

作为一种新的商品表现形态,内容几乎存在于手淘用户动线全流程,例如信息流种草内容、搜索消费决策内容、详情页种草内容等。通过低成本、高时效的AIGC内容生成能力,能够从供给端缓解内容生产成本高的问题,通过源源不断的低成本供给倒推消费生态的建立。过去一年,我们通过在视频生成、图文联合生成、个性化文案、人设Agent等核心技术上的持续攻关,AIGC内容生成在手淘多个场景取得了规模化落地价值。本专题《淘宝的AIGC内容生成技术总结》是我们摸索出的一部分实践经验,我们将开启一段时间的内容AI专题连载,欢迎大家一起交流进步。
第三篇《OpenAI o1模型的前世今生》
第四篇《多模态人物视频驱动技术回顾与业务应用》

淘宝法象视频生成大模型能力介绍
图生视频作为最贴近电商应用场景的核心视频生成模型能力,对训练数据、GPU资源、模型结构和训练策略,都有非常高的要求。我们的图生视频模型框架也紧跟行业技术的发展,经历了从UNet架构到DiT架构的演变,进行了长达一年半时间的技术探索、模型迭代和数据积累。目前,我们完成了一版效果稳定的具有电商服饰营销视频特色的图生视频大模型--淘宝法象。
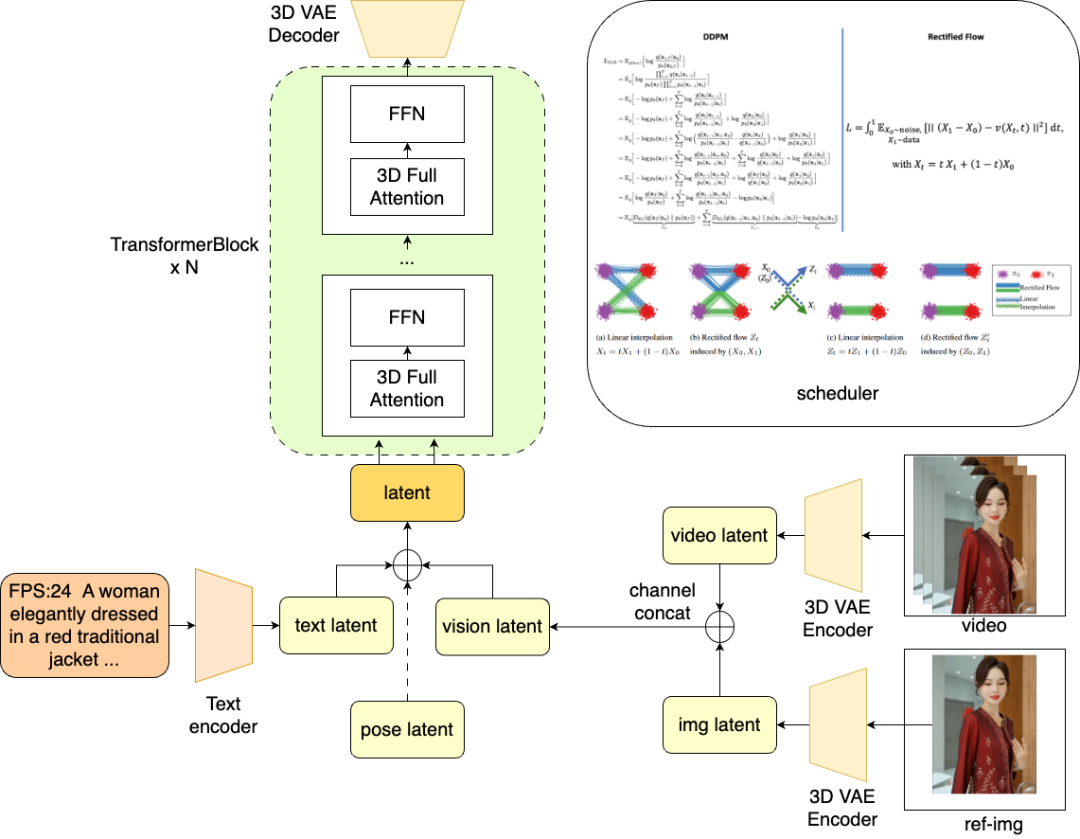

技术优势:
海量垂类电商数据:专注于人物垂领,持续积累、清洗和标注电商营销视频和电商域内容视频,建设了完善数据清洗算子体系,精心清洗2亿+的高质量电商数据,覆盖淘宝全服装品类。
电商领域专家对齐:通用模型生成的结果往往出现手部畸形,表情与动作怪异的问题,部分表情动作也与展示的服装有风格上的差异。通过人类电商专家进行标注打分,我们积累了丰富的人类偏好数据进行模型的对齐学习,让生成的视频更贴合电商应用场景。
精心设计的Lora精调体系:基于强大的基础模型能力,完善在各个细分场景上的功能生态建设,将生态功能lora化,减少模型迭代成本。当前已经构建带有营销文案的图生视频能力支持、运镜、光影、场景变换等lora的开发。
丰富的控制能力:模型支持文本控制、动作幅度控制和运镜控制,同样的图片可以生成多样的视频结果,用户可以根据投放场景定义合适的生成视频风格,一图多用。
丰富的衍生模型能力:“淘宝法象”不仅仅是图生视频!我们构建了一系列视频生成和编辑模型矩阵,包含:视频换衣模型,视频换背景模型,视频生视频模型,视频延展模型,动作驱动图生视频模型,语音驱动图生视频模型,虚拟人驱动模型等等。各项算法能力有层层递进、相互促进的关系,同时可组合出支持不同控制条件的产品级能力,支持多样的应用场景和业务需求,具体效果和应用场景见本文第二部分。

模型特色:
丰富的电商展示形式:通过多维度的控制能力,无论是活泼可爱的童装、严肃专业的职业装还是轻松悠闲的休闲装,模型都能高效生成对应风格的服装展示视频。同时,针对业务不同场景的需要,模型能生成不同分辨率和不同时长的视频片段。
成功率高:人物和画面畸形率低,肢体穿模、人体畸形等概率低,在整个视频生成业界的对比评测中处于最前沿水平。
-
更懂淘宝电商: 训练数据来自海量的淘宝主图视频和营销视频,并且与电商领域人类专家进行偏好对齐,模型有浓厚的淘宝电商特色:模特动作更加专业,针对不同服装品类,模型可以自动推理出合理的表情动作,避免服装模特动作表情与服装风格矛盾冲突。 -
泛化性好: 对生成模特图和真实模特图、复杂场景和棚拍场景、原模特图和换衣模特图,等等,都有较好的泛化性。
业务应用:帮助巨浪外投平台降本增效。基于上述视频生成和编辑模型矩阵,支持了10+不同的素材创意类型。目前AI视频产能整体已占到视频大盘的50%+,CTR、CTCVR分别高于非AI视频70%+和50%+,月曝光PV 4.5亿次,唤端后会话内购买人数和购买金额也已占到大盘的30%和50%,GMV转化效率是非AI视频的2.7倍。

应用场景1:输入平铺服饰图的商家主图视频
商家上传平铺服饰图,直接生成带有卖点讲解文案的可用于主图和种草场景的5-15s视频。此场景已在千牛-生意管家产品上线并开放给商家使用,欢迎试用。
应用场景2:输入模特图的商家主图视频和内容种草视频
应用场景3:虚拟人讲解融合图生视频的混剪视频
应用场景4:视频换衣
通过视频换衣(video tryon)模型,商家上传一段实拍模特视频,根据商品图生成展示新服饰的模特视频,可借此快速丰富店内其他商品的主图视频素材。
应用场景5:视频生视频
应用场景6:视频换背景
通过视频换背景(video background editting)模型,帮助商家对已有视频直接替换背景,生成新场景下的营销视频,满足不同场景营销诉求的同时提升视频丰富性。
-
应用场景7:动作驱动图生视频
-
应用场景8:视频延展
应用场景9:虚拟人讲解
结合人脸生成、视频换衣和口唇驱动三项算法,可以帮助虚拟人讲解营销视频进行从人脸到服饰的形象多样化生成,提升虚拟人营销视频的多样性和转化效率。

我们是淘宝业务技术内容AI-视频生成组,专注于服饰时尚领域,持续迭代服饰上身视频生成基础模型和下游服饰应用模型效果,并持续完善 “淘宝法象” 服饰视频生成的产品化解决方案,面向商家和内容场域,做更灵活可控和多样化的视频生成产品化能力,让AIGC技术充分发挥业务价值。欢迎关注和加入。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。