在R中实现线性混合效应模型(LMM)
线性混合效应模型是扩展线性回归模型以考虑固定效应和随机效应的统计模型。混合效应模型在心理学、生态学、计量经济学和空间统计学等领域应用十分广泛。例如,在生态学中,线性混合效应模型通常被称为分层线性模型(Hierarchical Linear Model,简称 HLM)。
这些模型在处理不完全独立的数据结构时特别有用。例如,在地学数据中,数据之间往往是不独立的,如降雨和蒸发,二者往往存在强线性关系,这时LMM则非常适用。
数据
在开始构建模型之前,让我们先准备好数据集。
我们使用mtcars数据集,并添加了每种车型的原产国信息,这些信息来自我们自己创建的单独表。
library(tidyverse)
data(mtcars)
cars_origin_trbl <- tribble(
~car, ~origin,
"Mazda RX4", "Japan",
"Mazda RX4 Wag", "Japan",
"Datsun 710", "Japan",
"Hornet 4 Drive", "United States",
"Hornet Sportabout", "United States",
"Valiant", "United States",
"Duster 360", "United States",
"Merc 240D", "Germany",
"Merc 230", "Germany",
"Merc 280", "Germany",
"Merc 280C", "Germany",
"Merc 450SE", "Germany",
"Merc 450SL", "Germany",
"Merc 450SLC", "Germany",
"Cadillac Fleetwood", "United States",
"Lincoln Continental", "United States",
"Chrysler Imperial", "United States",
"Fiat 128", "Italy",
"Honda Civic", "Japan",
"Toyota Corolla", "Japan",
"Toyota Corona", "Japan",
"Dodge Challenger", "United States",
"AMC Javelin", "United States",
"Camaro Z28", "United States",
"Pontiac Firebird", "United States",
"Fiat X1-9", "Italy",
"Porsche 914-2", "Germany",
"Lotus Europa", "British",
"Ford Pantera L", "United States",
"Ferrari Dino", "Italy",
"Maserati Bora", "Italy",
"Volvo 142E", "Sweden"
)
mtcars$car <- rownames(mtcars)
mtcars <- mtcars %>%
left_join(cars_origin_trbl)
数据探索
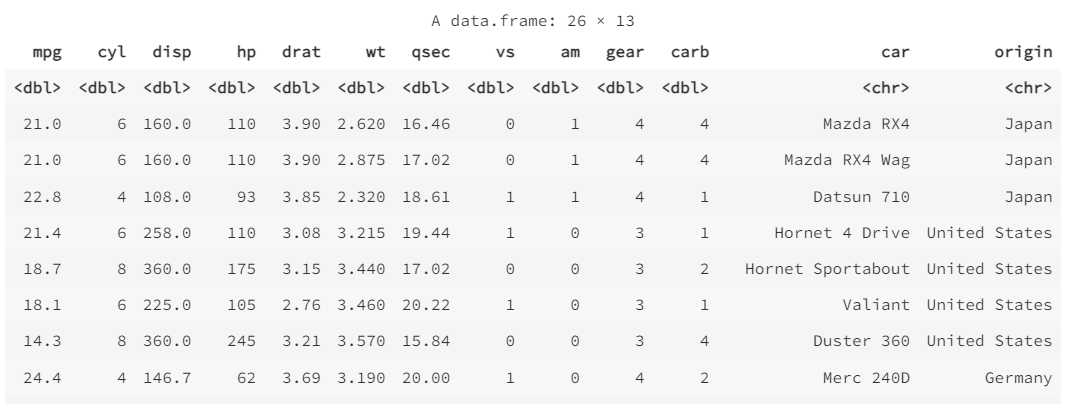
我们先探究每加仑行驶英里数(mpg)和发动机重量(wt)的关系,再把原产国映射到点上。
我们可以首先创建一个散点图来比较不同汽车的wt和mpg之间的关系,然后为散点图着色以显示附加特征origin。通过这样做,我们可以看到一种负相关关系:发动机较重的汽车往往燃油效率较差。但我们也看到了聚类现象,因为美国汽车似乎发动机较重,燃油效率较差,而日本和瑞典汽车发动机较轻,效率较高。
library(MetBrewer)
mtcars %>%
ggplot(aes(x = wt, y = mpg, color = origin)) +
geom_point(size = 4) +
scale_color_manual(values=met.brewer("Hiroshige", 6), name = "Origin") +
ggtitle("mtcars")
最小二乘回归
普通最小二乘线性回归通常是开始模型构建过程的第一站。我们可以从 OLS 回归开始
ols_model <- lm(mpg ~ wt + origin, mtcars)
lm(mpg ~ wt + origin, mtcars)
这里我们创建一个线性模型,以了解汽车发动机的重量如何预测燃油效率,同时将汽车的原产国作为附加因素考虑在内。此模型的函数形式可以按以下方式编写。
该模型使用最小二乘法估计系数β0、β1和β2,以最小化观测值和预测值之间的平方差和。现在让我们通过调用函数看看我们模型的输出。
summary(lm(mpg ~ wt + origin, mtcars))

变量的估计系数wt为-4.8375。这表明,保持origin不变,重量每增加一个单位,平均每加仑行驶里程就会减少约4.8375
OLS模型分析
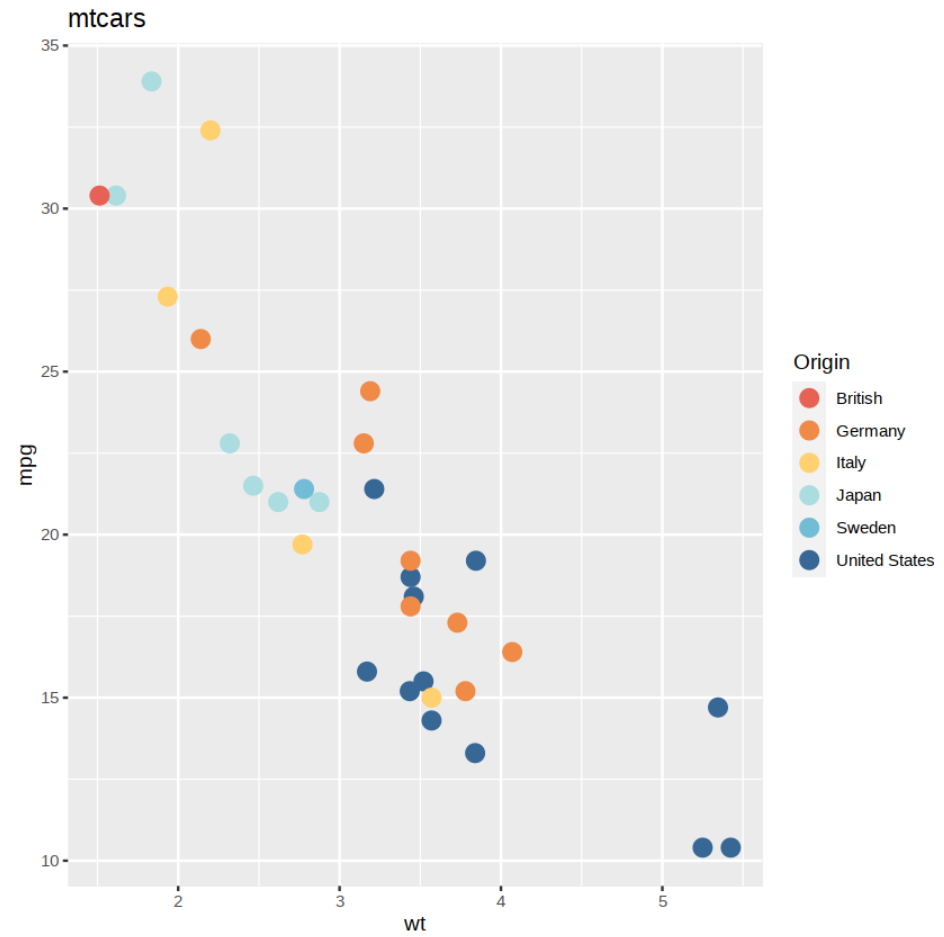
我们的线性模型假设和之间的关系wt在mpg分类变量的所有级别上都是相同的。换句话说,它假设对的影响wt是mpg恒定的,无论哪国生产的车型
让我们绘制数据图表,并为每个类别分别添加线性回归线。
mtcars %>%
ggplot(aes(x = wt, y = mpg, color = origin)) +
geom_point(size = 4) +
scale_color_manual(values=met.brewer("Hiroshige", 6), name = "Origin") +
ggtitle("mtcars") +
geom_smooth(method = 'lm', se = FALSE)
我们对每个类别分别应用线性回归后,我们可以看到每个类别的回归线斜率不同。这意味着重量对每加仑英里数的影响因国家而异。
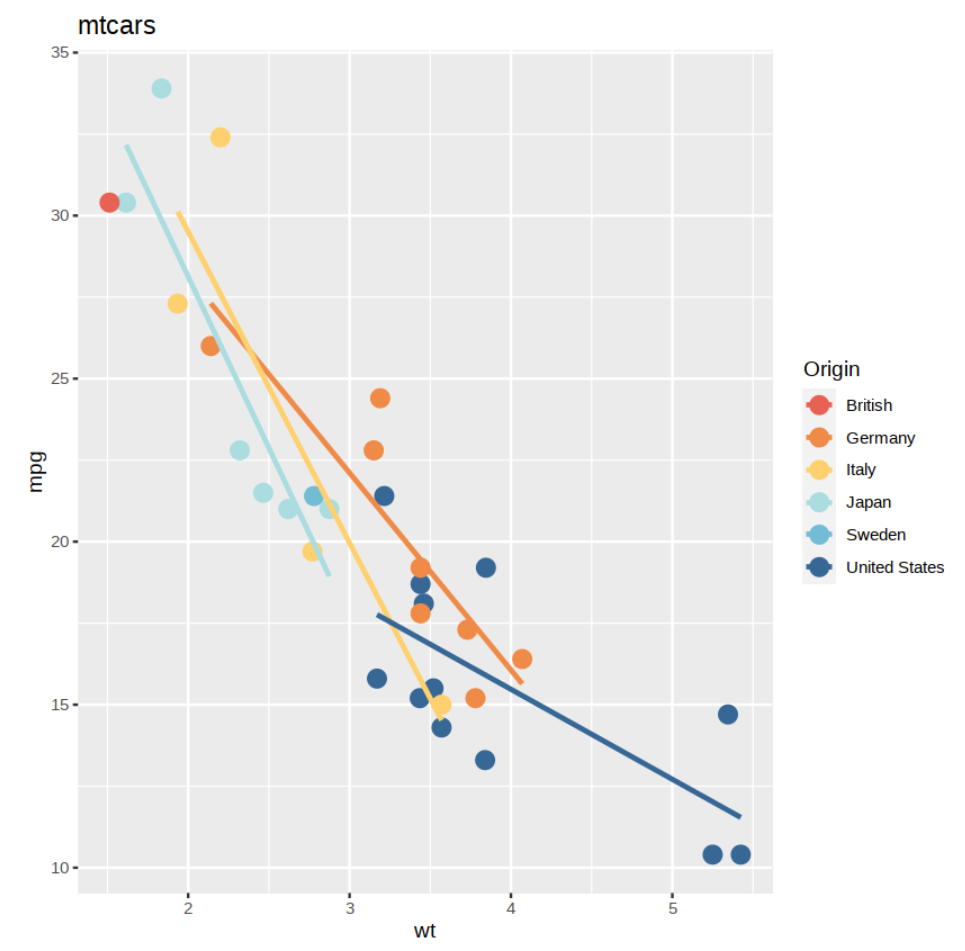
我们可以测试模型假设的另一种方法是创建诊断图。其中一个图是拟合值与残差的图。当我们创建这个诊断图时,我们可以看到一个 V 形,其中负残差位于底部和中间,而正残差位于两端。这表明我们的关系实际上有点非线性。我们看到的另一个问题是,不同汽车来源的残差方差并不相等。例如,我们看到美国汽车的残差往往比德国汽车的残差更远。
# Fit linear model
mtcars_linear_model <- lm(mpg ~ wt + origin, mtcars)
# Create a data frame with fitted values and residuals
residuals_df <- data.frame(
fitted_values = predict(mtcars_linear_model),
residuals = residuals(mtcars_linear_model),
origin = mtcars$origin
)
# First graph (scatter plot with linear regression)
mtcars_graph <- ggplot(data = mtcars, aes(x = wt, y = mpg, color = origin)) +
geom_point() +
geom_smooth(method = 'lm', se = FALSE, color = '#376795') +
labs(title = "Mtcars", subtitle = "Linear Regression") +
theme(legend.position = "none") +
scale_color_manual(values=met.brewer("Hiroshige", 6), name = "Origin")
# Second graph (Fitted Values vs. Residuals colored by origin)
fitted_values_vs_residuals <- ggplot(data = residuals_df, aes(x = fitted_values, y = residuals, color = origin)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dashed", color = '#ef8a47', size = 1) +
xlab("Fitted Values") +
ylab("Residuals") +
labs(title = "Mtcars", subtitle = "Fitted Values vs Residuals") +
scale_color_manual(values=met.brewer("Hiroshige", 6), name = "Origin") +
scale_x_reverse() # Reverse the x-axis order
library(patchwork)
# Combine the two graphs
mtcars_graph + fitted_values_vs_residuals
考虑交互作用
另一个选择是考虑交互作用。我们用符号来指定交互作用*。
ols_model <- lm(mpg ~ wt * origin, mtcars)
通过指定交互效应,我们表明wt对mpg的影响会随着origin而变化。当我们想要考虑一个变量的影响随着另一个变量的变化而变化时,交互效应通常是有意义的。
线性混合效应模型
现在让我们使用mtcars数据框来探索线性混合效应模型的概念。线性混合效应模型结合了固定效应和随机效应成分,以解释组内和组间变异。这种模型在处理表现出相关性或聚类的数据时特别有用,正如我们在mtcars数据中看到的那样。在其他情况下,线性混合效应模型还可以提供分析重复测量或嵌套数据的框架。
我们可以将固定效应视为适用于整个数据集的总体、一般模式或趋势。这些效应在所有组或级别上都是恒定的。在我们的模型中,我们将wt作为固定效应预测mpg,并考虑origin的随机效应。换句话说,模型的固定效应部分捕捉了所有汽车wt和mpg之间的平均关系,无论origin如何。
mtcars <- mtcars %>%
filter(origin == "Germany" | origin == "United States" | origin == "Japan")
我们现在使用lme4包中的lmer()函数创建一个线性混合效应模型。
library(lme4)
lmer_model <- lmer(mpg ~ wt + (1 | origin), mtcars)
我们再次使用summary()函数来了解我们模型的输出。
summary(lmer_model)

从我们的线性混合效应模型输出中,可以获得关于模型拟合和估计系数的信息。固定效应部分显示了截距和预测变量wt的估计系数。
这里截距估计为35.8161,wt的系数估计为-4.9253。这些估计代表了wt每增加一个单位时mpg的平均变化,而保持origin不变。“保持origin不变”在这里的含义不同于线性模型。在这里,wt对mpg的影响不考虑各国之间的差异,因为线性混合效应模型并没有为每个国家报告系数,而是通过随机效应处理国家间的变异。
从模型输出可以看出,随机效应部分提供了随机效应的方差成分信息。在该模型中,origin分组变量有一个随机截距。随机截距的估计方差为0.04054,标准差为0.2013。我们可以看到,0.04054的随机效应方差远小于8.59027的残差方差,这表明mpg的相当一部分变异是由固定效应和组内变异解释的,而不是组间变异。因此,在考虑wt之后,origin对mpg的影响有限。
两个模型的关键区别在于对origin变量的处理。虽然两个模型都认识到origin的重要性,但lm模型为每个级别提供了显式系数,使我们可以直接比较影响,而lmer模型则通过随机效应更隐式地处理变异。
本文由 mdnice 多平台发布