
论文:
开源链接:
https://github.com/OpenGVLab/DCNv4
在计算机视觉的研究征途上,我们团队一直在探索如何使卷积神经网络更加高效和强大。今年,我们在CVPR会议上发表了我们的研究成果——Deformable Convolution v4 (DCNv4),这是对我们之前工作的一次重大升级。总体而言DCNv4比之前的DCN算子推理速度更快,收敛速度更快,最终性能更优。
我们的研究动机
在深度学习的视觉任务中,卷积神经网络(ConvNets)的性能在很大程度上取决于其感受野的大小和形状。然而,传统的卷积操作是固定的,无法适应图像内容的变化。为了解决这一问题,可变形卷积(Deformable Convolution)通过引入额外的可学习偏移量来调整卷积核的形状,从而允许网络自适应地关注输入特征图的特定区域。虽然DCN算子在计算机视觉领域,尤其是目标检测和图像分割等感知任务上得到了广泛的应用,但是DCN算子受限于运行速度偏慢,并非是研究人员设计网络时的首要选择。与此同时,我们也观察到了DCN算子的收敛速度弱于Depth-wise Conv和注意力机制。针对这些问题,我们进行了细致的分析,并提出了相应的改进从而获得了更快,更强的DCNv4算子。
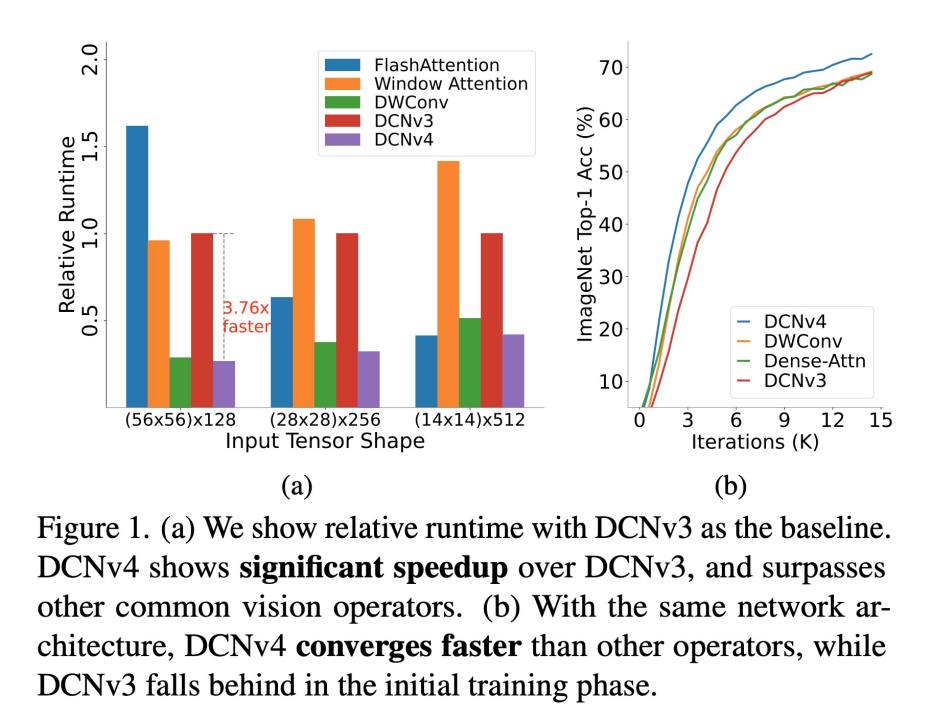
首先,我们对现有实现进行了指令级内核分析,发现DCNv3已经非常轻量级。计算成本不到1%,而内存访问成本占99%。这促使我们重新审视算子实现,并发现DCN前向过程中的许多内存访问是多余的,因此可以进行优化,从而使DCNv4的实现速度大大提高。其次,受到卷积无界权重范围的启发,我们发现在DCNv3中,密集注意力中的标准操作——空间聚合中的softmax标准化是不必要的,因为每个位置都有专门的聚合窗口,不是算子的必需条件。直观地说,softmax将权重限制在0到1的有界值范围内,这会限制聚合权重的表达能力。这一洞察使我们在DCNv4中移除了softmax,增强了其动态特性并提高了性能。结果,DCNv4不仅收敛速度显著快于DCNv3,而且前向速度提高了3倍以上。这一改进使DCNv4能够充分利用其稀疏特性,成为最快的通用核心视觉算子之一。如图1所示,我们最新提出的DCNv4算子相比之前版本在速度和收敛效率上都有显著改进。
DCNv4的核心创新
在DCNv4中,我们进行了两项关键改进:
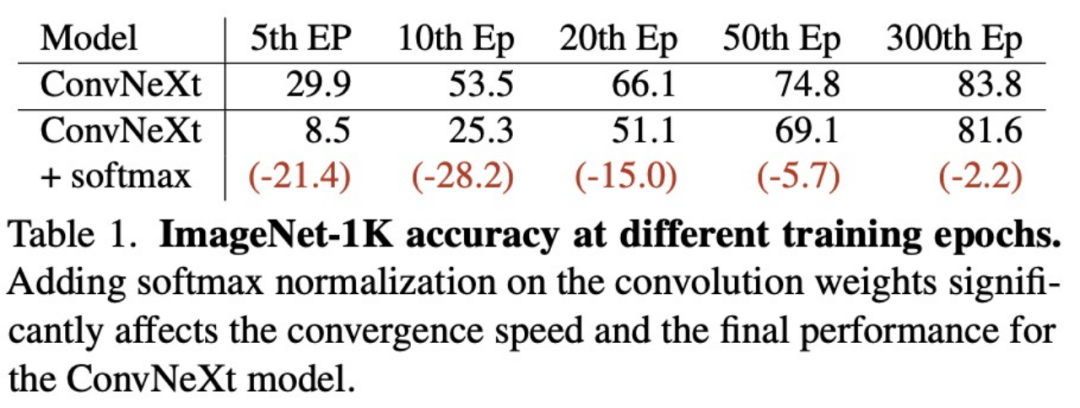
1.去除softmax归一化:在空间聚合中,我们去除了DCNv3中的softmax归一化,这样做不仅增强了网络的动态特性,还提升了其表达能力。我们发现,在没有标准注意力机制“key”概念的情况下,softmax归一化并不必要,反而可能限制了操作符的表达能力。为了验证我们的观点,我们在ConvNeXt上也进行了相应实验,如表1所示,为ConvNeXt添加softmax会显著制约其收敛速度和最终性能。如图2所示,我们提出的DCNv4算子具有自适应窗口,动态非约束权重等优势。
2.优化内存访问:通过对现有实现的指令级内核分析,我们发现内存访问占据了大部分的计算成本。因此,我们优化了内存访问模式,减少了冗余操作,显著提高了运行速度。如图3所示,我们通过优化访存操作,节约了两倍的访存开销,大幅增加了算子的效率。


DCNv4速度上的显著提升
理论上,作为具有3×3窗口的稀疏算子的DCN,应该比采用更大窗口尺寸的其他常见算子(如密集注意力或7×7深度卷积)更快。然而,如图1(a)所示,实际情况并非如此。我们首先进行了GPU效率的理论分析,发现内存访问成本根据读取内存的方式有很大的差异。我们进一步根据观察进行优化,通过节省额外的内存指令显著提高了DCN的速度,使稀疏算子的速度优势成为现实。
我们的研究从对DCNv3算子的计算行为进行理论考察开始。我们采用roofline model来评估其性能,重点关注理论上的浮点运算次数(FLOPs)和内存访问成本(MAC)。对于形状为(H, W, C)的输入和输出张量,DCNv3算子需要36HWC FLOPs,其中3×3代表卷积核的空间尺寸,4倍因子考虑了每个采样点的双线性插值。DCNv3的MAC计算为2HWC + 27HWG。第一项对应于输入/输出特征图的大小,第二项对应于DCNv3的偏移和聚合权重,G代表组数。我们假设组的尺寸为16,近似G为C/16,得到大约3.7HWC MAC。然而,这假设了一个理想的无限缓存场景和每个值单一的内存读取,这在并行计算环境中通常不现实,因为并发线程执行需要同时访问数据。为了估计最大的内存访问需求,我们考虑了一个无缓存的场景,每个输出位置需要新的内存读取,涉及36次双线性插值读取,27次偏移/聚合权重读取,以及一次写操作,导致MAC为64HWC。这是理想情况的17倍。
这一分析揭示了计算与内存访问之比的显著差距(从0.6到9.7不等),突出了内存访问优化的重大潜力。值得注意的是,尽管DCNv3使用了依赖输入的动态偏移导致非确定性内存访问,但一个确定的事情是同一组内的通道共享偏移值。这促使我们提出了一种特定的优化策略,以提高DCNv3的速度
在之前的CUDA实现中,对于具有形状(H, W, C)的输入,偏移(H, W, G, K2 × 2)和聚合权重(H, W, G, K2),我们将总共创建H×W×C个线程以最大化并行性,其中每个线程处理一个输出位置的一个通道。值得注意的是,每个组内的D = C/G通道在每个输出位置共享相同的采样偏移和聚合权重值。在同一输出位置使用多个线程处理这些D通道是浪费的,因为不同的线程将多次从GPU内存读取相同的采样偏移和聚合权重值,这对于一个以内存为瓶颈的算子来说是关键的。每个输出位置上使用一个线程处理同一组内的多个通道可以消除这些冗余的内存读取请求,从而大大减少内存带宽的使用。由于采样位置相同,我们也可以只计算一次在DCN中使用的双线性插值系数。具体来说,如果每个线程处理D'个通道,那么读取偏移和聚合权重的内存访问成本以及计算双线性插值系数的计算成本都可以减少D'倍。
在实践中,仅仅通过复用线程处理多个通道并不会看到速度的提升。原因是当D′增加时,我们创建的线程更少,而每个线程的工作负载增加了D′倍。这实际上降低了CUDA内核的并行度。幸运的是,DCN内核现在在计算上非常轻量级,因为双线性插值只需要为所有D′通道执行一次,而大部分工作负载是从不同通道读取输入值的内存指令。当内存布局是通道为末尾时,并且所有D′通道值是连续的,我们可以利用向量化加载:例如,要从内存中读取四个32位浮点值,不是使用四条指令四次读取一个32位浮点值,我们可以使用单一指令一次性加载一个128位打包值,从而减少指令数量和每个线程的执行时间。我们可以在将最终结果写入GPU内存时应用类似技术,以最小化内存访问时间并增加内存带宽利用率。此外,现代半精度数据格式(float16/bfloat16)将需要加载的字节减半,这意味着在使用半精度格式时,相同的内存带宽下内存效率可以提高一倍。然而,在原始的DCNv3实现中,我们没有看到半精度数据的速度提升,可能是由于数据访问和计算的过多开销,而在我们新的实现中,速度提升是显著的。值得注意的是,上述优化技术也可以应用于DCNv1/v2和变形注意力,因为它们有相似的性能瓶颈和问题。
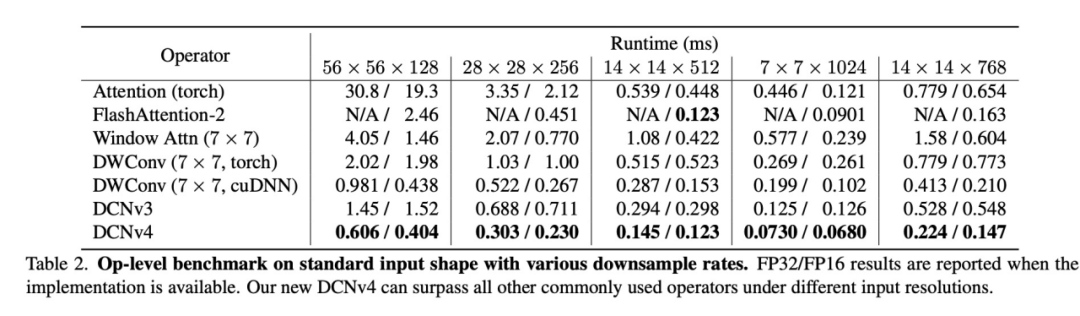
最终,如表2所示,DCNv4算子在实际运行速度上取得了最优三倍于DCNv3的效果。
下游任务性能的显著提升
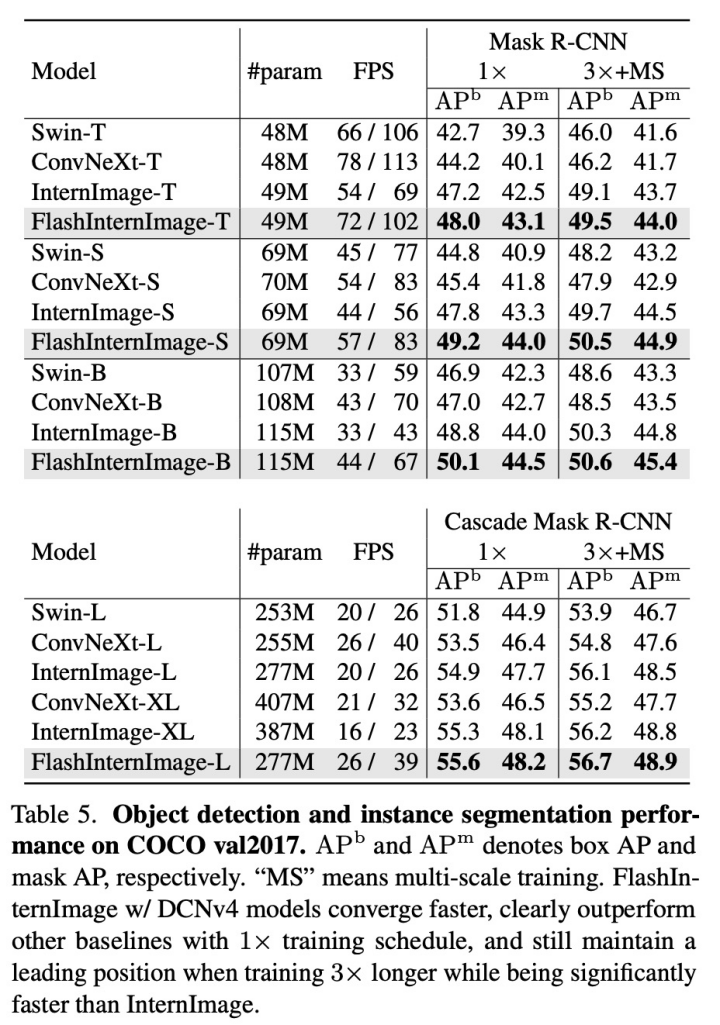
得益于以上改进,DCNv4在多个视觉任务上展现了卓越的性能。我们将DCNv4赋能InternImage得到新版本的Flash InternImage基础网络,该网络在图像分类、实例分割、语义分割等任务中,不仅收敛速度更快,而且最终性能也比InternImage表现更优。此外,当我们将DCNv4集成到生成模型中,如潜在扩散模型的U-Net,它在图像生成任务中也展现了出色的性能。与此同时Flash InternImage比InternImage具有50%-80%的速度提升。
为了广泛验证DCNv4算子的有效性,我们还在生成任务上进行了验证。DCN已被认为是感知任务中的一种有效算子。随着生成模型成为人工智能生成内容(AIGC)的基础工具,我们也对DCNv4在基于扩散的生成模型的生成任务中的表现感到好奇。具体来说,我们选择在Stable Diffusion中使用的U-Net [30]作为基线,并替换了U-Net中的注意力模块和常规的3×3卷积。我们使用U-ViT的代码库,遵循其训练计划,并基于Stable Diffusion提供的图像自动编码器提取的图像潜码训练了一个潜在扩散模型。我们在表9中展示了结果。可以看出,DCNv4在生成建模中也表现良好,与U-Net中常规卷积相比,在FID/吞吐量方面取得了更好的结果,且参数更少。需要注意的是,该架构/超参数可能不是DCNv4的最优选择,重新设计模型或为DCNv4寻找新的超参数可能会带来更好的结果。
