1. 人工智能从算法驱动到知识驱动的进化
当前,以GPT-4、Claude等为代表的大语言模型(LLM)虽然展现出强大的生成能力,但其局限性也日益凸显:依赖历史训练数据导致知识滞后,面对专业领域问题时易产生“幻觉”(Hallucination),且缺乏对动态实时信息的响应能力。
为解决这些问题,AI技术正经历从“算法驱动”到“知识驱动”的范式升级。知识库(Knowledge Base) 成为连接通用大模型与垂直领域应用的桥梁:
- 知识增强:通过RAG(检索增强生成)技术,将知识库中的结构化信息注入大模型输入,提升回答的可信度与专业性。
- 动态更新:智能体(Agent)依赖知识库的持续更新实现长期记忆,例如金融领域Agent需实时整合股票行情、政策法规等数据以支持投资决策。
- 降低算力成本:知识库可缓存高频查询结果,减少对大模型的重复调用。
2. 爬虫技术:概念与背景
2.1. 爬虫的定义与作用
网络爬虫,又称为网页蜘蛛、机器人或网络漫游器,是一种自动化脚本或程序,设计用于系统地浏览互联网并提取信息。爬虫的主要作用包括:
- 信息收集:爬虫可以快速地从大量网站中收集数据,帮助用户获得所需的信息。
- 搜索引擎优化:搜索引擎使用爬虫来抓取网页并索引内容,以便提供准确的搜索结果。
- 市场分析:企业使用爬虫来监测竞争对手的动态、分析市场趋势和消费者行为。
- 数据集构建:研究人员利用爬虫创建数据集以进行进一步的分析和模型训练。
2.2. 爬虫的工作原理
网络爬虫的工作流程通常包括以下几个步骤:
- 请求:爬虫向目标网站发送HTTP请求以获取网页内容。
- 响应:服务器响应请求并返回网页的HTML内容。
- 解析:爬虫使用解析器(如正则表达式、BeautifulSoup等)分析HTML,提取所需的信息。
- 存储:将提取的数据存储到数据库或文件中,以便后续处理和分析。
爬虫可以配置为定期更新数据,以确保信息的实时性和准确性。
2.3. 爬虫面临的挑战
在实际操作中,爬虫技术面临着多种挑战:
- 反爬机制:许多网站使用技术手段检测和阻止爬虫访问,例如通过设置机器人排除协议(robots.txt)或使用CAPTCHA验证。
- IP封禁:当同一IP地址频繁访问网站时,可能会被视为恶意行为而遭到封禁。使用代理IP轮换可以缓解这一问题。
- 数据动态加载:一些网站使用JavaScript动态加载数据,爬虫需要支持JavaScript解析或使用浏览器自动化工具(如Selenium)来抓取这些数据。
2.4. 合法爬虫的边界与注意事项
在实施爬虫技术时,遵循法律和伦理标准至关重要:
- 遵循robots.txt文件:尊重网站的robots.txt文件中规定的爬行规则和限制。
- 避免过度抓取:控制爬虫的抓取频率和范围,以避免对目标网站造成不必要的负担。
- 数据隐私:确保不侵犯用户隐私,不抓取敏感信息。
- 合法使用数据:确保获取的数据用于合法和道德的目的,不用于侵犯版权或其他法律权利。
在实施爬虫技术时,始终保持透明度和责任感,以维护良好的互联网生态环境。
3. 传统爬虫技术
传统爬虫技术是数据采集领域中最基础的工具之一,通过编写简单的脚本即可实现数据抓取。然而,随着互联网技术的发展,传统爬虫逐渐暴露出其局限性。本章将深入探讨传统爬虫的技术栈、示例代码以及面临的痛点。
3.1. 传统爬虫的技术栈
传统爬虫通常使用Python编程语言,结合Requests库和BeautifulSoup库来实现数据抓取:

- Python:以其简洁的语法和丰富的库支持成为爬虫开发的首选语言。
- Requests库:用于发送HTTP请求并接收响应。它简化了网络通信,使开发者能够轻松地获取网页内容。
- BeautifulSoup库:用于解析HTML和XML文档,提供便捷的方法来提取和处理网页中的数据。
这种技术栈适合于静态网页的抓取,易于学习和使用。
3.2. 使用亮数据代理ip爬取维基百科页面
接下来,我们一起来看下如何使用传统爬虫技术爬取维基百科,获取准确有价值的优质知识。
3.2.1. 维基百科关键词搜索api
GET https://en.wikipedia.org/w/api.php?action=query&list=search&srsearch={关键词}&srlimit={最大结果数}&format=json
{
"batchcomplete": "",
"continue": {
"sroffset": 10,
"continue": "-||"
},
"query": {
"searchinfo": {
"totalhits": 45,
"suggestion": "人工智能n",
"suggestionsnippet": "人工智能n"
},
"search": [
{
"ns": 0,
"title": "DeepSeek",
"pageid": 78452842,
"size": 61495,
"wordcount": 5930,
"snippet": "organization Jevons paradox – Efficiency leads to increased demand Chinese: 杭州深度求索\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E基础技术研究有限公司. Sometimes simply referred to in English as Hangzhou DeepSeek Artificial",
"timestamp": "2025-03-25T02:01:11Z"
},
{
"ns": 0,
"title": "Artificial intelligence industry in China",
"pageid": 57024219,
"size": 87277,
"wordcount": 7944,
"snippet": "ISBN 978-981-19-8504-1 "【人民网】世界\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E国际联合大会今秋将首次在中国举行----中国科学院". www.cas.cn. Archived from the original on 2023-05-04. Retrieved 2023-05-05. "科学网—首届吴文俊\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E科学技术奖颁奖". news",
"timestamp": "2025-03-13T21:04:04Z"
},
{
"ns": 0,
"title": "Generative artificial intelligence",
"pageid": 73291755,
"size": 163769,
"wordcount": 13713,
"snippet": "Archived from the original on July 27, 2023. Retrieved July 13, 2023. "生成式\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E服务管理暂行办法". July 13, 2023. Archived from the original on July 27, 2023. Retrieved",
"timestamp": "2025-03-22T15:24:03Z"
},
{
"ns": 0,
"title": "Alexandr Wang",
"pageid": 75806942,
"size": 10972,
"wordcount": 920,
"snippet": "你要知的8件事!創業6年25歲身家達10億美元成最年輕白手起家富翁". www.esquirehk.com. "DeepSeek:中國AI公司的驚人崛起帶來\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E的「Sputnik時刻」還是「珍珠港事件」?". BBC News 中文 (in Traditional Chinese). January 28",
"timestamp": "2025-03-03T16:04:26Z"
},
{
"ns": 0,
"title": "Beijing Academy of Artificial Intelligence",
"pageid": 73400769,
"size": 9766,
"wordcount": 803,
"snippet": "Beijing Academy of Artificial Intelligence (BAAI) (Chinese: 北京智源\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E研究院; pinyin: Běijīng Zhìyuán réngōng zhìnéng yánjiùyuàn), also known as Zhiyuan Institute",
"timestamp": "2025-01-01T19:02:51Z"
},
{
"ns": 0,
"title": "Interim Measures for the Management of Generative AI Services",
"pageid": 74437860,
"size": 7196,
"wordcount": 825,
"snippet": "Interim Measures for the Management of Generative AI Services (Chinese: 生成式\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E服务管理暂行办法; pinyin: Shēngchéng shì réngōng zhìnéng fúwù guǎnlǐ zànxíng bànfǎ)",
"timestamp": "2025-01-21T04:55:36Z"
},
{
"ns": 0,
"title": "Political repression",
"pageid": 1297768,
"size": 21504,
"wordcount": 2283,
"snippet": "Watch. 14 January 2020. Retrieved 2 March 2023. 孟宝勒 (2018-07-17). "中国的威权主义未来:\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E与无孔不入的监控" (in Chinese). 纽约时报中文网. Archived from the original on 2019-10-16",
"timestamp": "2025-02-28T17:24:22Z"
},
{
"ns": 0,
"title": "Kai-Fu Lee",
"pageid": 2273087,
"size": 31001,
"wordcount": 2817,
"snippet": "published February 2011, Beijing Xiron Books Co., Ltd) Artificial Intelligence (《\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E》, published May 2017, Beijing Xiron Books Co., Ltd) AI 2041: Ten Visions",
"timestamp": "2025-03-23T09:20:01Z"
},
{
"ns": 0,
"title": "Ted Chiang",
"pageid": 325507,
"size": 36433,
"wordcount": 2738,
"snippet": "Bibliography). Retrieved October 4, 2012. Klein, Ezra (March 3, 2023). "\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E真正的恐怖之处" [The Imminent Danger of A.I. Is One We’re Not Talking About]. The",
"timestamp": "2025-02-23T11:21:06Z"
},
{
"ns": 0,
"title": "VITAL (machine learning software)",
"pageid": 63804242,
"size": 19234,
"wordcount": 1913,
"snippet": "(PDF). Cadogan Consulting Group. Retrieved 6 May 2020. Lin, Shaowei (2018). "\u003Cspan class=\"searchmatch\"\u003E人工\u003C/span\u003E\u003Cspan class=\"searchmatch\"\u003E智能\u003C/span\u003E对公司法的影响:挑战与应对" [The impact of artificial intelligence on company law: challenges",
"timestamp": "2024-04-23T00:00:38Z"
}
]
}
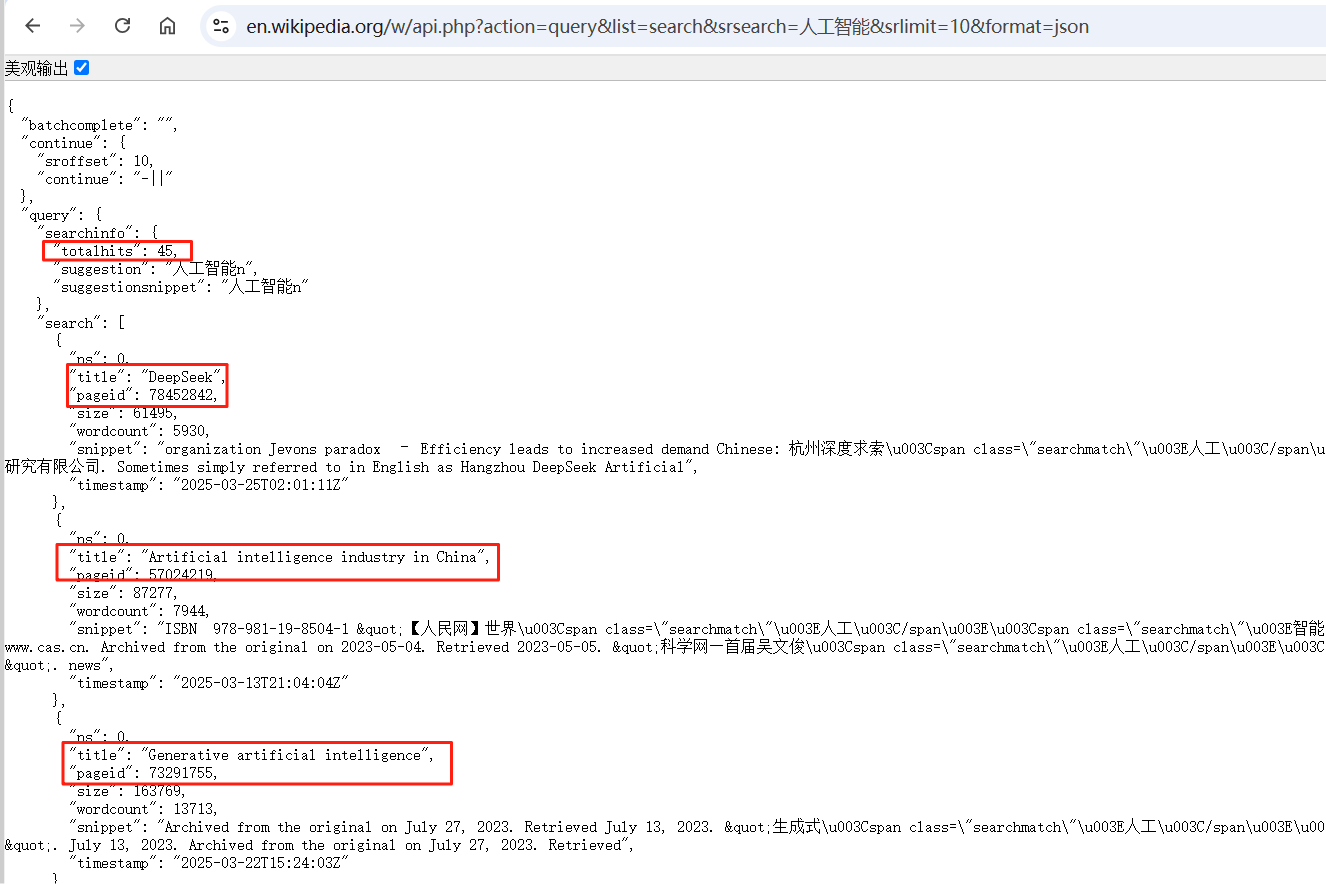
}可以看到,人工智能的搜索结果有45条数据,但是我们设置了srlimit为10,所以API只给我们返回了10条,每条数据包含了百科标题等摘要性信息。
3.2.2. 爬取维基百科内容页内容
GET https://en.wikipedia.org/wiki/{空格替换为_后的title}获取到网页内容之后,使用BeautifulSoup库解析网页源代码相关标签,得到需要的信息即可。
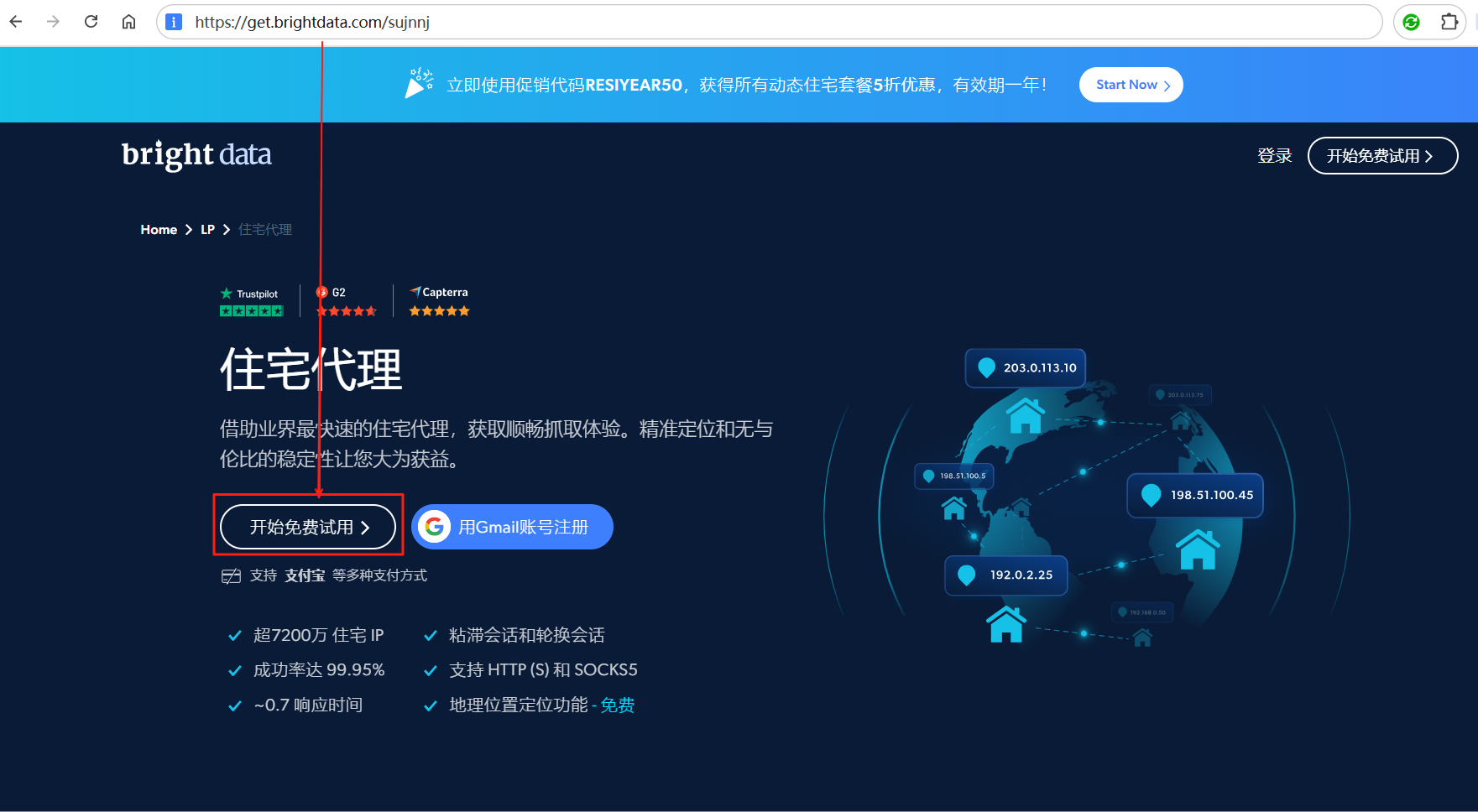
3.2.3. 获取亮数据代理ip
访问亮数据官网:购买住宅代理网络IP - 免费试用。点击开始免费试用按钮。
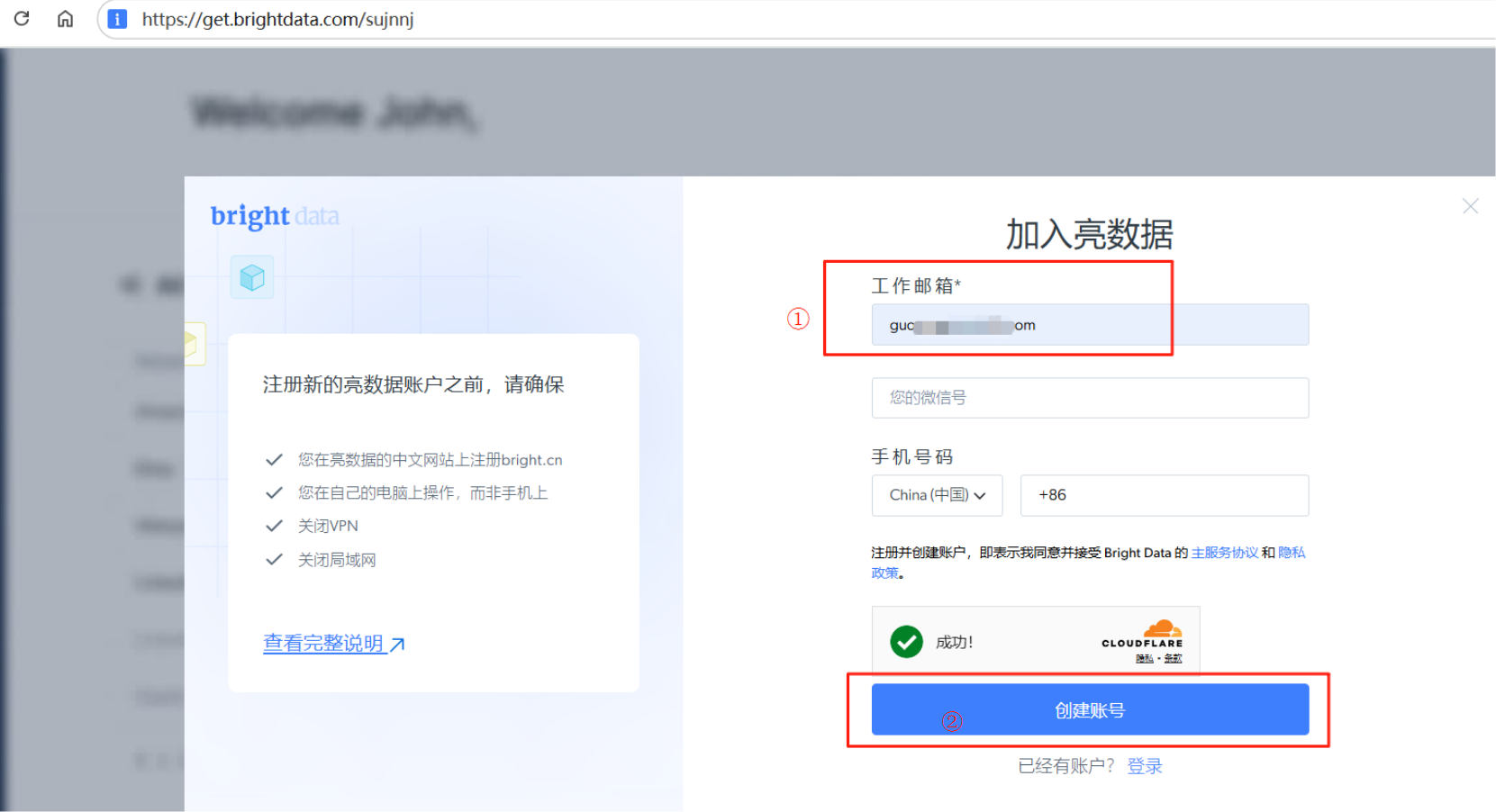
输入邮箱,点击创建账号按钮进行账号注册,然后登录网站。
登录成功后,点击左侧的Proxies & Scraping按钮。
找到住宅动态IP,点击开始使用按钮。
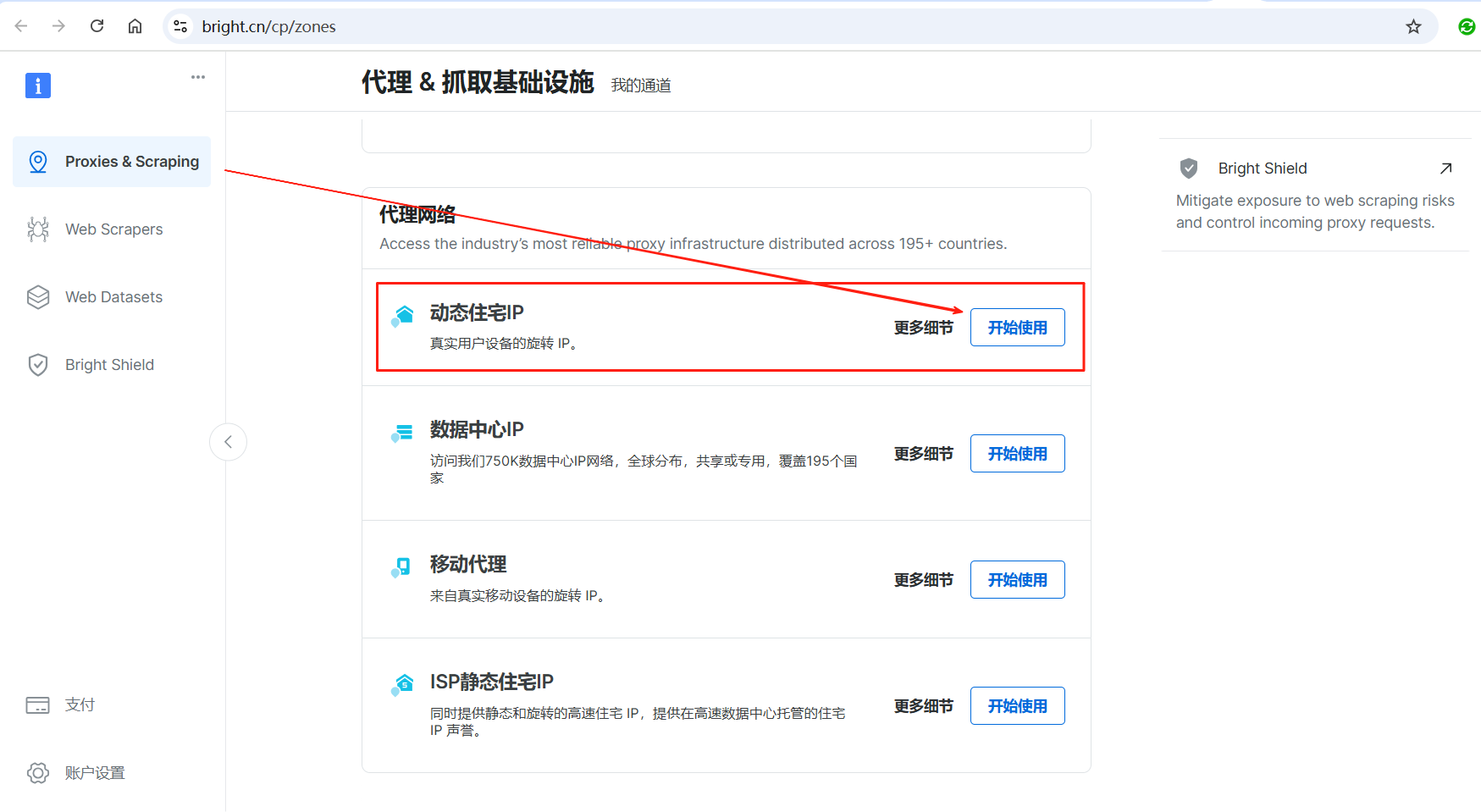
在基本设置里,找到通道名称,使用默认名称或者自己都可以。代理类型选共享(按GB收费),其它保持默认,然后点击右侧的添加按钮即可完成代理ip的设置。
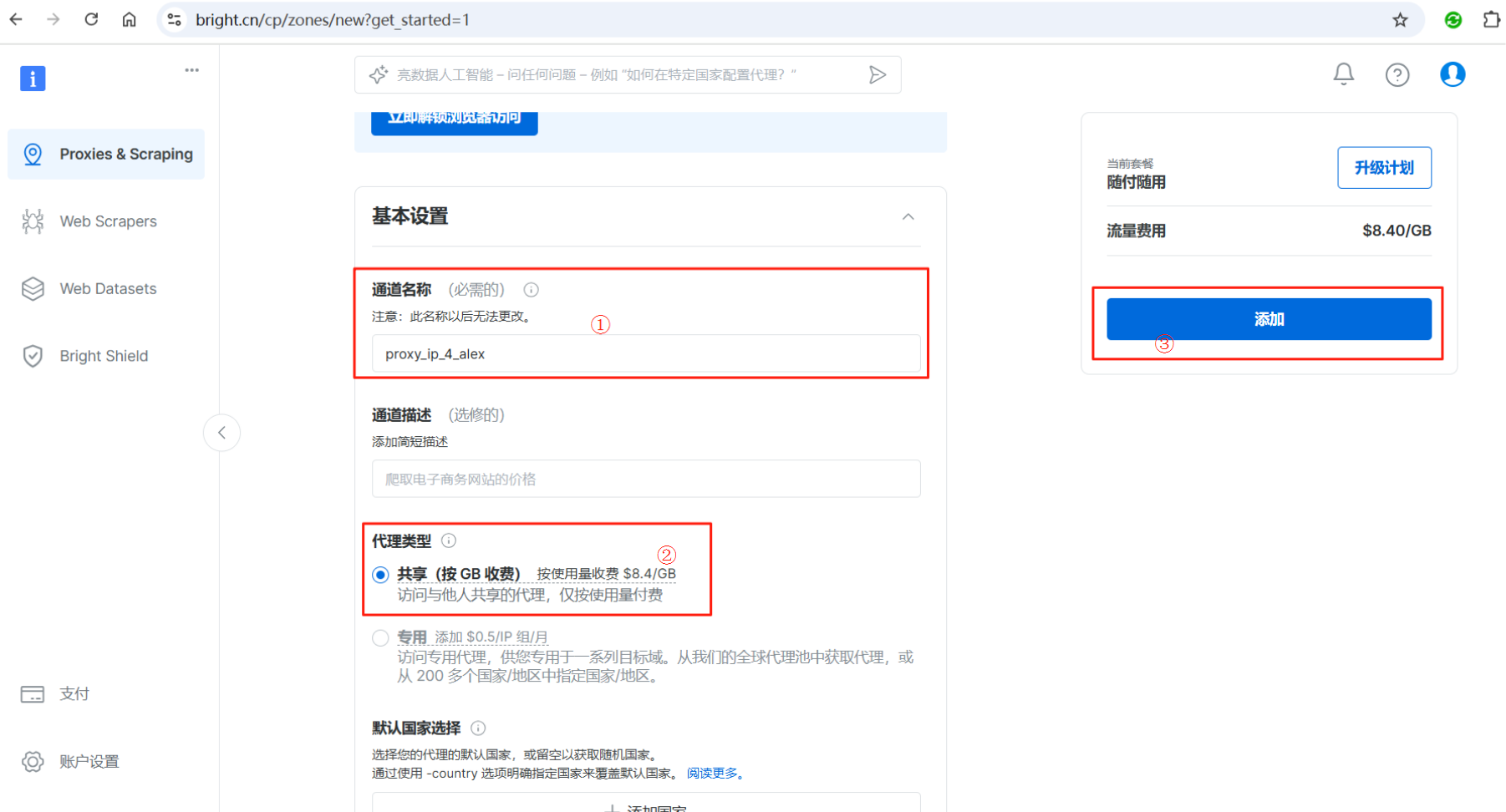
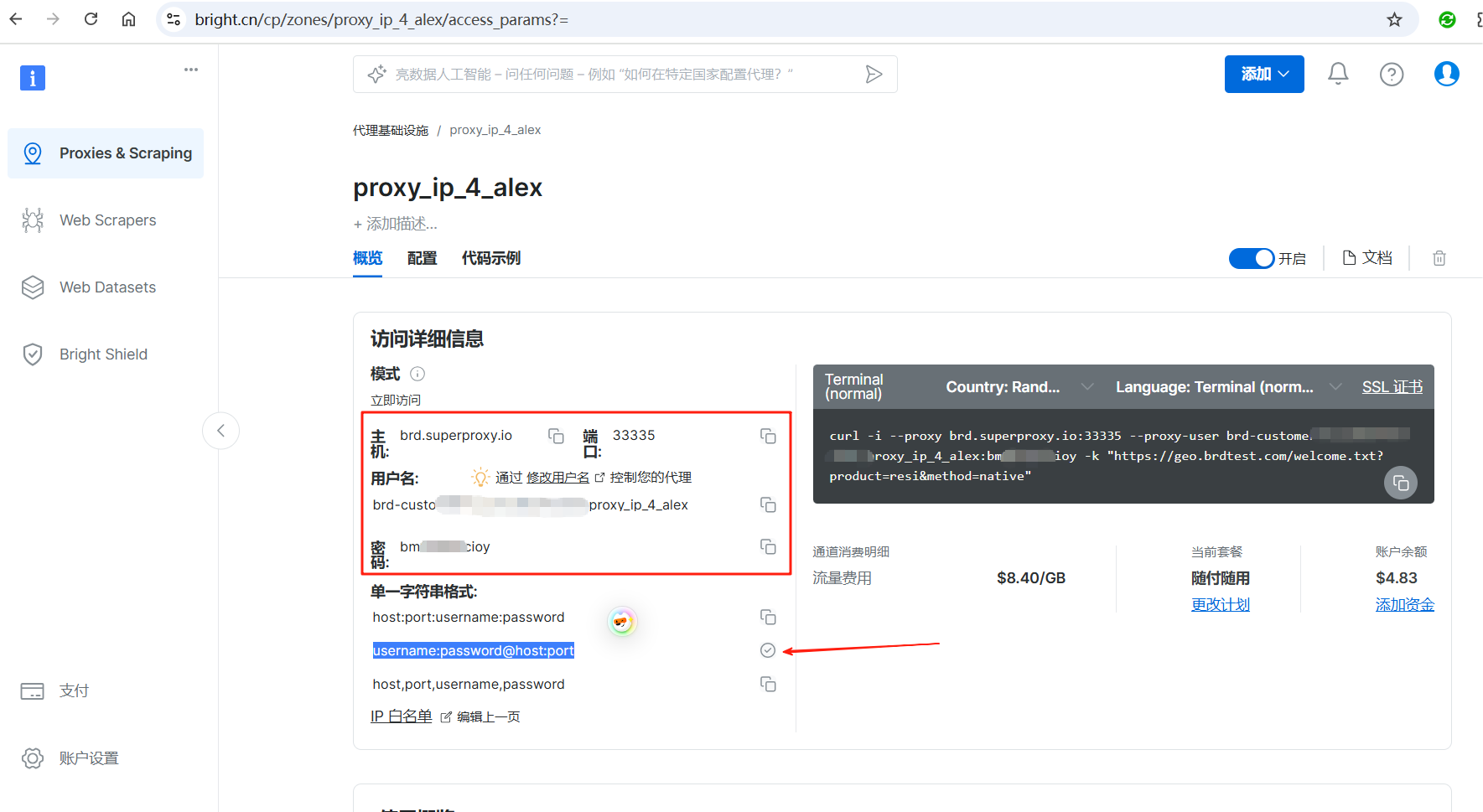
代理ip配置成功后,可以看到账号、密码和ip获取域名、测试命令等信息,我们可以直接点击username:password@host:port右侧的复制按钮一键复制代理ip配置,下一步会用到。
3.2.4. 完整代码
以下是从维基百科搜索资料并进行爬取内容的完整代码。将开头的代理ip替换上一步一键复制的信息即可。
import requests
from bs4 import BeautifulSoup
import json
# 亮数据代理ip配置(需要替换为自己的用户名、密码)
proxy = {
'http': '用户名:密码@brd.superproxy.io:33335',
}
class WikipediaScraper:
def __init__(self, url):
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def scrape_page(self):
try:
response = requests.get(self.url, headers=self.headers, timeout=5)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('h1', {'id': 'firstHeading'}).text
content = ''
for paragraph in soup.find_all('p'):
content += paragraph.text + '\n'
return {
'title': title,
'content': content.strip()
}
except requests.exceptions.RequestException as e:
print(f'网络请求失败: {e}')
except Exception as e:
print(f'解析页面时出错: {e}')
return None
class WikipediaKeywordSearch:
def __init__(self, keyword):
self.keyword = keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def search_articles(self, max_results=10):
"""通过Wikipedia API搜索包含关键字的文章"""
url = f'https://en.wikipedia.org/w/api.php?action=query&list=search&srsearch={self.keyword}&srlimit={max_results}&format=json'
try:
response = requests.get(url, headers=self.headers, verify=False, timeout=10)
response.raise_for_status()
data = response.json()
articles = []
for result in data['query']['search']:
article_url = f'https://en.wikipedia.org/wiki/{result["title"].replace(" ", "_")}'
scraper = WikipediaScraper(article_url)
page_content = scraper.scrape_page()
articles.append({
'title': result['title'],
'url': article_url,
'content': page_content['content'] if page_content else ''
})
return articles
except requests.exceptions.RequestException as e:
print(f'搜索失败: {e}')
return []
def save_results(self, articles, file_name='wikipedia_search_results.json'):
"""保存搜索结果到JSON文件"""
with open(file_name, 'w', encoding='utf-8') as f:
json.dump(articles, f, ensure_ascii=False, indent=2)
print(f'搜索结果已保存为 {file_name}')
if __name__ == '__main__':
keyword = 'Artificial Intelligence'
search = WikipediaKeywordSearch(keyword)
articles = search.search_articles(max_results=10)
if articles:
search.save_results(articles)如下所示,是爬虫爬取到的与人工智能相关的内容,包含了百科标题、网址和完整内容:
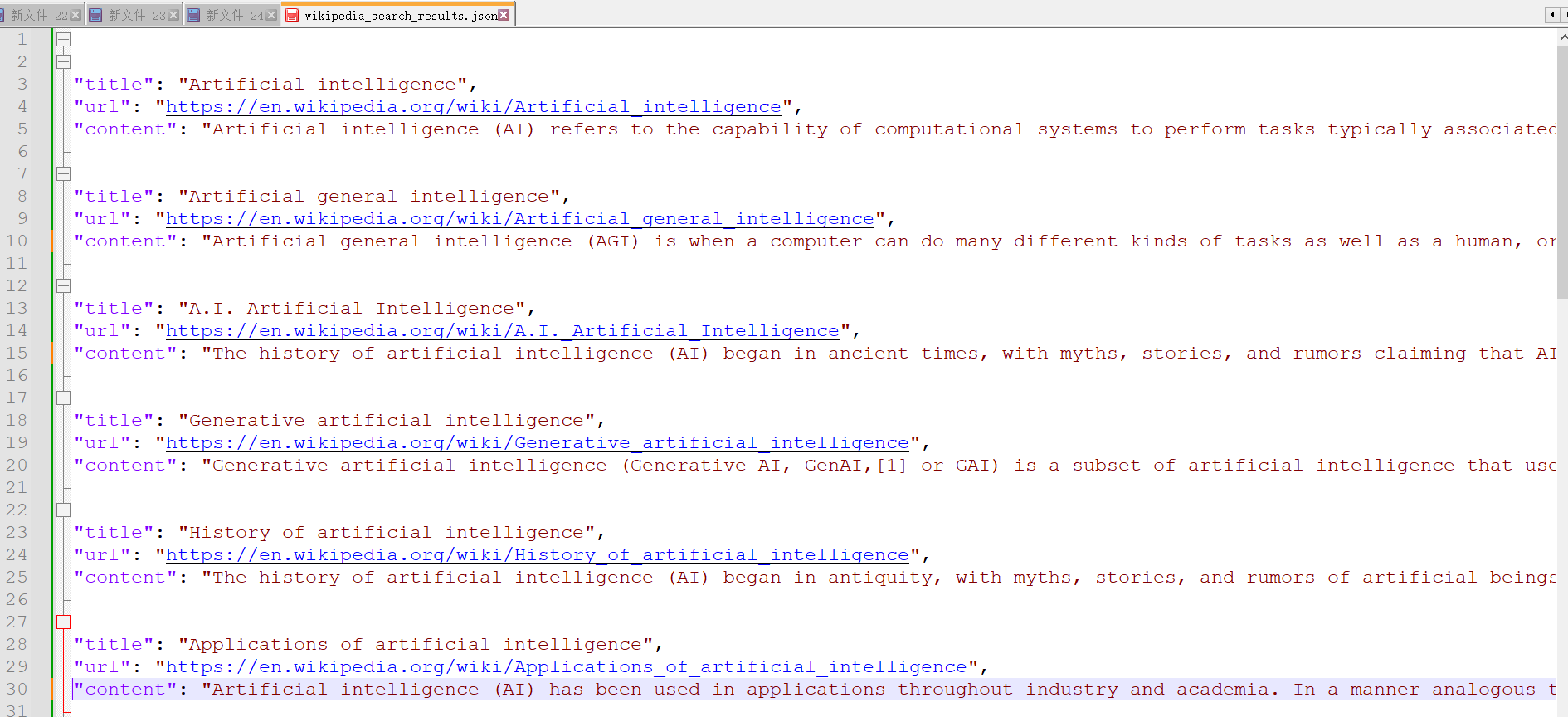
3.3. 传统爬虫的技术局限性
虽然传统爬虫技术在静态网页数据抓取中表现良好,但其局限性也显而易见:
- 动态内容处理:传统爬虫无法直接处理JavaScript动态加载的内容,需要借助其他工具(如Selenium)来模拟浏览器行为。
- 反爬策略:网站常常采用反爬策略如CAPTCHA验证、IP封禁等,传统爬虫难以绕过这些限制。
- 数据量和效率:面对大规模数据需求时,传统爬虫的抓取速度和效率可能不足,需优化代码或采用分布式爬虫技术。
- 维护和升级:随着网站结构的变化,爬虫代码需要频繁更新和维护,以确保数据抓取的准确性。
4. 亮数据网页抓取API:零代码网页抓取解决方案
4.1. 亮数据API的核心优势
亮数据的网页抓取API以零代码配置、全球网络支撑及动态渲染能力为核心,为企业与个人提供高效数据采集方案,具体优势如下:
- 无需编码:亮数据API允许用户通过可视化界面配置采集规则,无需编写复杂的代码。用户只需选择目标网站并设定抓取需求,API即可自动执行数据采集任务。这种简化的流程降低了技术门槛,使非技术人员也能参与数据抓取。
- 全球代理网络规避反爬限制:亮数据API集成了全球代理网络,能够有效规避IP封禁和其他反爬机制。通过智能代理切换,API可以模拟不同的地理位置和设备,提高数据采集的成功率和稳定性。
- 动态页面渲染支持(自动处理JavaScript):面对越来越多使用JavaScript动态加载内容的网站,亮数据API具备动态页面渲染支持。它能够自动处理JavaScript,确保动态内容的准确抓取。用户无需担心传统爬虫无法获取动态数据的问题。
4.2. 零代码实战:维基百科数据自动化采集
4.2.1. 选择爬取目标
访问亮数据官网:网页抓取工具 - 网页爬虫工具 - 免费试用。点击开始免费试用按钮。
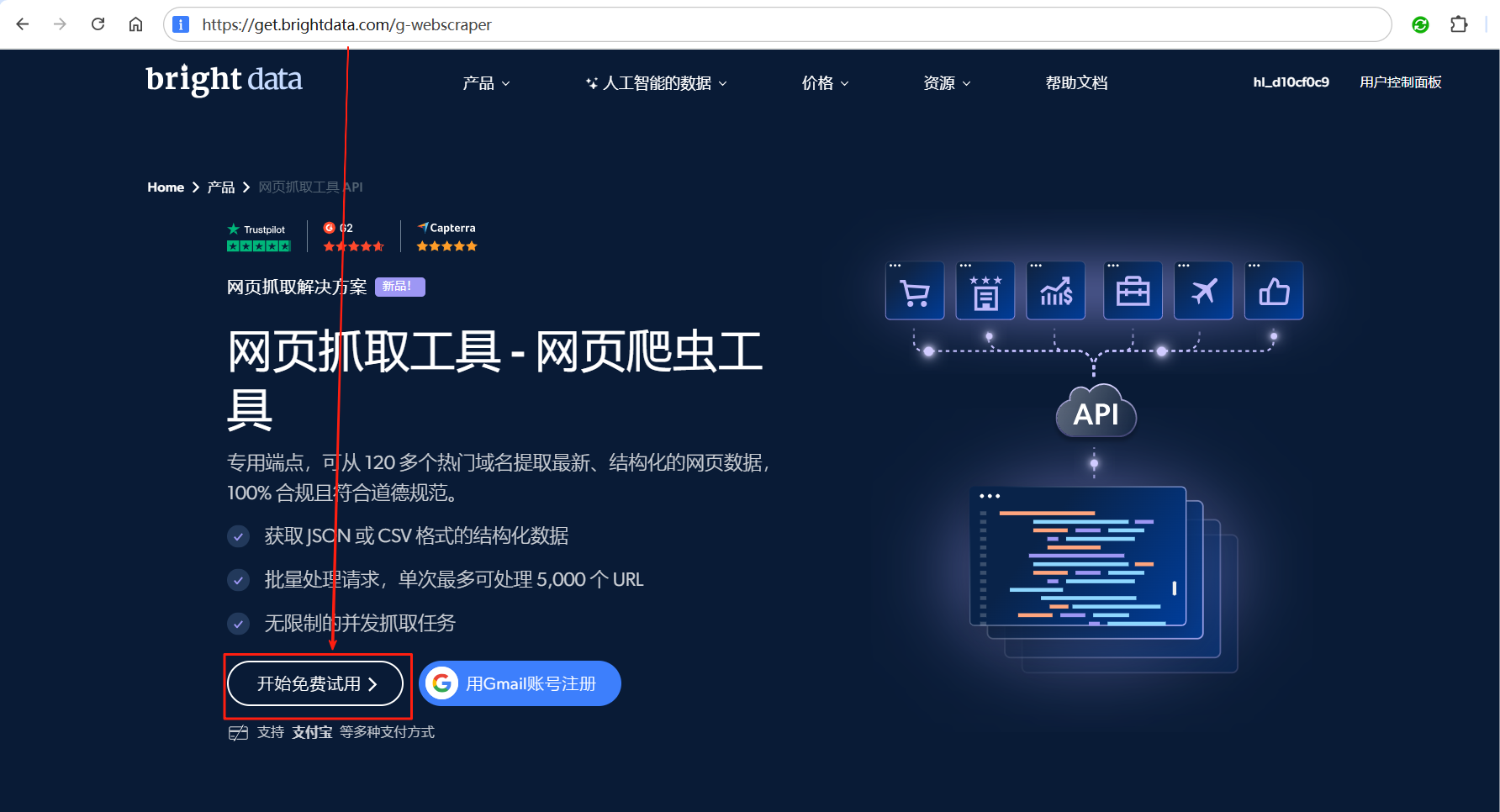
输入邮箱,点击创建账号按钮进行账号注册,然后登录网站。
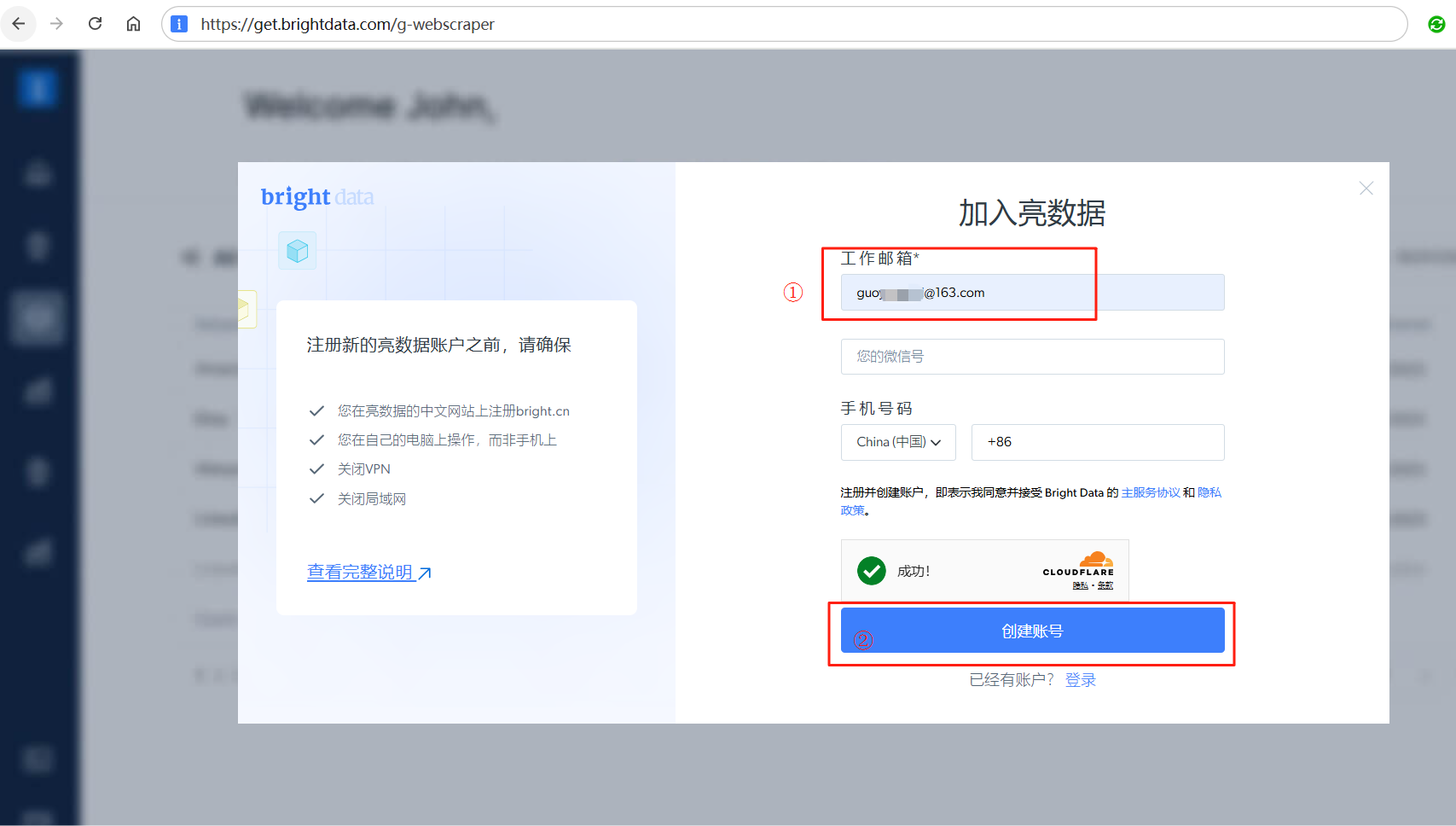
登录成功后,点击左侧的Web Scrapers按钮。
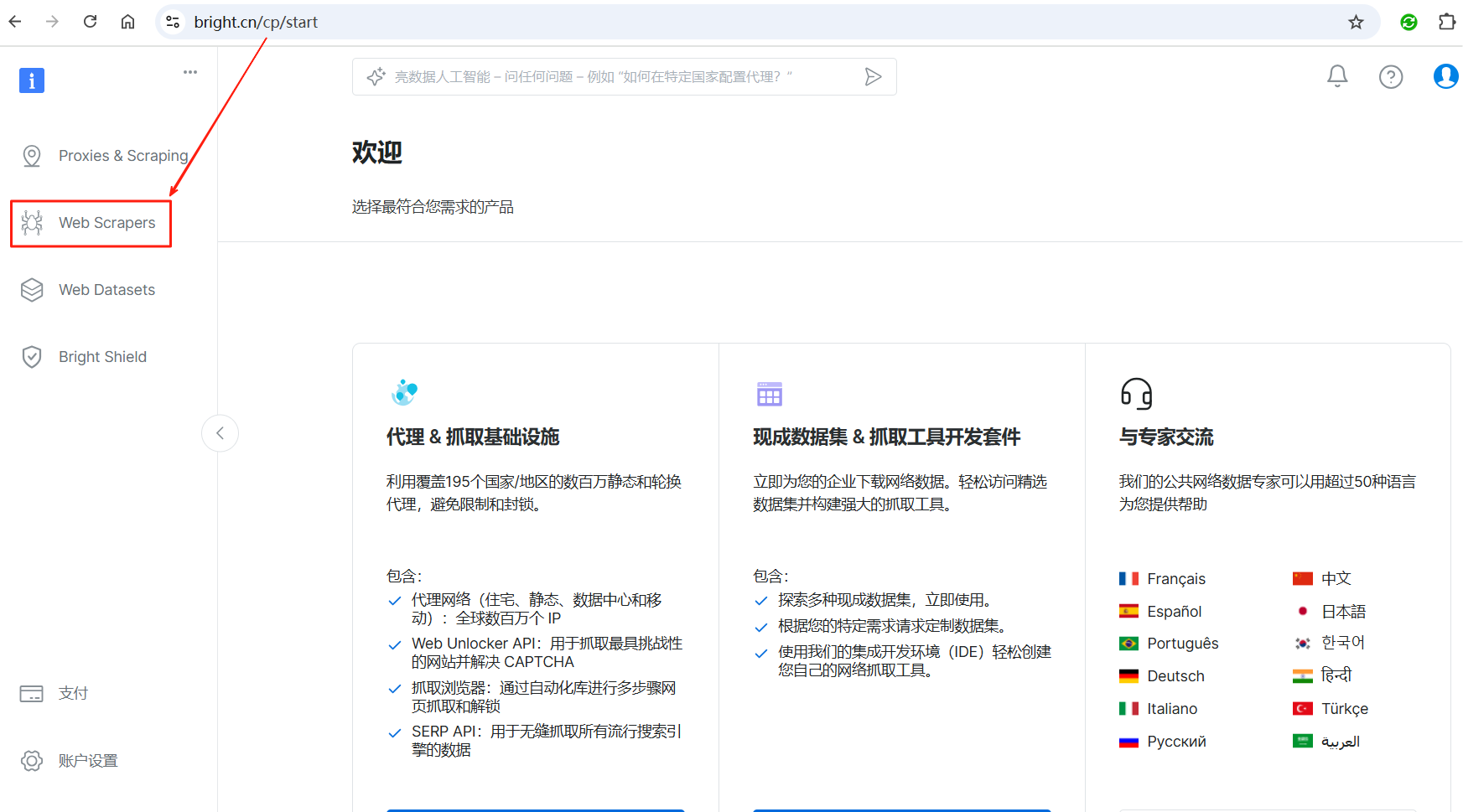
然后点击Web爬虫库,进入网络爬虫市场。
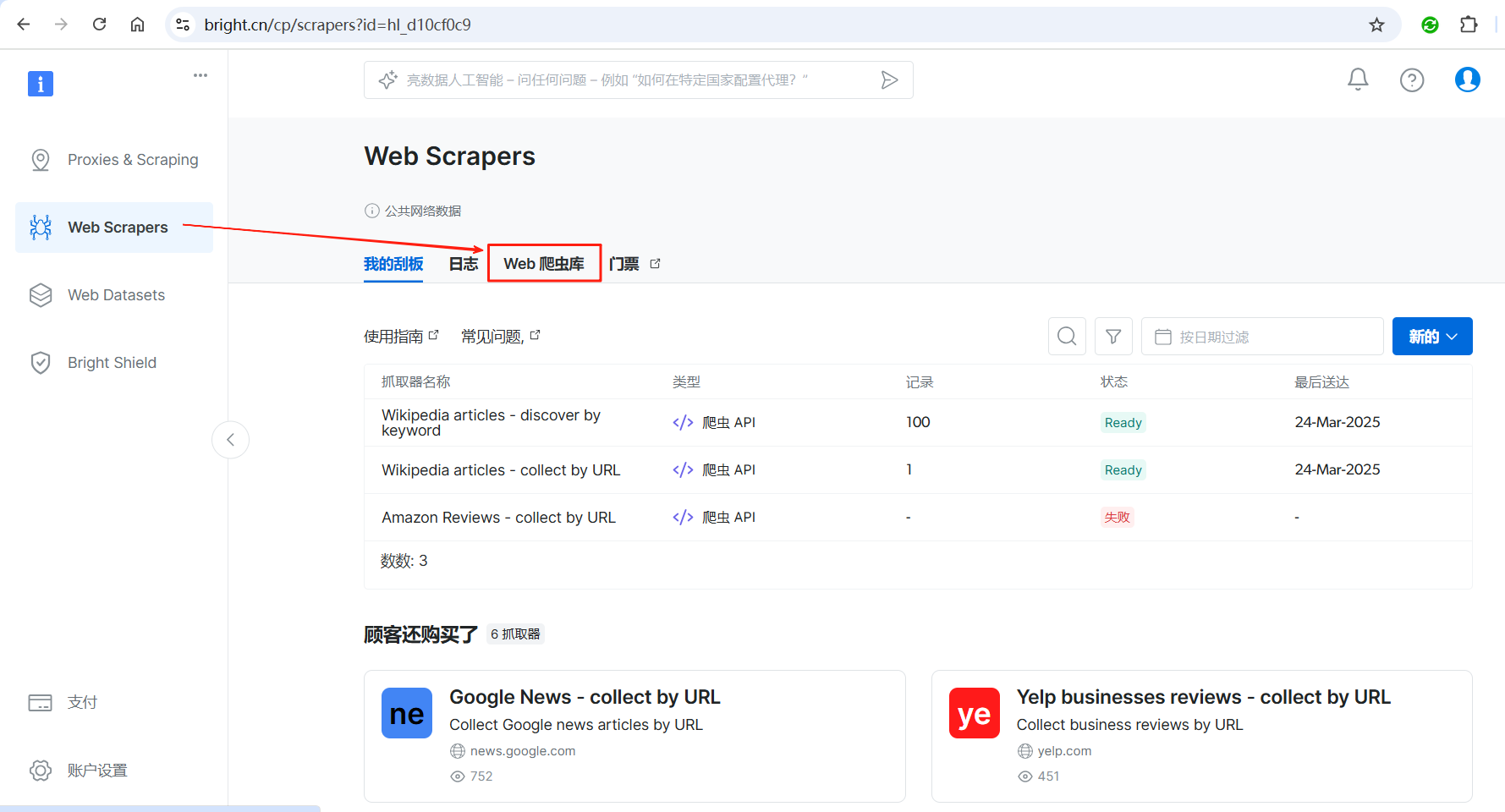
从网络爬虫市场中找到用于AI的数据,然后选择en.wikipedia.org。
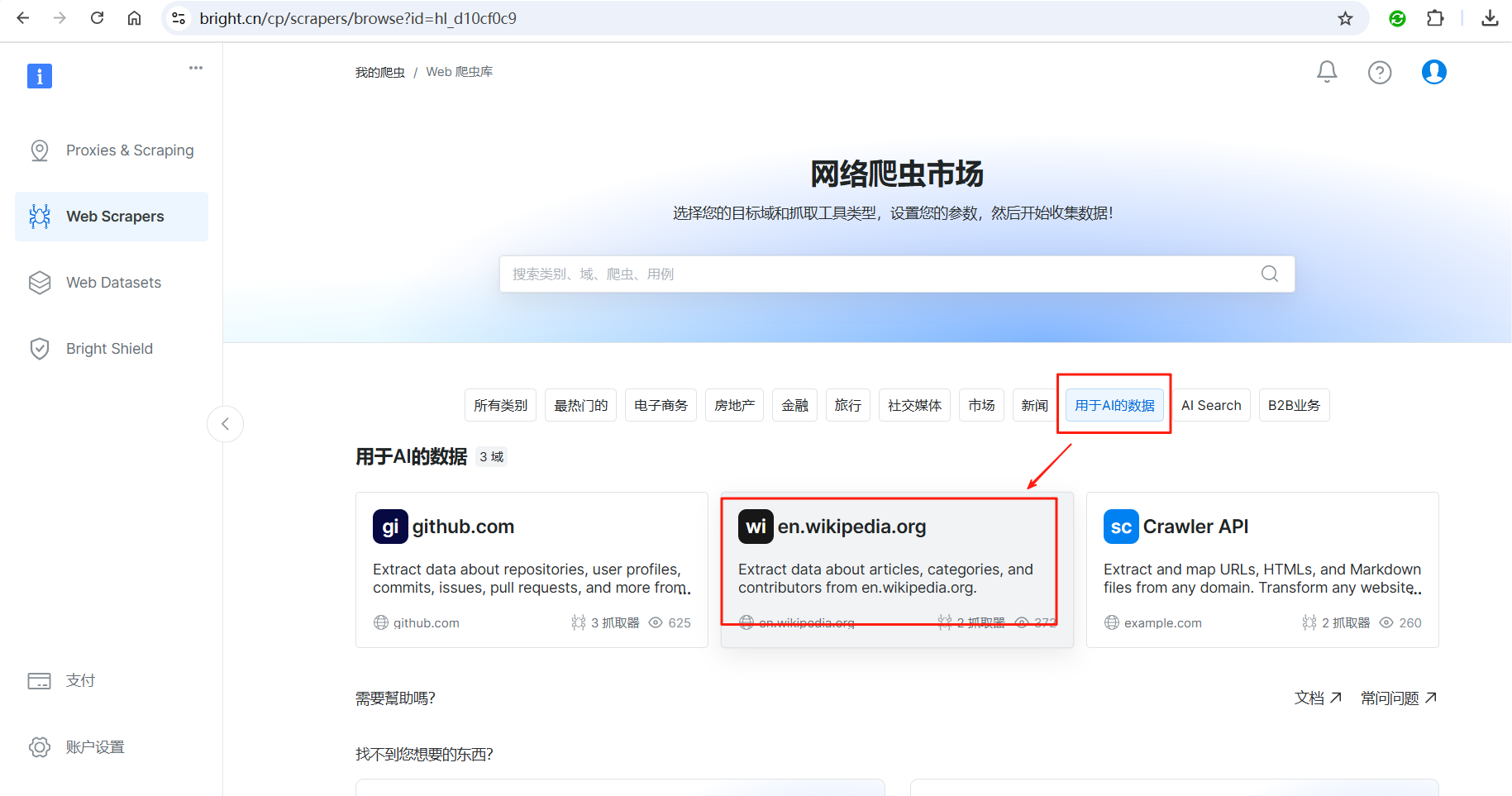
继续找到Wikipedia articles - discover by keyword,也就是按关键字搜索的方式。
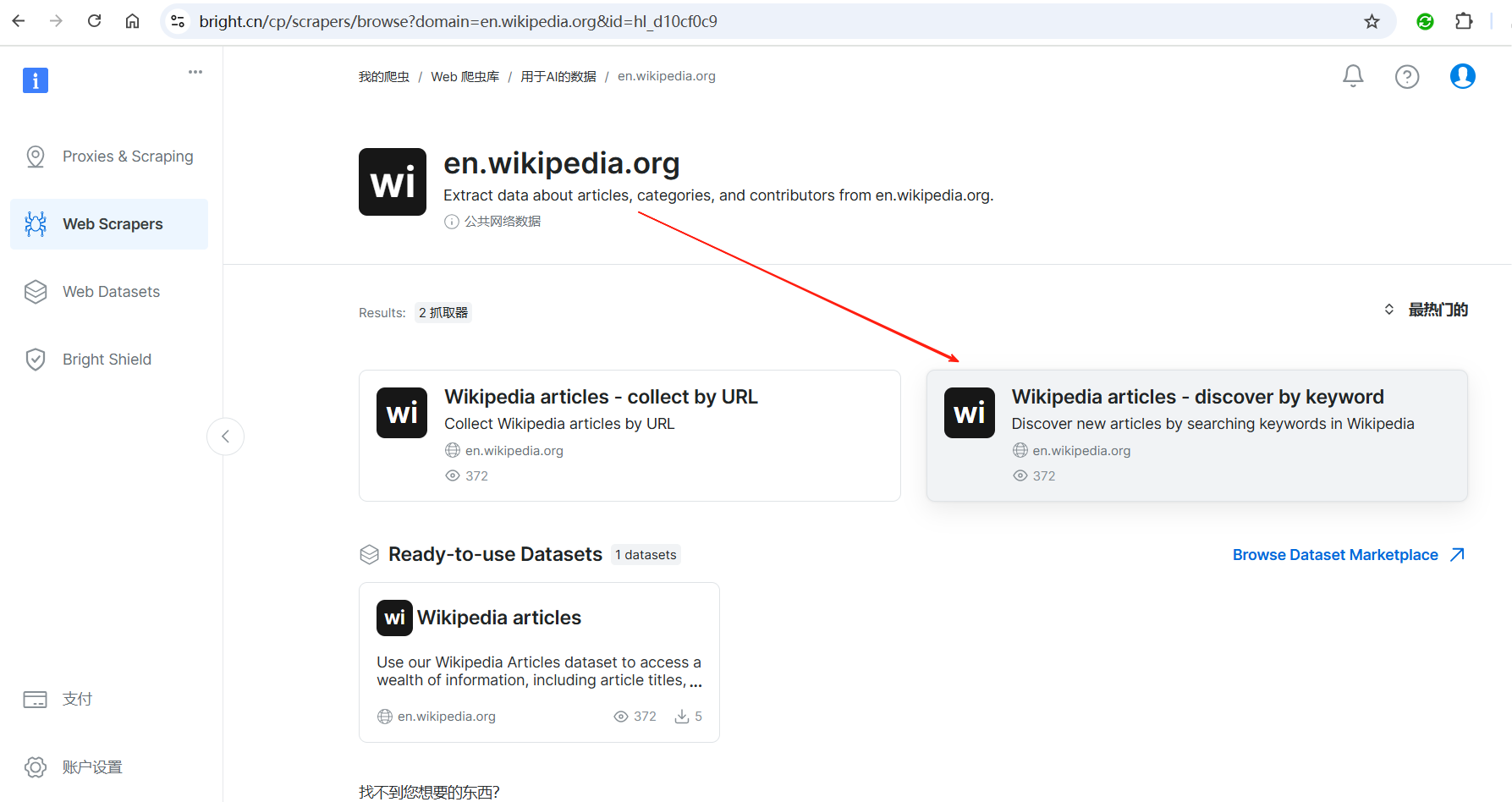
4.2.2. 网页爬取配置
选择无代码抓取器,点击下一个按钮。
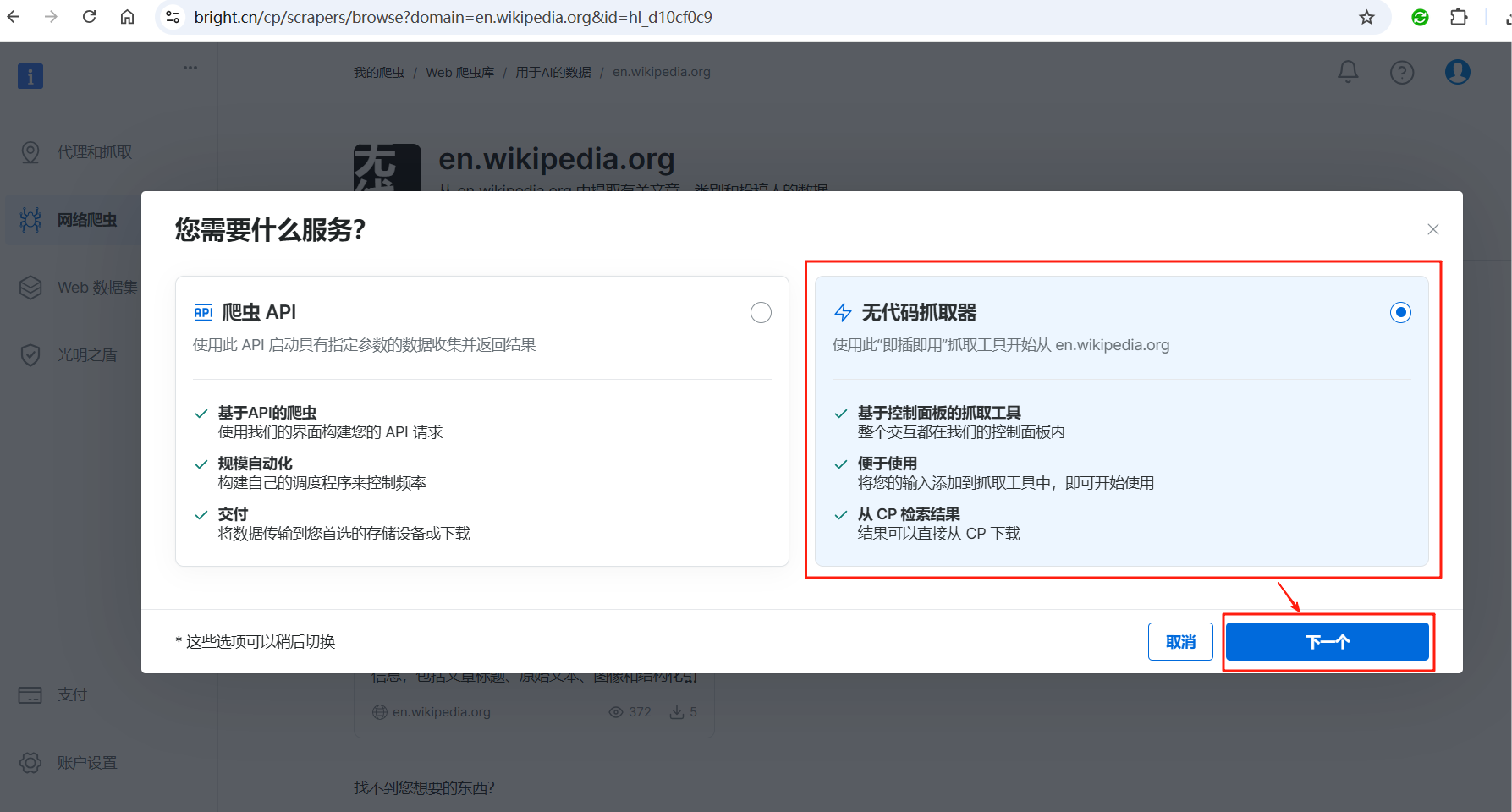
到此,就真正进入了爬虫配置页面,可以看到,我们只需要配置关键词,其它的编码参数和细节亮数据都帮我们搞定并且隐藏起来了(可以切换到词典页查看抓取的信息都有哪些),非常简单。配置好关键字之后,点击右下角的Start collecting按钮,就会自动启动抓取任务了。
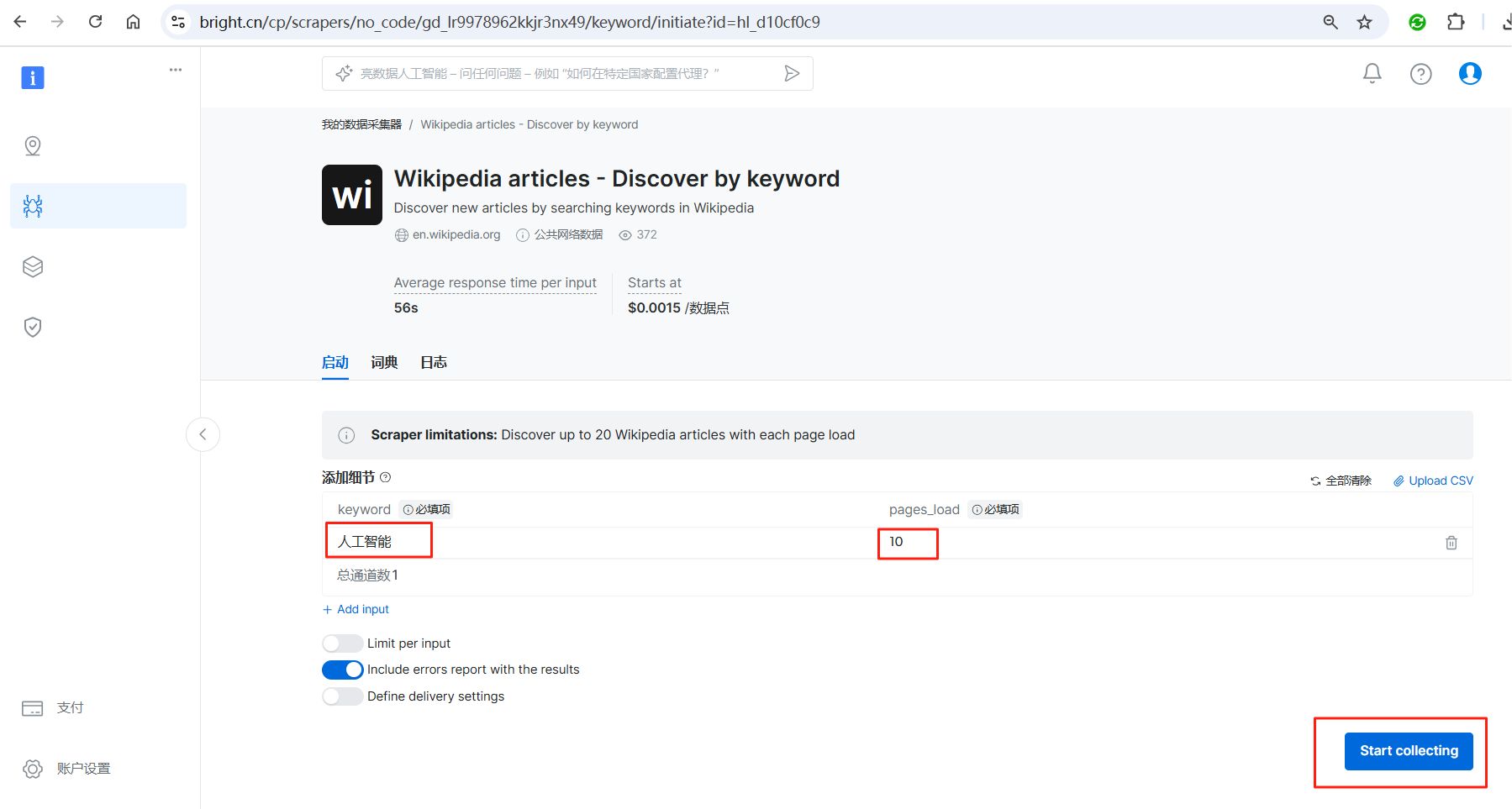
4.2.3. 数据下载
任务启动之后,重新回到Web Scrapers页面,等待刚才启动的任务状态变为Ready之后,点击进入任务详情。
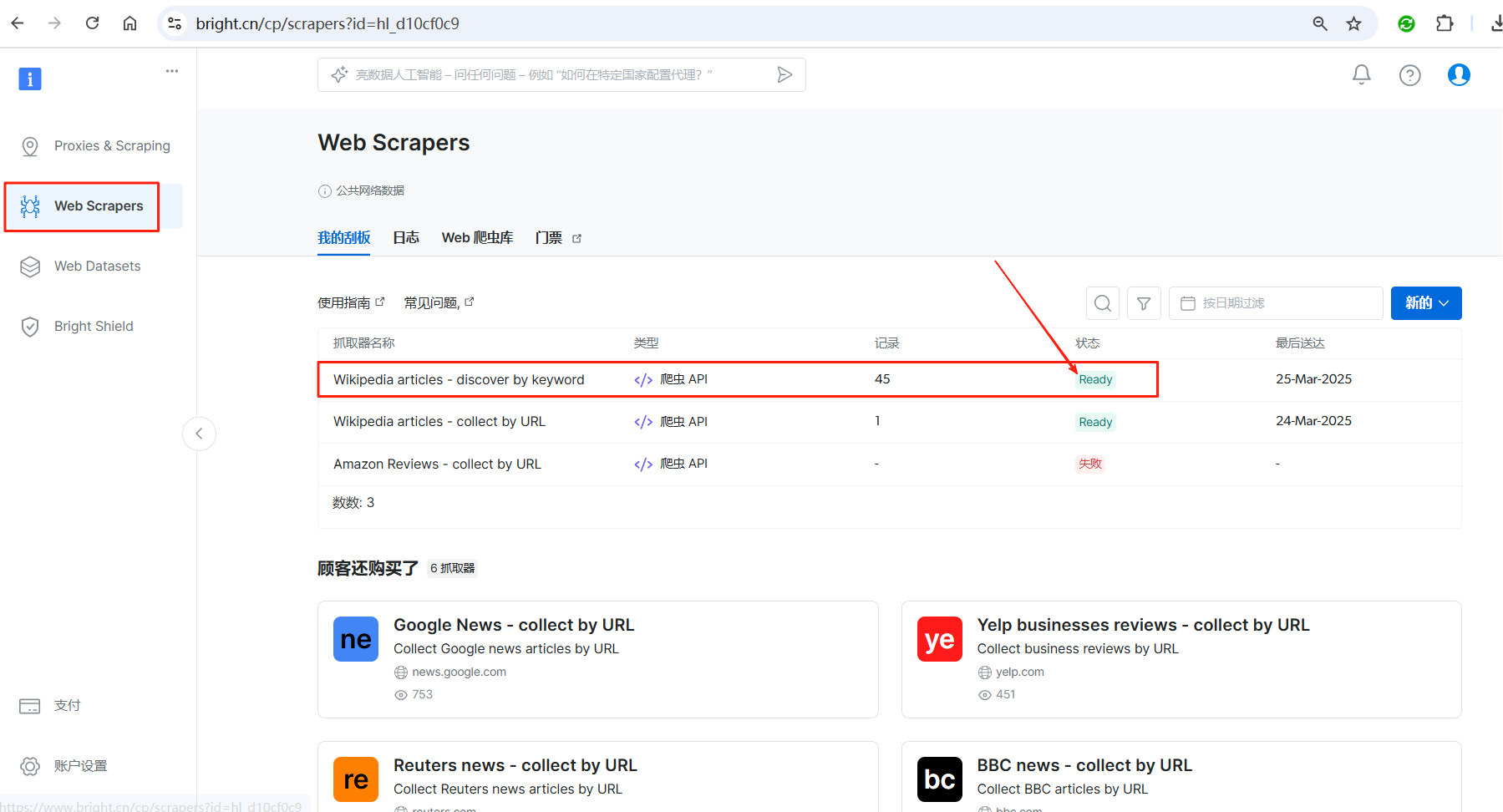
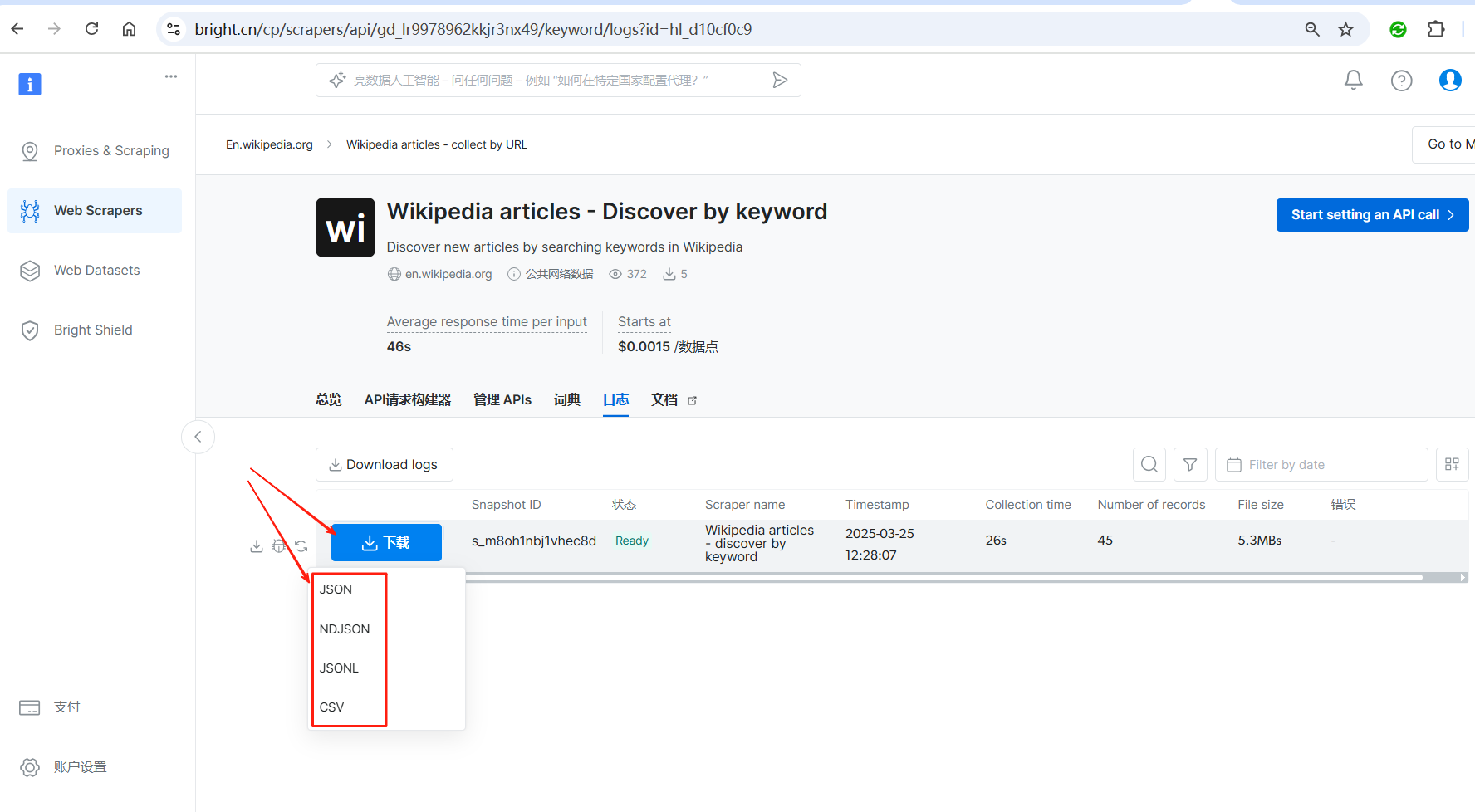
可以看到,我们配置的这个爬虫运行了26秒,收集到了45条数据,数据量5.3MB。然后点击下载按钮,选择需要的格式即可将爬取的数据下载到本地了。
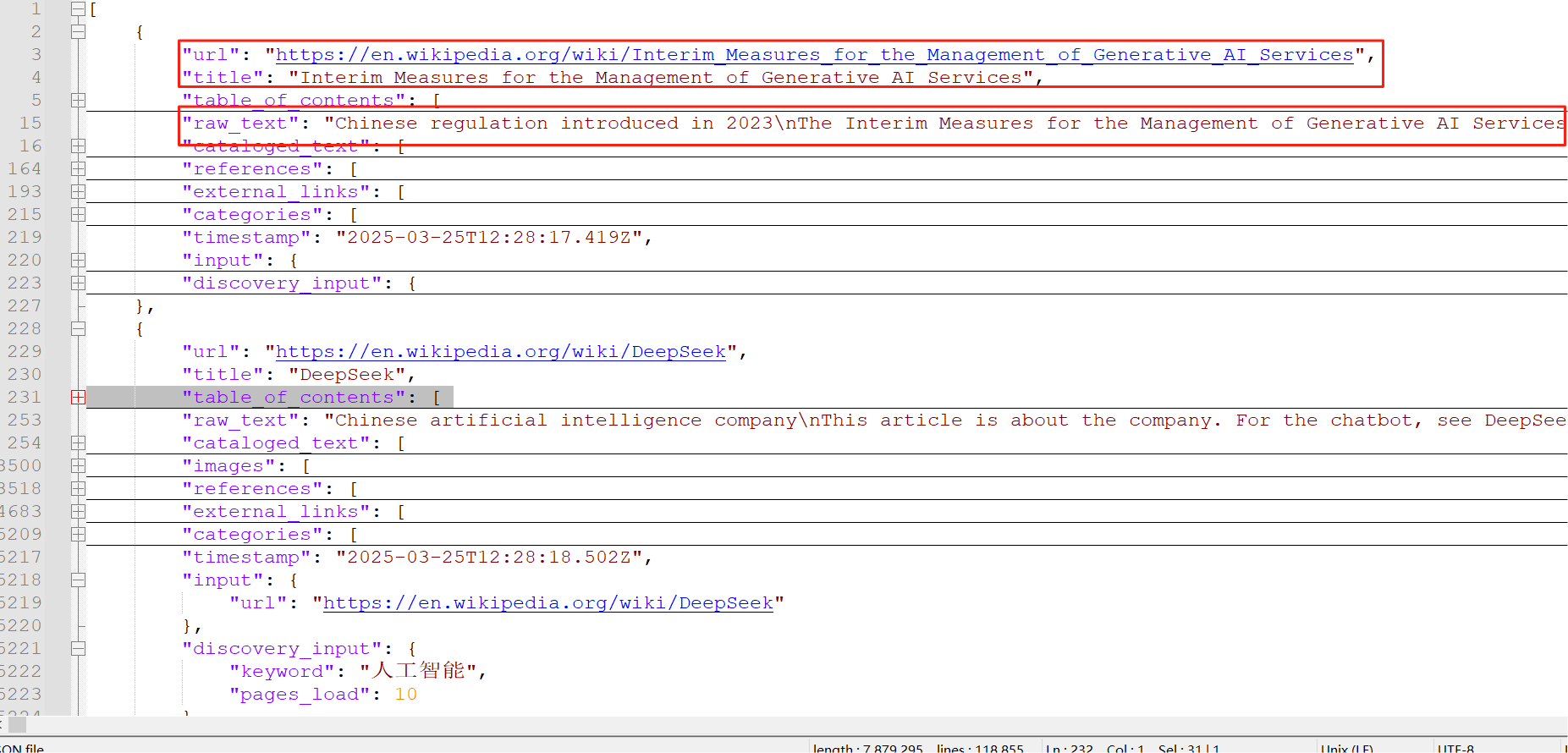
如下所示,是亮数据网页爬取API采集到的json格式数据,可以看到,比我们前面使用传统爬虫技术爬取到的数据量更多,知识更加优质!!
5. AI知识库的应用
AI知识库是智能系统的核心组成部分,通过收集、存储和组织大量数据,支持AI应用做出准确的决策和提供智能服务。以我们爬取的人工智能相关维基百科内容为例,这些信息可以通过智能体知识库发挥价值。
人工智能相关的维基百科内容涵盖广泛的知识,包括AI的基本概念、历史发展、技术应用、伦理问题等。这些信息可以被整合到智能体知识库中,支持智能体(如虚拟助手、聊天机器人等)提供更为丰富和准确的交互体验。
- 知识查询与回答:智能体知识库利用维基百科的结构化信息,帮助智能体快速检索和提供准确的知识回答。例如,用户询问“什么是机器学习?”时,智能体能够从知识库中提取相关定义和应用实例进行解释。
- 语境理解与推理:通过维基百科的内容,智能体知识库可以增强语境理解和推理能力。智能体能够结合上下文信息提供更有深度的回答,支持复杂问题的解答。
- 持续更新与扩展:维基百科内容不断更新,智能体知识库可以实现动态更新,以保持与最新知识同步。这确保了智能体能够提供及时和准确的信息。
6. 高效的数据采集赋能AI快速发展
数据是驱动AI发展的核心要素。通过高效的数据采集方法,我们能够构建丰富的知识库,为AI应用提供强大的支持。亮数据的网页抓取API通过零代码方案大幅降低了数据采集的技术和人力成本。随着零代码方案的崛起,企业将能够更轻松地获取和利用数据,释放数据的潜在价值,推动AI应用的创新和发展。在未来,数据采集技术将继续演进,帮助我们更好地理解和利用数据,赋能各类AI应用场景。
好消息:点击链接注册新账号直接送$2美金,可以免费试用爬取动态代理和自动采集API功能!!!