《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言

在我看来,最简单机器学习模型之一是k-Means聚类。它与无监督学习算法相关,能够在未标记的数据集中找到共同点。最大的特点是它不需要复杂的数学,基本上任何高中生都可以成功地实现和使用这种方法。在这篇文章中,将分享如何使用numpy和pandas库在python中从头开始构建k-Means算法,并将其应用于一个真实的世界问题-卫星图像的语义分割。
数据
本文将介绍如何使用ML语义分割来估计2000年到2023年之间咸海水面的变化?答案是K-Means!
在深入编码之前,让我们先看看本教程中要使用的数据。这是同一地区的两张RGB图像,间隔为23年,但很明显,地表特性和大气条件(云,气溶胶等)是不同的.这就是为什么我决定训练两个单独的k-Means模型,每个图像一个。

首先,让我们导入必要的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('MOD_01.jpg')
img2 = mpimg.imread('MOD_24.jpg')
你可以看到图像覆盖的区域相当大,我们截取水面的核心区域:
img = img[140:600,110:500,:]
img2 = img2[140:600,110:500,:]
fig, ax = plt.subplots(ncols=2, figsize=(16,9))
ax[0].imshow(img)
ax[1].imshow(img2)
for i in range(2):
ax[i].set_facecolor('black')
ax[i].set_xticks([])
ax[i].set_yticks([])
ax[0].set_title('2000-08-01', fontsize=26)
ax[1].set_title('2023-08-01', fontsize=26)
plt.show()

ML阶段之前的最后一步,让我们将图像转换为pandas数据框(每个图像通道一列)。我这样做是为了让我的解释可见。如果你想优化它,最好使用numpy数组。
df = pd.DataFrame({
'R': img[:,:, 0].flatten(), 'G': img[:,:, 1].flatten(), 'B':img[:,:, 2].flatten()})
df2 = pd.DataFrame({
'R': img2[:,:, 0].flatten(), 'G': img2[:,:, 1].flatten(), 'B':img2[:,:, 2].flatten()})
k-Means简介
那么k-Means算法背后的思想是什么呢?
想象一下,你用两个标准来判断食物的味道:甜度和价格。记住这一点,我会给你一组可能的选择吃:

我们可以把这些选择分成了三类:水果、饮料和面包。

在k-Means的情况下,算法的目标非常相似-在n维空间中找到预设的聚类数k(例如,除了类别之外,您还需要考虑营养,健康,冰箱中的食物,在这种情况下,n = 5)。
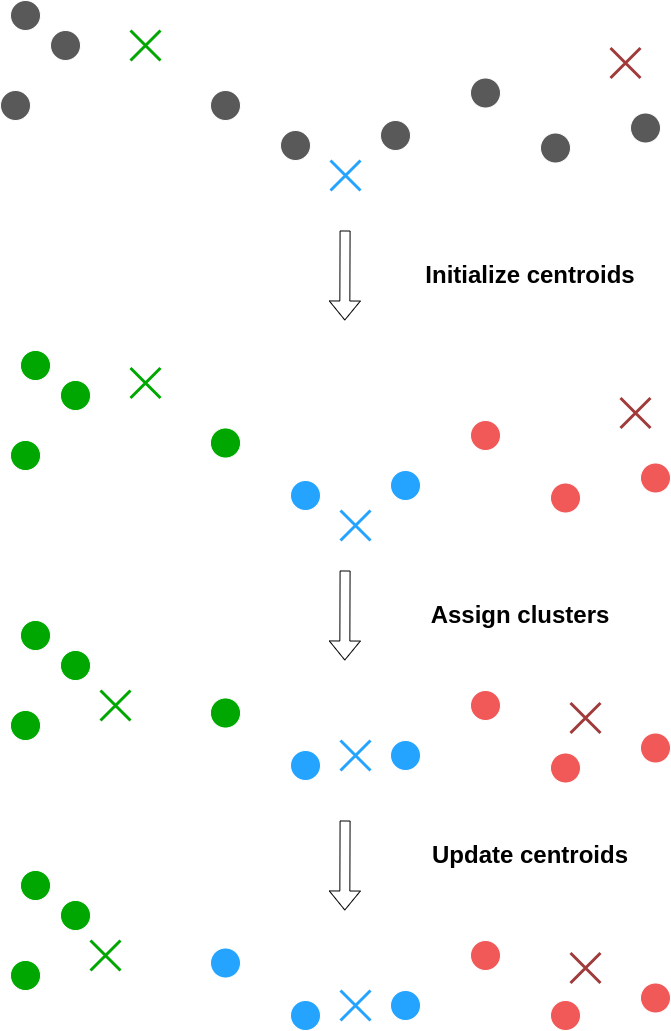
算法步骤
一.定义集群的数量
正如我之前提到的,k-Means中的k是你最终想要得到的聚类数,你应该在训练模型之前设置这个值。
二.随机初始化质心
质心是k-Means的组成部分。基本上,质心是一个圆心的圆,圆心由一组坐标定义,每个质心代表一个聚类。例如,在我们前面的例子中,有三个质心。
三.计算距离并分配聚类。
现在我们需要找出每个点到每个质心的距离。基于此计算,我们将每个点分配到最远的质心(聚类)。
四.计算新的质心。
现在,我们的每个聚类都至少包含一个点,所以现在是时候通过获取所有聚类点的平均坐标来重新计算质心了。
就是这样!我们重复步骤2-4,直到质心不变。
编码代码
现在让我们将k-Means背后的这个非常简单的想法通过python代码实现。
提醒:在这个任务中,我们有3D问题,即我们的X,Y和Z是红色,绿色和蓝色图像通道!
def kmeans(data, K, kind):
L = list()
new_centroids = data.sample(K).values
data = distance(data.copy(), new_centroids, kind)
old_centroids = new_centroids.copy()
new_centroids = np.array([data[data.Class == Class][['R', 'G', 'B']].mean().values for Class in data.loc[:,'C1':f'C{
K}'].columns])
i = 1
print(f'Iteration: {
i}\tDistance: {
abs(new_centroids.mean()-old_centroids.mean())}')
while abs(new_centroids.mean()-old_centroids.mean())>0.001:
L.append(abs(new_centroids.mean()-old_centroids.mean()))
data = distance(data, new_centroids, kind)
old_centroids = new_centroids.copy()
new_centroids = np.array([data[data.Class == Class][['R', 'G', 'B']].mean().values for Class in data.loc[:,'C1':f'C{
K}'].columns])
i+=1
print(f'Iteration: {
i}\tDistance: {
abs(new_centroids.mean()-old_centroids.mean())}')
print(f"k-Means has ended with {
i} iteratinons")
return data, L
在第一阶段,我们创建一个列表L来收集聚类之间的所有距离,然后将它们可视化,并从数据集中随机采样K个点,使它们成为我们的质心(或者,您可以为质心分配随机值)。
L = list()
new_centroids = data.sample(K).values
现在我们需要计算质心和数据点之间的距离。在数据科学中有很多不同的距离度量,但让我们关注以下几个-欧几里得,曼哈顿,切比雪夫。
对于欧几里得距离:
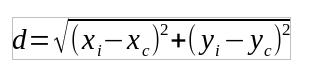
对于曼哈顿距离:

对于切比雪夫距离:

为了使用这个公式,让我们为任意维数编写一个通用函数:
def distance(data, centroids, kind):
#kind = euclidean, manhattan, chebyshev
#Here we add to the dataframe as many clusters C-ith as needed
cols=list()
for i in range(1,k+1):
if kind=='euclidean':
data[f'C{
i}'] = ((centroids[i-1][0]-data.R)**2+(centroids[i-1][1]-data.G)**2+(centroids[i-1][2]-data.B)**2)**0.5
elif kind=='manhattan':
data[f'C{
i}'] = abs(centroids[i-1][0]-data.R)+abs(centroids[i-1][1]-data.G)+abs(centroids[i-1][2]-data.B)
elif kind=='chebyshev':
merged=pd.concat([centroids[i-1][0]-data.R, centroids[i-1][1]-data.G, centroids[i-1][2]-data.B], axis=1)
data[f'C{
i}'] = merged.max(axis=1)
cols.append(f'C{
i}')
data['Class'] = data[cols].abs().idxmin(axis=1) #assigning clusters to points
return data #returning the dataframe with k cluster columns and one Class column with the final cluster
所以现在我们可以简单地计算距离并为每个数据点分配一个聚类。因此,我们的新质心变成了旧的,所以我们将它们存储在另一个变量中并重新计算新的。为了做到这一点,我们对每个聚类进行了遍历,并在所有坐标上取平均值(在我们的例子中,在RGB通道上)。因此,变量new_centroids具有**(k,3)**的形状。
data = distance(data.copy(), new_centroids, kind)
old_centroids = new_centroids.copy()
new_centroids = np.array([data[data.Class == Class][['R', 'G', 'B']].mean().values for Class in data.loc[:,'C1':f'C{
K}'].columns])
最后,我们重复所有这些步骤,直到质心的坐标不再改变。我将这个条件表示为:平均聚类坐标之间的差异应该小于0.001。但您可以在这里玩其他数字。
while abs(new_centroids.mean()-old_centroids.mean())>0.001:
L.append(abs(new_centroids.mean()-old_centroids.mean()))
data = distance(data, new_centroids, kind)
old_centroids = new_centroids.copy()
new_centroids = np.array([data[data.Class == Class][['R', 'G', 'B']].mean().values for Class in data.loc[:,'C1':f'C{
K}'].columns])
就这样。算法可以训练了!所以让我们设置k = 3并将结果存储到字典中。
k = 3
segmented_1, segmented_2, distances_1, distances_2 = {
}, {
}, {
}, {
}
segmented_1['euclidean'], distances_1['euclidean'] = kmeans(df, k, 'euclidean')
segmented_2['euclidean'], distances_2['euclidean'] = kmeans(df2, k, 'euclidean')
segmented_1['manhattan'], distances_1['manhattan'] = kmeans(df, k, 'manhattan')
segmented_2['manhattan'], distances_2['manhattan'] = kmeans(df2, k, 'manhattan')
segmented_1['chebyshev'], distances_1['chebyshev'] = kmeans(df, k, 'chebyshev')
segmented_2['chebyshev'], distances_2['chebyshev'] = kmeans(df2, k, 'chebyshev')
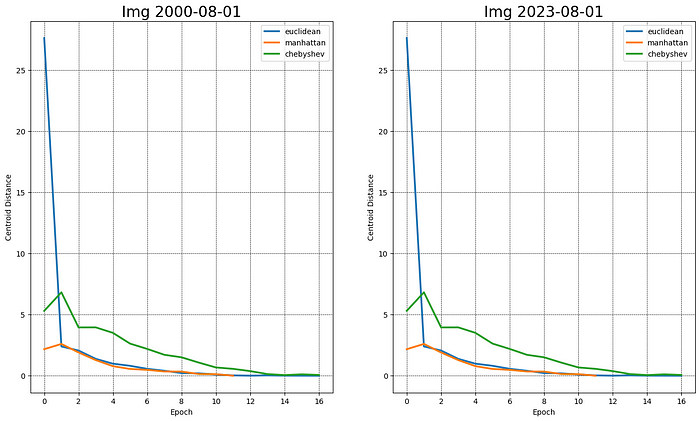
我决定比较一下这个任务的所有距离指标,正如你所看到的,很明显,这里的曼哈顿距离是最快的。
在可视化集群之前,让我们将集群名称转换为int类型:
d = {
'C1':0, 'C2': 1, 'C3':2}
for key in segmented_1.keys():
segmented_1[key].Class = segmented_1[key].Class.apply(lambda x: d[x])
segmented_2[key].Class = segmented_2[key].Class.apply(lambda x: d[x])
for key in segmented_1.keys():
fig, ax = plt.subplots(ncols=2, nrows=2, figsize=(10,10))
ax[0, 0].imshow(img)
ax[0, 1].imshow(segmented_1[key].Class.values.reshape(460,390))
ax[0, 0].set_title('MOD09GA RGB', fontsize=18)
ax[0, 1].set_title(f'kMeans\n{
key[0].upper()+key[1:]} Distance', fontsize=18)
ax[1, 0].imshow(img2)
ax[1, 1].imshow(segmented_2[key].Class.values.reshape(460,390))
ax[1, 0].set_title('MOD09GA RGB', fontsize=18)
ax[1, 1].set_title(f'kMeans\n{
key[0].upper()+key[1:]} Distance', fontsize=18)
for i in range(2):
for j in range(2):
ax[i, j].set_facecolor('black')
ax[i, j].set_xticks([])
ax[i, j].set_yticks([])
plt.savefig(f'{
key}.png')
plt.tight_layout()
plt.show()
欧几里得距离聚类后的分割结果:

曼哈顿距离聚类后的分割结果:

切比雪夫距离聚类后的分割结果:

不难看出,欧几里得距离和曼哈顿距离最适合这个特定的任务。但为了确保这是真的,让我们使用Silhouette Coefficient来评估k-Means聚类结果。当聚类点没有标记的真值时,该指标非常适合训练结果评估。
为了计算它,我们将使用sklearn函数。

- **a -**样本与同一类中所有其他点之间的平均距离。
- **B -**样本与下一个最近聚类中所有其他点之间的平均距离。
轮廓系数的值范围为[-1,1]。是的,它的计算成本很高,因为你需要多次计算数千个点之间的距离,所以要做好等待的准备。
scores_1, scores_2 = {
}, {
}
for key in segmented_1.keys(): #key is a metric for the distance estimation
scores_1[key]=round(silhouette_score(segmented_1[key].loc[:, :'C3'], segmented_1[key].Class, metric=key),2)
scores_2[key]=round(silhouette_score(segmented_2[key].loc[:, :'C3'], segmented_2[key].Class, metric=key),2)
print(f'Distance: {
key}\t Img 1: {
scores_1[key]}\t Img 2: {
scores_2[key]}')

现在你可以看到我们已经证明了这一点:欧几里得距离和曼哈顿距离具有类似的良好性能,所以让我们使用这两种距离来估计水面面积损失。
for metric, Class in zip(['euclidean', 'manhattan'], [2,1]):
img1_water = np.count_nonzero(segmented_1[metric].Class.values == Class)*500*500*1e-6 #pixel size is 500, so the area is 500*500 and to convert to km2 * 1e-6
img2_water = np.count_nonzero(segmented_2[metric].Class.values == Class)*500*500*1e-6
print(f'Distance: {
metric}\tWater Area Before: {
round(img1_water)}km\u00b2\tWater Area After: {
round(img2_water)}km\u00b2\tChange: -{
100-round(img2_water/img1_water*100)}%')

- - - -
距离:欧几里得
前水域面积:17125平方公里
水域面积后:1960平方公里
变化:-89%
- - - - -
距离:曼哈顿
前水域面积:16244平方公里
水域面积后:2003平方公里
变化:-88%
正如你所看到的,根据我们的聚类结果,水面面积的变化几乎是90%(!).这意味着在过去的23年里,水流失了近90%,这是真实的证据的事实。


好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!