深入理解 Java 中的 Set 集合及其实现:HashSet 和 LinkedHashSet
在 Java 中,Set 是一个非常常用的数据结构,它的核心特点是不允许存储重复元素。Set 集合广泛用于需要保证元素唯一性的场景中,例如需要对数据去重或者进行集合运算。本文将深入探讨 Java 中 Set 接口的特点及其几种常用实现类:HashSet 和 LinkedHashSet,并通过代码实例来展示它们的应用。
1. Set 集合的概述与特点
Set 集合的特点
- 不允许存储重复元素:Set 集合中的每个元素必须是唯一的,这也是 Set 最重要的特性之一。Set 通过各种机制(如哈希值)来实现这一点。
- 无序存储:Set 集合中的元素没有特定的顺序,这意味着添加到 Set 中的元素的存储顺序可能与遍历时的顺序不同。
- 没有索引:Set 集合不像 List 集合一样提供基于索引的访问方式,因此无法使用普通的
for循环通过索引遍历。
Set 集合的使用示例
以下代码展示了 Set 集合如何存储字符串并进行遍历:
import java.util.Set;
import java.util.TreeSet;
import java.util.Iterator;
public class MySet1 {
public static void main(String[] args) {
// 创建集合对象
Set<String> set = new TreeSet<>();
// 添加元素
set.add("ccc");
set.add("aaa");
set.add("aaa"); // 重复元素将不会被添加
set.add("bbb");
// 遍历集合 (使用 Iterator 迭代器)
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
System.out.println("-----------------------------------");
// 使用增强 for 循环遍历集合
for (String s : set) {
System.out.println(s);
}
}
}
运行结果
aaa
bbb
ccc
-----------------------------------
aaa
bbb
ccc
在上述代码中,TreeSet 集合不允许存储重复的元素,并且元素以自然顺序(即字典顺序)进行排序。
2. HashSet 集合的概述与特点
HashSet 是 Set 接口的一个具体实现,它使用**哈希表(Hash Table)**来存储数据,因此它的性能通常较好,尤其在插入和查找元素方面。HashSet 的一些特点如下:
HashSet 集合的特点
- 底层数据结构是哈希表:
HashSet使用哈希表来存储元素,因此对元素的插入、删除和查找操作的时间复杂度都是 O(1)。 - 存储无序:
HashSet集合中的元素是无序的,即添加到集合中的元素在存储后不会按照插入顺序保存。 - 不允许存储重复元素:
HashSet使用哈希值来判断元素的唯一性,因此不允许存储重复的元素。 - 没有索引:与其他
Set一样,HashSet集合中没有索引,无法通过索引来访问元素。
HashSet 集合的基本应用
以下代码展示了如何使用 HashSet 集合存储和遍历字符串元素:
import java.util.HashSet;
public class HashSetDemo {
public static void main(String[] args) {
// 创建集合对象
HashSet<String> set = new HashSet<String>();
// 添加元素
set.add("hello");
set.add("world");
set.add("java");
// 重复元素将不会被添加
set.add("world");
// 遍历集合
for(String s : set) {
System.out.println(s);
}
}
}
运行结果
java
world
hello
在 HashSet 中,添加的元素是无序的,且重复元素不会被存储。
3. 哈希值与哈希表结构
什么是哈希值?
- 哈希值是通过哈希函数计算出来的一个
int类型的值,用于标识对象的唯一性。 - 在 Java 中,
Object类提供了public int hashCode()方法来获取对象的哈希码值。 - 哈希值的特点:
- 同一个对象多次调用
hashCode()方法返回的值相同。 - 默认情况下,不同对象的哈希值不同。但通过重写
hashCode()方法,可以实现不同对象具有相同的哈希值。
- 同一个对象多次调用
哈希表结构
HashSet 底层基于哈希表,其存储方式在 JDK1.8 之前与之后有所不同:
-
JDK1.8 之前:
- 哈希表的底层结构是数组 + 链表,即当哈希冲突(两个对象计算得到相同的哈希值)时,会将这些对象存储在同一个链表中。
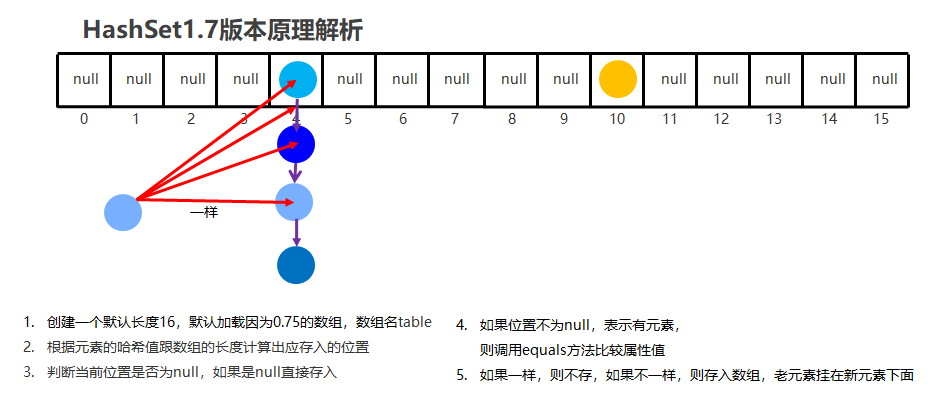
-
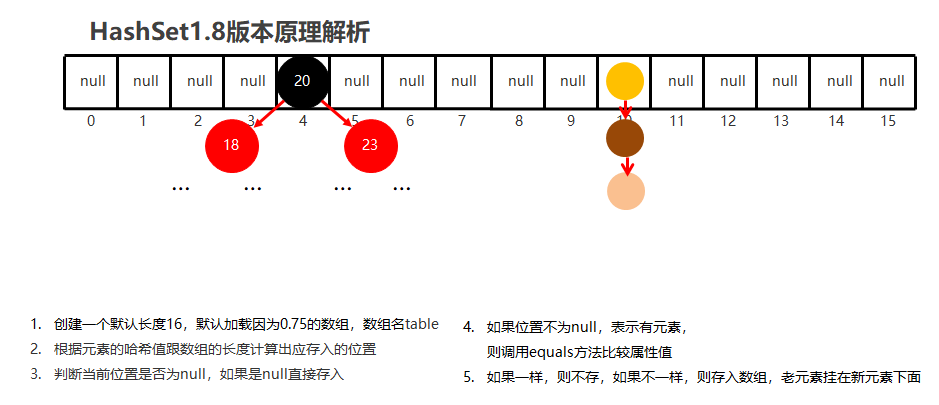
JDK1.8 之后:
- 当链表中的节点个数超过一定数量(默认为 8)时,链表会转化为红黑树,以提高查找效率。
- 节点个数少于等于 8 个时,使用数组 + 链表。
- 节点个数大于 8 个时,使用数组 + 红黑树。
HashSet 集合存储自定义对象并遍历
以下示例展示了如何使用 HashSet 存储自定义类型的对象,并确保对象的唯一性:
-
案例需求:
- 创建一个存储学生对象的集合,存储多个学生对象,并遍历该集合。
- 如果学生对象的成员变量值相同,则认为它们是相同的对象。
-
代码实现:
学生类(重写 equals() 和 hashCode() 方法):
public class Student {
private String name;
private int age;
// 构造方法
public Student(String name, int age) {
this.name = name;
this.age = age;
}
// Getter 和 Setter 方法省略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && (name != null ? name.equals(student.name) : student.name == null);
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
测试类:
import java.util.HashSet;
public class HashSetDemo02 {
public static void main(String[] args) {
// 创建 HashSet 集合对象
HashSet<Student> hs = new HashSet<Student>();
// 创建学生对象
Student s1 = new Student("林青霞", 30);
Student s2 = new Student("张曼玉", 35);
Student s3 = new Student("王祖贤", 33);
Student s4 = new Student("王祖贤", 33); // 重复对象
// 把学生添加到集合
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
// 遍历集合 (增强 for)
for (Student s : hs) {
System.out.println(s.getName() + "," + s.getAge());
}
}
}
运行结果:
林青霞,30
张曼玉,35
王祖贤,33
通过重写 hashCode() 和 equals() 方法,HashSet 确保了 Student 对象的唯一性。
4. LinkedHashSet 集合
LinkedHashSet 是 HashSet 的一个子类,它具有以下特点:
- 有序存储:
LinkedHashSet维护了一个链表,用于记录元素的插入顺序,因此遍历集合时可以按插入顺序访问元素。 - 不允许存储重复元素:和
HashSet一样,LinkedHashSet也使用哈希表来保证元素的唯一性。
LinkedHashSet 集合的使用示例
以下是 LinkedHashSet 集合的基本使用示例:
import java.util.LinkedHashSet;
public class LinkedHashSetDemo {
public static void main(String[] args) {
// 创建 LinkedHashSet 集合对象
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
// 添加元素
linkedHashSet.add("apple");
linkedHashSet.add("banana");
linkedHashSet.add("orange");
linkedHashSet.add("banana"); // 重复元素,不会被添加
// 遍历集合
for (String s : linkedHashSet) {
System.out.println(s);
}
}
}
运行结果
apple
banana
orange
在上述代码中,LinkedHashSet 集合保持了元素的插入顺序,因此在遍历时可以看到插入顺序的结果:apple, banana, orange。与 HashSet 不同,LinkedHashSet 不仅保证元素的唯一性,还确保了元素的有序性。
5. Set 集合各实现类的对比
为了更好地理解 Set 集合的不同实现类(HashSet、LinkedHashSet 和 TreeSet),下表总结了它们的主要特性和区别:
| 实现类 | 底层数据结构 | 是否有序 | 是否允许重复 | 线程安全性 | 性能复杂度 (查找、插入、删除) |
|---|---|---|---|---|---|
HashSet |
哈希表 | 否 | 否 | 否 | O(1)(平均情况下) |
LinkedHashSet |
哈希表 + 双向链表 | 是 | 否 | 否 | O(1)(平均情况下) |
TreeSet |
红黑树 | 是(排序) | 否 | 否 | O(log n) |
- HashSet:不保证存储顺序,适合用于快速去重以及元素的查找,增删效率高。
- LinkedHashSet:保持元素的插入顺序,适合用于既需要保证元素唯一性,又需要按插入顺序访问的场景。
- TreeSet:自动对元素进行排序,适合需要对元素保持自然顺序或自定义顺序的场景。
6. HashSet 和 LinkedHashSet 的实际应用场景
-
HashSet 的应用场景:
- 数据去重:
HashSet可用于从集合中删除重复元素,例如从用户输入中提取唯一的关键字。 - 无序集合管理:在需要快速检查元素是否存在于集合中而不关心顺序时,
HashSet是非常合适的选择。
- 数据去重:
-
LinkedHashSet 的应用场景:
- 顺序相关的去重集合:
LinkedHashSet保留插入顺序,例如用于记录用户访问过的页面 URL,保证访问的顺序不变。 - 缓存系统的实现:
LinkedHashSet可以用于实现 LRU(Least Recently Used)缓存,当数据被插入时按顺序排列,最早插入的数据最先被删除。
- 顺序相关的去重集合:
7. HashSet 存储自定义对象的注意事项
在使用 HashSet 存储自定义对象时,为了保证对象的唯一性,必须重写 equals() 和 hashCode() 方法。重写 equals() 方法可以保证对比逻辑符合业务需求,而重写 hashCode() 方法可以确保相同内容的对象具有相同的哈希值。
在 Student 类的实现中,我们重写了 equals() 和 hashCode() 方法来保证集合中不会有重复的学生对象:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && (name != null ? name.equals(student.name) : student.name == null);
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
equals()方法:判断两个Student对象是否相同的逻辑是:如果name和age属性的值都相同,则认为两个对象是相同的。hashCode()方法:根据name和age的属性值生成一个哈希值,使得内容相同的对象具有相同的哈希值。
8. Set 集合使用的最佳实践
- 选择合适的实现类:在不同的应用场景下,选择合适的
Set实现类可以提高程序的效率。例如,如果不需要顺序,HashSet是最佳选择;如果需要保持插入顺序,LinkedHashSet是更好的选择。 - 重写
equals()和hashCode()方法:在存储自定义对象时,确保重写equals()和hashCode()方法,以正确判断对象的唯一性。 - 避免线程安全问题:
HashSet和LinkedHashSet都不是线程安全的,如果在多线程环境中使用,应考虑通过Collections.synchronizedSet()方法来实现线程安全,或者使用ConcurrentHashMap之类的线程安全集合。
结语
在 Java 中,Set 集合为管理唯一元素提供了一种简单而有效的方式。HashSet 和 LinkedHashSet 作为 Set 的主要实现类,分别通过哈希表和链表结构,为数据去重、集合操作和有序存储提供了不同的解决方案。
- HashSet 以其无序存储和高效的增删查操作,适用于需要快速查找、添加而不关心顺序的场景。
- LinkedHashSet 在保证数据唯一性的同时维护元素的插入顺序,适用于需要保留元素顺序的应用场景。
synchronizedSet()方法来实现线程安全,或者使用ConcurrentHashMap` 之类的线程安全集合。
结语
在 Java 中,Set 集合为管理唯一元素提供了一种简单而有效的方式。HashSet 和 LinkedHashSet 作为 Set 的主要实现类,分别通过哈希表和链表结构,为数据去重、集合操作和有序存储提供了不同的解决方案。
- HashSet 以其无序存储和高效的增删查操作,适用于需要快速查找、添加而不关心顺序的场景。
- LinkedHashSet 在保证数据唯一性的同时维护元素的插入顺序,适用于需要保留元素顺序的应用场景。