论文介绍
题目:Point2RBox: Combine Knowledge from Synthetic Visual Patterns for End-to-end Oriented Object Detection with Single Point Supervision
会议:2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
论文:http://arxiv.org/abs/2311.14758
代码:https://github.com/yuyi1005/point2rbox-mmrotate

创新点
-
基于合成图案的知识组合:通过在原始图像上叠加合成的视觉图案,来模拟具有明确尺寸和方向的目标,从而帮助模型学习如何从一个单独的点出发,推断出目标的具体形状、大小和方向。这个过程允许模型从非常有限的监督中学习框的回归。
-
基于变换的自监督:通过强制模型学习图像变换(翻转、旋转和缩放)后目标的一致性表征,提高模型对目标尺寸、位置和方向估计的准确性和鲁棒性。
-
端到端框架:Point2RBox是点监督的端到端解决方案,与先将点注释转换为水平框(HBox)或掩膜(Mask)然后再转换为RBox的两步方法形成对比。这种直接方法既创新又节省计算资源。

区别于现有的两种“Point-to-RBox”的方式:
-
Point-to-HBox-to-RBox
简单的结合P2B和H2RBOX两种算法,缺点是可能带来累积误差,即把P2B结果作为了真值。
-
Point-to-Mask-RBox
点生成掩膜,再得到RBox。缺点是比较耗时,且无法真正学习到目标的角度。
本文提出的方法是由点直接生成有向框,与上一篇文章来自同一研究团队: 论文赏读 |CVPR24 |单点直接生成旋转框用于遥感目标检测, PointOBB模型 两篇论文代码都已集成至mmrotate。
数据
DIOR-R数据集
DIOR-R是基于其先前版本DIOR的航拍图像数据集的OBB注释版本,包括23,463张图像,20个类别,以及190,288个实例。
https://gcheng-nwpu.github.io/
DOTA-v1.0数据集
基础信息:DOTA-v1.0是一个大规模的航拍图像数据集,用于遥感目标检测,包含2,806张图像、15个类别以及188,282个带有OBB和HBB注释的实例。
https://captain-whu.github.io/DOTA/dataset.html
HRSC数据集
基础信息:包含海上和近岸的船舶实例,具有任意方向。训练集、验证集和测试集分别包含 436、181 和 444 张图像。
https://www.scitepress.org/PublishedPapers/2017/61206/
方法
训练流程

用图像中每个目标对象的单一标记点来预测目标的旋转边界框(RBox)。这一方法通过合成模式知识组合和变换自监督两个关键策略实现。
1. 基于合成图案的知识组合(Synthetic Pattern Knowledge Combination)
基本流程
-
图案生成:在每个标记点周围生成合成图案。这些图案旨在模仿对象的形状和外观,但是以合成的方式构造,并具有已知的边界框。
使用了两套基础图案:
-
SetRC:包含具有曲线纹理的矩形和圆形,旨在增加多样性并帮助网络学习大小和角度估计。首先生成矩形或圆形,然后再叠加曲线纹理。
-
SetSK:包含每个类别的基本图案。每个类别使用一张样本作为基本图案,样本来自于训练数据集中的前面几张图像。研究从DOTA数据集中截取了15张图像作为基本图案。

-
-
颜色采样和重新着色:对于每个标记点,从其邻域采样颜色特征(包括填充颜色和边缘颜色)。这些颜色随后通过重新着色过程映射到基本图案上。
-
叠加到输入图像上:这些图案在经过数据增强(随机缩放翻转平移旋转)后被重新叠加回输入图像上(上面的图3)。在叠加时,为了避免图案之间的重叠,应用非极大值抑制NMS,确保图案之间的IOU小于0.05。为了避免合成图案完全遮挡真实目标,使用了透明混合技术。另外,随机选取的一些模式会通过平移操作生成一组紧密排列的模式集合,以模拟现实世界中目标可能紧密分布的情况。
-
训练中的使用:通过将这些带有已知边界框的合成图像叠加到原始图像上,模型被训练以识别和预测这些合成对象的尺寸和方向,从而间接学习到如何处理真实的、未标记尺寸的目标。
2. 变换自监督(Transform Self-supervision)
自监督策略:
-
对输入图像进行一系列的几何变换(如翻转、旋转、缩放),并让模型预测变换后图像中对象的RBox(其中缩放专门用来学习目标尺度)。
-
使用一个原始分支和一个变换分支(图2右侧上方为原始分支,右侧为变换后分支)。两个分支之间进行自我监督,相互监督。每次训练变换分支会随机从翻转、旋转、缩放中选择一个,这样训练时显存占用更小。
-
通过比较变换前后模型的预测结果,并确保这些预测在几何变换下是一致的,使模型学习到更加准确的目标定位和方向估计方法。
损失函数
-
点监督损失 (Loss from Point Supervision)
包含点的分类损失 (Lcls) 和目标中心损失 (Lcen)
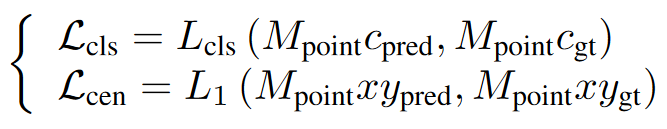
-
知识组合损失 (Loss from Knowledge Combination)
通过合成图案提供的知识来训练边界框回归的损失。

-
变换自监督损失 (Loss from Transform Self-supervision)

-
总体损失函数

标签分配
选用YOLOF-A1作为基座。YOLOF-A1是在原始的YOLOF模型基础上的一个变种,其中"A1"指的是该模型仅使用一种尺寸的锚点(Anchor)。保持Anchor的数量为5个,但尺寸相同。点标签被分配给那些能够生成最高类别评分的锚点。这一步是基于假设:能够给出高类别评分的锚点更有可能正确地预测出对象的位置。
精度
精度对比
DOTA数据集
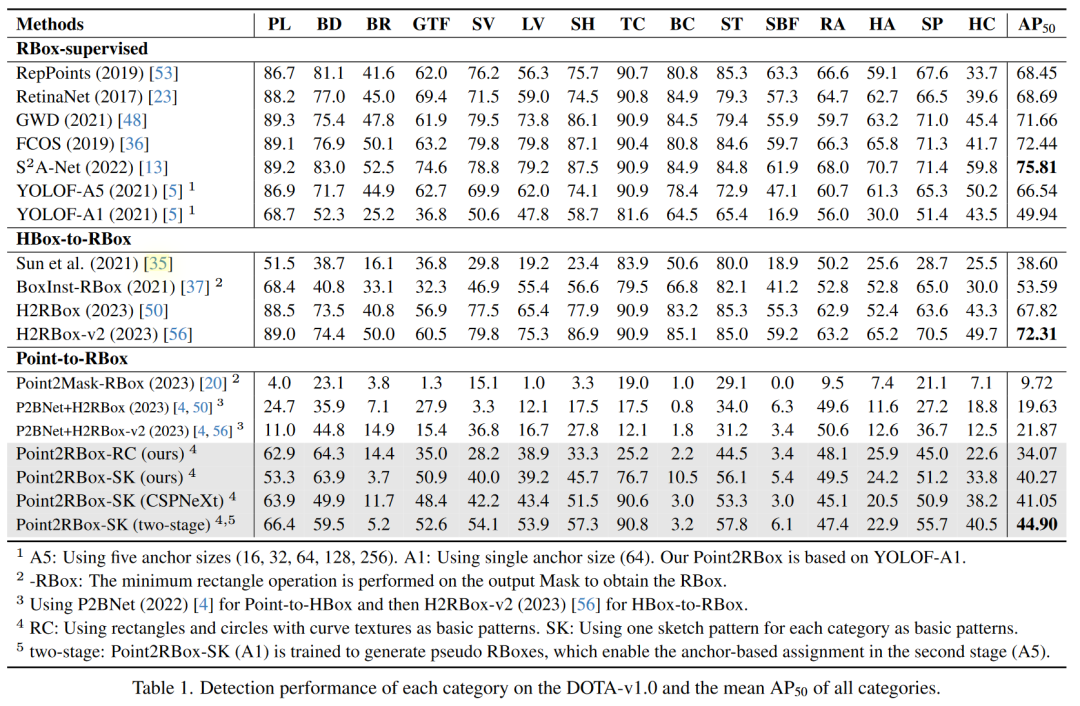
DIOR和HRSC数据集精度

可视结果

消融实验
基本图案设置
-
SetSK相比SetRC有更优的性能。

变换自监督设置
-
通过引入变换自监督损失(包括翻转、旋转和缩放),能够显著提升模型性能。

标注误差
-
即使在点注释存在一定噪声(即标注点的位置不完全准确)的情况下,文章方法也表现出了比较好的鲁棒性。特别是在一定范围内增加点注释的随机偏移,对性能影响不大,甚至在某些情况下能够提高性能。

锚点尺寸和数量的选择
-
即使所有锚点尺寸相同,使用多个锚点(而不是减少为一个)也可以提升性能。