加上
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
div[data-woundplast="hi"] {
width: 300px;
height: 300px;
float: right;
background-color: aquamarine;
}
</style>
</head>
<body>
<div data-woundplast="hi">前端创可贴</div>
</body>
<script>
const divdom = document.querySelector('div');
console.log(divdom?.getAttribute("data-woundplast"));
console.log(divdom?.dataset);
</script>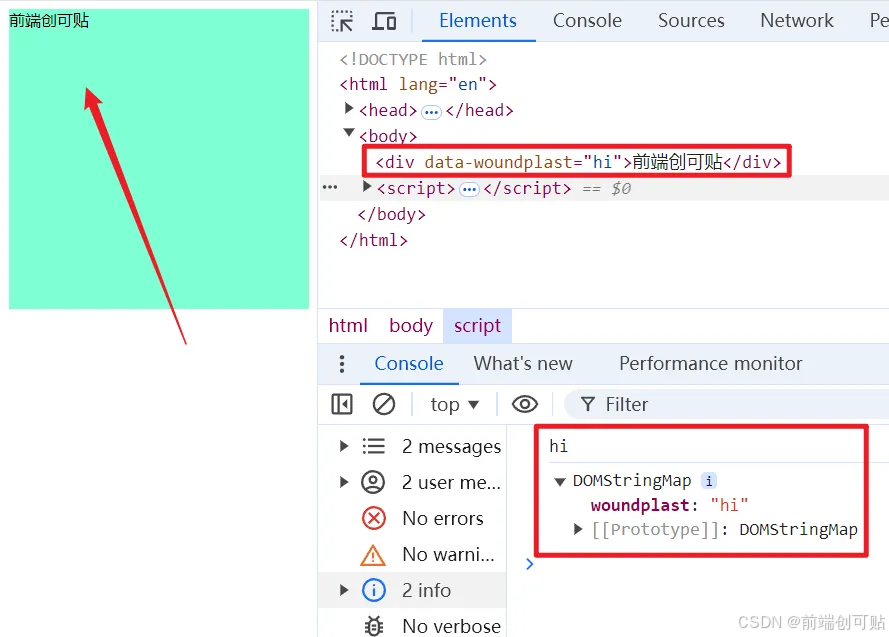
- 开发者可以通过
<meta name="" content="">机制定义页面元数据,让浏览器更好的解析页面。
-
- 比如我们常用的设置字符集
<meta charset="UTF-8" />。 - 还有通过 meta 标签的 name-content 这种键值对的形式,告诉浏览器一些元数据以便浏览器解析,例如我们最常用的移动端设置 layout viewport 的时候就会用到
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0" />
- 比如我们常用的设置字符集
- 开发者可以使用
rel=""机制通过预定义的链接类型来指定链接具体的含义,上面提到的微格式也用到了它。
-
- 乍一看这个 rel(relation 简称) 属性可能有些同学感到些许陌生,但是看到这个你肯定就想起来了:
<link rel="stylesheet" href="..." />。rel 属性定义了链接资源和当前文档的关系,可用于link、a、area和form元素,可用的 rel 属性值在这里。常用的有stylesheet、dns-prefetch、nofollow、noreferrer、prefetch、preload等。
- 乍一看这个 rel(relation 简称) 属性可能有些同学感到些许陌生,但是看到这个你肯定就想起来了:
- 开发者可以通过
<script type="">自定义 type 值,嵌入原始数据,以供内联或外部脚本访问。
-
- 我们经常在编写或使用前端模板引擎的时候会用到这样的写法,在自定义 type 的 script 标签里定义好模板,再将数据塞进去进行替换。
<script src="https://cdnjs.cloudflare.com/ajax/libs/mustache.js/0.1/mustache.min.js"></script>
<body>
<div class="display" />
<script type="template" id="template">
<div>
<ul>
<li>姓名:{
{name}}</li>
<li>年龄:{
{age}}</li>
<li>电话:{
{phone}}</li>
<ul>
</div>
</script>
<script>
const user = { name: "前端创可贴", age: 18, phone: "xxx" };
// Get elements template.
const template = document.getElementById("template").innerHTML;
const view = Mustache.render(template, user);
document.querySelector(".display").innerHTML = view;
</script>
</body>
- 开发者可以使用 JavaScript 的原型机制扩展 API,这个大家应该就非常熟悉了,比如在类的继承时会用到。
- 开发者可以通过
itemscope=""和itemprop=""属性,使用微数据(microdata)特性嵌入嵌套的 name-value 键值对的数据,方便搜索引擎和其他应用理解我们的内容,比如告诉搜索引擎,某段信息描述的是一部电影、一个人或一个地方。
-
- itemscope 属性用来指定关联的元数据的范围,给元素加上了 itemscope 属性,就会创建一个
item,表示会有一些键值对关联在该元素上。
- itemscope 属性用来指定关联的元数据的范围,给元素加上了 itemscope 属性,就会创建一个
-
- itemscope 属性可以用在任何 HTML 元素上,是一个 boolean 类型的属性,即不用写属性值。指定了 itemscope 属性的元素上,还可以加上 itemtype 属性,这个属性用来表明上面创建的
item的类型,这个属性必须是一个有效的词汇的 URL,例如 schema.org 里的 https://schema.org/Movie,说明通过 itemscope 属性创建的item的类型是电影。
- itemscope 属性可以用在任何 HTML 元素上,是一个 boolean 类型的属性,即不用写属性值。指定了 itemscope 属性的元素上,还可以加上 itemtype 属性,这个属性用来表明上面创建的
-
- 再通过 itemprop 来指定键值对中的键名,根据 itemtype 所指定的 URL 所代表的类型,键名可以指定为哪些已经被规定好了,大家可以点击上面的链接,看看 Movie 这个类型可以指定哪些键。例如下面这段代码,就是在告诉搜索引擎,这段信息描述的是一部电影的相关信息:
<div itemscope itemtype="https://schema.org/Movie">
<h1 itemprop="name">Avatar</h1>
<span>
Director: <span itemprop="director">James Cameron</span> (born August 16,
1954)
</span>
<span itemprop="genre">Science fiction</span>
<a href="https://youtu.be/0AY1XIkX7bY" itemprop="trailer">Trailer</a>
</div>- 开发者可以使用自定义元素来扩展 HTML,自定义元素必须带有
-,为的是保证兼容性,因为 HTML、SVG、MathML 的标准元素不可能会有-。
-
- 自定义元素在平时开发中用的比较少,但是在一些微前端的解决方案中,用的就是自定义元素,再结合
Shadow DOM,创建一个Web Component,即可产生天然的沙箱隔离。
- 自定义元素在平时开发中用的比较少,但是在一些微前端的解决方案中,用的就是自定义元素,再结合
<body>
<h1>Custom element demo</h1>
<open-shadow text="I have an open shadow root"></open-shadow>
</body>
<script>
customElements.define(
"open-shadow",
class extends HTMLElement {
constructor() {
super();
const pElem = document.createElement("p");
pElem.textContent = this.getAttribute("text");
const shadowRoot = this.attachShadow({ mode: "open" });
shadowRoot.appendChild(pElem);
}
}
);
</script>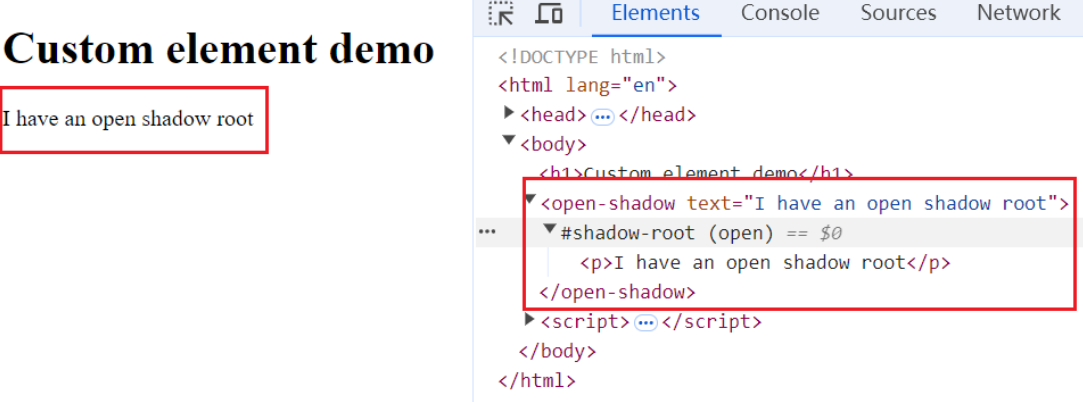
HTML 简单介绍
这里我们先简单的介绍一下 HTML ,后续的系列篇会更加仔细的介绍 HTML 的细节。
看一个最基本的 HTML 文档:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Sample page</title>
</head>
<body>
<h1>Sample page</h1>
<p>This is a <a href="demo.html">simple</a> sample.</p>
<!-- this is a comment -->
</body>
</html>HTML 文档由一棵树组成,包含了元素和文本,元素由开始标签(start tag)和结束标签(end tag)来表示,在某些情况下元素的开始标签和结束标签是可以省略的(没错,不仅仅是结束标签可以省略,就连开始标签都可以一起省略,后续的系列篇再详细介绍~)。
元素标签可以嵌套,子元素必须完全在父元素里面,不能重叠,比如下面这段代码就是错误的:
<p>This is <em>very <strong>wrong</em>!</strong></p>正确的应该是:
<p>This <em>is <strong>correct</strong>.</em></p>元素可以指定属性(attribute),由 = 分割开属性名和属性值,当属性值没有空格、"、'、`、=、<、>时,属性值可以不写引号,否则必须用单引号或双引号。如果属性值是空,可以将属性值和 = 符号一起省略。
<input name=前端创可贴 disabled />
<input name=前端创可贴 disabled="" />
<input name='前端创可贴' maxlength=2>
<input name="前端创可贴" maxlength="2">HTML 的 user agent(例如浏览器)就会解析 HTML 代码,将其转变成 DOM(Document Object Model)树,DOM 树是文档在内存中的表示。
页面里的脚本(通常是 JavaScript)可以修改 DOM 树,通过 script 元素或事件处理类型的属性(例如 onclick)。
<form name="main">
你好呀: <output name="result"></output>
<script>
document.forms.main.elements.result.value = "前端创可贴";
</script>
</form>DOM 树中的每一个元素都对应着一个对象,这些对象都有一些 API 可以改变元素的属性:
const a = document.links[0];
a.href = 'aaa.html';
a.protocol = 'https';
a.setAttribute('href', 'https://aaa.com/');需要注意的安全问题
一旦 HTML 页面有了交互,我们就需要注意很多安全问题,这里简单介绍几个常见的 web 安全问题,后续的系列篇再详细介绍~

Cross-site scripting (XSS)
在我们接收不可信的输入(比如用户评论、URL 参数里的值、第三方网站的消息等)的时候,在使用它们之前我们一定要先校验一遍,并且展示的时候需要对文本进行转义。否则很有可能受到跨站脚本(XSS)攻击,简单来说就是在不可信的输入里,可能包含了一些会被 HTML 解析成可执行的代码,而这些代码很明显并不是我们自己的代码,所以会对用户有害,比如打开一个新页面,拼接上 cookie 等,就泄露了用户数据。这种类型的安全问题叫做跨站脚本攻击。
以下方式都可以插入可执行代码或改写网站的本意:
- img 元素的一些属性例如 onload、onerror,可以执行任意的 JavaScript 代码。
<img src="" alt="" onerror="alert('前端创可贴')" />
- 当使用别人提供的 URL 作为链接时,如果链接前缀是
javascript:,就可能会执行有害的代码而不是跳转链接。而且不仅仅是javascript:,有的 user agent 可能会实现别的这种规则,从而引发漏洞。
<a href="javascript:alert('前端创可贴')">前端创可贴</a>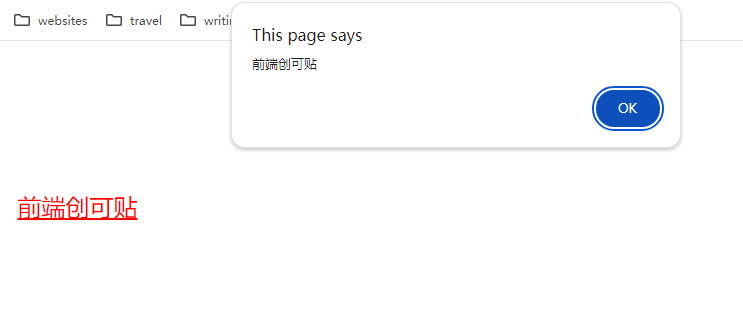
- base 元素可以改写当前页面的 base URL,当页面存在相对路径时,这个路径就被 base 元素给改写了,不再是服务器原本的路径了。
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<base href="http://www.baidu.com" />
<title>Document</title>
</head>
<body>
<a href="a.html">a</a>
</body>假设当前页面是 http://a.com/index.html,本来点击 a 标签是跳转到 http://a.com/a.html,但是因为 base 元素将页面的 base URL 改写成了 baidu.com,跳转路径变成了 http://www.baidu.com/a.html。
Cross-site request forgery (CSRF)
当网站允许用户提交有副作用的表单数据时,比如购买商品、转账、请求密码等,这种会影响到用户数据和安全的情况,一定要验证这些请求是用户主动发起的,而不是被别人伪造的。这个安全问题叫做跨站请求伪造。
引发这个安全问题的原因之一是,HTML 表单可以提交给其他源(只有协议、域名、端口号全都相同时才是同源),也就是说表单的提交是可以跨域的(这是一道面试题,面试官会问表单可以跨域吗?请大声且自信的说出答案:可以!)。

网站可以通过下发用户 token、检查 Origin 请求头等方式避免请求伪造的攻击。
Clickjacking
什么是点击劫持呢?“点击劫持”攻击允许恶意页面以用户的名义点击“受害网站”。
以微博为例:
- 恶意页面吸引访问者,例如一个游戏;
- 页面上有一个看起来无害的链接或按钮,吸引用户去点击;
- 恶意页面在无害的链接或按钮上面,隐藏了一个透明的 iframe,其 src 就是微博,比如恶意页面主人的某个帖子的点赞按钮;
- 访问者想要点的是恶意页面看起来无害的链接或按钮,但实际上点的是一个点赞按钮。
网站可以通过限制其不能在 iframe 中嵌入来避免这个安全问题,比如通过对比 window 对象和 top 对象值是否相同(页面没有被嵌入 iframe 时,window === top 为 true)、X-Frame-Options 响应头限制页面不能嵌入 iframe 中等方式。
绑定事件时常见的陷阱
HTML 中的脚本具有“运行至完成”(run-to-completion)的特点,也就是说浏览器通常会在执行其他操作(如触发进一步的事件或继续解析文档)之前不间断地运行完脚本。
另一方面,HTML 文件的解析是增量进行的,也就是说解析器可以在任何时候暂停以运行脚本。这通常是件好事,但这也意味着开发者需要避免在事件已经触发了以后才绑定事件处理程序,很明显这种情况你的事件处理程序压根不会起作用。

有两种方式可以避免这个问题:
- 使用事件处理类型的属性,比如想给 img 元素绑定 error 事件,就直接在 img 元素上设置 onerror 属性。
- 在脚本中创建元素,然后在同一个脚本中立马添加事件处理程序。不用担心这样写会不会还是在触发了事件以后才绑定了事件处理程序,因为上面说了,脚本会在其他事件触发之前运行至完成,所以一定会在事件触发之前就绑定了。
举个例子,我们想给 img 标签绑定 load 事件,img 图片一旦加载完了,就会立马执行我们的 load 事件,尤其是当这个图片在缓存里,图片的加载会特别快,执行 load 事件就会更快更早。按照上面的两种方式,我们可以这样写:
- 在 img 元素上设置 onload 属性:
<img src="cat.png" alt="cat" onload="yourEventHandler(event)">- 如果一开始 img 元素不在 HTML 中,而是通过脚本创建的,就需要在创建 img 元素之后立马绑定 onload 事件:
<script>
const img = new Image();
img.src = 'cat.png';
img.alt = 'cat';
img.onload = yourEventHandler;
</script>如果你不在创建 img 元素后立马绑定事件,而是在另外一个 script 元素里绑定 onload 事件,那么就有可能在执行到绑定 onload 事件的 script 元素之前就已经加载了图片,onload 事件处理程序根本没有执行。
<img id="img" src="cat.png" alt="cat">
<!-- 可能在这里图片已经加载完了,解析器还没来得及执行下面的脚本 -->
<script>
const img = document.getElementById('img');
img.onload = yourEventHandler; // 在绑定事件之前图片可能已经加载完了,这里的事件处理程序根本不会执行
</script>怎么捕获编写 HTML 代码时的错误和不规范
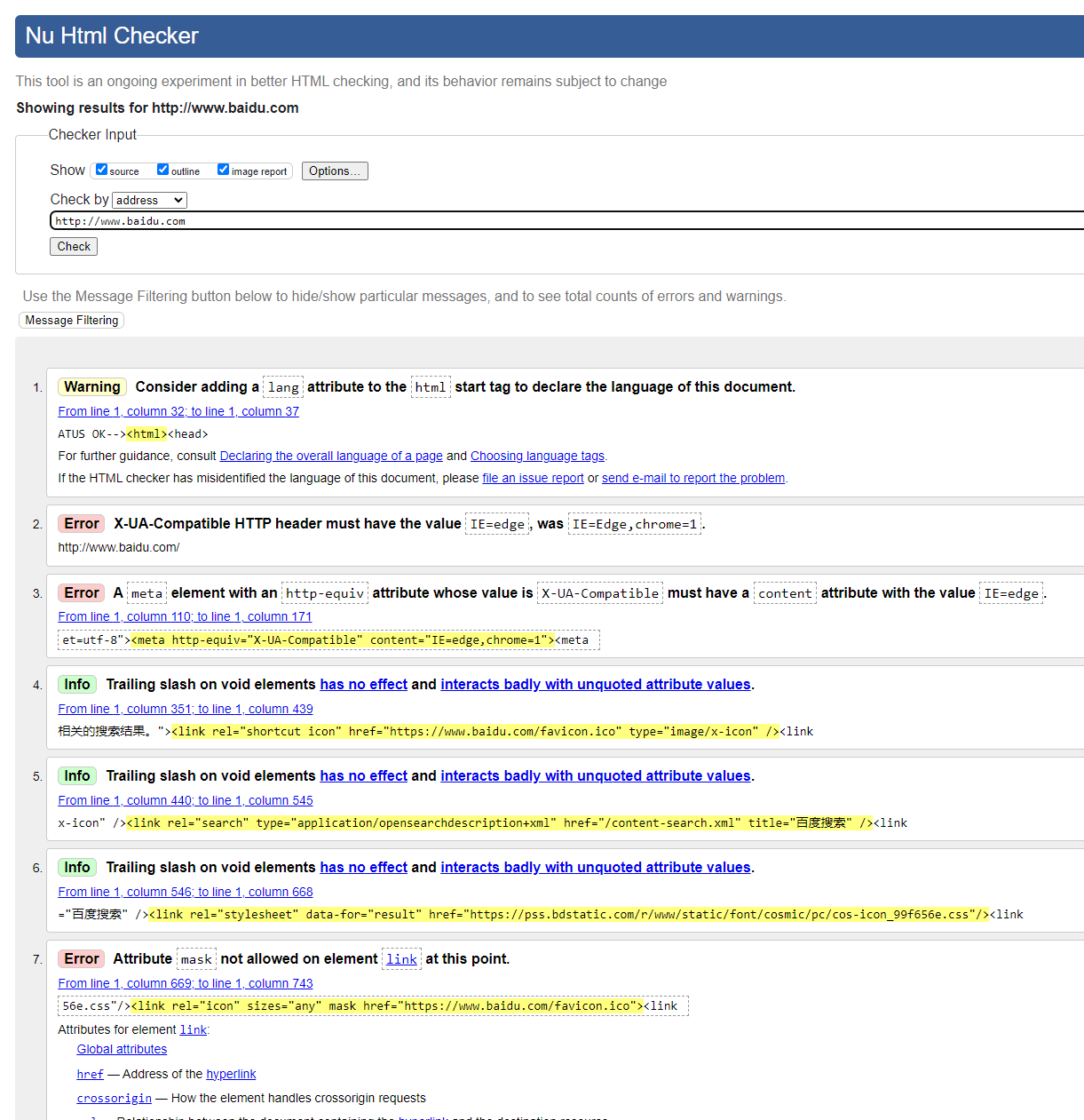
我们在编写 HTML 代码的时候,有时可能因为粗心大意,导致一些不规范或者错误的代码出现,但是又很难被我们发现,这个时候就可以借助工具来帮我们检查。Nu Html Checker 工具,在输入我们的网站地址后,就可以帮助我们检查分析 HTML 的错误,提升我们的错误排查效率和网站质量。
比如检测一下百度,可以看到检测出了非常多的问题,大家可以去试一下:
结束语
我们一起学习了 HTML 发展的历史,不得不感慨 HTML 的发展还是挺坎坷的,经历了各种变迁,幸好在 WHATWG 组织的推动下,最终还是做到了可持续发展。
也学习了 HTML 的一些设计原则,从中可以看到 HTML 的可扩展性还是很强的,这也是其能做到可持续发展的根本原因。
还一起学习了 HTML 的简单介绍,窥探了一些常见的安全问题,以及事件绑定时可能遇到的陷阱。
可以看到学习 HTML 的过程中,会牵扯到很多 JavaScript 的相关知识,毕竟他们要结合在一起才能发挥出全部的实力。还请各位看客老爷们稍安勿躁,在后续的系列篇中我会为大家详细介绍其中的具体细节,敬请期待啦。
欢迎关注我的公众号,前端创可贴。
