Dominance-Analysis:用于准确、直观地计算预测因子相对重要性的 Python 库
地学中变量的重要性和敏感性非常重要,如果没有模型,则必须用统计方法确定敏感性。
此包旨在确定回归和分类模型中预测因子的相对重要性。相对重要性的确定取决于如何定义重要性;Budescu (1993) 和 Azen 和 Budescu (2003) 建议使用优势分析 (DA)
如果目标是连续变量,该包将通过比较所有子集模型中增量 R 平方贡献来确定一个预测变量相对于另一个预测变量的主导地位。如果目标变量是二进制变量,该包将通过比较所有子集模型中增量伪 R 平方贡献来确定另一个预测变量相对于另一个预测变量的主导地位。
Python库
使用以下命令安装该包:
pip install dominance-analysis
原理
本方法的优势之处在于它以成对方式衡量相对重要性,并在包含其他预测因子子集的所有 2 (p-2)个模型的背景下比较这两个预测因子。因此,如果我们总共有“p”个预测因子,我们将构建 2^p -1 个模型(所有可能的子集模型)并计算每个预测因子对所有其他预测因子子集模型的增量 R2贡献。
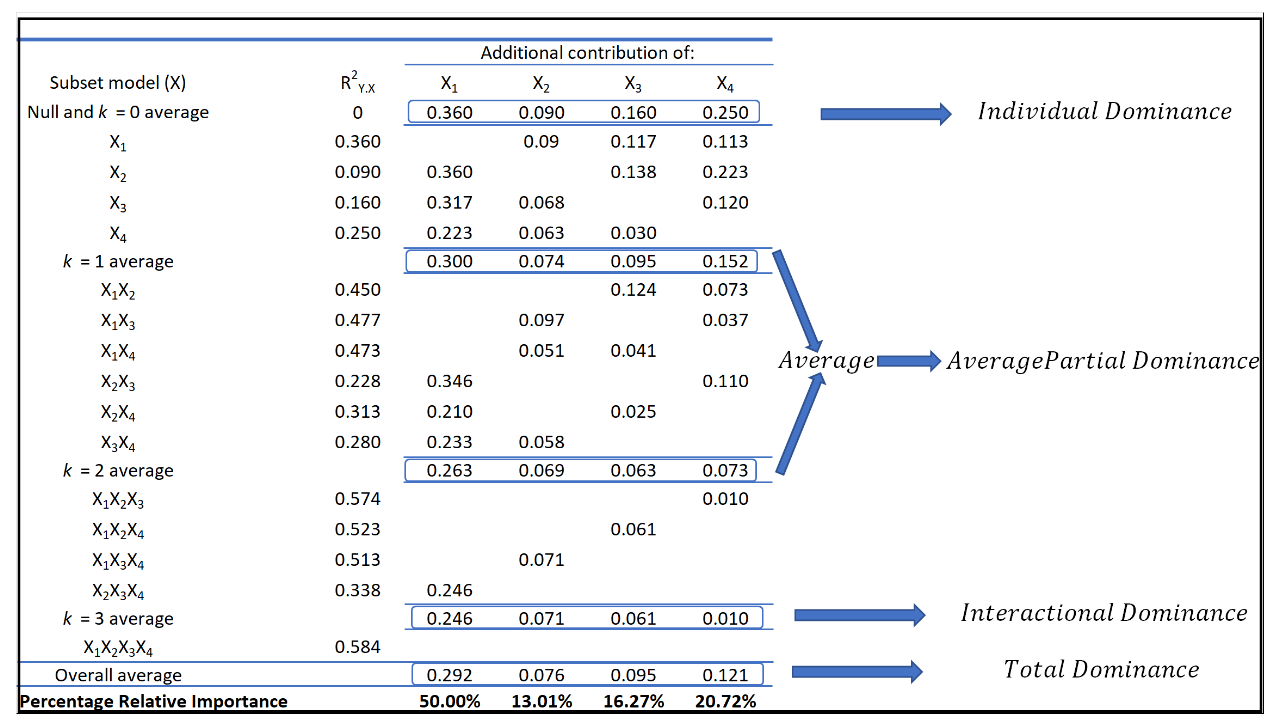
下面是用于计算具有四个预测因子的重要性比较

本包也适用于分类任务,回归的方差比例度量是 R2,但是由于在逻辑回归/分类模型中没有 R2,因此我们使用了伪 R2。
妙处在于,所有预测因子的总体平均增量 R2之和等于完整模型,这样得到的结果是具有实际意义的。
根据作者所述,该库具有三个优势
-
交互优势- 这是预测因子对完整模型的增量 R2贡献。因此,特定预测因子“X”的交互优势将是完整模型的R2与模型与除特定预测因子“X”之外的所有其他预测因子的R2之间的差值。 -
**平均部分优势 -**这是预测因子对所有子集模型(完整模型和双变量(仅存在一个预测因子时)模型除外)的平均增量R2贡献的平均值。 因此,这可以解释为当预测因子可用于与其他预测因子的所有可能组合(所有预测因子都可用时的组合除外)时,预测因子的平均影响。 -
**总主导性 -**主导性的最后一个度量通过对所有条件值取平均值来总结每个预测因子对所有子集模型的额外贡献。
在下表中,我们说明了用于得出四个主导地位指标的计算方法。
数据
使用的示例数据为蒸散发
import pandas as pd
geo_dataset=pd.read_csv('../data/geo.csv')
geo_dataset
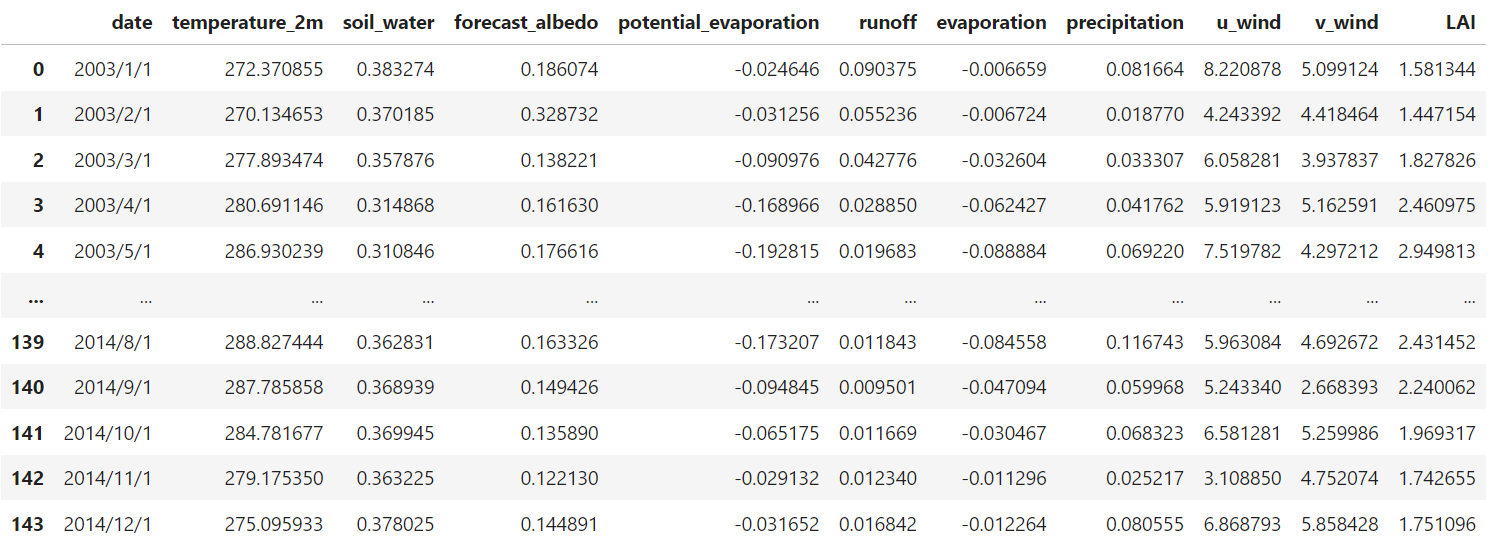
其它变量包括温度降水等等,探究蒸散发的敏感性
代码
from dominance_analysis import Dominance_Datasets
from dominance_analysis import Dominance
dominance_regression=Dominance(data=boston_dataset,target='House_Price',objective=1)
绘制增量 R 平方和优势曲线
from dominance_analysis import Dominance
dominance_regression = Dominance(data=geo_dataset.drop(columns=['date', 'potential_evaporation']), target='evaporation', objective=1)
dominance_regression.incremental_rsquare()
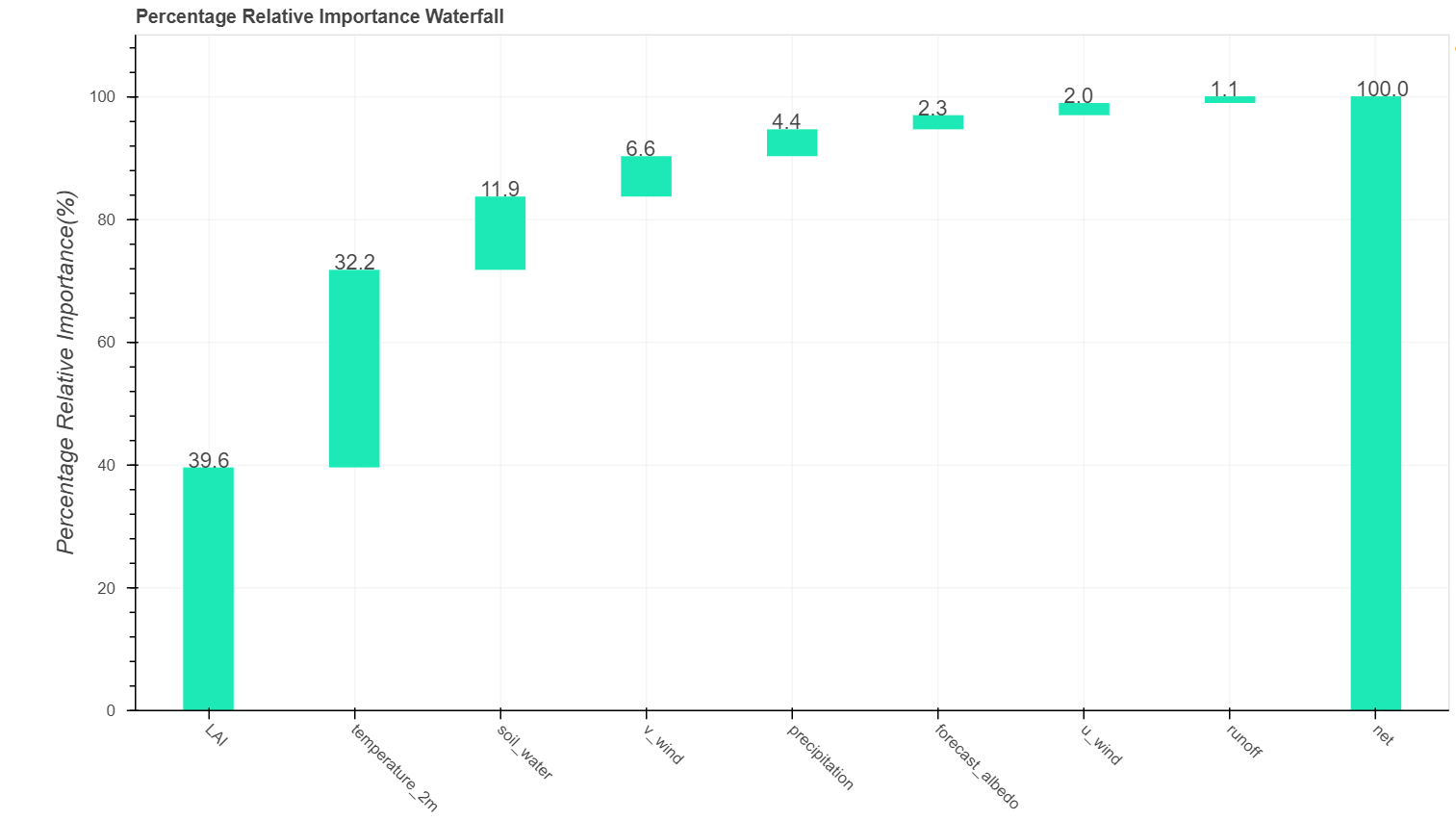
dominance_regression.plot_incremental_rsquare()
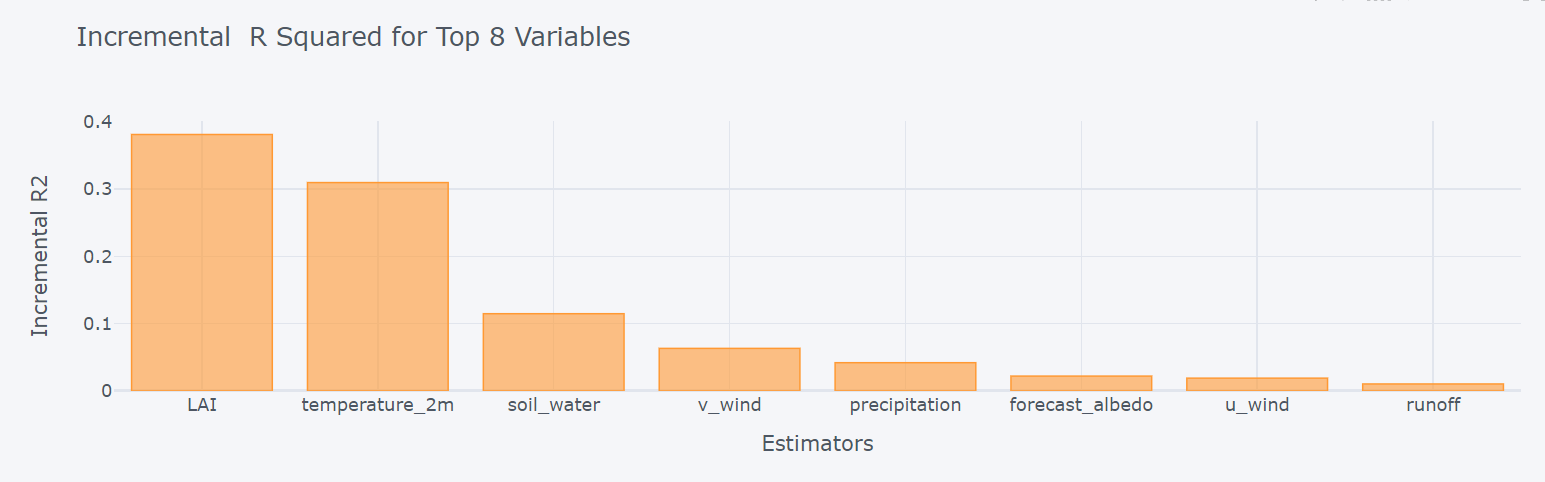
可见该区域蒸散发对LAI、温度、土壤水较为敏感。
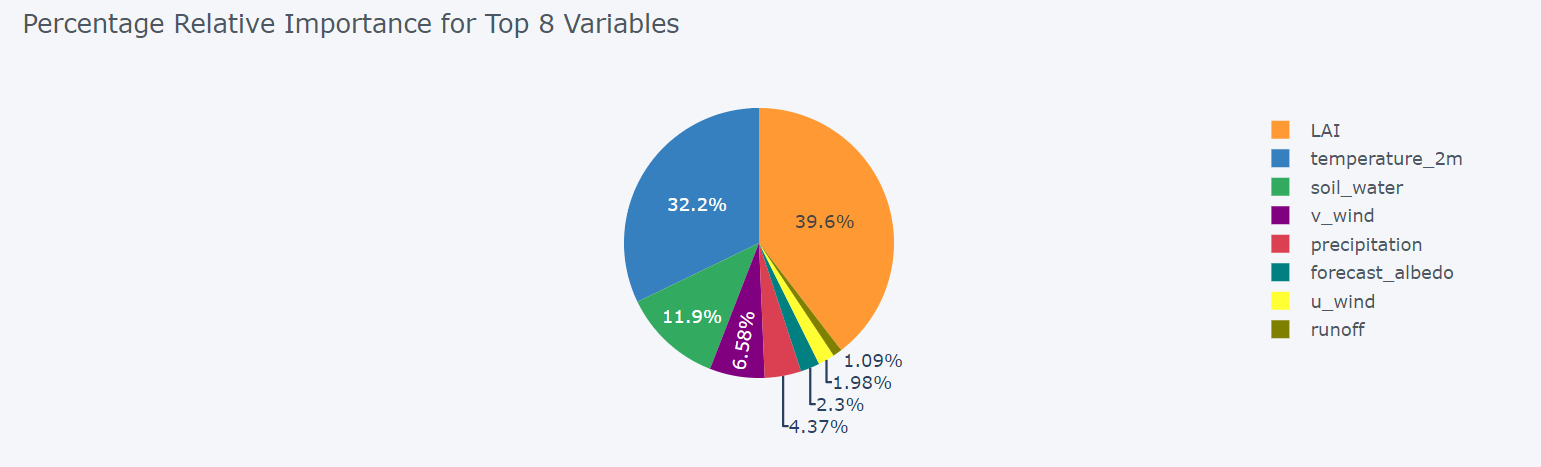
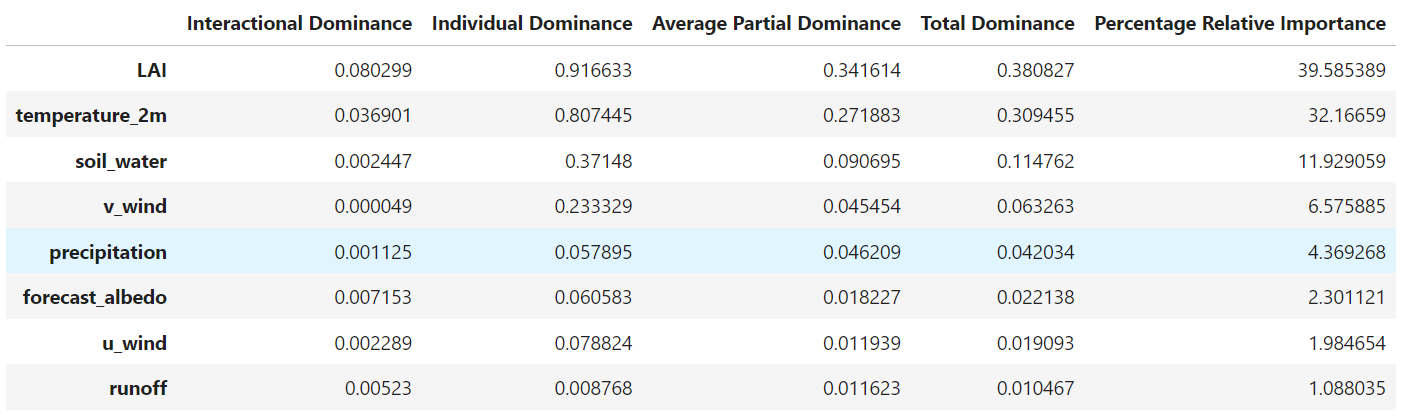
优势统计(R 平方)
dominance_regression.dominance_stats()
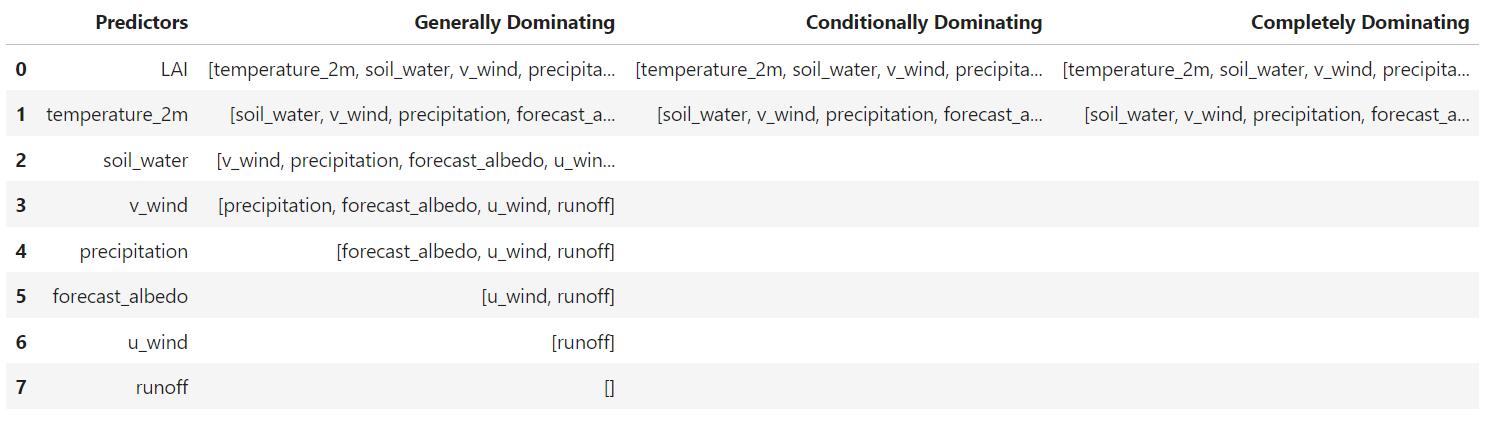
主导程度
dominance_regression.dominance_level()
示例数据和代码可以后台回复
读者如果在全球大尺度上运行,进行一定的统计分析和故事撰写,也能发表SCI论文!