前言
最近,字节跳动的青训营再次扬帆起航,作为第二次参与其中的小北,深感荣幸能借此机会为那些尚未了解青训营的友友们带来一些详细介绍。青训营不仅是一个技术学习与成长的摇篮,更是一个连接未来与梦想的桥梁~

小北的字节跳动青训营与 LangChain 实战课:探索 AI 技术的新边界(持续更新中~~~)-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/143454165
https://blog.csdn.net/Zhiyilang/article/details/143454165
小北的字节跳动青训营与LangChain系统安装和快速入门学习(持续更新中~~~)。-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/143455380
https://blog.csdn.net/Zhiyilang/article/details/143455380
哈喽哈喽,这里是是zyll~,北浊.欢迎来到小北的 LangChain 实战课学习笔记!
在这个充满变革的时代,技术的每一次进步都在推动着世界的快速发展。字节跳动的青训营,作为技术人才培养的重要平台,再次扬帆起航,为怀揣梦想的技术爱好者们提供了一个学习和成长的摇篮。作为青训营的一员,小北深感荣幸能够借此机会,为大家详细介绍青训营的精彩内容,并分享 LangChain 实战课的学习心得,希望能够帮助大家更好地理解和应用最前沿的 AI 技术。
嗨,技术爱好者们!今天,小北将带大家深入了解一个实战项目——“易速鲜花”内部员工知识库问答系统的开发。这个项目充分展示了LangChain框架的强大功能,让我们一探究竟!
【项目背景】
“易速鲜花”,作为在线鲜花销售领域的佼佼者,拥有复杂的业务流程和详尽的员工操作手册。然而,这些宝贵的信息却散落各处,员工难以快速查找。为了解决这个问题,我们决定利用LangChain框架,打造一套基于内部知识手册的“Doc-QA”系统,让信息查询变得简单快捷。
【开发框架】
整个框架由三部分构成: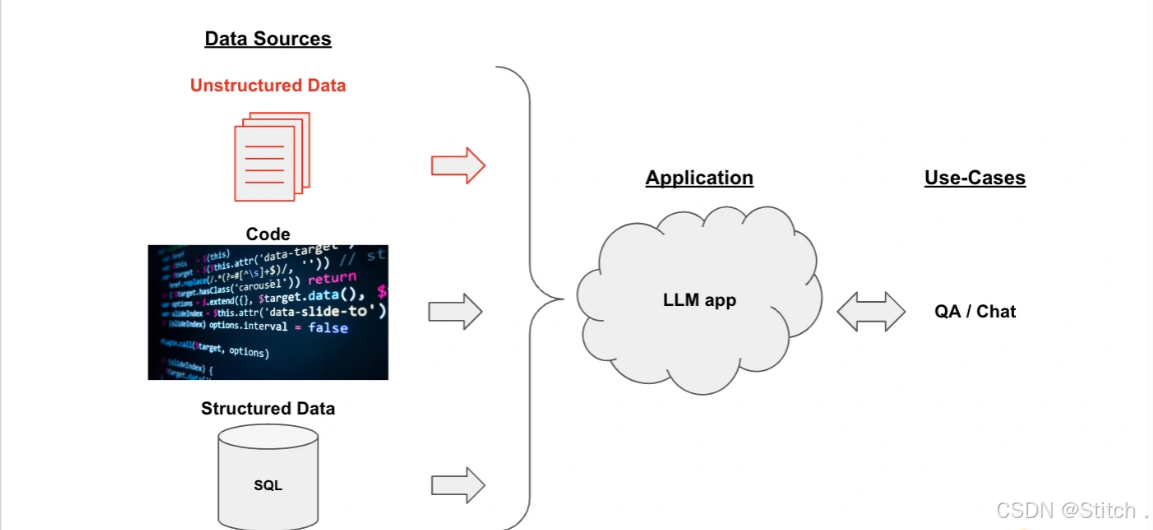
- 数据源(Data Sources):数据可以有很多种,包括PDF在内的非结构化的数据(Unstructured Data)、SQL在内的结构化的数据(Structured Data),以及Python、Java之类的代码(Code)。在这个示例中,我们聚焦于对非结构化数据的处理。
- 大模型应用(Application,即LLM App):以大模型为逻辑引擎,生成我们所需要的回答。
- 用例(Use-Cases):大模型生成的回答可以构建出QA/聊天机器人等系统。
【核心实现机制】
项目的核心在于数据处理管道,具体流程如下: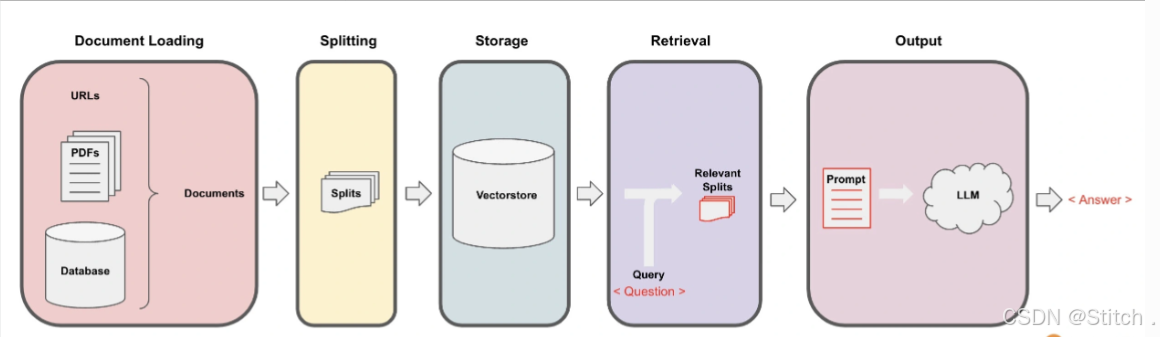
- Loading(加载):通过文档加载器,将各类文档转化为LangChain可识别的格式。
- Splitting(分割):利用文本分割器,将文档切割成指定大小的“文档块”。
- Storage(存储):将分割后的“文档块”转化为嵌入形式,并存储于向量数据库中,形成“嵌入片”。
- Retrieval(检索):应用程序通过比较余弦相似度,从存储中检索出与输入问题相似的嵌入片。
- Output(输出):将问题和检索到的嵌入片传递给语言模型(LLM),生成最终答案。
【数据的准备与载入】
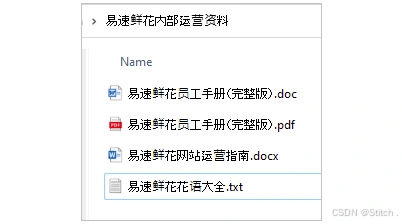
其中一个文档的示例如下:

我们使用LangChain的document_loaders模块,轻松加载PDF、Word和TXT等多种格式的文本文件。这些文本文件被加载后,存储在列表中,为后续处理提供便利。
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open AI API Key'
# 1.Load 导入Document Loaders
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader
# 加载Documents
base_dir = '.\OneFlower' # 文档的存放目录
documents = []
for file in os.listdir(base_dir):
# 构建完整的文件路径
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path)
documents.extend(loader.load())
这里我们首先导入了OpenAI的API Key。因为后面我们需要利用Open AI的两种不同模型做以下两件事:
- 用OpenAI的Embedding模型为文档做嵌入。
- 调用OpenAI的GPT模型来生成问答系统中的回答。
当然了,LangChain所支持的大模型绝不仅仅是Open AI而已,你完全可以遵循这个框架,把Embedding模型和负责生成回答的语言模型都替换为其他的开源模型。
在运行上面的程序时,除了要导入正确的Open AI Key之外,还要注意的是工具包的安装。使用LangChain时,根据具体的任务,往往需要各种不同的工具包(比如上面的代码需要PyPDF和Docx2txt工具)。它们安装起来都非常简单,如果程序报错缺少某个包,只要通过 pip install 安装相关包即可。
【文本的分割】
为了进行嵌入和向量存储,我们采用RecursiveCharacterTextSplitter对文本进行精细分割。
# 2.Split 将Documents切分成块以便后续进行嵌入和向量存储
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
【向量数据库存储】
分割后的文本被转化为嵌入形式,并存储于向量数据库中。在这里,我们选用OpenAIEmbeddings生成嵌入,并使用Qdrant作为向量数据库,确保高效存储和检索。
向量数据库有很多种,比如Pinecone、Chroma和Qdrant,有些是收费的,有些则是开源的。
LangChain中支持很多向量数据库,这里我们选择的是开源向量数据库Qdrant。(注意,需要安装qdrant-client)
具体实现代码如下:
# 3.Store 将分割嵌入并存储在矢量数据库Qdrant中
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Qdrant.from_documents(
documents=chunked_documents, # 以分块的文档
embedding=OpenAIEmbeddings(), # 用OpenAI的Embedding Model做嵌入
location=":memory:", # in-memory 存储
collection_name="my_documents",) # 指定collection_name
【相关信息的获取】
当用户提出问题时,系统会将问题转化为向量,并与向量数据库中的各个向量进行比较。通过计算相似度,系统能够迅速提取出与问题最相关的信息。
向量之间的比较通常基于向量的距离或者相似度。在高维空间中,常用的向量距离或相似度计算方法有欧氏距离和余弦相似度。
- 欧氏距离:这是最直接的距离度量方式,就像在二维平面上测量两点之间的直线距离那样。在高维空间中,两个向量的欧氏距离就是各个对应维度差的平方和的平方根。
- 余弦相似度:在很多情况下,我们更关心向量的方向而不是它的大小。例如在文本处理中,一个词的向量可能会因为文本长度的不同,而在大小上有很大的差距,但方向更能反映其语义。余弦相似度就是度量向量之间方向的相似性,它的值范围在-1到1之间,值越接近1,表示两个向量的方向越相似。
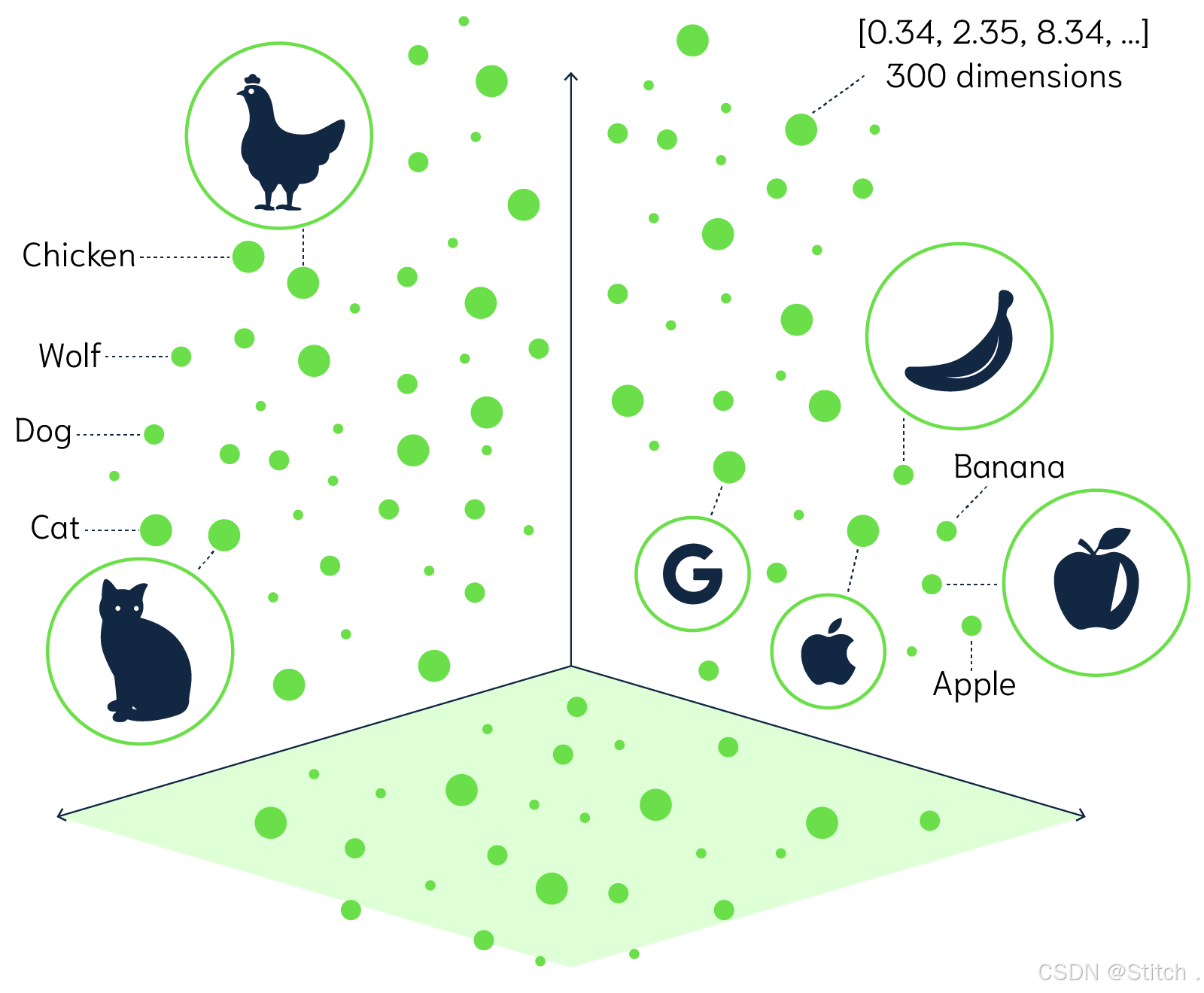 这两种方法都被广泛应用于各种机器学习和人工智能任务中,选择哪一种方法取决于具体的应用场景。
这两种方法都被广泛应用于各种机器学习和人工智能任务中,选择哪一种方法取决于具体的应用场景。
在RetrievalQA 链中有下面两大重要组成部分。
- LLM是大模型,负责回答问题。
- retriever(vectorstore.as_retriever())负责根据问题检索相关的文档,找到具体的“嵌入片”。这些“嵌入片”对应的“文档块”就会作为知识信息,和问题一起传递进入大模型。本地文档中检索而得的知识很重要,因为从互联网信息中训练而来的大模型不可能拥有“易速鲜花”作为一个私营企业的内部知识。
具体代码如下:
# 4. Retrieval 准备模型和Retrieval链
import logging # 导入Logging工具
from langchain.chat_models import ChatOpenAI # ChatOpenAI模型
from langchain.retrievers.multi_query import MultiQueryRetriever # MultiQueryRetriever工具
from langchain.chains import RetrievalQA # RetrievalQA链
# 设置Logging
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
# 实例化一个大模型工具 - OpenAI的GPT-3.5
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 实例化一个MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm)
# 实例化一个RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
【生成回答并展示】
最后,我们创建一个Flask应用来接收用户的问题,并生成相应的答案。通过index.html页面,用户可以直观地看到生成的答案。在这个步骤中,我们使用了之前创建的 RetrievalQA 链来获取相关的文档和生成答案。然后,将这些信息返回给用户,显示在网页上。
# 5. Output 问答系统的UI实现
from flask import Flask, request, render_template
app = Flask(__name__) # Flask APP
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
# 接收用户输入作为问题
question = request.form.get('question')
# RetrievalQA链 - 读入问题,生成答案
result = qa_chain({"query": question})
# 把大模型的回答结果返回网页进行渲染
return render_template('index.html', result=result)
return render_template('index.html')
if __name__ == "__main__":
app.run(host='0.0.0.0',debug=True,port=5000)
相关HTML网页的关键代码如下:
<body>
<div class="container">
<div class="header">
<h1>易速鲜花内部问答系统</h1>
<img src="{
{ url_for('static', filename='flower.png') }}" alt="flower logo" width="200">
</div>
<form method="POST">
<label for="question">Enter your question:</label><br>
<input type="text" id="question" name="question"><br>
<input type="submit" value="Submit">
</form>
{% if result is defined %}
<h2>Answer</h2>
<p>{
{ result.result }}</p>
{% endif %}
</div>
</body>
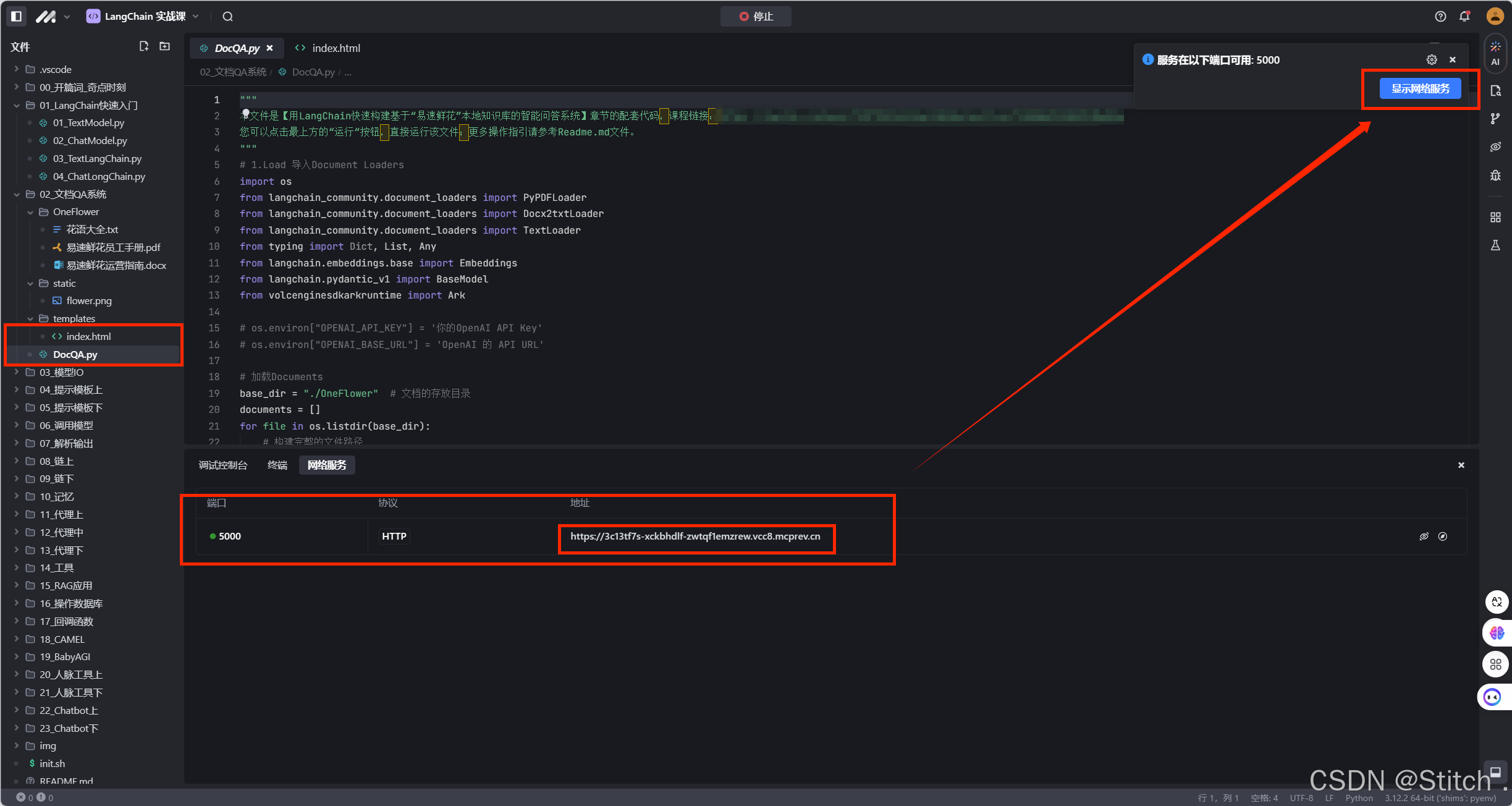
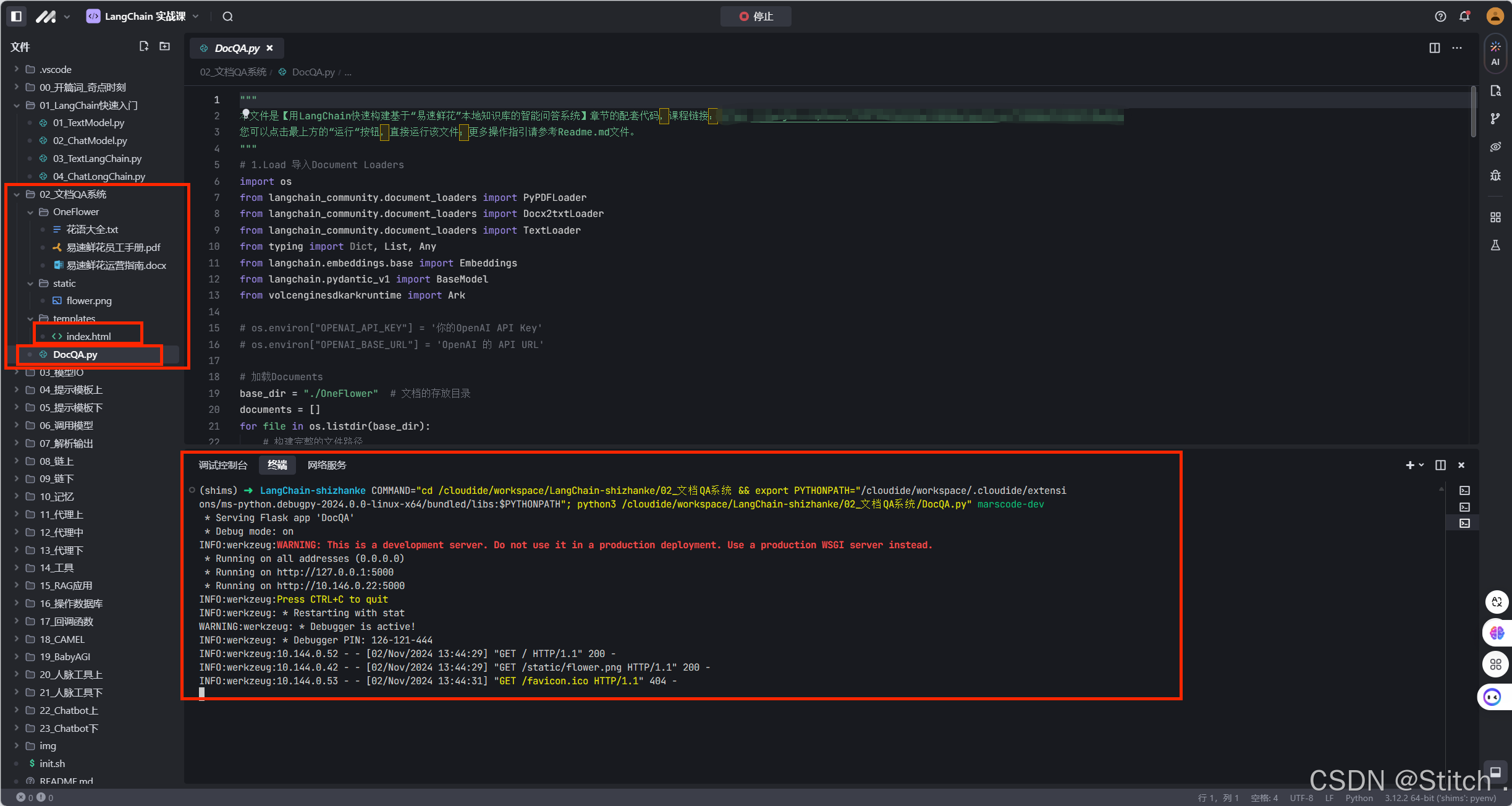
这个项目的目录结构如下: 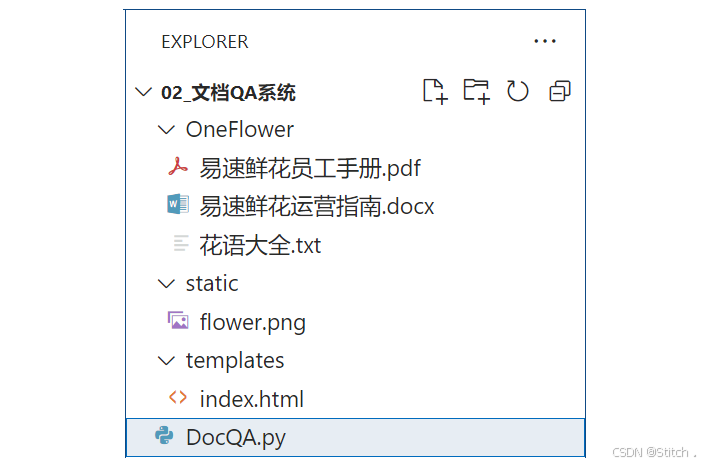 运行程序之后,我们跑起一个网页 http://127.0.0.1:5000/
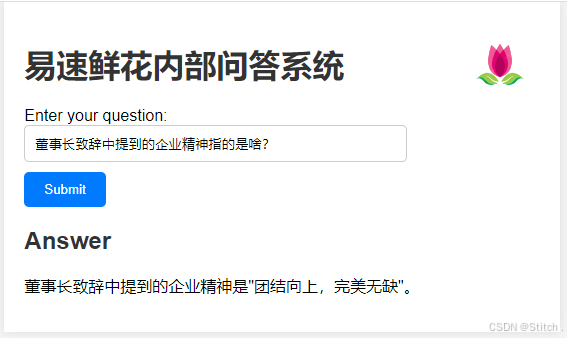
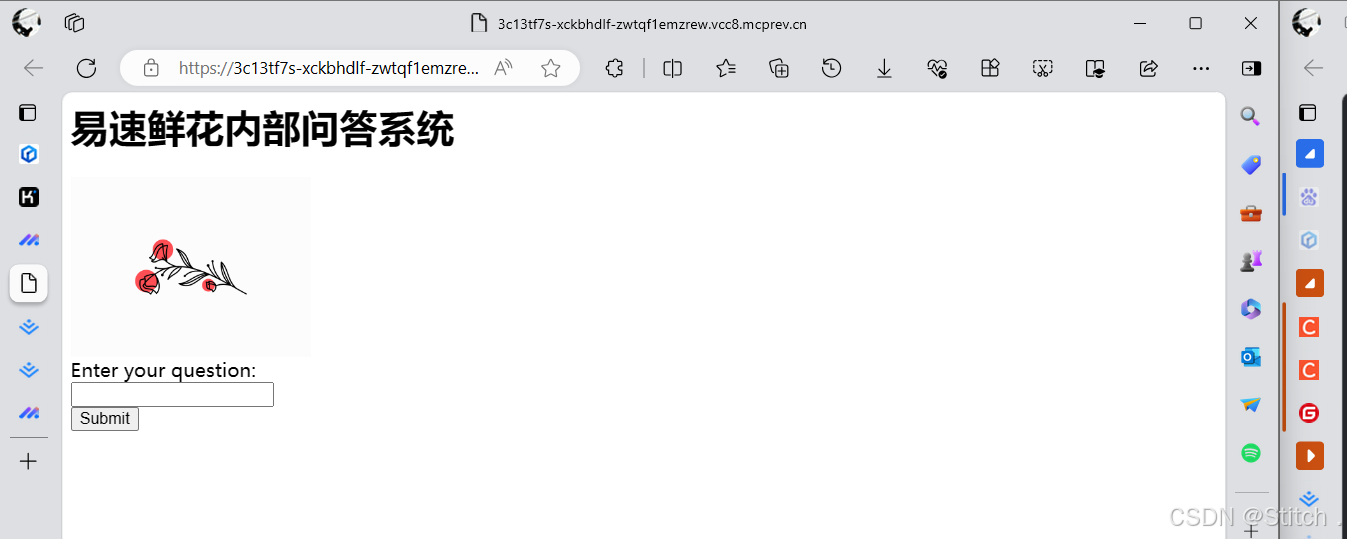
运行程序之后,我们跑起一个网页 http://127.0.0.1:5000/![]() https://link.juejin.cn/?target=http%3A%2F%2F127.0.0.1%3A5000%2F。与网页进行互动时,可以发现,问答系统完美生成了专属于异速鲜花内部资料的回答。
https://link.juejin.cn/?target=http%3A%2F%2F127.0.0.1%3A5000%2F。与网页进行互动时,可以发现,问答系统完美生成了专属于异速鲜花内部资料的回答。
【总结】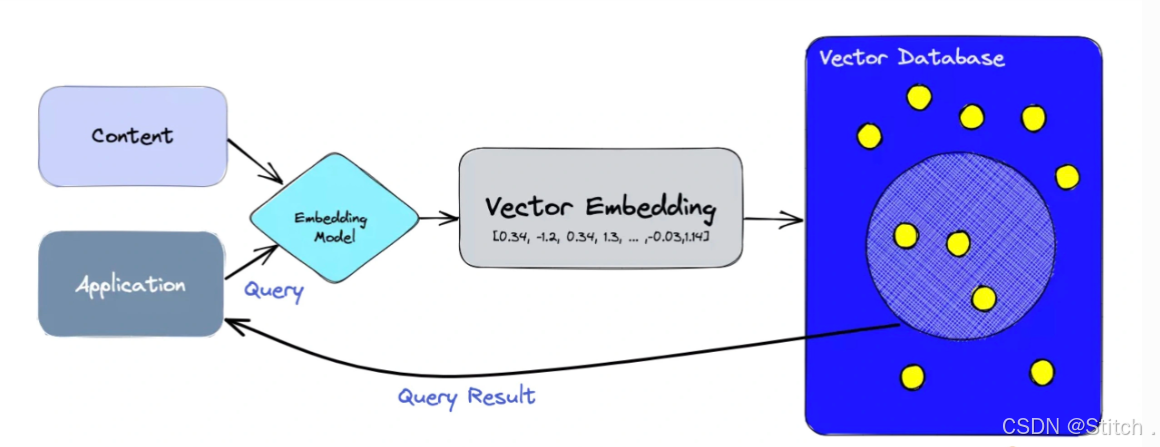
通过这一系列流程,我们成功地将本地知识切片、嵌入并存储于向量数据库中。当用户提出问题时,系统能够迅速检索相关信息,并生成精准的回答。LangChain的强大功能在此得到了充分展示。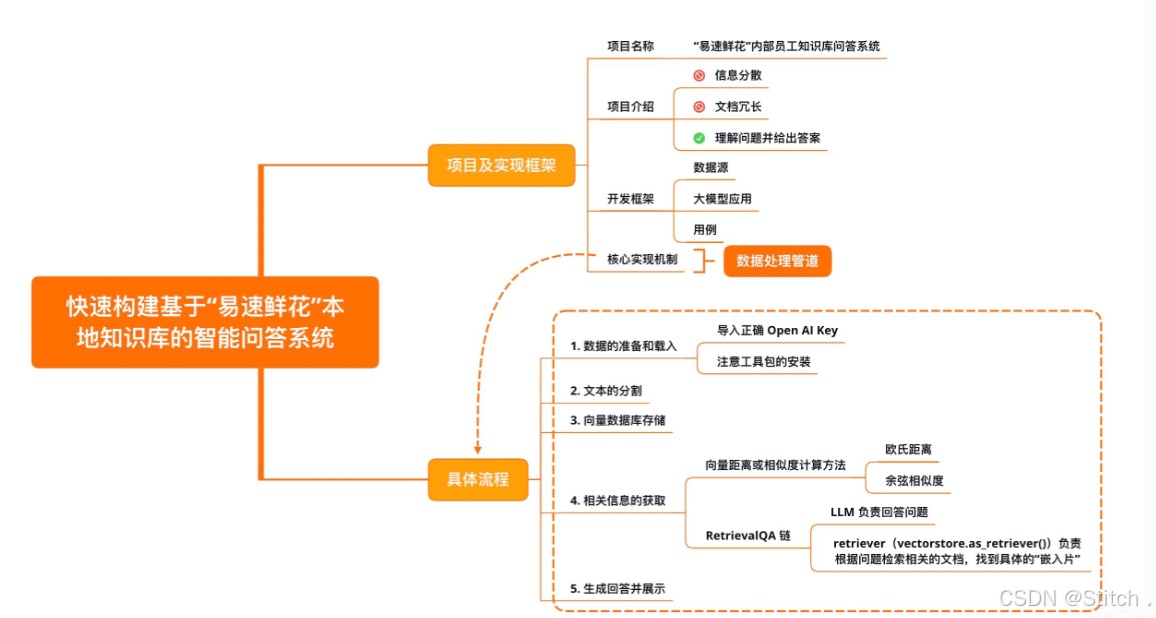
【思考题】
- 请你用自己的话简述一下这个基于文档的QA(问答)系统的实现流程?
- LangChain支持很多种向量数据库,你能否用另一种常用的向量数据库Chroma来实现这个任务?
- LangChain支持很多种大语言模型,你能否用HuggingFace网站提供的开源模型 google/flan-t5-x1 代替GPT-3.5完成这个任务?
【延伸阅读】
- LangChain官方文档对 Document QA 系统设计及实现的详细说明
- HuggingFace官网上的文档问答资源
- 论文开放式表格与文本问题回答,Chen, W., Chang, M.-W., Schlinger, E., Wang, W., & Cohen, W. W. (2021). Open Question Answering over Tables and Text. ICLR 2021.
【结束语】
我是小北,感谢友友们的阅读!如果你觉得这个项目对你有帮助,欢迎分享给更多有需要的人。在后面的文章中,我们将继续深入探讨LangChain的更多功能和应用。期待与你在技术的海洋中再次相遇!