本系列文章主要是分享一些关于大模型的一些学术研究或者实验性质的探索,为大家更新一些针对大模型的认知。所有的结论我都会附上对应的参考文献,有理有据,也希望这些内容可以对大家使用大模型的过程有一些启发。
注:本系列研究关注的是大型语言模型(Large Language Models, LLMs)的普遍特性,而非专指GPT。在文中,我们使用“GPT”作为一个典型例子来代表这一类模型,但请读者注意,所讨论的观点和结论通常也适用于其他同类大型模型。这样的表述旨在简化叙述,同时也强调了这些发现的广泛适用性。
不定期更新,敬请期待~
Chain-of-Thought(CoT, 思维链)其实是一种日用而不知的技巧。
首先看一个例子,还是上一篇的例子举例:
我还是这么提问:
古诗中,“白云千载空悠悠”的上一句是什么?

此时再一次生成了一个非常不靠谱的回答。
什么是“思维链提示方法”呢?
没有思维链提示方法的时候,对于上面这个问题,就只能听天由命,等待大语言模型每一次运行产生的一个随机结果中可能有一个是正确的…

那么,使用思维链提示词的方法怎么得到答案呢?你要这么一步步引导GPT得到正确答案。
现在,额外告诉GPT一个信息,看一下GPT能否猜出来。

看来范围可能还是太大,起不到引导的作用。现在我再给出一些提示,我把这首诗的作者给GPT。

标题猜对了!但是答案仍然是错了。此时几乎已经看到了希望,因为你如果让GPT根据标题《黄鹤楼》背诵全文,这是一个正向的提问,那么不存在什么「逆转诅咒」,那么也就大概率可以得到正确结果了。
那么这一次的提问方式变成了:

最终回答正确!
这个过程的展示可以见下面这个视频。
以上就是思维链提示法的工作原理。
对应的论文如下:
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
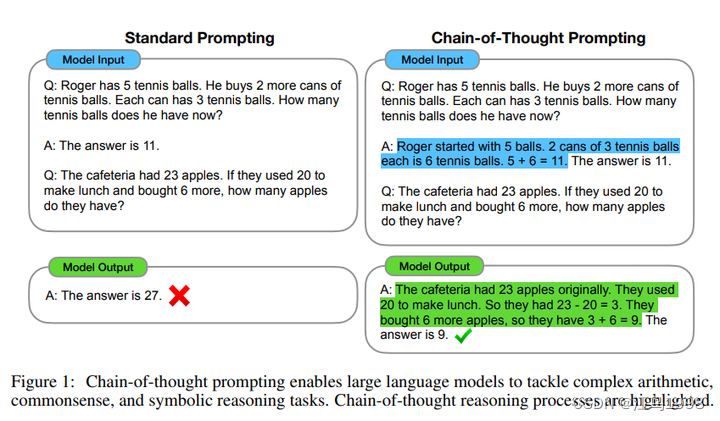
思维链最常用的,包括论文里面指出的,就是通过向大语言模型展示一些少量的例子,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
所有引导式的提问,鼓励模型自己做出推理的提示方法,都是CoT(思维链)。