在过去的两年里,计算机视觉领域涌现出了多种不同的多模态大模型(LVLM),如BLIP2, MiniGPT4等。这些大模型在多种不同的视觉任务上取得了亮眼的效果。为了准确评估多模态大模型的能力,许多研究人员从不同角度对模型进行了评测[1,2]。结果显示,LVLM在各种多模态任务中展示了卓越的能力。但是,这些评测工作大多只关注LVLM在通用视觉任务中的效果,它们在医学领域的潜力尚未被充分探索。这些多模态大模型能否较好地解决医学领域的问题,如何准确评估多模态大模型在医学领域的能力,仍然是一个未知的问题。
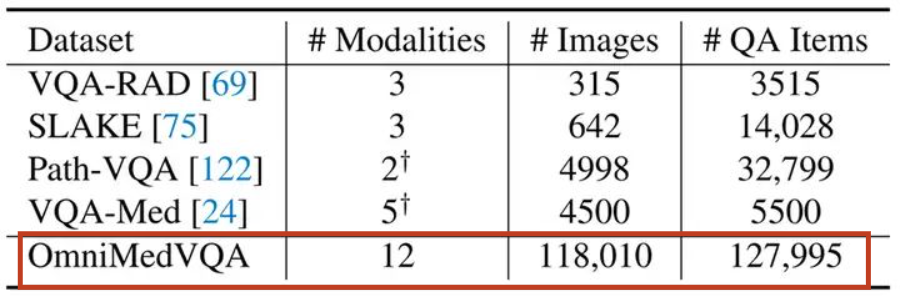
要准确评估多模态大模型在医学领域的效果,就需要构建全面的、涉及多种不同模态、覆盖人体多种不同位置的医学评测数据集。同时,对于多模态大模型而言,视觉问答能力(VQA)是其最基础且关键的能力之一。因此,要想准确评测医学大模型的能力,就需要一个全面的医学VQA数据集做支撑。但是,如图1所示。由于高质量医学数据的稀缺性,现有的医学VQA数据集不论是规模还是全面性都有所欠缺。因此,为了准确评估多模态大模型在医学领域的能力,构建一个大规模、全面的医学评测数据集十分重要。
Paper:
https://arxiv.org/pdf/2402.09181
代码与数据集下载):
https://github.com/OpenGVLab/Multi-Modality-Arena
数据集构建
由于高质量医学数据的稀缺性,加之普通标注员很难处理医学数据,因此,构建高质量的医学VQA数据集是一个十分有挑战性的任务。为了解决这个问题,我们从医学分类数据集入手,基于数据集中的类别属性和其他延伸知识,构建VQA问题。
比如,对于一个肺结核患者拍摄的胸腔X-Ray影像。我们可以设计如下QA模版对:
Q:该图像是通过什么模态采集得到的 A:X-Ray
Q:该图像显示了什么部位的信息 A:胸部
Q:该图像呈现出何种疾病 A:肺结核
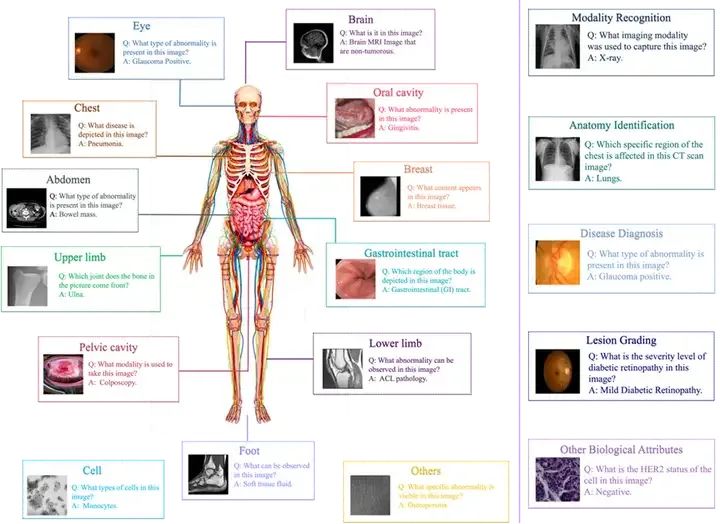
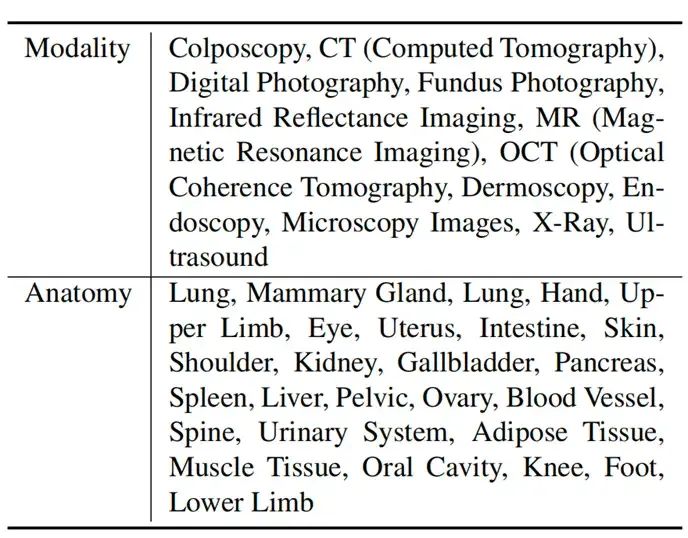
根据上述思路,我们以73个不同分类数据集为基础,拓展出了多种QA模版。我们基于这些QA对进行采样,得到了127995个不同的VQA条目。为了拓展OmniMedVQA数据集的多样性,我们通过GPT-4对QA模版进行复写。同时,为了便于评测,我们让GPT-4为每个条目配置错误答案,将其构造成选择题的形式。通过这种方式,在确保语义不变的前提下,使不同VQA条目的问答形式更多样。最终,我们的OmniMedVQA数据集包含118,010种不同图片,拥有12种不同模态,涉及超过20个人体不同的器官、部位。数据集概览如图2所示。图2右侧展示了OmniMedVQA的五种问题类型。图3反映了数据集包含的不同模态的影像和涉及的相关器官。
评测方法
为了准确评测多模态大模型在医学领域的能力,我们设计了两种评测指标:Question-answering score和Prefix-based score。它们各自的流程如图4所示。Question-answering score以选择题的形式进行评测。我们将问题和选项作为文本输入,让多模态大模型结合图像进行回答,进而根据模型的输出结果判断是否回答正确。
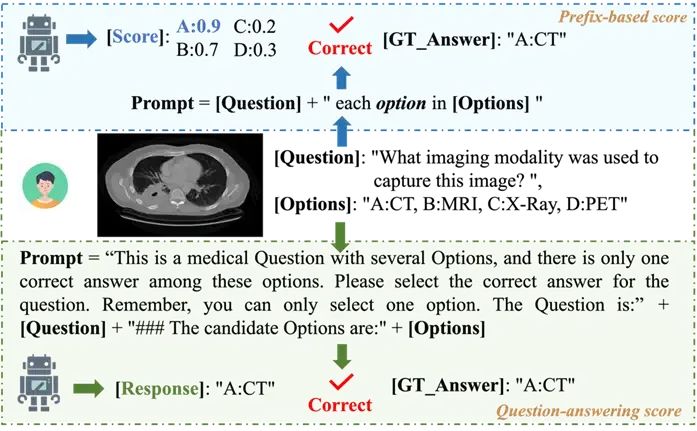
Prefix-based score则更关注模型内在的知识。具体来说,在多项选择问答任务中,给定输入图像和文本句子,我们首先分别提取视觉特征和question的文本特征。然后,将视觉特征与文本特征一起输入大语言模型,计算大语言模型输出各选项的可能性得分。这个得分被视为该图像-文本对的Prefix-based score,反映了模型生成相应文本内容的概率。对于每个测试条目中的所有选项,我们都通过此方式计算Prefix-based score。得分最高的选项意味着它是这个问题最可能的答案,我们将该选项与真实答案进行比较判断模型回答是否正确。
实验
我们利用OmniMedVQA数据集,测试了8个通用多模态大模型:BILP2, MiniGPT-4, InstructBLIP, mPLUGOwl, Otter, LLaVA, LLama adapter v2, 和VPGTrans。以及四个医学多模态模型:Med-Flamingo, RadFM, MedVInT 和 LLaVA-Med。实验结果如图5和图6所示,它们分别按5种不同任务类型和12种不同模态体现了各模型的评测结果。表格中“/”左侧和右侧的数值分别是Question-answering Score 和Prefix-based Score。
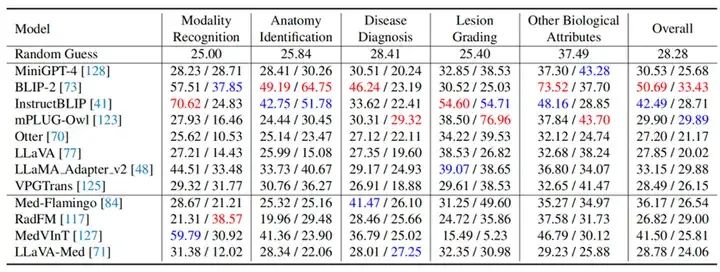
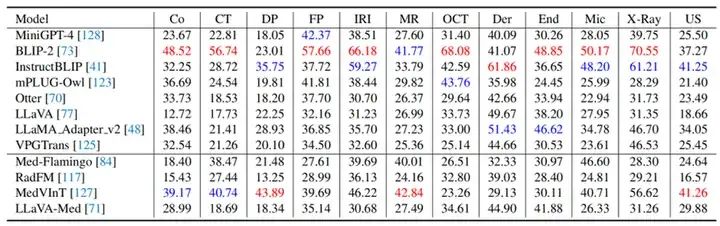
从实验结果我们可以得到如下结论:
-
让我们非常惊讶的是,在所有LVLM中,BLIP-2和InstructBLIP取得了最好的表现,远远超过许多医学LVLM。这说明现有医学LVLM并没有得到充分的训练,它们的表现还有很大的进步空间。
-
医学领域迫切需要一个强大的模型来对齐图像-文本对,从而产生更多高质量数据用于训练LVLM。BLIP在通用数据集和我们的OmniMedQA中都展现出了较好的表现,因为它是使用各种视觉领域的大量高质量图像-文本对进行训练的。因此,开发通用医学LVLM的关键在于使用来自不同医学领域的大量高质量“图像-文本”数据对模型进行训练。由于医学数据的稀缺性和标注难度,如果有一个强大的图像-文本对齐模型,可以更好地由医学影像生成文本描述,为医学领域带来更多高质量数据。
-
MedVInT和Med-Flamingo在所有医学LVLM中取得了最优的表现,并且还超过了除BLIP2和InstructBLIP之外的许多通用LVLM。这种成功可能是因为他们在训练中接受了大量专门的医学知识。Med-Flamingo学习了超过4000本医学教科书,而MedVInT基于381K图像-标题对生成的QA数据进行训练。这表明,为了获得更好的性能,应该向LVLM注入更多的医学领域知识。
-
从图6中我们可以发现,对于CT、MRI这种分布和自然图像有明显区别的影像,医学LVLM展现出了更好的表现。这是因为医学LVLM在训练中接触过更多CT、MRI数据,这些数据和自然图像有明显不同。因此,医学LVLM在这些数据上展现出了更好的表现。
结论
医疗是关系国计民生的大事,建立鲁棒的医学多模态大模型可以大大促进医疗人工智能的水平,带来重要的社会价值。但是,由于医疗安全的重要性,在现实医疗场景应用多模态大模型前,需要谨慎测评各模型的能力,确保鲁棒性和安全性。为此,我们建立了OmniMedVQA数据集,并对现有主流多模态大模型进行了全面评测。评测结果显示,现有主流多模态大模型面对很多医学问题仍然无法很好结果。同时,医学大模型的效果并没有明显优于通用大模型。为了训练更为鲁棒的医学LVLM,需要一个强大的图像-文本对齐模型提供更多高质量医学数据。同时,由于不同医学影像模态间的多样性和不同器官间的差异性,现阶段想直接建立一个通用的医学LVLM十分不易。因此,我们认为可以尝试从某一个器官的部分模态入手,建立一个针对某个科室或某几种疾病的专门化的医学LVLM。我们希望该数据集可以为未来医学多模态大模型的发展提供评测基准。
Paper:
https://arxiv.org/pdf/2402.09181
代码与数据集下载:
https://github.com/OpenGVLab/Multi-Modality-Arena
参考文献
[1] Wenqi Shao, Yutao Hu, Peng Gao, Meng Lei, Kaipeng Zhang, Fanqing Meng, Peng Xu, Siyuan Huang, Hongsheng Li, Yu Qiao, et al. Tiny lvlm-ehub: Early multimodal experiments with bard. arXiv preprint arXiv:2308.03729, 2023.
[2] Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Yu Qiao, and Ping Luo. Lvlm-ehub: A comprehensive evaluation benchmark for large vision-language models. arXiv preprint arXiv:2306.09265, 2023.