可解释机器学习在社会经济模型的应用
在地学中尤其是人文地理学,有时我们要创建社会经济模型。机器学习作为一种强大的工具,能够在这些模型中达到高精度的预测效果。然而,在许多实际应用中,可解释性是关键,因为它不仅帮助我们理解模型的决策过程,还能增加用户对模型预测结果的信任。本文将探讨如何在社会经济模型中应用可解释机器学习,特别是使用澳洲公开数据集进行分析。
数据
本文使用澳洲公开的数据集
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
file_path = '/home/mw/input/eco2933/data.csv'
data = pd.read_csv(file_path)
data = data.dropna()
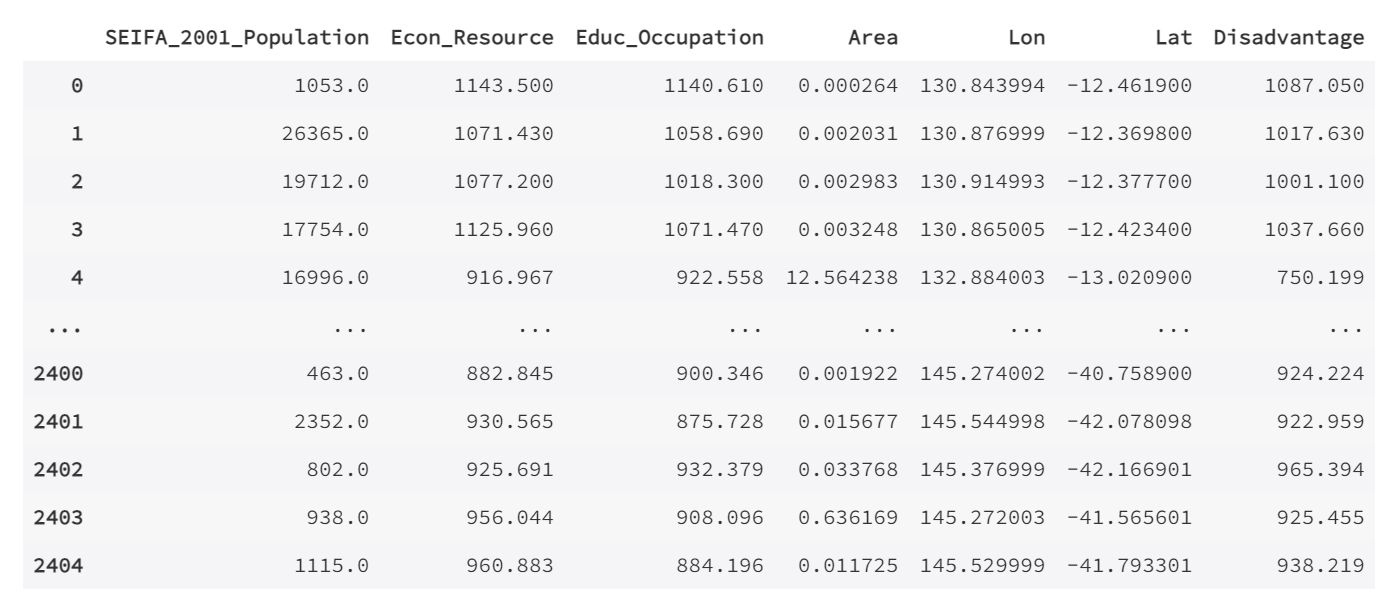
包括人口、经济、教育、地理信息等多种变量。我们的目标是预测各个地区的劣势人口数量(Disadvantage)。劣势人口数量往往意味着低收入和较差的生活条件,如果能够准确模拟这种情况,将对区域发展和政策制定提供重要的指导。
我们将数据集划分为7:3,分别用来训练和测试
# Exclude the date column and separate the target variable
X = data.drop(columns=['Disadvantage'])
y = data['Disadvantage']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=101)
模型
这里我们构建一个随机森林模型:
随机森林模型因其在处理复杂数据集时的高效性和准确性而被广泛应用。以下是模型的训练和评估代码:
# Initialize and train the RandomForestRegressor
model = RandomForestRegressor(max_depth=5, random_state=101)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# Print the evaluation metrics
print(f'Mean Squared Error: {mse}')
print(f'R^2 Score: {r2}')
-
Mean Squared Error: 1161.0806348966228
-
R^2 Score: 0.7781199666990248
模型的评估结果显示,均方误差(MSE)为1161.08,R^2得分为0.778,表明模型能够解释78%的变量。这是一个相当高的解释度,表明模型在预测劣势人口数量方面具有良好的性能。
结果分析
接下来,我们在测试集上评估模型的性能,通过绘制观测值与预测值的散点图来直观地展示模型的预测效果:
import matplotlib.pyplot as plt
# Predict on the test set
y_pred = model.predict(X_test)
# Plot the observed vs predicted values
plt.figure(figsize=(4, 4))
plt.scatter(y_test, y_pred, alpha=0.7)
plt.title("predict disadvantaged using Machine Learning")
plt.xlabel("Observed Disadvantaged")
plt.ylabel("Predicted Disadvantage")
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--r', lw=2)
plt.text(600, 1150, 'R^2=0.78')
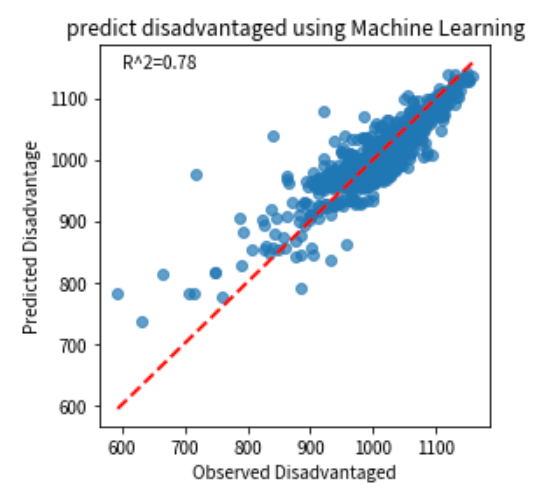
结果显示,模型的预测值与实际观测值之间的相关性较高,表明模型具有较好的稳健性。
可解释机器学习
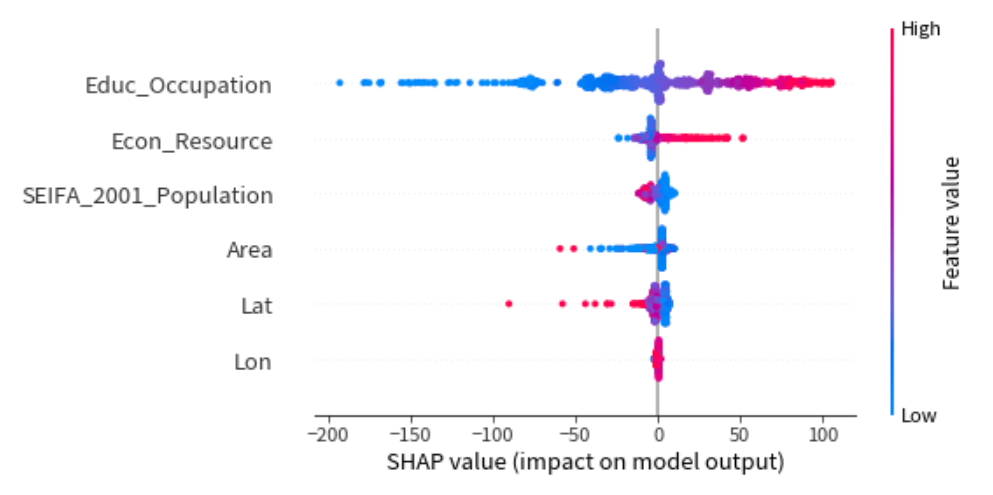
为了提高模型的可解释性,我们使用SHAP(SHapley Additive exPlanations)值对模型进行解释。SHAP值能够提供每个特征对预测结果的贡献,帮助我们理解模型的决策过程。以下是使用SHAP进行模型解释的代码:
import shap
explainer = shap.Explainer(model)
shap_values = explainer.shap_values(X_test)
plotsp = shap.summary_plot(shap_values, X_test, max_display=6, show = False)
shap.plots.bar(explainer(X_test), max_display=10)
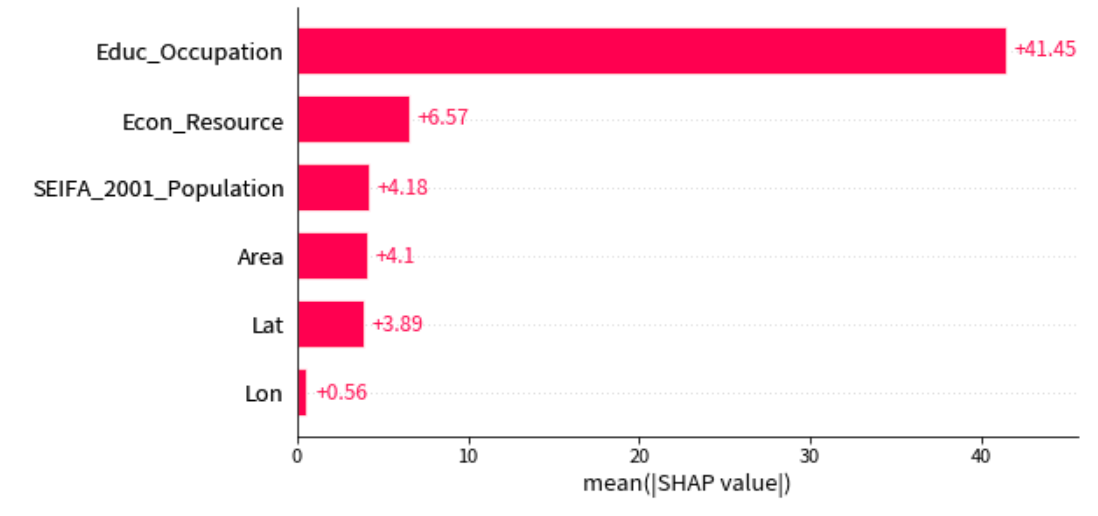
结果表明教育因素排名第一,而经济因素贡献第二,表明一个区域的劣势人口总体上受该地区的教育水平影响。
通过SHAP值的分析,我们发现教育因素在预测劣势人口数量中起到最重要的作用,其次是经济因素。这表明一个地区的教育水平对劣势人口的数量有着显著影响,而经济因素的影响也不可忽视。
结论
本文通过随机森林模型和SHAP值分析展示了可解释机器学习在社会经济模型中的应用。通过对澳洲公开数据集的分析,我们能够准确预测各个地区的劣势人口数量,并通过可解释性方法揭示了不同特征对预测结果的贡献。这不仅增强了模型的透明性,也为区域发展和政策制定提供了重要的依据。未来的研究可以进一步优化模型,加入更多的变量,以提高预测精度和解释深度。