目录
1.线性回归凭什么这么重要?
要解释整个问题首先要了解一下什么叫线性回归
在二十世纪二十年代以前,科学家基于传统牛顿力学、相对论等理论的成功,认为世界是由因果规律支配的,一切事物都严格遵守因果律和自然法则。也就是苹果会掉下来是因为有力在拉它,太阳在转也是因为有力在拉它。推导到最后就发现世界必须有一个源头提供原始的力,最终侧面证明了上帝的存在。
仔细想想当时人们的想法也确实可以理解,貌似世界的运转规律就是按照人为编写好的代码逻辑一样有条不紊的运行着。
然鹅!到了二十世纪二十年代以后,开创量子力学的哥本哈根学派科学家波尔、海森伯认则为认为世界上一切事物的发生都是不确定的,只能用概率也就是发生的可能性来描述事物运动规律。也就是说世间一切的事儿都符合于某种概率分布而不是因果,可以用概率模型来表示一切规律。这就完全打破了人们以前的固有认知。

沃纳·卡尔·海森堡(1901年12月5日—1976年2月1日) 德国著名物理学家,量子力学的主要创始人,哥本哈根学派的代表人物,1932年诺贝尔物理学奖获得者
举个例子,我说我会轻功可以在水上行走。按照以前人们的逻辑来看,这人一定是个傻子,按照上帝写好的逻辑人的密度比水大你不是一下就沉底了么。然而如果按照概率模型的逻辑,我虽然还是会沉底。但是我还是有千万亿万个零分之一的概率在真的在水面扑腾几下。虽然这个概率小到可以忽略不记,但是还是有本质的区别。
我们学习机器学习的目的就是为了寻找事物背后的这个规律,或者说模式(pattern),而线性回归就是描述背后逻辑规律的一种方法。
说了这么多我们为什么要学习线性回归模型呢?
对机器学习有点了解的同学可能觉得这个东西不就是高中学过的东西,有必要重新学习一边吗?况且这么老这么笨的算法哪有什么决策树,SVM 有逼格。其实线性回归依然是工业界使用最广泛的模型。对于工业界,他们面临最棘手的问题不是数据不足,而是算力紧张。因此正需要那种即需要大量数据又计算简单的算法模型。因为数据量够多,线性回归这种简单的模型也可以产生不错的效果。而使用更复杂的模型不仅速度会大幅下降,准确率也不见得能提高多少。在很多场景下,因为公司没办法根据黑盒模型去做相应的策略,所以业务方也更需要可解释性的模型,如线性回归,决策树,知识图谱等。所以线性回归,依旧是工业界使用最广泛,效果非常好的模型。
2.线性到底是怎么一回事?
概念澄清:什么是“线性”
很多初学者都会把“线性”简单的理解成预测的模型是一条线,或者在分类任务中用一条线把数据集分开。这种理解方式可以帮助我们在很短时间内记住概念,然而线性模型也可以通过基函数的方式画出曲线分类线,“线性”限制的是parameter(参数),而不是feature(自变量)。这种错误的概念在深入学习时需要得到及时的纠正
先从定义看起:线性回归分析(Linear Regression Analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。本质上说,这种变量间依赖关系就是一种线性相关性,线性相关性是线性回归模型的理论基础
例如:
- 身高:由父亲的身高、母亲的身高、家庭收入、所在地区等因素决定
- 房价:由地段、面积、周围配套、时间等因素决定
线性回归要做的是就是找到一个数学公式能相对较完美地把所有自变量组合(加减乘除)起来,得到的结果和目标接近。简单来说,就是选择一条线性函数来很好的拟合已知数据并预测未知数据。
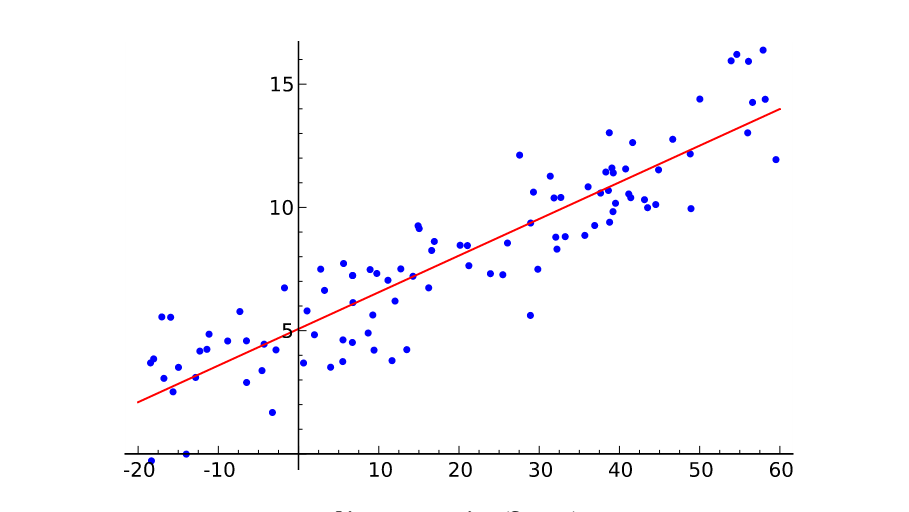
所以线性的定义是:自变量之间只存在线性关系,即自变量只能通过相加、或者相减进行组合
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
1.线性回归的基本形式
给定由 �d 个属性描述的示例x=(x1,x2...xd) 其中 xi 是 x 在第 i 个属性上的取值,线性模型视图学得一个通过属性得线性组合来进行预测的函数,即

![]()

2. 损失函数的选择
我们的目标:模型预测出来的值和真实值无限接近,即 (xi)≈yi,因从需要有一个具体的方法判断这两个值之间的差距到底有多少。
这里给出几种常用的误差判别方法:
2.1.误差平方判别

解释:由于误差有正有负,故使用平方和来抵消正负
问题:
- 使用平方后会放大(差>1)部分的误差,同时缩小(-1<差<1)部分的误差
- 当不同维度之间的度量差异很大时无法处理。例如:衡量一个人有年龄和收入两个维度,两个维度相差100倍以上,模型会严重受到收入大小的影响,要求在建模前对数据进行归一化处理,关于数据归一化、标准化的内容,我们在level2有讲到过。
2.2.欧氏距离判别

问题:
- 带根号,求解麻烦
- 当不同维度之间的度量差异很大时无法处理
2.3.曼哈顿 距离判别

问题:不是连续函数,求导很麻烦,计算不方便,只能计算垂直、水平距离
适用场景:数据稀疏(自带归一化处理)
3. 目标函数
我们这里只考虑一元线性回归的情况
这里使用均方误差MSE来判定距离,并限定损失函数为平方损失函数,也就是普通最小二乘法(Ordinary Least Square,OLS),得到目标函数。其中“二乘”表示取平方,“最小”表示损失函数最小,

我们的目的是确定∗w∗,b∗ 损失函数最小,因此可以建立如下的目标函数:

这里最小二乘法的作用就是使所选择的回归模型应该使所有观察值的残差平方和达到最小,即采用平方损失函数。有兴趣了解为什么误差平方可以表示损失函数以及详细推导过程的同学可以看一下这篇文章 :point_right: 最小二乘法的本质是什么 。
4.求解函数
可以看出最小二乘法得到的cost function是一个凸函数,可以看作一元二次方程,目标是求该方程的最小值,即求一元二次方程导数逼近0的点。介绍两种方法,
- 一种通过矩阵运算得到精确解的方法,
- 另一种在数据量巨大数据情况复杂时使用的逼近最优解的方法:梯度下降法
4.1.SVD分解
最小二乘的超定方程通常可以通过一步解法、SVD分解来求解E(w,b) 是关于 w 和 b 的凸函数,当它关于 w 和 b 的导数均为 0 时,得到 w 和 b 的最优解:

4.2.梯度下降
- 非线性的最小二乘可以通过牛顿高斯迭代、LM算法、梯度下降求解
梯度下降:随机初始化 w 和 b ,通过逼近的方式来求解
梯度下降形象解释: 把损失函数想象成一个山坡,目标是找到山坡最低的点。则随便选一个起点,计算损失函数对于参数矩阵在该点的偏导数,每次往偏导数的反向向走一步,步长通过 α 来控制,直到走到最低点,即导数趋近于0的点为止
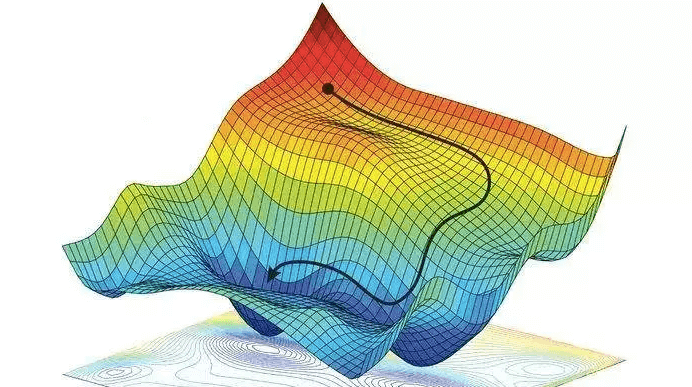

优化方法:

缺点:最小点的时候收敛速度变慢,并且对初始点的选择极为敏感
梯度下降有时会陷入局部最优解的问题中,即下山的路上有好多小坑,运气不好掉进坑里,但是由于底部梯度(导数)也为0,故以为找到了山的底部
同时,步长选择的过大或者过小,都会影响模型的计算精度及计算效率
解决方法:随机梯度下降、批量梯度下降、动量梯度下降
关于梯度下降法的详细理解,可以查看 :point_right: 什么是梯度下降
5.评价指标
模型建好了,我们需要设计相关的指标来检验模型的表现。有人会问,最小二乘法不就是评价指标吗,和这里的评价指标有什么区别?
从概念上讲,两者都是评价指标没什么区别。但是从使用场景上讲,我们在上文提到的最小二乘法,是我们在用训练数据集训练建模时,为了调整模型参数而确定的评价指标,目的是为了优化模型参数。而这里我们要讲的评价指标,是衡量模型建立好以后,使用别的数据集时(测试数据集、真实数据集)这组模型参数的表现效果,目的是为了选择模型参数
这里给出准确定义:评价指标是针对将相同的数据,输入不同的算法模型,或者输入不同参数的同一种算法模型,而给出这个算法或者参数好坏的定量指标
- 均方误差(SSE)
真实值-预测值 然后平方之后求和平均
- 同样的数据集的情况下,SSE越小,误差越小,模型效果越好
- 缺点:SSE数值大小本身没有意义,随着样本增加,SSE必然增加,也就是说,不同的数据集的情况下,SSE比较没有意义

改进:
MSE:对SSE求平均。是线性回归中最常用的损失函数,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较
![]()
2. 均方根误差(标准误差 RMSE)
MSE是用来衡量一组数自身的离散程度,而RMSE是用来衡量观测值同真值之间的偏差,它们的研究对象和研究目的不同。它的意义在于开个根号后,误差的结果就与数据是一个级别的,可以更好地来描述数据。标准误差对一组测量中的特大或特小误差反映非常敏感,所以,标准误差能够很好地反映出测量的精密度。这正是标准误差在工程测量中广泛被采用的原因
当数据集中有一个特别大的异常值,这种情况下,data会被skew,RMSE会被明显拉大。所以对RMSE低估值(under-predicted)的判罚明显小于估值过高(over-predicted)的情况

3. 平均绝对误差(MAE)
平均绝对误差是绝对误差的平均值,平均绝对误差能更好地反映预测值误差的实际情况
MAE是一个线性的指标,所有个体差异在平均值上均等加权,所以它更加凸显出异常值。MSE和MAE适用于误差相对明显的时候,此时大的误差也有比较高的权重

6.API介绍
1. 函数原型及参数说明
这里只挑几个比较重要的参数进行说明。
1class sklearn.linear_model.LinearRegression(*, fit_intercept=True, normalize=False, copy_X=True, n_jobs=None,positive=False)
- fit_intercept:bool, default=True 是否计算截距。默认值 True,计算截距。
- normalize:bool, default=False 是否进行数据标准化,该参数仅在 fit_intercept = True 时有效。
- n_jobs:int, default=None 计算时设置的任务数,为 n>1和大规模问题提供加速。默认值 任务数为 1。
2.LinearRegression() 类的主要属性:
- coef_: 线性系数,即模型参数 w1... 的估计值
- intercept_: 截距,即模型参数 w0 的估计值
3.LinearRegression() 类的主要方法:
- fit(X,y[,sample_weight]):用样本集(X, y)训练模型。sample_weight 为每个样本设权重,默认None。
- get_params([deep]):获取模型参数。注意不是指模型回归系数,而是指fit_intercept,normalize等参数。
- predict(X):用训练的模型预测数据集 X 的输出。即可以对训练样本给出模型输出结果,也可以对测试样本给出预测结果。
- score(X,y[,sample_weight]):R2 判定系数,是常用的模型评价指标。
7.代码示例
7.1.Boston 房价预测
数据集:housing.data
housing.names:
1. Title: Boston Housing Data
2. Sources:
(a) Origin: This dataset was taken from the StatLib library which is
maintained at Carnegie Mellon University.
(b) Creator: Harrison, D. and Rubinfeld, D.L. 'Hedonic prices and the
demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978.
(c) Date: July 7, 1993
3. Past Usage:
- Used in Belsley, Kuh & Welsch, 'Regression diagnostics ...', Wiley,
1980. N.B. Various transformations are used in the table on
pages 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning.
In Proceedings on the Tenth International Conference of Machine
Learning, 236-243, University of Massachusetts, Amherst. Morgan
Kaufmann.
4. Relevant Information:
Concerns housing values in suburbs of Boston.
5. Number of Instances: 506
6. Number of Attributes: 13 continuous attributes (including "class"
attribute "MEDV"), 1 binary-valued attribute.
7. Attribute Information:
1. CRIM per capita crime rate by town
2. ZN proportion of residential land zoned for lots over
25,000 sq.ft.
3. INDUS proportion of non-retail business acres per town
4. CHAS Charles River dummy variable (= 1 if tract bounds
river; 0 otherwise)
5. NOX nitric oxides concentration (parts per 10 million)
6. RM average number of rooms per dwelling
7. AGE proportion of owner-occupied units built prior to 1940
8. DIS weighted distances to five Boston employment centres
9. RAD index of accessibility to radial highways
10. TAX full-value property-tax rate per $10,000
11. PTRATIO pupil-teacher ratio by town
12. B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks
by town
13. LSTAT % lower status of the population
14. MEDV Median value of owner-occupied homes in $1000's
8. Missing Attribute Values: None.
波士顿房价数据集介绍 波士顿房价数据说明:此数据源于美国某经济学杂志上,分析研究波士顿房价( Boston HousePrice)的数据集。数据集中的每一行数据都是对波士顿周边或城镇房价的情况描述。本问题是一个回归问题。每个类的观察值数量是均等的,共有 506 个观察,13 个输入变量和1个输出变量。 数据特征:
- CRIM: 城镇人均犯罪率
- ZN: 住宅用地所占比例
- INDUS: 城镇中非住宅用地所占比例
- CHAS: 虚拟变量,用于回归分析
- NOX: 环保指数
- RM: 每栋住宅的房间数
- AGE: 1940 年以前建成的自住单位的比例
- DIS: 距离 5 个波士顿的就业中心的加权距离
- RAD: 距离高速公路的便利指数
- TAX: 每一万美元的不动产税率
- PTRATIO: 城镇中的教师学生比例
- B: 城镇中的黑人比例
- LSTAT: 地区中有多少房东属于低收入人群
- MEDV: 自住房屋房价中位数(也就是均价)
1.导入包
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import numpy as np2.从网站下载数据集
# 从原始源手动加载波士顿房价数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
x_data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])# 取出所有特征数据,并将其拼接成一个矩阵506*13
y_data = raw_df.values[1::2, 2] # 取出目标数据,即房价数据(需要预测的变量)
# 特征名称
feature_names = [
"CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD",
"TAX", "PTRATIO", "B", "LSTAT"
]
3.特征工程-可视化各个特征与房价的关系
for i in range(13): # 循环13次,对应数据集中的13个特征
plt.subplot(7, 2, i+1) # 创建一个7行2列的子图网格,并指定当前子图的位置为第i+1个
plt.scatter(x_data[:, i], y_data, s=10) # 在当前子图上绘制散点图,x轴是第i个特征的所有数据,y轴是目标数据,点的大小为10
plt.title(feature_names[i]) # 设置当前子图的标题为第i个特征的名称
plt.show() # 显示当前子图
print(feature_names[i], np.corrcoef(x_data[:, i], y_data)) # 打印当前特征的名称和它与目标变量之间的相关系数
for i in range(len(y_data)):
plt.scatter(i,y_data[i],s=10) #横纵坐标和点的大小

4.3、特征工程-处理数据 基于散点图,分析因变量与自变量的相关性,把不相关的数据剔除。经过上面散点图的分析,可以看到数据异常的变量需要特殊处理,根据散点图分析,房屋的’RM(每栋住宅的房间数)’,‘LSTAT(地区中有多少房东属于低收入人群)’,'PTRATIO(城镇中的教师学生比例)’特征与房价的相关性最大,所以,将其余不相关特征剔除。
i_=[] # 初始化一个空列表,用于存储房价等于50的异常值下标
for i in range(len(y_data)): # 遍历目标变量y_data的每一个元素
if y_data[i] == 50: # 如果当前元素的值等于50,认为是异常值
i_.append(i) # 将这个异常值的下标添加到列表i_中
x_data = np.delete(x_data, i_, axis=0) # 从x_data中删除对应下标的行,即删除异常值数据
y_data = np.delete(y_data, i_, axis=0) # 从y_data中删除对应下标的行,即删除异常值
j_=[] # 初始化一个空列表,用于存储次要特征的下标
for i in range(13): # 遍历特征名称列表
if feature_names[i] == 'RM' or feature_names == 'PTRATIO' or feature_names == 'LSTAT': # 如果当前特征是RM、PTRATIO或LSTAT
continue # 跳过这些特征,不将它们的下标添加到列表j_
j_.append(i) # 将其他次要特征的下标添加到列表j_
x_data = np.delete(x_data, j_, axis=1) # 从x_data中删除次要特征,即删除对应的列
print(np.shape(y_data)) # 打印目标变量y_data的形状,即行数和列数
print(np.shape(x_data)) # 打印特征数据x_data的形状,即行数和列数
5.数据分割:数据分割为训练集和测试集
from sklearn.model_selection import train_test_split
# 导入scikit-learn库中的train_test_split函数,用于将数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data, random_state = 0, test_size = 0.20)
# 使用train_test_split函数将x_data和y_data分割成训练集和测试集,设置随机种子为0,测试集大小为原始数据的20%
print(len(X_train)) # 打印训练集特征数据的样本数量
print(len(X_test)) # 打印测试集特征数据的样本数量
print(len(y_train)) # 打印训练集目标数据的样本数量
print(len(y_test)) # 打印测试集目标数据的样本数量
6.数据归一化
from sklearn import preprocessing # 导入预处理模块,用于数据标准化
min_max_scaler = preprocessing.MinMaxScaler(feature_range = (0,1), copy = True)
# 创建一个MinMaxScaler对象,用于将数据缩放到0到1之间,并保留原始数据的副本
X_train = min_max_scaler.fit_transform(X_train)
# 对训练集特征进行拟合和转换,计算训练集的最小值和最大值,并应用这些值进行归一化
X_test = min_max_scaler.transform(X_test)
# 对测试集特征进行转换,使用训练集的最小值和最大值进行归一化()
y_train = min_max_scaler.fit_transform(y_train.reshape(-1,1))
# 将训练集标签转换为二维数组并进行归一化处理,以匹配MinMaxScaler的要求
y_test = min_max_scaler.transform(y_test.reshape(-1,1))
# 将测试集标签转换为二维数组并进行归一化处理,7.模型训练

- 线性回归
from sklearn import linear_model
# 导入scikit-learn库中的线性模型模块,该模块包含了多种线性回归算法
lr = linear_model.LinearRegression()
# 创建一个线性回归模型对象,用于进行线性回归分析
lr.fit(X_train, y_train)
# 使用训练集数据(X_train和y_train)来训练线性回归模型,即找到最佳拟合线
lr_y_predict = lr.predict(X_test)
# 使用训练好的模型对测试集特征X_test进行预测,得到预测的房价lr_y_predict
from sklearn.metrics import r2_score
# 导入scikit-learn库中的metrics模块,该模块包含了用于评估模型性能的多种指标
score_lr = r2_score(y_test, lr_y_predict)
# 使用r2_score函数计算测试集真实房价y_test与预测房价lr_y_predict之间的R^2(决定系数)值,
# R^2值越接近1表示模型的预测效果越好- 岭回归
rr = linear_model.Ridge(alpha=.1)
# 创建一个Ridge回归模型对象,Ridge回归是一种带有L2正则化的线性回归模型,alpha参数是正则化强度的系数
rr.fit(X_train, y_train)
# 使用训练集数据(X_train和y_train)来训练Ridge回归模型
rr_y_predict = rr.predict(X_test)
# 使用训练好的Ridge回归模型对测试集特征X_test进行预测,得到预测结果
score_rr = r2_score(y_test, rr_y_predict)
# 使用r2_score函数计算测试集真实目标值y_test与预测值rr_y_predict之间的R^2(决定系数)值,
# 这是评价模型性能的一个指标,值越接近1表示模型的预测效果越好
score_rr
# 打印出R^2分数的值- Lasso“套索回归”
lassr = linear_model.Lasso(alpha=.0001)
# 创建一个Lasso回归模型对象,Lasso回归是一种带有L1正则化的线性回归模型,alpha参数控制正则化的强度
lassr.fit(X_train, y_train)
# 使用训练集数据(X_train和y_train)来训练Lasso回归模型,即找到最佳拟合参数
lassr_y_predict = lassr.predict(X_test)
# 使用训练好的Lasso回归模型对测试集数据X_test进行预测,得到预测结果
score_lassr = r2_score(y_test, lassr_y_predict)
# 使用r2_score函数计算测试集真实目标值y_test与预测值lassr_y_predict之间的R2(决定系数)值,这是评价模型性能的一个指标
print(score_lassr)
#绘制真实值和预测值对比图
def draw_infer_result(groud_truths,infer_results):
title='Boston'
plt.title(title, fontsize=24)
x = np.arange(-0.2,2)
y = x
plt.plot(x, y)
plt.xlabel('ground truth', fontsize=14)
plt.ylabel('infer result', fontsize=14)
plt.scatter(groud_truths, infer_results,color='green',label='training cost')
plt.grid()
plt.show()
draw_infer_result(y_test, lr_y_predict)
draw_infer_result(y_test, rr_y_predict)
draw_infer_result(y_test, lassr_y_predict)
print("score of 线性回归:", score_lr)
print("score of 岭回归:", score_rr)
print("score of Lasso“套索回归”:", score_lassr)


完整代码:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import numpy as np
# 从原始源手动加载波士顿房价数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
x_data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])# 取出所有特征数据,并将其拼接成一个矩阵506*13
y_data = raw_df.values[1::2, 2] # 取出目标数据,即房价数据(需要预测的变量)
# 特征名称
feature_names = [
"CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD",
"TAX", "PTRATIO", "B", "LSTAT"
]
for i in range(13): # 循环13次,对应数据集中的13个特征
plt.subplot(7, 2, i+1) # 创建一个7行2列的子图网格,并指定当前子图的位置为第i+1个
plt.scatter(x_data[:, i], y_data, s=10) # 在当前子图上绘制散点图,x轴是第i个特征的所有数据,y轴是目标数据,点的大小为10
plt.title(feature_names[i]) # 设置当前子图的标题为第i个特征的名称
plt.show() # 显示当前子图
print(feature_names[i], np.corrcoef(x_data[:, i], y_data)) # 打印当前特征的名称和它与目标变量之间的相关系数
for i in range(len(y_data)):
plt.scatter(i,y_data[i],s=10) #横纵坐标和点的大小
i_=[] # 初始化一个空列表,用于存储房价等于50的异常值下标
for i in range(len(y_data)): # 遍历目标变量y_data的每一个元素
if y_data[i] == 50: # 如果当前元素的值等于50,认为是异常值
i_.append(i) # 将这个异常值的下标添加到列表i_中
x_data = np.delete(x_data, i_, axis=0) # 从x_data中删除对应下标的行,即删除异常值数据
y_data = np.delete(y_data, i_, axis=0) # 从y_data中删除对应下标的行,即删除异常值
j_=[] # 初始化一个空列表,用于存储次要特征的下标
for i in range(13): # 遍历特征名称列表
if feature_names[i] == 'RM' or feature_names == 'PTRATIO' or feature_names == 'LSTAT': # 如果当前特征是RM、PTRATIO或LSTAT
continue # 跳过这些特征,不将它们的下标添加到列表j_
j_.append(i) # 将其他次要特征的下标添加到列表j_
x_data = np.delete(x_data, j_, axis=1) # 从x_data中删除次要特征,即删除对应的列
print(np.shape(y_data)) # 打印目标变量y_data的形状,即行数和列数
print(np.shape(x_data)) # 打印特征数据x_data的形状,即行数和列数
from sklearn.model_selection import train_test_split
# 导入scikit-learn库中的train_test_split函数,用于将数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data, random_state = 0, test_size = 0.20)
# 使用train_test_split函数将x_data和y_data分割成训练集和测试集,设置随机种子为0,测试集大小为原始数据的20%
print(len(X_train)) # 打印训练集特征数据的样本数量
print(len(X_test)) # 打印测试集特征数据的样本数量
print(len(y_train)) # 打印训练集目标数据的样本数量
print(len(y_test)) # 打印测试集目标数据的样本数量
from sklearn import preprocessing # 导入预处理模块,用于数据标准化
min_max_scaler = preprocessing.MinMaxScaler(feature_range = (0,1), copy = True)
# 创建一个MinMaxScaler对象,用于将数据缩放到0到1之间,并保留原始数据的副本
X_train = min_max_scaler.fit_transform(X_train)
# 对训练集特征进行拟合和转换,计算训练集的最小值和最大值,并应用这些值进行归一化
X_test = min_max_scaler.transform(X_test)
# 对测试集特征进行转换,使用训练集的最小值和最大值进行归一化()
y_train = min_max_scaler.fit_transform(y_train.reshape(-1,1))
# 将训练集标签转换为二维数组并进行归一化处理,以匹配MinMaxScaler的要求
y_test = min_max_scaler.transform(y_test.reshape(-1,1))
# 将测试集标签转换为二维数组并进行归一化处理,
from sklearn import linear_model
# 导入scikit-learn库中的线性模型模块,该模块包含了多种线性回归算法
lr = linear_model.LinearRegression()
# 创建一个线性回归模型对象,用于进行线性回归分析
lr.fit(X_train, y_train)
# 使用训练集数据(X_train和y_train)来训练线性回归模型,即找到最佳拟合线
lr_y_predict = lr.predict(X_test)
# 使用训练好的模型对测试集特征X_test进行预测,得到预测的房价lr_y_predict
from sklearn.metrics import r2_score
# 导入scikit-learn库中的metrics模块,该模块包含了用于评估模型性能的多种指标
score_lr = r2_score(y_test, lr_y_predict)
# 使用r2_score函数计算测试集真实房价y_test与预测房价lr_y_predict之间的R^2(决定系数)值,
# R^2值越接近1表示模型的预测效果越好
rr = linear_model.Ridge(alpha=.1)
# 创建一个Ridge回归模型对象,Ridge回归是一种带有L2正则化的线性回归模型,alpha参数是正则化强度的系数
rr.fit(X_train, y_train)
# 使用训练集数据(X_train和y_train)来训练Ridge回归模型
rr_y_predict = rr.predict(X_test)
# 使用训练好的Ridge回归模型对测试集特征X_test进行预测,得到预测结果
score_rr = r2_score(y_test, rr_y_predict)
# 使用r2_score函数计算测试集真实目标值y_test与预测值rr_y_predict之间的R^2(决定系数)值,
# 这是评价模型性能的一个指标,值越接近1表示模型的预测效果越好
score_rr
# 打印出R^2分数的值
lassr = linear_model.Lasso(alpha=.0001)
# 创建一个Lasso回归模型对象,Lasso回归是一种带有L1正则化的线性回归模型,alpha参数控制正则化的强度
lassr.fit(X_train, y_train)
# 使用训练集数据(X_train和y_train)来训练Lasso回归模型,即找到最佳拟合参数
lassr_y_predict = lassr.predict(X_test)
# 使用训练好的Lasso回归模型对测试集数据X_test进行预测,得到预测结果
score_lassr = r2_score(y_test, lassr_y_predict)
# 使用r2_score函数计算测试集真实目标值y_test与预测值lassr_y_predict之间的R2(决定系数)值,这是评价模型性能的一个指标
print(score_lassr)
#绘制真实值和预测值对比图
def draw_infer_result(groud_truths,infer_results):
title='Boston'
plt.title(title, fontsize=24)
x = np.arange(-0.2,2)
y = x
plt.plot(x, y)
plt.xlabel('ground truth', fontsize=14)
plt.ylabel('infer result', fontsize=14)
plt.scatter(groud_truths, infer_results,color='green',label='training cost')
plt.grid()
plt.show()
draw_infer_result(y_test, lr_y_predict)
draw_infer_result(y_test, rr_y_predict)
draw_infer_result(y_test, lassr_y_predict)
print("score of 线性回归:", score_lr)
print("score of 岭回归:", score_rr)
print("score of Lasso“套索回归”:", score_lassr)7.2.PM2.5预测
数据集介绍
- 本次作业使用丰原站的观测记录,分成 train set 跟 test set,train set 是丰原站每个月的前 20 天所有资料。test set 则是从丰原站剩下的资料中取样出来。
- train.csv: 每个月前 20 天的完整资料。
- test.csv : 从剩下的资料当中取样出连续的 10 小时为一笔,前九小时的所有观测数据当作 feature,第十小时的 PM2.5 当作 answer。一共取出 240 笔不重複的 test data,请根据 feature 预测这 240 笔的 PM2.5。
- Data 含有 18 项观测数据 AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR。
1.数据分析
import os
import pandas as pd
import numpy as np
# 1.读取数据
data=pd.read_csv(r"C:\pythonProject\机器学习\回归算法\线性回归\PM2.5\train.csv", encoding="big5")
print(data.head(20))
print(data.info())
print(data.describe())
2. 特征提取
# rainfall补零,截取第四列一直到结束
data=data.iloc[:,3:] # 解析:选择DataFrame的第四列到最后一列的数据
data[data=='NR']=0 # 解析:将数据中所有的'NR'替换为0
numpy_data=data.to_numpy() # 解析:将DataFrame转换为NumPy数组
# 可见雨全0
data.head(18) # 解析:显示数据的前18行,用于检查数据
data.info() # 解析:显示数据的概览信息,包括行数、列数和非空值的数量
# RangeIndex: 4320 entries, 0 to 4319 24列(小时),18个特征
# 4320 18= 12月 18 480每月小时数...os
month_data={} # 解析:初始化一个字典,用于存储按月分组的数据
for month in range(12): # 解析:遍历每个月
# 每月数据量
sample=np.empty([18,480]) # 解析:创建一个18行480列的空数组,用于存储每个月的数据
# 每天数据量
for day in range(20): # 解析:遍历每个月的20天
# 每天24小时,对应这个18个*24小时个数据
sample[:, day*24:(day+1)*24]=numpy_data[18*(20*month +day): 18*(20*month +day+1),:] # 解析:将每天的数据填充到sample数组中
month_data[month]=sample # 解析:将每个月的数据存储到字典中
3.数据分析
test.csv : 从剩下的资料当中取样出连续的 10 小时为一笔,前九小时的所有观测数据当作 feature,第十小时的 PM2.5 当作 answer。一共取出 240 笔不重複的 test data,请根据 feature 预测这 240 笔的 PM2.5。
- 每个月480小时,9小时一个data,总计480-9-471小时。年度471*12个
- 每个data有9*18个特征
# 数据
x=np.empty([12*471,18*9],dtype=float)
# pm2.5
y=np.empty([12*471,1],dtype=float)
for month in range(12):
for day in range(20):
for hour in range(24):
# 如果是最后一天,最后一个包结束,则返回
if day==19 and hour>14:
continue
# 每个小时的18项数据
x[month*471+day*24+hour,:]=month_data[month][:,day*24+hour:day*24+hour+9].reshape(1,-1)
# pm值
y[month*471+day*24+hour,0]=month_data[month][9,day*24+hour+9]
print(x)
print(y)
#归一化
mean_x = np.mean(x, axis = 0) #18 * 9
std_x = np.std(x, axis = 0) #18 * 9
for i in range(len(x)): #12 * 471
for j in range(len(x[0])): #18 * 9
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
x
4.模型训练


# 2.模型训练
# 1为常数项
dim = x.shape[1] + 1 # 解析:计算特征维度加1(常数项)
w = np.zeros(shape=(dim, 1)) # 解析:初始化权重数组w,维度为(dim, 1),所有元素为0
# 将常数项1添加到特征矩阵x的第一列
x = np.concatenate((np.ones((x.shape[0], 1)), x), axis=1).astype(float) # 解析:在x的第一列添加全1的列,然后转换为浮点数
learning_rate = np.array([[2000]] * dim) # 解析:初始化学习率数组,每个维度相同
iter_time = 10001 # 解析:设置迭代次数
adagrad = np.zeros(shape=(dim, 1)) # 解析:初始化Adagrad的累加平方梯度
# 防止被除数为0
eps = 0.0005 # 解析:设置一个很小的数,防止分母为0
# 开始迭代
for t in range(iter_time): # 解析:进行iter_time次迭代
if t % 500 == 0: # 解析:每500次迭代打印一次信息
print("迭代次数:", t) # 解析:打印当前迭代次数
loss = np.sum((x.dot(w) - y) ** 2) / x.shape[0] / 2 # 解析:计算损失值(均方误差)
print("损失值:", loss) # 解析:打印损失值
# 每100次输出一次
print((x.dot(w) - y) ** 2) # 解析:打印预测值与真实值之间的平方差
# 计算梯度
gradient = 2 * np.transpose(x).dot(x.dot(w) - y) # 解析:计算梯度
adagrad += gradient ** 2 # 解析:更新Adagrad累加平方梯度
w = w - learning_rate * gradient / (np.sqrt(adagrad) + eps) # 解析:更新权重w
# 保存权重
np.save('weight.npy', w) # 解析:将权重数组w保存到文件weight.npy中
# 输出最终的权重
print(w) # 解析:打印最终的权重数组
5.测试
test_data=pd.read_csv(r"C:\pythonProject\机器学习\回归算法\线性回归\PM2.5\test.csv",header=None, encoding="big5")
test_data.head()
test_data=test_data.iloc[:,2:] # 解析:选择DataFrame的第3列到最后一列的数据
test_data.head(18) # 解析:显示数据的前18行,用于检查数据
test_data[test_data == 'NR'] = 0
test_data=test_data.to_numpy()
# 240个记录,18*9
test_x=np.empty([240,18*9], dtype=float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)
# 归一化
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
test_x6.预测
w=np.load("weight.npy") # 加载名为"weight.npy"的权重文件到变量w中
ans_y=np.dot(test_x,w) # 使用点乘操作计算测试数据test_x和权重w的乘积,结果存储在ans_y中
import csv # 导入csv模块,用于处理CSV文件
with open("submit.csv", mode="w",newline='') as submit_file: # 打开(或创建)名为"submit.csv"的文件,以写入模式,并设置newline=''以避免额外的空行
csv_writer=csv.writer(submit_file) # 创建一个CSV写入器对象
header=['id','value'] # 定义CSV文件的头部
csv_writer.writerow(header) # 写入头部到CSV文件
for i in range(240): # 循环240次,假设我们只需要写入240行数据
row=["id_" +str (i), ans_y[i][0]] # 创建一个列表row,包含id和ans_y中对应行的第一个元素
csv_writer.writerow(row) # 将row写入到CSV文件的一行
print(row) # 打印row,显示在控制台

完整代码:
import os
import pandas as pd
import numpy as np
# 1.读取数据
data=pd.read_csv(r"C:\pythonProject\机器学习\回归算法\线性回归\PM2.5\train.csv", encoding="big5")
print(data.head(20))
print(data.info())
print(data.describe())
# rainfall补零,截取第四列一直到结束
data=data.iloc[:,3:] # 解析:选择DataFrame的第四列到最后一列的数据
data[data=='NR']=0 # 解析:将数据中所有的'NR'替换为0
numpy_data=data.to_numpy() # 解析:将DataFrame转换为NumPy数组
# 可见雨全0
data.head(18) # 解析:显示数据的前18行,用于检查数据
data.info() # 解析:显示数据的概览信息,包括行数、列数和非空值的数量
# RangeIndex: 4320 entries, 0 to 4319 24列(小时),18个特征
# 4320 18= 12月 18 480每月小时数...os
month_data={} # 解析:初始化一个字典,用于存储按月分组的数据
for month in range(12): # 解析:遍历每个月
# 每月数据量
sample=np.empty([18,480]) # 解析:创建一个18行480列的空数组,用于存储每个月的数据
# 每天数据量
for day in range(20): # 解析:遍历每个月的20天
# 每天24小时,对应这个18个*24小时个数据
sample[:, day*24:(day+1)*24]=numpy_data[18*(20*month +day): 18*(20*month +day+1),:] # 解析:将每天的数据填充到sample数组中
month_data[month]=sample # 解析:将每个月的数据存储到字典中
# 数据
x=np.empty([12*471,18*9],dtype=float)
# pm2.5
y=np.empty([12*471,1],dtype=float)
for month in range(12):
for day in range(20):
for hour in range(24):
# 如果是最后一天,最后一个包结束,则返回
if day==19 and hour>14:
continue
# 每个小时的18项数据
x[month*471+day*24+hour,:]=month_data[month][:,day*24+hour:day*24+hour+9].reshape(1,-1)
# pm值
y[month*471+day*24+hour,0]=month_data[month][9,day*24+hour+9]
print(x)
print(y)
#归一化
mean_x = np.mean(x, axis = 0) #18 * 9
std_x = np.std(x, axis = 0) #18 * 9
for i in range(len(x)): #12 * 471
for j in range(len(x[0])): #18 * 9
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
x
import math
x_train_set = x[: math.floor(len(x) * 0.8), :]
y_train_set = y[: math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8): , :]
y_validation = y[math.floor(len(y) * 0.8): , :]
print(x_train_set)
print(y_train_set)
print(x_validation)
print(y_validation)
print(len(x_train_set))
print(len(y_train_set))
print(len(x_validation))
print(len(y_validation))
# 2.模型训练
# 1为常数项
dim = x.shape[1] + 1 # 解析:计算特征维度加1(常数项)
w = np.zeros(shape=(dim, 1)) # 解析:初始化权重数组w,维度为(dim, 1),所有元素为0
# 将常数项1添加到特征矩阵x的第一列
x = np.concatenate((np.ones((x.shape[0], 1)), x), axis=1).astype(float) # 解析:在x的第一列添加全1的列,然后转换为浮点数
learning_rate = np.array([[2000]] * dim) # 解析:初始化学习率数组,每个维度相同
iter_time = 10001 # 解析:设置迭代次数
adagrad = np.zeros(shape=(dim, 1)) # 解析:初始化Adagrad的累加平方梯度
# 防止被除数为0
eps = 0.0005 # 解析:设置一个很小的数,防止分母为0
# 开始迭代
for t in range(iter_time): # 解析:进行iter_time次迭代
if t % 500 == 0: # 解析:每500次迭代打印一次信息
print("迭代次数:", t) # 解析:打印当前迭代次数
loss = np.sum((x.dot(w) - y) ** 2) / x.shape[0] / 2 # 解析:计算损失值(均方误差)
print("损失值:", loss) # 解析:打印损失值
# 每100次输出一次
print((x.dot(w) - y) ** 2) # 解析:打印预测值与真实值之间的平方差
# 计算梯度
gradient = 2 * np.transpose(x).dot(x.dot(w) - y) # 解析:计算梯度
adagrad += gradient ** 2 # 解析:更新Adagrad累加平方梯度
w = w - learning_rate * gradient / (np.sqrt(adagrad) + eps) # 解析:更新权重w
# 保存权重
np.save('weight.npy', w) # 解析:将权重数组w保存到文件weight.npy中
# 输出最终的权重
print(w) # 解析:打印最终的权重数组
test_data=pd.read_csv(r"C:\pythonProject\机器学习\回归算法\线性回归\PM2.5\test.csv",header=None, encoding="big5")
test_data.head()
test_data=test_data.iloc[:,2:] # 解析:选择DataFrame的第3列到最后一列的数据
test_data.head(18) # 解析:显示数据的前18行,用于检查数据
test_data[test_data == 'NR'] = 0
test_data=test_data.to_numpy()
# 240个记录,18*9
test_x=np.empty([240,18*9], dtype=float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)
# 归一化
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
test_x
w=np.load("weight.npy") # 加载名为"weight.npy"的权重文件到变量w中
ans_y=np.dot(test_x,w) # 使用点乘操作计算测试数据test_x和权重w的乘积,结果存储在ans_y中
import csv # 导入csv模块,用于处理CSV文件
with open("submit.csv", mode="w",newline='') as submit_file:
# 打开(或创建)名为"submit.csv"的文件,以写入模式,并设置newline=''以避免额外的空行
csv_writer=csv.writer(submit_file) # 创建一个CSV写入器对象
header=['id','value'] # 定义CSV文件的头部
csv_writer.writerow(header) # 写入头部到CSV文件
for i in range(240): # 循环240次,假设我们只需要写入240行数据
row=["id_" +str (i), ans_y[i][0]] # 创建一个列表row,包含id和ans_y中对应行的第一个元素
csv_writer.writerow(row) # 将row写入到CSV文件的一行
print(row) # 打印row,显示在控制台