通义大模型开源发布 LHM 可驱动 3D数字人生成模型,可单图秒级生成超写实3D数字人,基于生成的3D数字人搭建了完整的实时交互对话工程链路,包括LLM、ASR、TTS和数字人模块,即输入一张图片、即可与这张图片所生成的数字人化身进行低延迟的实时对话,应用于客服、教育、陪伴等场景。
LHM是一个单视角输入、端到端的Transformer模型,依赖于人体先验模型SMPL-X进行驱动,最终输出一个可驱动的高斯3D人体模型。你可以把LHM看作一个“魔法工具”,它能帮你用一张照片快速生成一个可以在电脑里动起来的3D数字人。
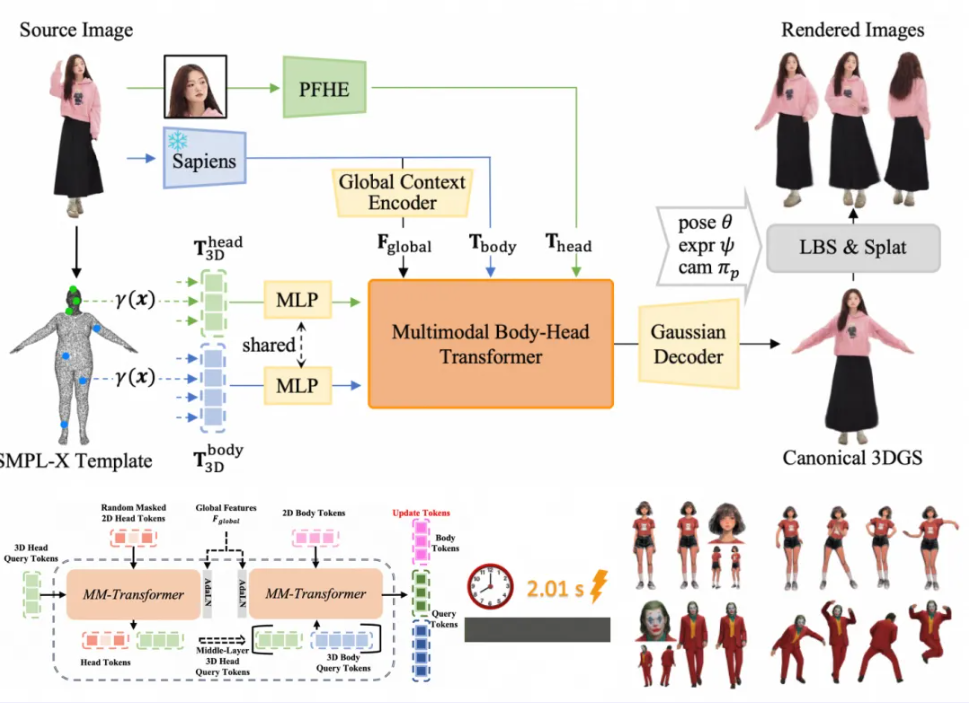
根据介绍,项目团队通过Vision Transformer技术将单张图片拆解为小块,并借助Meta的Mae模型编码身体特征。为获取更精细的人体头部特征,还设计了Head Tokenization方式(借鉴DINOv2网络结构),通过提取多感受的特征信息,并结合MLP映射,捕捉头部的整体结构细节。
基于人体先验模型SMPL-X,基于Transformer回归出五个关键高斯特征:坐标偏移、透视程度、表面颜色值、高斯大小和旋转向量。这些特征定义了3D模型的形状、颜色和动态表现能力。
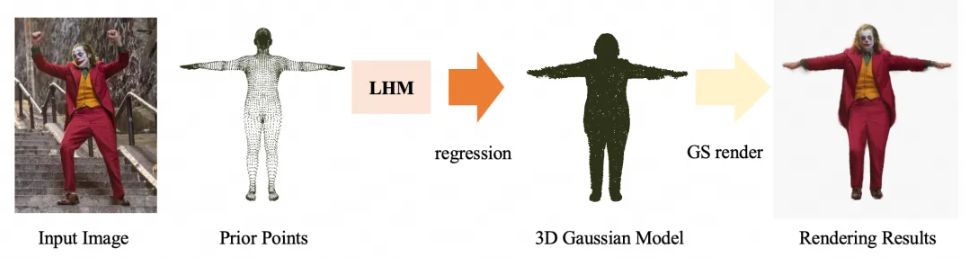
通过高斯渲染技术,得到T-pose下的人体先验图,并与SMPL-X建立一一映射关系,就可以直接索引SMPL-X中的骨骼,从而实现让3D数字人动起来的效果,最终得到一个真实且可驱动的3D高斯模型。
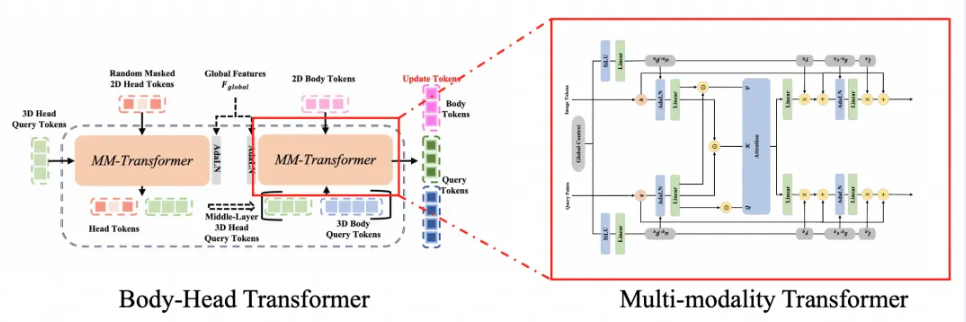
开发团队提出了Body-Head Transformer架构,借鉴了多模态Transformer(SD3)的设计理念,通过自适应Token和多层次Self-Attention机制,有效融合2D与3D Token。具体来说,先将头部Token输入到Multi-modality Transformer中学习头部特征,再将其与身体的随机Token结合,输入到Body Multi-modality Transformer 中,同步学习头部和身体的特征。
LHM有三大应用方向:动作重现、游戏角色生成和虚拟现实探索。你可以生成3D数字人并指定动作,比如跳舞、打篮球等,这些动作流畅且细节还原度高。还能在游戏领域,生成的3D资产可以无缝融入渲染管线,作为游戏角色使用。未来,LHM还可以与VR眼镜结合,生成的数字人可以直接进入虚拟现实世界,与玩家互动。