趁热打铁,上一篇总结了高效微调PEFT的主要方法,这一篇实践一下LLama使用Lora进行微调,包含保姆级的详细步骤和各种坑的总结。本文的背景是刚好结合我工作需要微调一下LLama作为翻译工具使用。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
本文前提需要你知道微调模型的基本原理。
一、方案选择
原始LLama模型+开源Lora代码微调
Huggingface格式LLama模型+Huggingface Lora代码微调
国内已实现的LLama中文微调后的模型进行微调
国内外使用Huggingface模型格式和其配套的通用代码进行微调是主流,且使用方便,这次想从最基本的模型开始,所以选择了方案2,等基本方案摸索清楚后再使用国内大家用中文微调后的模型,比如流行的Chinese-LLaMA-Alpaca-2、Llama2-Chinese等。
二、环境准备
GPU服务器:RTX 3090,24G双GPU,cuda11
Python: 3.11
安装的python包,主要包括:torch 1.19,transformers(huggingface开发),peft(huggingface开发),trl以及其他安装时依赖自动安装的包,基本上就是运行时提示缺啥就装啥,版本不对就改。
三、模型准备
现在大家比较头疼的问题之一是需要科学上网下载国外的模型,否则meta网站访问不了下不了LLama,huggingface从今年9月份开始也访问不了。
LLama模型主要有两种方式下载,都需要提前在meta网站申请一个唯一码,然后使用这个唯一码:一是直接从meta公司网站下载原始格式模型,二是可以从huggingface网站下载huggfaceing格式的模型。具体如何下载网上已经有很多资料,不再赘述。
我之前已经下载了原始格式的模型llama-2-7b,即70亿参数的模型版本,刚好想试试从原始格式一步一步操作,微调使用huggingface的代码,所以执行路径是:原始格式LLama ->转为huggingface格式->使用huggingface代码微调。
原始模型包括文件如下:

四、Huggingface格式模型转换
首先从github克隆下载huggingface的transformers代码,https://github.com/huggingface/transformers,准备好LLama原始模型目录,使用transformers里面的代码执行下面命令:

其中,/tmp/llama-2-7b是原始模型目录,/tmp/llama-2-7b-hf是转换为huggingface格式后要保存的目录。
遇到的坑:原始模型目录结构不对,没转换成功。
解决方法:目录里需要包括tokenizer模型,要么和LLama模型文件放一起,要么把模型文件放在和tokenizer同级的名叫7B的文件夹中,这是转换代码逻辑规定的:

或者
转换完后llama-2-7b-hf中内容如下:
五、小试牛刀
在做微调之前,我们先试试如何使用原始模型进行推理,看看模型的威力,毕竟最终目的都是要使用模型,并且微调前后需要比较模型的输出有什么不一样。
运行原始模型,需要到github克隆下载LLama2代码,其中有两个示例脚本:

第一个是用于对话的例子,第二个是处理文本的,为了方便截图小点,我们以处理文本为例,删掉一部分例子后脚本主要内容如下:
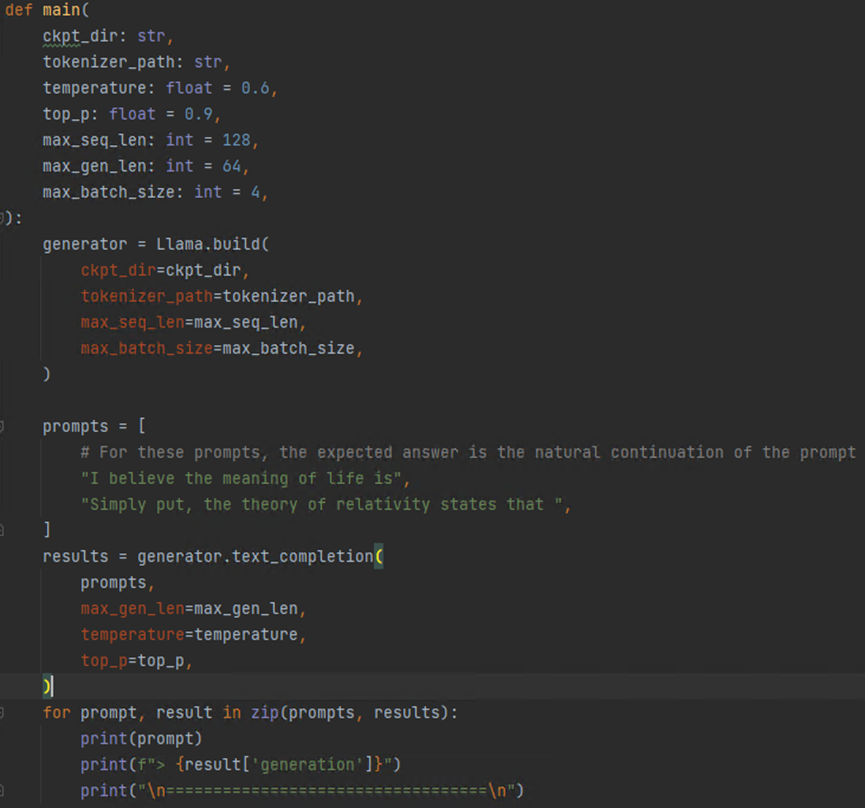
主要就是给两个输入,看看LLama能输出什么内容,就好比在ChatGPT网站输入一些问题,看看能给你输出啥。运行下面命令即可:

输出如下:

模型输出了一些有意思的内容。
六、微调场景和数据准备
本次微调是有实际需求的,我需要一个中英翻译功能API,但是目前商用的翻译API只有少量免费试用词条数,超过条数都是要收费的,那我们就用大模型试试吧。但LLama基座模型绝大多数训练数据都是英文的,对中文效果并不好,所以需要使用中文数据进行微调。
LLama等类似的大模型都是使用无监督学习方法,从句子上一个字预测下一个,所以不需要标签。训练和微调的数据根据你的具体任务构造数据格式就好了,就是大家经常说的提示prompt模板格式。
对于我的翻译任务,我构造的prompt格式如下:
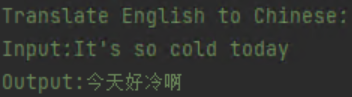
其中,“Translate English to Chinese”是指令要求,Input是输入,Output是输出。我希望在基座模型基础上,使用这个格式的中英和英中数据微调模型,使得微调后的模型在我给“Translate English to Chinese”指令和任意一句英语后,能给我输出中文,或者相反的从中文翻译为英文。
所以我需要从网上找“中-英”对照的数据,整理好后,代码上可以定义一个python list,按照prompt格式加到list中,训练数据样例如下:

然后定义训练和验证集Dataset如下:
![]()
一会儿直接用这个Dataset就好了。
七、核心登场--微调代码
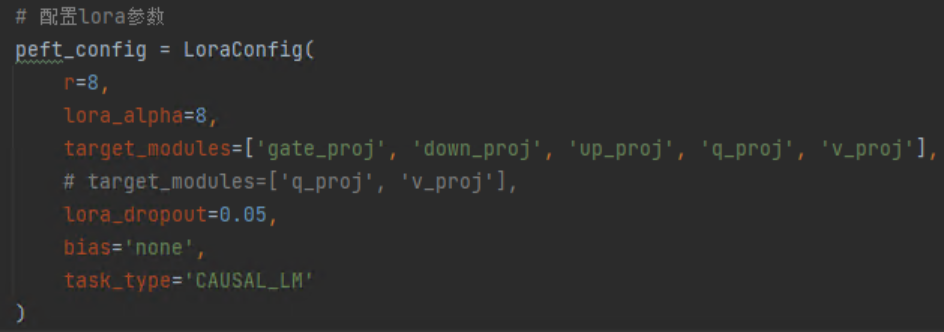
主要包括Lora参数配置,训练参数配置。

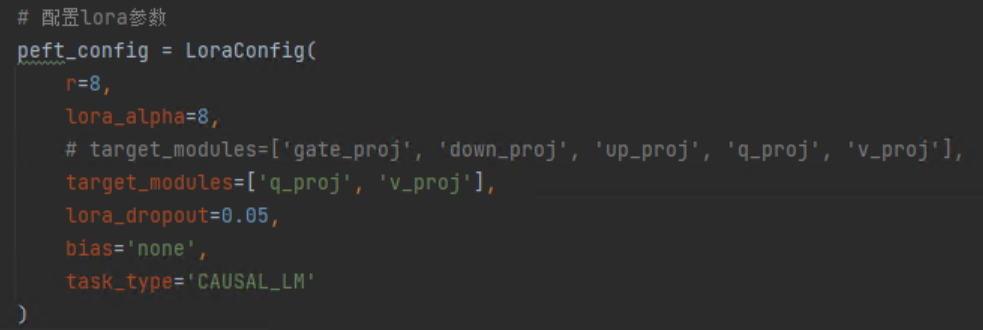
Lora参数的理解需要之前学习的Lora原理知识,r是缩放矩阵的秩,target_modules是要微调的目标模块,Lora论文中实验发现只微调attention中Q和V参数效果就不错了,此时target_modules=['q_proj','v_proj']就行,代码会根据模型中层的名称去查找。
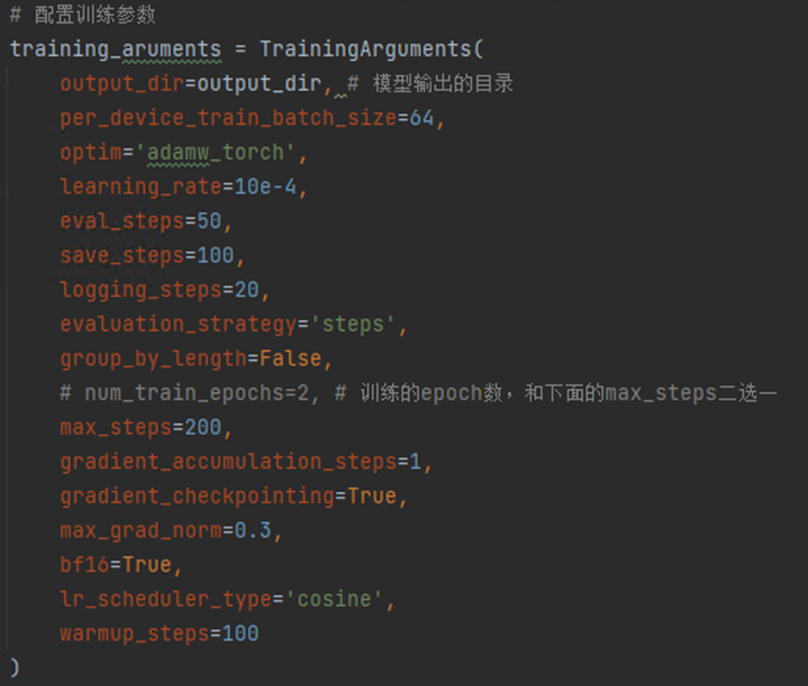
训练参数配置,参数名称一目了然,没有太多需要解释的,各种batch_size,训练中评估、保存、log等操作的步数,这些都是模型训练的常规参数。
遇到的坑:
![]()
解决方法:没有找到需要进行梯度下降更新的参数,加上下面两行中的任意一行即可。

下面代码定义trainer并开始训练:
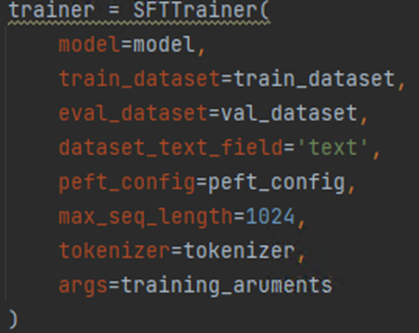

其中的train_dataset,val_dataset就是上面准备的数据集,dataset_text_field=‘text’是数据集字典中的key,代码会自动去找key为‘text’的数据。
八、执行微调训练
运行第七节定义的代码,先以训练200步为例,输出如下:

中间的红框关键部分,可以看到整个模型67亿参数,需要更新的参数只有400万,只占0.06%,这就是所谓高效微调,只调0.06%的参数。
如果需要微调的target_modules增加一些:
微调参数比例就上升到了0.23%。
![]()
使用0.06%的比例,我两张24G的GPU运行200步花了38分钟,每步只有64条数据,相当慢。

由于我设置的每100步保存一下模型,输出目录包含每100步的checkpoint和最后的模型微调参数的权重,才16M大小。

一些细节,我原本准备了近2000万条微调数据,batch_size设为1024,直接就Cuda Out of Memory了。后来改为200万数据,batch_size=64,GPU占用如上,勉强能跑起来。
九、权重合并和模型预测
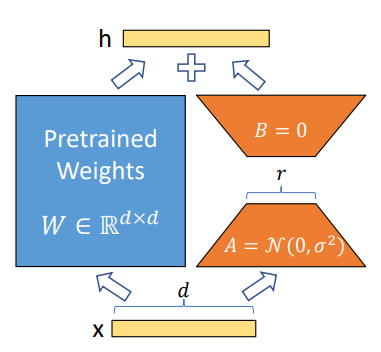
第八节保存的只是微调参数的权重,最终使用需要和基座模型参数合并,回顾一下Lora就是:

![]()
,需要和
![]()
合并,保存为新的模型版本,代码如下:

合并后保存目录如下:

十、检验效果
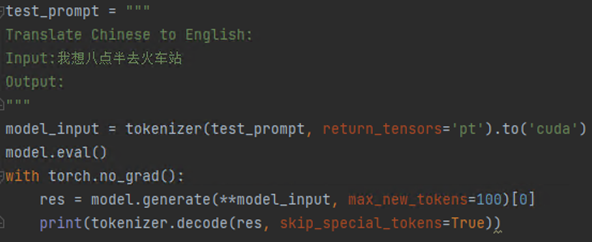
为了检验我们的微调起没起作用,先用基本模型预测一下我们要求的prompt格式的效果,使用同样的输入:
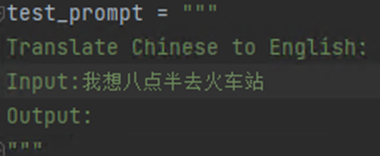
LLama基座模型输出如下,它不太认识这个prompt,有点像把整个输入的内容翻译了,格式有点问题,翻译也不太准确:

微调后模型的输出结果如下,显然它认识了这个prompt格式,输出格式是正确的,并且翻译得更准:

再试一个英文翻译中文的例子,因为我的微调语料既包含了中翻英,又包含了英翻中:

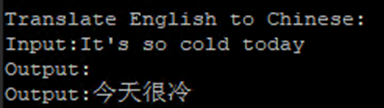
看起来效果不错。
当然,并不是说基座模型没有翻译能力,输入一些别的prompt格式,基座模型是可以翻译的,只是翻译中文不是它的强项,上面实验我的侧重点也是为了验证微调是起了作用的,并且只训练了200步,共见了200*64=12800条数据,效果还是很明显。
本文完整实验了一把从原始LLama模型用Lora微调的过程,为了最终模型能在实际生产环境用起来,还需要加更多的数据、训练更长的时间,并且还需要研究加速模型训练的方法,继续探索!