蓝耘携手通义万相 2.1,赋予 AI 视频生成无限可能。从注册到实操,带你解锁影视、广告等多领域应用。即便是小白,也能借此开启创意视频创作的闪耀之旅 。
目录
一·为什么会写这篇文章???
最近,我听说了蓝耘和通义万相 2.1 这两个听起来很厉害的东西,据说它们结合起来能在 AI 视频生成领域创造出令人惊叹的效果。我心里就燃起了一股强烈的好奇心,特别想弄明白这到底是怎么回事。于是,我开启了这段探索之旅,想要亲自揭开蓝耘与通义万相 2.1 结合的神秘面纱,看看它们到底能为 AI 视频生成带来怎样的惊喜。
二、初遇蓝耘与通义万相 2.1:
2.1 啥是蓝耘?
一开始,我完全不知道蓝耘是什么。经过一番查找资料,我了解到蓝耘是一个智算平台。简单来说,它就像是一个超级强大的 “大脑运算基地”,有着特别厉害的计算能力。就好比我们做数学题,普通的计算器可能算得很慢,还容易出错,但蓝耘这个 “超级计算器” 可以又快又准地完成各种复杂的计算任务。它的硬件部分支持很多高端的 GPU,像 NVIDIA A100、V100、H100 这些,这些 GPU 就像是一个个勤劳又能干的小工人,能同时处理好多好多的数据和复杂的计算。而且,蓝耘在软件方面也很厉害,它集成了 Kubernetes 和 Docker 技术,这就好比给这些小工人搭建了一个特别高效的工作环境,让它们能更灵活、更稳定地工作。
那下面我们来模拟下:
class BlueFarming:
def __init__(self):
self.supported_gpus = ["NVIDIA A100", "NVIDIA V100", "NVIDIA H100"]
self.software_technologies = ["Kubernetes", "Docker"]
def describe_hardware(self):
gpu_list = ", ".join(self.supported_gpus)
print(f"蓝耘平台的硬件部分支持以下高端 GPU: {gpu_list}。")
def describe_software(self):
software_list = ", ".join(self.software_technologies)
print(f"蓝耘平台在软件方面集成了 {software_list} 技术,为计算提供高效环境。")
def calculate(self):
print("蓝耘平台像超级计算器一样,能快速准确地完成复杂计算任务。")
if __name__ == "__main__":
blue_farming = BlueFarming()
blue_farming.describe_hardware()
blue_farming.describe_software()
blue_farming.calculate()2.2 通义万相 2.1 是啥?
接着,我又去了解通义万相 2.1。原来它是一个多模态 AI 生成模型,听起来很专业,其实就是一个能根据我们输入的文字描述,生成各种东西的神奇 “魔法盒子”。它可以生成图片、视频,甚至 3D 内容。比如说,我告诉它 “我想要一个美丽的海边日落场景,有金色的沙滩和蓝色的大海”,它就能通过复杂的算法和大量的学习,把这个场景以视频的形式呈现出来。而且,它采用了 VAE 架构、DiT 架构以及 IC - LoRA 技术,这些技术就像是它的 “魔法咒语”,让它生成的视频质量更高、细节更丰富,速度也比其他一些类似的模型快很多。
使用python类模一下:
import time
class TongyiWanxiang2_1:
def __init__(self):
# 模拟模型采用的架构和技术
self.architectures = ["VAE 架构", "DiT 架构"]
self.technologies = ["IC - LoRA 技术"]
print("通义万相 2.1 已就绪。")
def generate_content(self, text_description, output_type="图片"):
print(f"接收到描述: {text_description},请求生成 {output_type}。")
print("正在使用 VAE 架构、DiT 架构以及 IC - LoRA 技术进行处理...")
# 模拟处理时间
time.sleep(2)
if output_type == "图片":
print(f"已生成符合描述的图片。")
elif output_type == "视频":
print(f"已生成符合描述的视频,该视频质量高、细节丰富。")
elif output_type == "3D 内容":
print(f"已生成符合描述的 3D 内容。")
else:
print("不支持的输出类型。")
return f"生成的 {output_type}"
# 使用示例
if __name__ == "__main__":
model = TongyiWanxiang2_1()
description = "我想要一个美丽的海边日落场景,有金色的沙滩和蓝色的大海"
result = model.generate_content(description, output_type="视频")
print(result)2.3 它们为啥要结合?
我就在想,蓝耘和通义万相 2.1 为啥要结合在一起呢?后来我明白了,它们就像是一对完美的搭档。通义万相 2.1 虽然有生成视频的 “魔法”,但是在处理大规模、复杂的视频生成任务时,需要大量的计算资源。而蓝耘正好有强大的算力,可以为通义万相 2.1 提供足够的 “能量”,让它能更高效地施展 “魔法”。这样一来,它们结合在一起就能在 AI 视频生成领域发挥出巨大的威力。
三、准备工作之和蓝耘、通义万相 2.1 做朋友:
如何快速高效注册蓝耘平台并急速调用通义万相 2.1:
首先我们点击链接先进行注册:https://cloud.lanyun.net//#/registerPage?promoterCode=0131
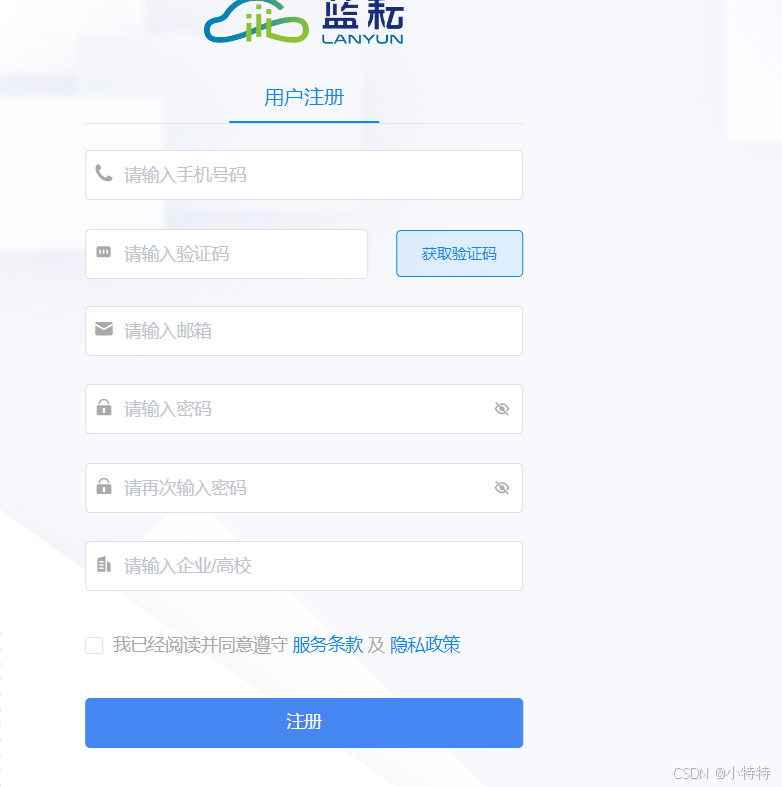
注册完后进行登录:
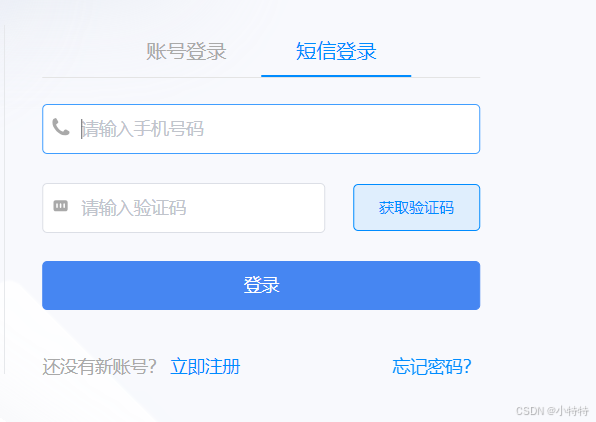
点击这里:
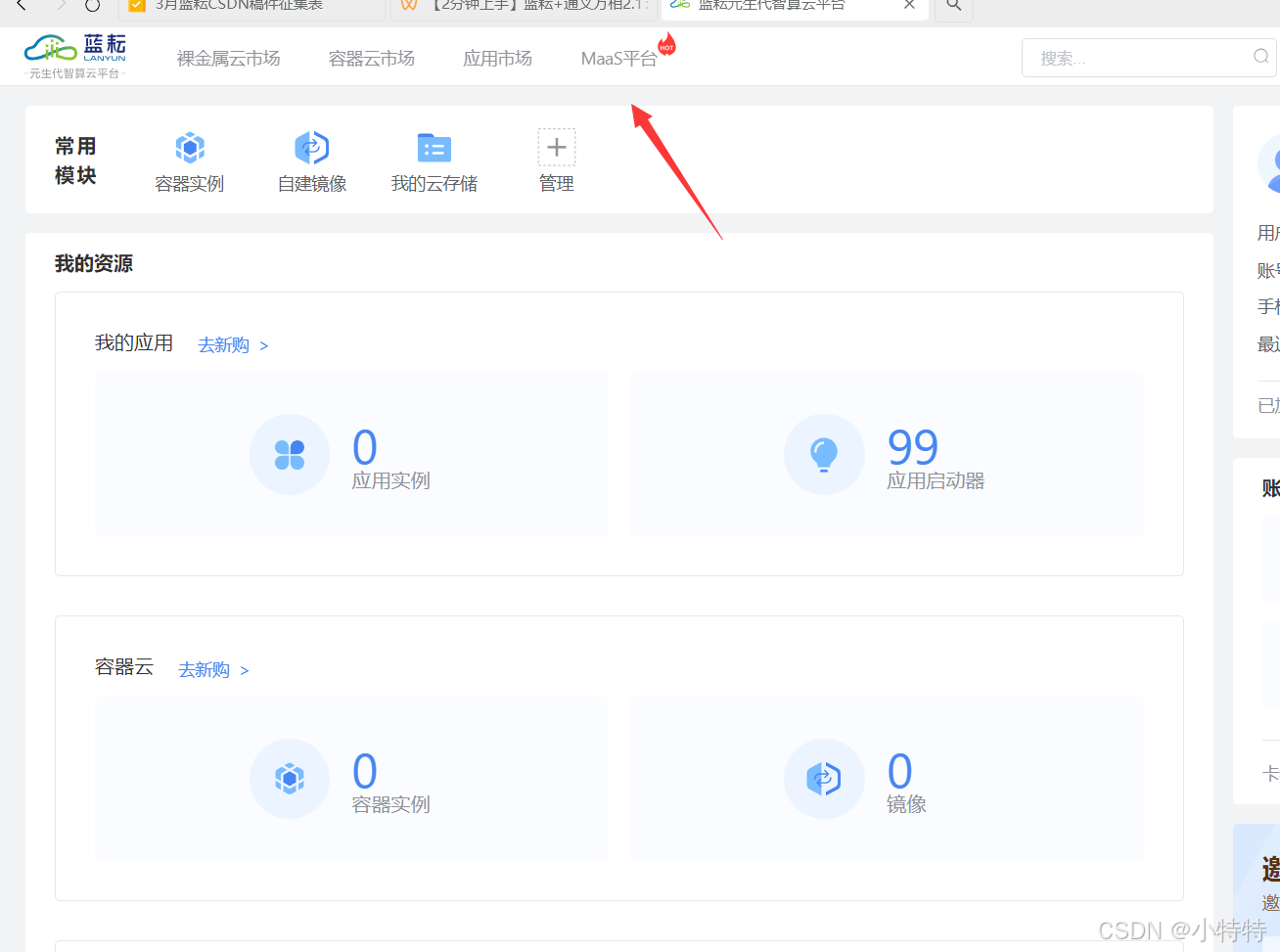
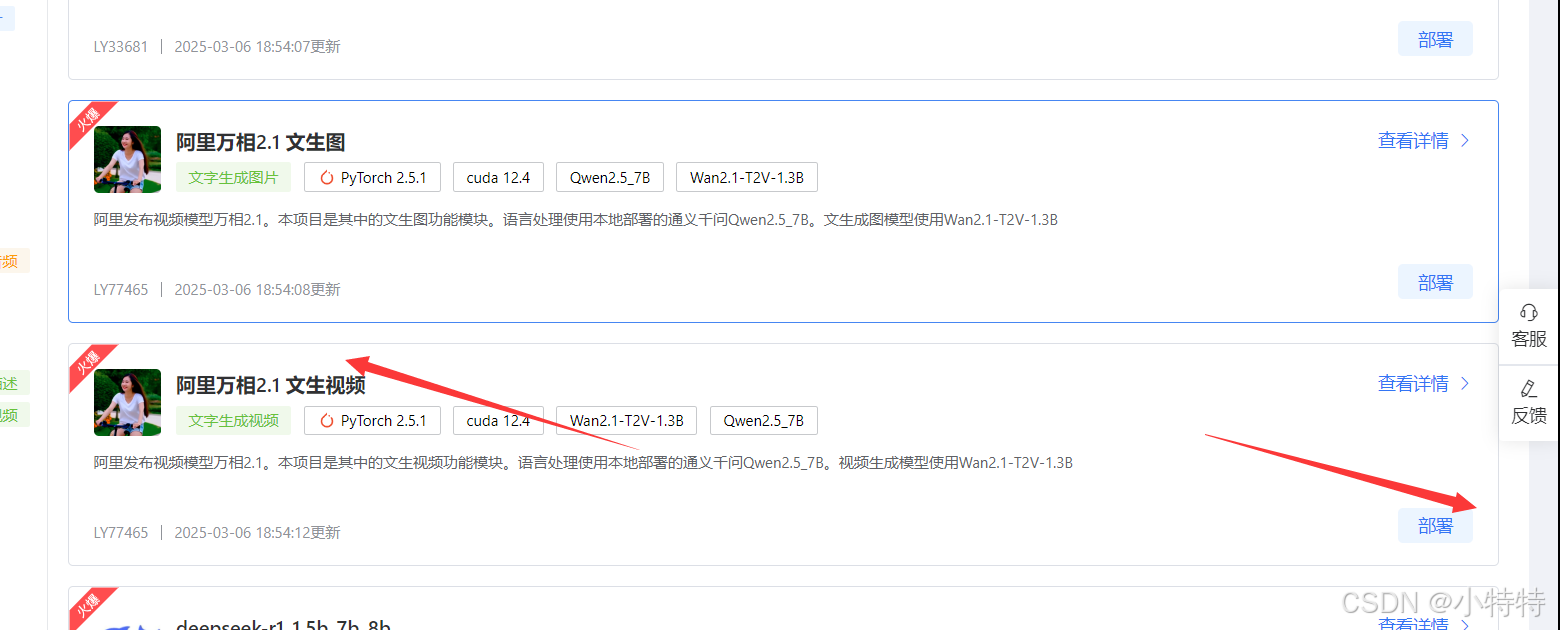 进行部署:
进行部署:
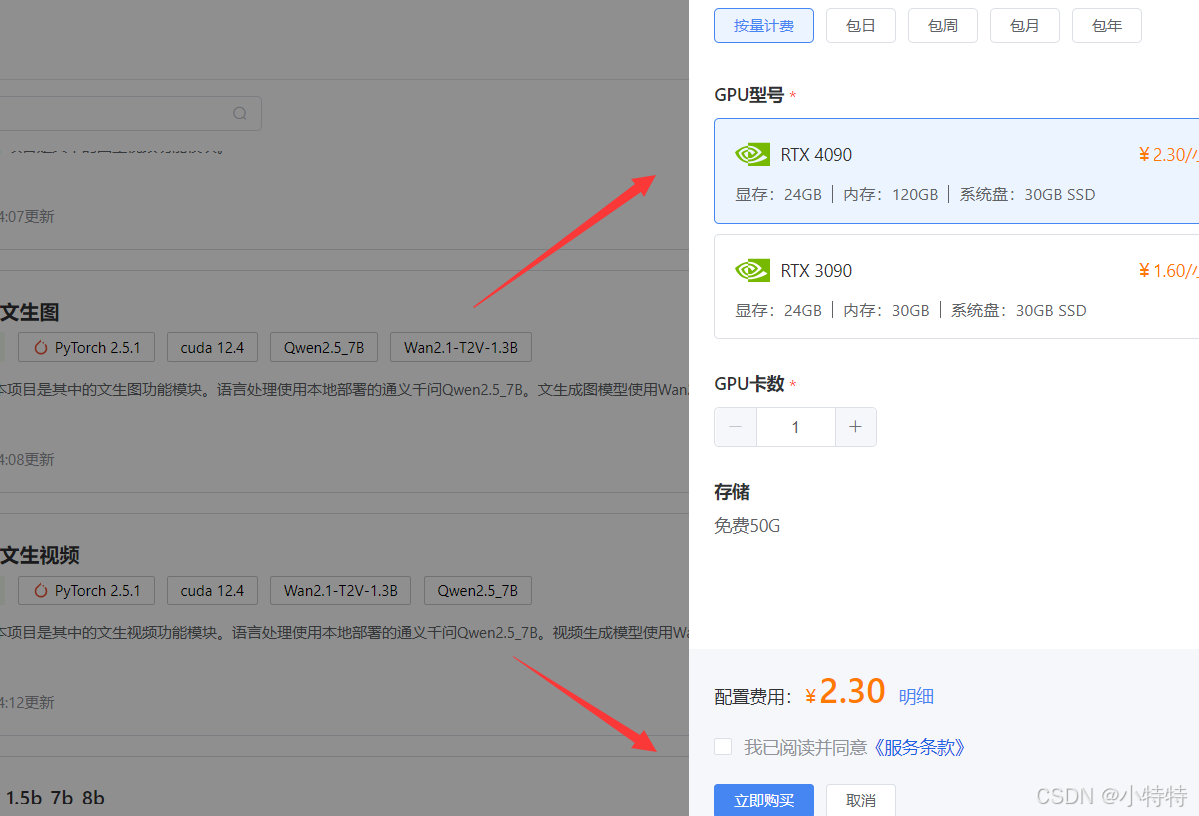
点击启动然后等待一会:
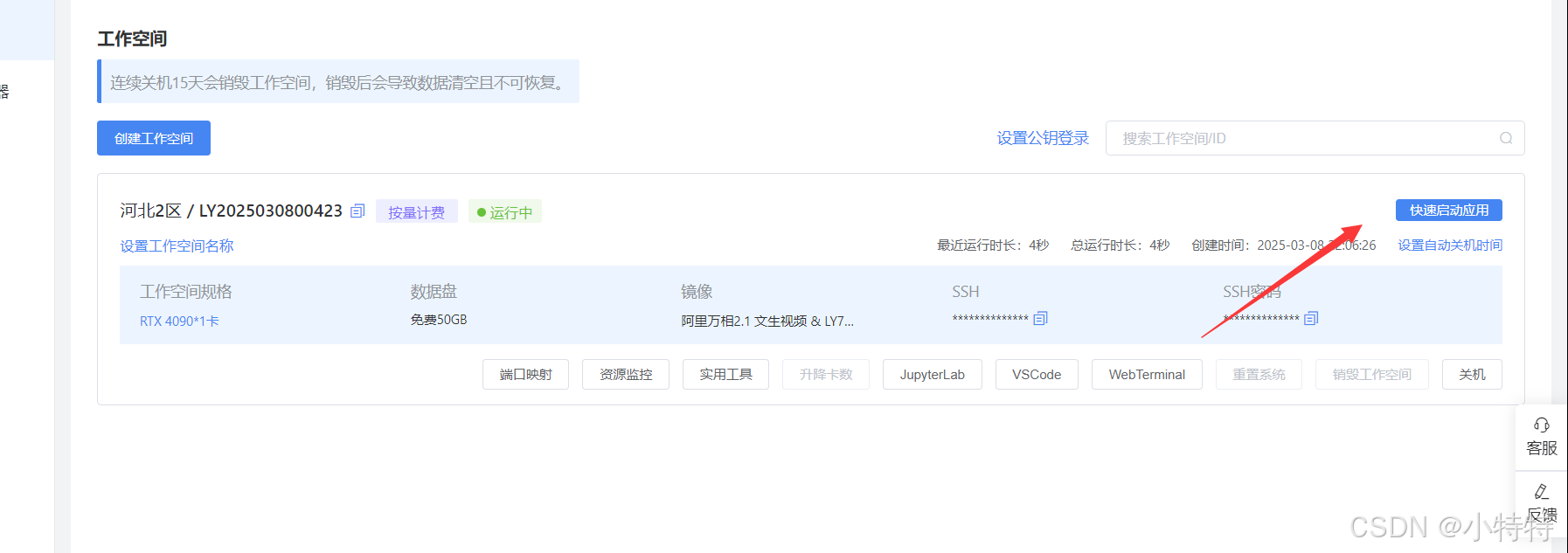
接下俩跳转来到:
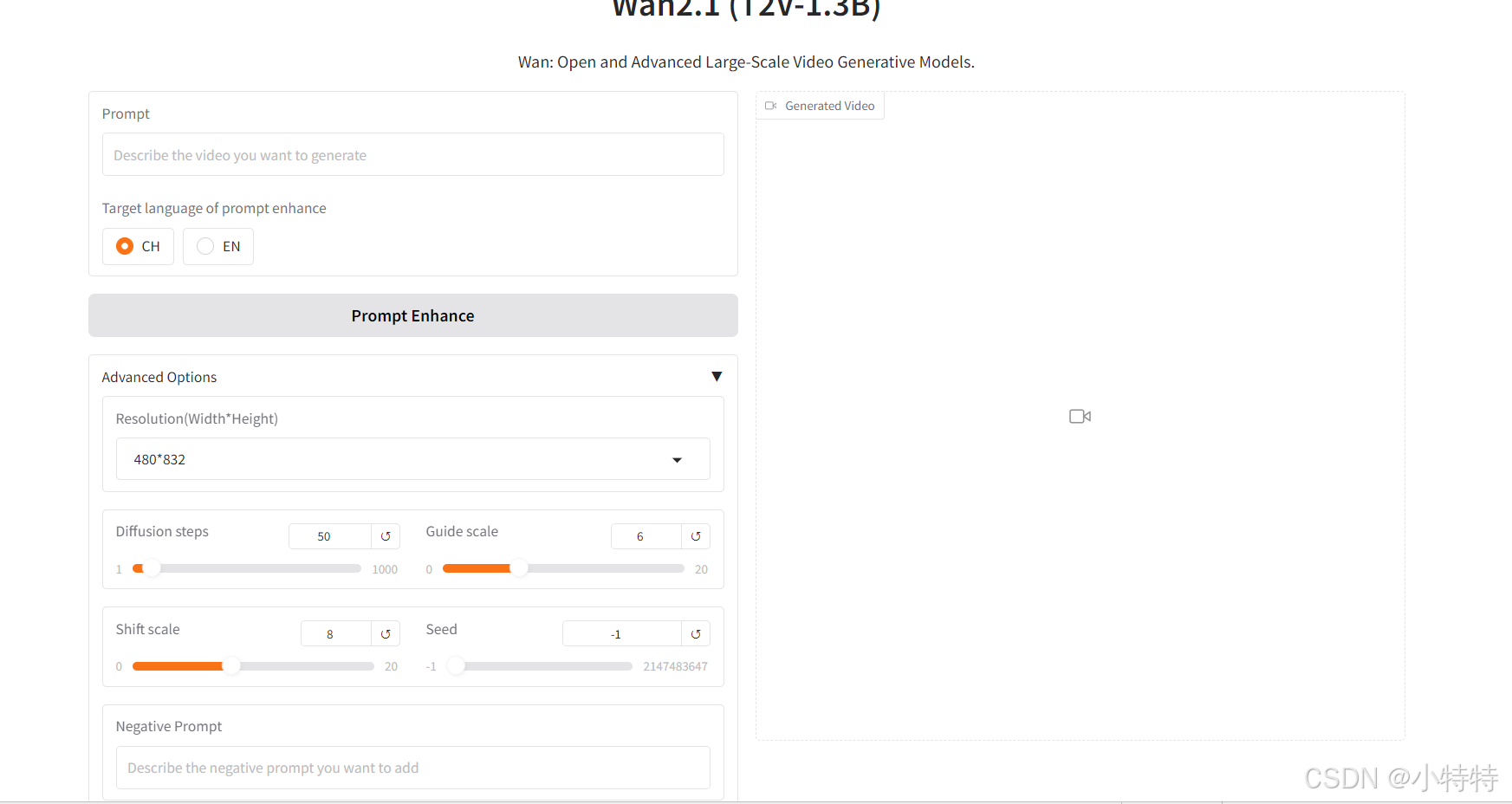
我们只需进行输入描绘即可:
下面我们把这段话输入进去:
人群之中,这位小鲜肉宛如一颗璀璨明星。他身材清瘦却不失力量感,宽肩窄腰,线条流畅。脸庞犹如精美的瓷器,肌肤白皙嫩滑,透着微微的光泽。一双丹凤眼,眼角微微上挑,眼眸深邃幽远,仿佛藏着无数故事,不经意间的凝视,便能勾人心弦。浓密的眉毛如同墨染,为他的面容增添了几分英气。高挺笔直的鼻梁,让他的五官更显立体。那唇瓣,色泽红润,饱满诱人,微微嘟起时,带着一丝可爱的倔强。此刻,他身着一件黑色印花 T 恤,上面点缀着精致的图案,下身搭配一条破洞工装裤,裤子边缘磨损自然,脚踩一双酷炫的黑色马丁靴,鞋底带有鲜明的磨损痕迹。再配上一顶反戴的棒球帽,帽檐微微低垂,遮住了一部分前额。他站在人群中,举手投足间,满是潮流与个性的张扬,青春荷尔蒙肆意挥洒,引得周围人纷纷投来羡慕与欣赏的目光。镜头拉近,聚焦在他微笑着看向镜头的瞬间,背景是一片繁忙的人群,人们或行色匆匆,或驻足观望,形成鲜明对比。纪实摄影风格,中景特写,背景虚化。
最后我们等待几分钟:
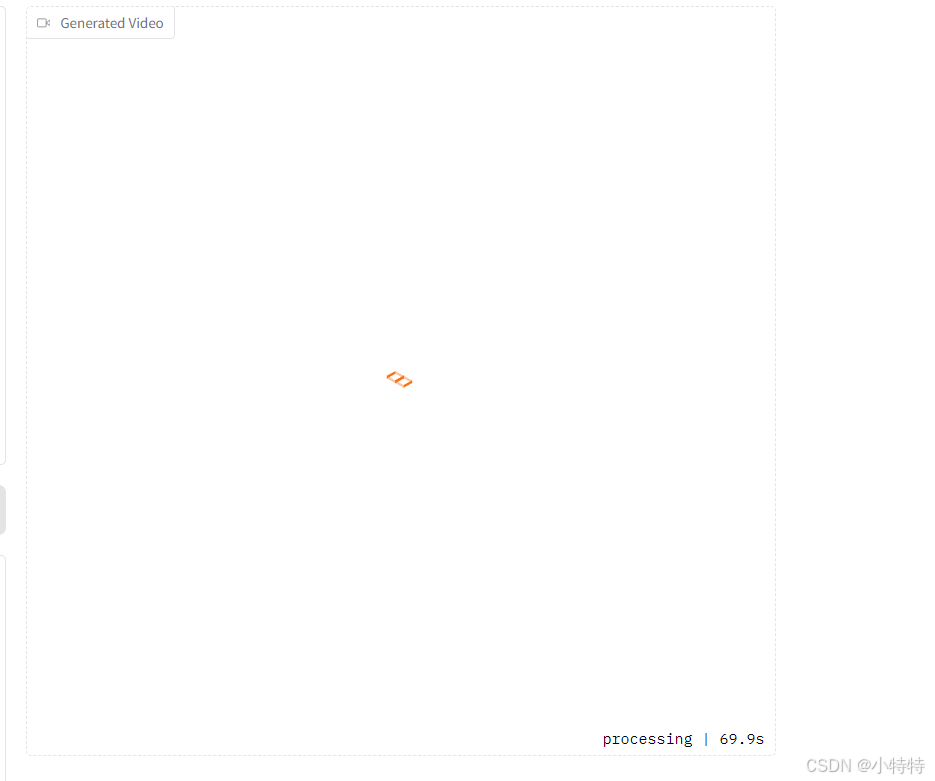
然后就能看见生成的视频如下:
example
当然我们也可以自己使用api去调用;如下:
3.1 注册和获取权限:
我首先要做的就是和蓝耘、通义万相 2.1 正式 “认识” 一下。我去了蓝耘的官方网站,按照上面的指引完成了注册。注册过程就像我们在网上注册其他账号一样,填一些基本信息,然后验证一下邮箱或者手机就可以了。注册好之后,我还需要申请使用蓝耘算力的权限,这个过程可能需要一些时间审核,不过只要按照要求提供准确的信息,一般都能顺利通过。
对于通义万相 2.1,我也去它的相关平台完成了注册。注册成功后,我得到了一个 API Key,这个 API Key 就像是一把钥匙,有了它我才能调用通义万相 2.1 的功能。
3.2 安装必要的工具和库:
接下来,我要给我的 “作战装备” 升级一下,安装一些必要的工具和库。我主要用的是 Python 语言,因为它简单易学,而且有很多强大的库可以帮助我完成 AI 视频生成的任务。我打开命令行工具,用下面的命令安装了一些常用的库:
pip install requests # 用于发送网络请求
pip install torch # PyTorch 深度学习框架
pip install torchvision # 用于处理图像和视频
pip install opencv-python # 用于计算机视觉任务
安装这些库就像是给我的 “武器库” 里添加了各种厉害的武器,让我在后面的操作中能更得心应手。
四、小试牛刀之调用通义万相 2.1 生成简单视频:
4.1 编写第一个调用代码:
我怀着激动又紧张的心情,开始编写第一个调用通义万相 2.1 的代码。我想先从一个简单的视频生成任务开始,看看这个 “魔法盒子” 到底有多神奇。以下是我的代码:
import requests
import json
# 通义万相 2.1 API 地址,这里需要替换成实际的地址
api_url = "https://your-tongyiwanxiang2.1-api-url"
# 我的 API Key,就像前面说的钥匙
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_ACCESS_TOKEN"
}
# 我输入的文本提示,描述我想要的视频场景
prompt = {
"场景描述": "一个宁静的公园,有绿树和湖泊,阳光洒在地面上",
"风格": "清新写实风格",
"时长": 10,
"帧率": 24
}
data = {
"prompt": prompt,
"parameters": {
"width": 1280,
"height": 720
}
}
try:
# 发送请求给通义万相 2.1
response = requests.post(api_url, headers=headers, data=json.dumps(data))
response.raise_for_status()
result = response.json()
frame_urls = result["frame_urls"]
print("成功获取视频帧 URL 列表")
except requests.RequestException as e:
print(f"请求出错: {e}")
except KeyError:
print("返回结果格式有误,未找到预期的视频帧 URL 列表。")
我首先导入了 requests 和 json 库,requests 库可以帮助我向通义万相 2.1 的 API 发送请求,json 库用于处理 JSON 数据。然后我设置了 API 地址和请求头,请求头里包含了我的 API Key。接着,我定义了一个 prompt 字典,里面描述了我想要的视频场景,包括场景描述、风格、时长和帧率等信息。最后,我把这些信息打包成 JSON 格式,发送给通义万相 2.1 的 API。如果一切顺利,我就能得到一个包含视频帧 URL 列表的结果。
4.2 理解代码和结果:
我仔细看了看这段代码,发现其实并不难理解。每一步都有它的作用,就像是按照一个清晰的步骤清单在操作。当我运行这段代码后,看到控制台输出 “成功获取视频帧 URL 列表” 时,我特别兴奋,感觉自己已经成功迈出了第一步。这些视频帧 URL 就像是一个个宝藏的地址,我接下来要做的就是把这些宝藏(视频帧)都挖出来。
五、深入挖掘之下载和处理视频帧:
5.1 下载视频帧:
得到视频帧 URL 列表后,我就开始编写代码下载这些视频帧。以下是我的代码:
import requests
import cv2
import numpy as np
from torchvision import transforms
import torch
# 假设蓝耘平台有 GPU 可用,这样计算会更快
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义图像预处理函数,把图像转换为适合模型处理的格式
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
frames = []
for url in frame_urls:
try:
# 下载视频帧
frame = cv2.imdecode(np.frombuffer(requests.get(url).content, np.uint8), cv2.IMREAD_COLOR)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_tensor = preprocess(frame).unsqueeze(0).to(device)
frames.append(frame_tensor)
except Exception as e:
print(f"下载或处理视频帧时出错: {e}")
print("视频帧下载并预处理完成")
我首先判断是否有 GPU 可用,如果有就使用 GPU 进行计算,这样速度会快很多。然后我定义了一个图像预处理函数 preprocess,它的作用是把下载的视频帧转换为 PyTorch 张量,并进行归一化处理。接着,我遍历视频帧 URL 列表,使用 requests 库下载每个视频帧,再用 cv2 库进行解码和颜色转换,最后把处理好的视频帧添加到 frames 列表中。
5.2 简单处理视频帧:
下载完视频帧后,我想对它们进行一些简单的处理,让视频看起来更美观。我决定给视频帧添加一些光影效果,就像给画面加上一层美丽的滤镜。以下是处理代码:
import torch.nn.functional as F
# 定义视频帧增强函数,添加光影效果
def enhance_frame(frame):
# 应用锐化卷积核,让画面更清晰
kernel = torch.tensor([[-1, -1, -1], [-1, 9, -1], [-1, -1, -1]], dtype=torch.float32).unsqueeze(0).unsqueeze(0).to(device)
enhanced_frame = F.conv2d(frame, kernel, padding=1)
# 添加光影效果,模拟阳光的明暗变化
light_mask = torch.randn_like(frame) * 0.1
enhanced_frame = enhanced_frame + light_mask
enhanced_frame = torch.clamp(enhanced_frame, 0, 1)
return enhanced_frame
enhanced_frames = []
for frame in frames:
enhanced_frame = enhance_frame(frame)
enhanced_frames.append(enhanced_frame)
print("视频帧增强处理完成")
我首先定义了一个锐化卷积核,通过 F.conv2d 函数对视频帧进行卷积操作,让画面更清晰。然后我生成一个随机的光影掩码,添加到视频帧上,模拟阳光的明暗变化。最后,我使用 torch.clamp 函数把像素值限制在 0 到 1 之间,避免出现像素值溢出的问题。
六、大功告成之保存处理后的视频:
6.1 转换视频帧格式:
处理完视频帧后,我要把它们转换为适合保存的格式。以下是转换代码:
from torchvision.utils import make_grid
import torchvision.io as io
# 将处理后的视频帧转换为适合保存的格式
output_frames = []
for frame in enhanced_frames:
frame = frame.squeeze(0).cpu()
frame = make_grid(frame, normalize=True, scale_each=True)
frame = (frame * 255).byte().permute(1, 2, 0).numpy()
output_frames.append(frame)
我首先把视频帧从 GPU 移到 CPU 上,然后使用 make_grid 函数把视频帧转换为网格形式,方便后续处理。接着,我把像素值乘以 255 并转换为字节类型,最后调整维度顺序并转换为 NumPy 数组,添加到 output_frames 列表中。
6.2 保存视频:
最后一步,就是把这些处理好的视频帧保存成一个完整的视频。以下是保存代码:
import cv2
# 保存处理后的视频
fps = prompt["帧率"]
height, width, _ = output_frames[0].shape
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output_video.avi', fourcc, fps, (width, height))
for frame in output_frames:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
out.write(frame)
out.release()
print("处理后的视频已保存为 output_video.avi")
我首先获取视频的帧率,然后根据第一帧的尺寸确定视频的宽度和高度。
接着,我使用 cv2.VideoWriter_fourcc 函数指定视频编码格式,创建一个 cv2.VideoWriter 对象。最后,我遍历 output_frames 列表,把每一帧转换为 BGR 格式,写入视频文件中,最后释放资源。当我看到控制台输出 “处理后的视频已保存为 output_video.avi” 时,我特别有成就感,感觉自己已经掌握了用蓝耘和通义万相 2.1 生成 AI 视频的基本方法。
七.结合应用:
7.1影视制作:
影视制作方面,输入 “遥远外太空星际战舰交火” 等描述,通义万相 2.1 快速生成高分辨率视频帧,蓝耘算力保障高效渲染。这大幅节省拍摄成本,突破拍摄限制,助力导演实现奇思妙想,为影视创作增添无限可能。在广告、教育、游戏开发等领域也各有建树,为 AI 视频生成开拓广阔前景,让小白也能开启创意视频制作。
7.2 广告营销领域:
在广告营销里,吸引消费者眼球很关键。蓝耘与通义万相 2.1 结合,能帮企业快速制作吸睛的宣传视频。
比如一家新运动饮料公司,想做广告突出产品活力与功能性。输入 “一群活力运动员赛后喝饮料恢复能量,背景是热闹运动场”,通义万相 2.1 快速生成视频帧。还能利用蓝耘算力优化色彩、音效。和传统广告制作比,它节省大量时间与成本。传统制作需聘请演员、搭建场景,繁琐又昂贵,现在输入提示就能快速出高质量广告。
7.3 教育领域:
在教育方面,这一组合带来新体验。教师可制作生动教学视频。历史课讲古代战争,输入 “展示古代大规模战争,有士兵冲锋、战马奔腾”,能生成逼真视频,让学生身临其境。科学课讲生态系统,输入相关提示,能清晰展示运作原理。语言学习中,输入对话场景提示,可助学生提升英语应用能力。教师还能按需修改优化视频,蓝耘算力也保证不影响教学进度。
7.4 游戏开发领域:
游戏开发需大量高质量素材与逼真场景,蓝耘和通义万相 2.1 提供有力支持。场景设计上,输入 “神秘地下城,有古老墙壁、火把、陷阱和宝藏”,能快速生成场景视频帧用于游戏。角色设计时,输入 “超级英雄在城市战斗”,生成的视频可助完善角色形象与动作设计。
八·小结一下:
蓝耘与通义万相 2.1 的组合,为 AI 视频创作领域带来惊喜变革,尤其对小白创作者十分友好。蓝耘强大算力支持多型号 GPU 并行计算,软件层技术让通义万相 2.1 运行更稳定高效。通义万相 2.1 利用先进架构,能依据文本描述生成高质量视频。从基础的注册、工具安装,到输入提示生成视频,再经下载、处理视频帧,最终产出完整视频,流程简单易懂。无论是影视制作中奇幻场景生成,还是广告、教育、游戏领域应用,都能助力小白快速上手,轻松开启创意 AI 视频制作之旅 。
传送门:https://cloud.lanyun.net//#/registerPage?promoterCode=0131