前言
这篇文章用来验证多层感知机在复杂图像任务猫狗分类中的性能表现。因此这次使用与《多层感知机(MLP)实战教程:使用PyTorch实现-CSDN博客》这篇文章相同的网络结构进行实验,并继续使用FunHPC | 算力简单易用 AI乐趣丛生这个平台提供的免费P4显卡进行实验,具体过程详见以上文章。
一、实验基础
1、运行环境:

2、数据来源:
https://www.microsoft.com/en-us/download/details.aspx?id=54765
3、数据介绍:
这个数据集包含了从Petfinder.com收集的大量猫和狗的图片,这些图片由美国各地的动物收容所的工作人员手动分类。
数据集的目的是用于图像识别任务,特别是用于训练机器学习模型来区分猫和狗的图片。这个数据集常用于图像分类、物体识别和深度学习领域的研究和竞赛。
数据集的特点包括:
- 大规模:数据集包含超过三万张图片。
- 高质量:图片由人工分类,确保了数据的准确性。
- 多样性:图片包括不同品种、不同年龄和不同姿态的猫和狗。
- 研究价值:数据集不仅用于竞赛,也用于学术研究。
二、实验过程:
1、数据划分:
通过以下代码,将数据集按照8:2的比例进行划分。
import os,shutil
def mymovefile(srcfile,dstfile):
if not os.path.isfile(srcfile):
print("src not exist!")
else:
fpath,fname=os.path.split(dstfile) #分离文件名和路径
if not os.path.exists(fpath):
os.makedirs(fpath) #创建路径
shutil.move(srcfile,dstfile) #移动文件
test_rate=0.2#训练集和测试集的比例为8:2。
img_num=12500
test_num=int(img_num*test_rate)
import random
test_index = random.sample(range(0, img_num), test_num)
file_path="./PetImages"
tr="train"
te="test"
cat="Cat"
dog="Dog"
#将上述index中的文件都移动到/test/Cat/和/test/Dog/下面去。
for i in range(len(test_index)):
#移动猫
srcfile=os.path.join(file_path,tr,cat,str(test_index[i])+".jpg")
dstfile=os.path.join(file_path,te,cat,str(test_index[i])+".jpg")
mymovefile(srcfile,dstfile)
#移动狗
srcfile=os.path.join(file_path,tr,dog,str(test_index[i])+".jpg")
dstfile=os.path.join(file_path,te,dog,str(test_index[i])+".jpg")
mymovefile(srcfile,dstfile)在执行这段代码之后,目录结构将如下所示:
PetImages/
├── train/
│ ├── Cat/
│ │ ├── (剩余未被选为测试集的猫的图片)
│ ├── Dog/
│ │ ├── (剩余未被选为测试集的狗的图片)
├── test/
├── Cat/
│ ├── (被选为测试集的猫的图片)
└── Dog/
├── (被选为测试集的狗的图片)2、数据加载:
# 使用cuda
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
# 超参数设置
batch_size_train = 128
batch_size_test = 1000
epochs = 50
num_workers=32
# 加载数据
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
transforms.Resize((150, 150))
]
)
file_path='./PetImages'
train_data = datasets.ImageFolder(os.path.join(file_path,'train'), transforms)
trainloader = torch.utils.data.DataLoader(train_data,batch_size=batch_size_train,shuffle=True, num_workers=num_workers)
test_data=datasets.ImageFolder(os.path.join(file_path,'test'), transforms)
testloader = torch.utils.data.DataLoader(test_data,batch_size=batch_size_test,shuffle=False, num_workers=num_workers)
# 定义MLP模型1.超参数
batch_size_train: 训练时每个批次的样本数量。较小的批次大小可能导致训练时间更长,但有助于模型更好地泛化。较大的批次大小可以加快训练速度,但可能需要更多的内存,并且有时会影响模型的泛化能力。batch_size_test: 测试时每个批次的样本数量。通常,测试时批次大小可以更大,因为测试阶段不需要进行反向传播和参数更新。epochs: 训练周期的总数。一个epoch意味着整个训练集被遍历一次。通常需要多个epoch来训练模型,直到它在验证集上的性能不再显著提高。num_workers: 加载数据时使用的子进程数。增加子进程数可以加快数据加载速度,但也可能增加内存使用量。设置为32意味着有32个子进程同时工作来加载数据。
2. 数据预处理参数
transforms.Compose: 这是一个PyTorch的transforms工具,它允许你将多个图像预处理操作组合成一个管道。这里的操作包括:transforms.ToTensor(): 将PIL图像或NumPy数组转换为FloatTensor,并缩放像素值到[0, 1]。transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]): 对图像进行标准化。这里的均值和标准差是针对ImageNet数据集预先计算的,它们用于将图像数据调整到一个标准范围内,有助于加速模型的收敛。其中mean和std均是三个值,这是因为猫狗图像是一个RGB三通道数据。transforms.Resize((150, 150)): 将图像的大小调整为150x150像素。这是为了确保所有输入图像具有相同的尺寸,因为神经网络需要固定大小的输入。
3. 数据加载器参数
train_data和test_data: 使用datasets.ImageFolder加载训练和测试数据集。这个函数期望数据集是按类别组织的,每个类别的图像存储在单独的文件夹中。trainloader和testloader: 使用torch.utils.data.DataLoader创建数据加载器。这些加载器在训练和测试过程中批量加载数据。batch_size: 每个批次的样本数量,与之前定义的batch_size_train和batch_size_test相对应。shuffle=True: 在训练数据加载器中设置为True,意味着每个epoch开始时,数据会被随机打乱。这有助于模型学习到更一般化的特征,而不是记住特定顺序的样本。shuffle=False: 在测试数据加载器中设置为False,意味着测试数据按顺序加载,不进行打乱。num_workers: 与之前定义的num_workers相同,用于指定加载数据时使用的子进程数。这个参数在可以适当的调整,在计算资源充足的情况下(cpu、内存、显存),适当调大会加速训练。
3、模型构建:
# 定义MLP模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(150 * 150*3, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = x.view(-1, 150 * 150*3)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x在模型上,只是将多层感知机的输入层的特征数量改为了(150*150*3),正好对应了transforms.Resize((150, 150))设置图像尺寸这部分以及图像数据是一个三通道数据,其他的并没有改变。
4、模型训练与测试:
# 初始化模型、损失函数、优化器
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 评估模型
def evaluate_model(model, testloader, criterion):
model.eval()
test_loss = 0
correct = 0
total = 0
all_labels = []
all_predictions = []
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
all_labels.extend(labels.cpu().numpy())
all_predictions.extend(predicted.cpu().numpy())
accuracy = correct / total
average_loss = test_loss / len(testloader)
return average_loss, accuracy, all_labels, all_predictions
# 训练模型
import time
import torch
# 训练模型
def train_model(model, trainloader, testloader, criterion, optimizer, epochs=5, log_interval=10):
train_losses = []
test_losses = []
test_accuracies = []
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
start_time = time.time()
for batch_idx, (images, labels) in enumerate(trainloader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
# 每 log_interval 批次打印一次信息
if batch_idx % log_interval == 0:
batch_loss = running_loss / (batch_idx + 1)
accuracy = 100. * correct / total
batch_time = time.time() - start_time
print(f'Epoch {epoch+1}/{epochs} [{batch_idx * len(images)}/{len(trainloader.dataset)} '
f'({100. * batch_idx / len(trainloader):.0f}%)]\t'
f'Loss: {batch_loss:.4f}\tAccuracy: {accuracy:.2f}%\tTime: {batch_time:.2f}s')
start_time = time.time() # 重置计时器
# 计算训练集的平均损失
train_loss = running_loss / len(trainloader)
train_losses.append(train_loss)
# 每个epoch后评估模型在测试集上的表现
test_loss, accuracy, _, _ = evaluate_model(model, testloader, criterion)
test_losses.append(test_loss)
test_accuracies.append(accuracy)
print(f"Epoch {epoch+1} completed. Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.4f}\n")
# 保存模型参数
torch.save(model.state_dict(), f'model_epoch_{epoch+1}.pth')
print(f'Model parameters saved for epoch {epoch+1}.')
# 绘制学习曲线并保存
plt.figure()
plt.plot(train_losses, label='Train Loss')
plt.plot(test_losses, label='Test Loss')
plt.title('Learning Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.savefig("learning_curve.png")
plt.close()
return train_losses, test_losses, test_accuracies
# 绘制混淆矩阵
def plot_confusion_matrix(true_labels, predictions):
cm = confusion_matrix(true_labels, predictions)
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.savefig("confusion_matrix.png")
plt.close()
# 绘制ROC曲线
def plot_roc_curve(true_labels, predictions):
fpr = {}
tpr = {}
roc_auc = {}
true_labels = np.array(true_labels)
predictions = np.array(predictions)
for i in range(2):
true_binary = (true_labels == i).astype(int)
pred_probs = (predictions == i).astype(int)
fpr[i], tpr[i], _ = roc_curve(true_binary, pred_probs)
roc_auc[i] = auc(fpr[i], tpr[i])
plt.figure()
for i in range(2):
plt.plot(fpr[i], tpr[i], label=f'Class {i} (AUC = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--')
plt.title('ROC Curve for Each Class')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.savefig("roc_curve.png")
plt.close()
# 训练并评估模型
train_losses, test_losses, test_accuracies = train_model(model, trainloader, testloader, criterion, optimizer, epochs=epochs)
# 评估并绘制混淆矩阵与ROC曲线
_, _, true_labels, predictions = evaluate_model(model, testloader, criterion)
plot_confusion_matrix(true_labels, predictions)
plot_roc_curve(true_labels, predictions)这部分代码,包含了模型初始化、损失函数和优化器设置。以及模型训练函数、模型测试函数、模型一些评估指标的可视化函数。这部分代码与之前不同的地方是,增加了模型保存的代码,是每迭代一次就保存一次模型参数,模型参数的大小是32.9M:
# 保存模型参数
torch.save(model.state_dict(), f'model_epoch_{epoch+1}.pth')
三、实验结果分析:
单从下图的损失变化折线图中可以发现,在五个迭代中,训练损失减少的还是很快的,测试损失在第二次迭代后就没有太大变化。相比手写数字任务来说,明显可以看出多层感知机在更加复杂的任务上有点吃力。


从

从混淆矩阵上也可以发现,测试效果并不是很理想,但肯定是要比瞎蒙50%的准确率是要高的。
虽然数据集不同,没有一定的可比性,但是猫狗数据集的量比手写数字数据集大呀。在这样的情况下,相同的迭代次数,模型在猫狗数据集上的表现还远远不如手写数字。难道是迭代次数不够,大数据集需要更多的迭代次数?
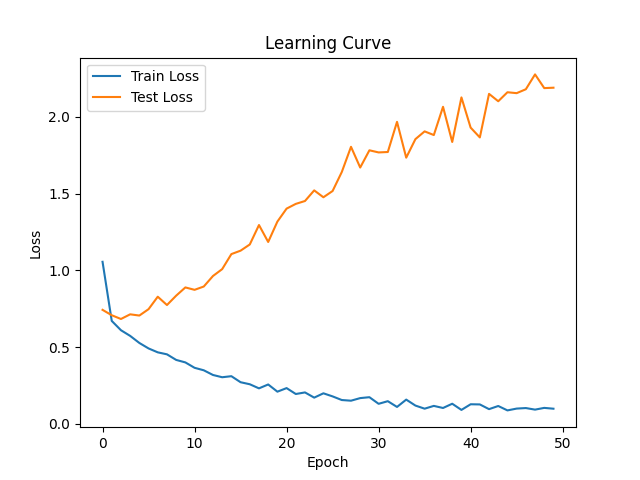
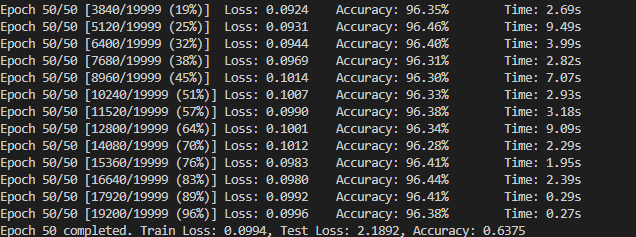
带着这样的疑问,我又训练了50次,结果如下。可以发现模型在训练集中的损失是一直在降的,但是在测试集上的损失不降反升。另外,在精度上,虽然训练精度已经达到90%以上,但是测试精度依然是63%。
这不就是妥妥的过拟合了嘛!!
其实到这里足以说明一件事,模型结构足以决定模型的性能上限,这个上限不是可以通过扩大数据集或者增加训练迭代次数可以弥补的。想要让模型在更加复杂的任务上表现更好,就需要改变模型的构造。
四、总结
这个实验清楚地证明了一个关键的观点:模型结构对于其性能至关重要。而这也说明了卷积神经网路的必要性!