1. 基础技术(Fundamental Techniques)
1.1 矩阵乘法
对于两个 n × n n×n n×n的矩阵 X X X和 Y Y Y,我们计算它们的乘积 Z = X Y Z=XY Z=XY时,
矩阵 Z Z Z中的每个元素 Z [ i , j ] Z[i,j] Z[i,j]的计算公式为 Z [ i , j ] = ∑ n − 1 k = 0 X [ i , k ] ⋅ Y [ k , j ] Z[i,j]= ∑^{k=0}_{n−1} X[i,k]⋅Y[k,j] Z[i,j]=∑n−1k=0X[i,k]⋅Y[k,j]
这个计算过程的时间复杂度是 O ( n 3 ) O(n^3) O(n3),因为对于每个元素 Z [ i , j ] Z[i,j] Z[i,j],我们需要进行 n n n次乘法和 n − 1 n−1 n−1次加法。
1.1.1 Strassen算法
Strassen算法通过重新组织涉及子矩阵 A A A到 H H H的算术运算,使得计算 I , J , K I, J, K I,J,K和 L L L只需要七个递归矩阵乘法。
Strassen算法定义了七个子矩阵乘积 S 1 S_1 S1到 S 7 S_7 S7: S 1 = A ( F − H ) S_1=A(F−H) S1=A(F−H)
S 2 = ( A + B ) H S_2=(A+B)H S2=(A+B)H
S 3 = ( C + D ) E S_3=(C+D)E S3=(C+D)E
S 4 = D ( G + E ) S_4=D(G+E) S4=D(G+E)
S 5 = ( A + D ) ( E + H ) S_5=(A+D)(E+H) S5=(A+D)(E+H)
S 6 = ( D − E ) ( G + H ) S_6=(D−E)(G+H) S6=(D−E)(G+H)
S 7 = ( A − C ) ( E + F ) S_7=(A−C)(E+F) S7=(A−C)(E+F)
给定这七个子矩阵乘积,我们可以计算 I , J , K I, J, K I,J,K和 L L L: I = S 5 + S 6 + S 4 − S 2 = A E + B G I=S_5+S_6+S_4-S_2=AE+BG I=S5+S6+S4−S2=AE+BG
I = S 1 + S 2 = A F + B H I=S_1+S_2=AF+BH I=S1+S2=AF+BH
K = S 3 + S 4 = C E + D G K=S_3+S_4=CE+DG K=S3+S4=CE+DG
L = S 1 − S 7 − S 3 + S 5 = C F + D H L=S_1-S_7-S_3+S_5=CF+DH L=S1−S7−S3+S5=CF+DH
因此现在我们用递归关系描述这个算法的运行时间 T ( n ) T(n) T(n)为 T ( n ) = 7 T ( n / 2 ) + b n 2 T(n)=7T(n/2)+bn^2 T(n)=7T(n/2)+bn2,其中 b b b是一个大于0的常数。
根据主定理,这里 T ( n ) = O ( n l o g 7 ) T(n)=O(n^{log^7}) T(n)=O(nlog7)
1.1.2 矩阵乘法时间复杂度的发展
ω ω ω是矩阵乘法算法的时间复杂度的下界,即最小的指数,使得对于任何 ϵ > 0 ϵ>0 ϵ>0,算法的时间复杂度为 O ( n ω + ϵ ) O(n^{ω+ϵ}) O(nω+ϵ)。
传统的矩阵乘法算法的时间复杂度为 O ( n 3 ) O(n^3) O(n3),即 ω ≤ 3 ω≤3 ω≤3。
Strassen (1969):Strassen算法首次将 ω ω ω降低到小于2.81。
Pan (1978):进一步将 ω ω ω降低到小于2.79。
Bini et al. (1979):将 ω ω ω降低到小于2.78。
Schönhage (1981):将 ω ω ω降低到小于2.555。
Pan; Romani; Coppersmith + Winograd (1981-1982):将 ω ω ω降低到小于2.50。
Strassen (1987):将 ω ω ω降低到小于2.48。
Coppersmith + Winograd (1987):将 ω ω ω降低到小于2.375。
Stothers (2010):将 ω ω ω降低到小于2.3737。
Williams (2011):将 ω ω ω降低到小于2.3729。
Le Gall (2014):将 ω ω ω降低到小于2.37286。
1.2 计算逆序对(Counting inversions)
逆序对是指在一个有序集合中,前面的元素大于后面的元素。
假设你已经对一组电影或书籍进行了评分,从你最喜欢的(排名第1)到最不喜欢的(排名第n)进行了排序。
为了给你提供推荐,网站希望将你的评分与其他人的评分进行比较,以查看它们有多相似,比较的方式是通过计算逆序对的数量来实现的。
下面我们给出逆序对的详细定义,假设有一组排列 a 1 , a 2 , a 3 , . . . , a n a_1,a_2,a_3,...,a_n a1,a2,a3,...,an,
如果存在一对整数 i i i和 j j j,满足 i < j i<j i<j,但排列中的位置满足 a i > a j a_i>a_j ai>aj ,那么我们称这对整数 i , j i,j i,j形成了一个逆序对(inversion)。
下面给出几个例子。
例1:排列 1 2 4 3
这个排列中只有一个逆序对:(4, 3),因为4在3之前。
例2:排列 1 4 3 2:
这个排列中有三个逆序对:(4, 3);(4, 2);(3, 2)。
所以我们想找到逆序对的数量其实需要计算所有不按顺序排列的元素对 i i i和 j j j,其中 i ≠ j i≠j i=j。
对于一个包含 n 个元素的排列,逆序对的数量可以从0开始,一直到最大值 ( n 2 ) = n ( n − 1 ) / 2 \binom{n}{2}= n(n−1)/2 (2n)=n(n−1)/2 (排列组合)。
最大值 ( n 2 ) \binom{n}{2} (2n)出现在排列是逆序的情况下,即元素按照从大到小的顺序排列(例如, n , n − 1 , . . . , 2 , 1 n,n-1,... ,2,1 n,n−1,...,2,1)。
因此,例3:排列 2 1 3 4 5
这个排列中只有一个逆序对:(2, 1)。
例4:排列 2 3 4 5 1
这个排列中有四个逆序对(2, 1);(3, 1);(4, 1);(5, 1)。
因此我们现在是用最直观的方法是检查所有可能的元素对 ( i , j ) (i,j) (i,j),以确定它们是否构成逆序对。由于有 n n n个元素,总共有 ( n 2 ) \binom{n}{2} (2n)对元素对需要检查,所以这种方法的时间复杂度为 O ( n 2 ) O(n^2) O(n2),因为它需要对每一对元素进行比较。
如果我们使用分治法去解决这个问题呢?它的时间复杂度会降为 O ( n l o g n ) O(nlogn) O(nlogn)。
用分治法计算逆序对的步骤如下:
- 首先将给定的排列(或称为置换)分成两个大致相等的部分。
- 然后递归地计算每个部分中的逆序对数量。
- 通过上述步骤,我们可以得到大部分逆序对的数量。接下来需要计算那些涉及第一部分和第二部分元素的逆序对数量。
- 为了计算这些涉及两部分的逆序对,我们需要对每个子列表进行排序,并将它们合并成一个单一的(已排序的)列表。在合并的过程中,我们可以计算上述提到的逆序对(因为在合并两个排序列表时,每当我们从第二个列表中选择一个元素,并且第一个列表中有尚未处理的剩余元素时,就会与这些元素中大于自己的元素形成逆序对)。
如下图所示。
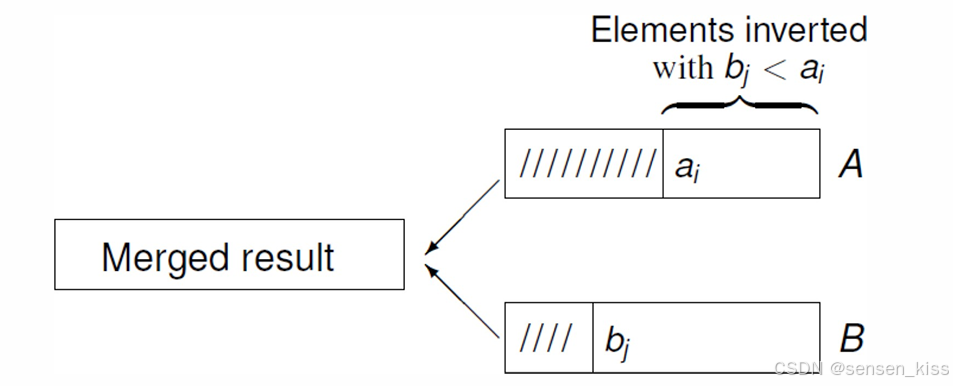
在合并 A A A和 B B B的过程中,每当从列表 B B B中取出一个元素 b j b_j bj并将其放入合并结果中时,它会与列表 A A A中所有尚未处理的、且大于 b j b_j bj的元素形成逆序对。
因为在最终的合并结果中, b j b_j bj应该出现在所有这些 A A A中元素的后面,但由于我们是从 B B B中按顺序取出元素,所以 b j b_j bj会先于这些 A A A中的元素出现,从而形成逆序对。
这种方法实际上是对归并排序算法的一个修改,它在合并两个排序列表时计算逆序对的数量,因此它的时间复杂度是 O ( n l o g n ) O(nlogn) O(nlogn)。
其的伪代码如下。
COUNTINVERSIONS(L)
Input: A list, L, of distinct integers.
Output: The number of inversions in L.
if L has one element in it then
there are no inversions, so Return (0, L)
else
Divide the list into two halves
A contains the first ⌊n/2⌋ elements
B contains the last ⌊n/2⌋ elements
(k_A, A) = COUNTINVERSIONS(A)
(k_B, B) = COUNTINVERSIONS(B)
(k, L) = MERGEANDCOUNT(A, B)
Return (k_A + k_B + k, L)
MERGEANDCOUNT(A, B)
Current_A ← 0
Current_B ← 0
Count ← 0
L ← empty list
while both lists (A and B) are non-empty do
Let a_i and b_j denote the elements pointed to by Current_A and Current_B.
Append the smaller of a_i and b_j to L.
if b_j is the smaller element then
Increase Count by the number of elements remaining in A.
Advance the Current pointer of the appropriate list.
Once one of A and B is empty, append the remaining elements to L.
Return (Count, L)
通过计算逆序对数量,我们可以用逆序对数量来衡量一个排列与标准排列的相似度。逆序对的数量越少,表示排列越接近标准排列,相似度越高。逆序对的数量越多,表示排列与标准排列的差异越大,相似度越低。
2. 优化问题(Optimization Problems)
优化问题是指存在多种可能解决方案的问题,每种解决方案都有一个特定的值(比如成本、收益等),我们的目标是找到一个具有最优(最大或最小)值的解决方案。
优化问题的算法通常会经历一系列步骤,每一步都有一组选择。
因此就诞生了贪心算法(Greedy Algorithm)。
2.1 贪心算法(Greedy Algorithm)
贪心算法(Greedy Algorithm)是一种在每一步选择中都采取当前状态下最优(最有利)的选择,希望这样能导致全局最优解的算法策略。
注意:贪心方法并不总是能得到最优解。因为贪心方法没有考虑到所有可能的未来步骤,有时候可能会因为短视而做出不是最佳的整体决策,即无法得到全局最优解。
如果一个问题可以通过贪心方法解决,那么这个问题就具有贪心选择性质(Greedy-Choice Property)。
对于某些难以解决(NP难或NP完全)的问题,贪心方法可以用来生成近似解。
2.1.1 背包问题(Knapsack Problem)
背包问题是一个经典的优化问题,其中:
S S S是一个包含 n n n个物品的集合。
每个物品 i i i有一个正的重量 w i w_i wi和一个正的收益 b i b_i bi。
目标是找到一个子集,使得该子集的总重量不超过给定的总重量(容量) W W W,并且总收益最大。
贪心算法在背包问题中可能无法找到最优解。
例如这个例子:
物品:(3, 7); (4, 9); (5, 9); (2, 2)(重量和收益),最大重量:6
贪心算法可能会按照收益与重量的比率(即 w i / b i w_i/b_i wi/bi)来选择物品,选择比率最大的物品,直到达到最大重量。
因此计算后会先选择(3,7),因为其比率最高,然后选择(2, 2),因为它们的总重量不超过6.
但是选择(2, 2) 和 (3, 7) 的总收益为 2 + 7 = 9 2+7=9 2+7=9。
在这个例子中,贪心算法并没有找到最优解。
2.1.2 分数背包问题(Fractional Knapsack Problem, FKP)
它是经典背包问题的一个变体,它允许我们选择物品的一部分,而不是只能完整地选择或不选择一个物品。
现在问题的目标是找到总收益最大的物品子集,使得这些物品的总重量不超过给定的总重量 W W W。
在分数背包问题中,我们允许取每个物品的任意部分 x i x_i xi,即 0 ≤ x i ≤ w i 0≤x_i≤w_i 0≤xi≤wi对于所有 i i i,其中 w i w_i wi是第 i i i个物品的重量。
所有选择的物品的重量之和不超过总重量 W W W,即 ∑ i ∈ S x i ≤ W ∑_{i∈S}x_i≤W ∑i∈Sxi≤W
选择的物品的总收益为 ∑ i ∈ S b i ( x i / w i ) ∑_{i∈S}b_i(x_i/w_i) ∑i∈Sbi(xi/wi),其中 b i b_i bi是第 i i i个物体的收益,其中 x i x_i xi是第 i i i个物体选择的重量,其中 w i w_i wi是第 i i i个物体的总重量。
我们可以使用上一章我们学习的堆的优先队列来解决分数背包问题,这里我们使用一个最大堆来存储物品集合 S S S中的物品每个物品在堆中都有一个键(key),这个键是物品的“价值指数”(value index),即单位重量的收益 b i / w i b_i/w_i bi/wi。
和前面例子一样:物品:(3, 7); (4, 9); (5, 9); (2, 2)(重量和收益),价值指数分别为:2.33;2.25;1.8;1。因此 2.33 在根节点。
现在我们分数背包问题就可以充分利用现在的价值参数,因为我们可以充分的利用背包的空间,因此现在它满足贪心选择性质。
所以我们在每一步可以选择尽可能多的当前价值指数(单位重量的收益)最大的物品,该物品拿完后如果背包有剩余容量就继续选择价值指数次大的物品,依此类推,直到达到重量限制 W W W。
由于我们使用最大堆去储存价值指数,所以每一步都是从堆中移除(并可能添加)一个物品,因此时间是 O ( l o g n ) O(logn) O(logn)。
因此算法的步骤是先对物品的价值指数对所有物品进行排序,这一步需要 O ( n l o g n ) O(nlogn) O(nlogn)时间,然后按照排序选择每个物体知道到达限制 W W W,这一步需要 O ( n l o g n ) O(nlogn) O(nlogn)时间。
所以整个算法的总时间复杂度是 O ( n l o g n ) O(nlogn) O(nlogn)。
它的伪代码如下。
FRACTIONALKNAPSACK(S, W)
// Input: Set S of items, item i has weight w_i and benefit b_i,
// maximum total weight W.
// Output: Amount x_i of each item to maximize the total benefit.
for i ← 1 to |S| do
x_i ← 0
v_i ← b_i / w_i
Insert (v_i, i) into a heap H (max value index at root).
w ← 0
while w < W do
Remove the max value from H.
a ← min{w_i, W - w}
x_i ← a
w ← w + a
2.1.3 区间调度问题(Interval Scheduling Problem)
我们有一组任务,这些任务需要使用单一的资源来执行,每个任务都有一个开始时间和结束时间,可以表示为一个时间区间。
我们的目标是从所有任务中选择一个子集,以便在单一资源上安排尽可能多的任务。
假设我们有一个任务集合 T T T,包含 n n n个任务,每个任务 i i i有一个开始时间 s i s_i si和一个结束时间 f i f_i fi。
两个任务 i i i和 j j j是非冲突的是 f i ≤ s j f_i≤s_j fi≤sj或 s i ≤ f j s_i≤f_j si≤fj,即任务 i i i的结束时间不晚于任务 j j j的开始时间,或者任务 j j j的结束时间不晚于任务 i i i的开始时间。
在这个问题中我们如果使用贪心算法,假设总是选择最早开始的可用任务。
下面的例子是贪心算法并非最优解的证明。
任务集合 S={1,2,3,4,5},每个任务的开始时间和结束时间如下:
任务1:开始时间 S 1 = 0 S_1=0 S1=0,结束时间 f 1 = 20 f_1 =20 f1=20
任务2:开始时间 S 2 = 1 S_2=1 S2=1,结束时间 f 1 = 4 f_1 =4 f1=4
任务3:开始时间 S 3 = 6 S_3=6 S3=6,结束时间 f 1 = 10 f_1 =10 f1=10
任务4:开始时间 S 4 = 12 S_4=12 S4=12,结束时间 f 1 = 15 f_1 =15 f1=15
任务5:开始时间 S 5 = 16 S_5=16 S5=16,结束时间 f 1 = 19 f_1 =19 f1=19

如果按照最早开始时间的贪心策略,我们会选择任务1。然而,这会导致我们只能接受一个任务,而最优解是选择任务2、3、4和5,这样可以安排四个任务。
如果我们试着将我们的策略改为选择持续时间(结束时间-开始时间)最短的任务优先呢?
它能解决上面的例子,但是如果有任务重复呢,如下图所示。
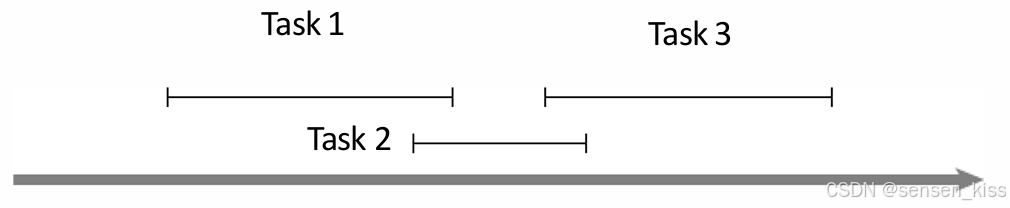
我们按照这个策略会选择任务2,但是任务1和任务3在整体上比单独选择任务2更好。
那我们现在的策略是选择结束时间最早呢?
下图给出了一个有九个任务的例子。
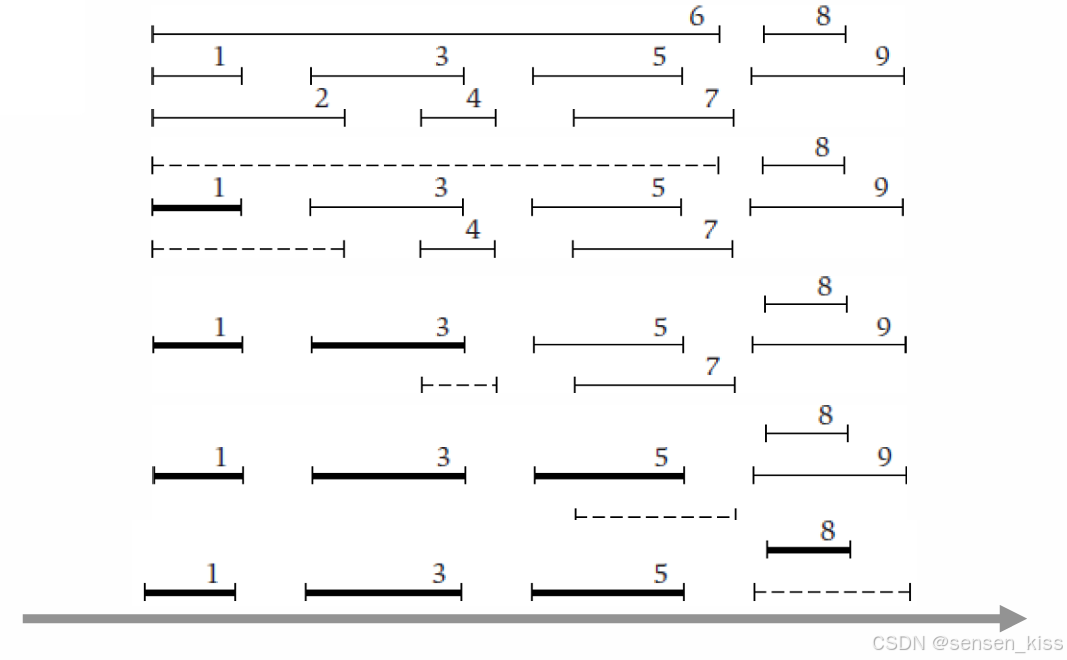
按照这个策略选择了任务1、任务3、任务5、任务8。
这种策略能帮助我们找到关于区间调度问题的全局最优解。
因此关于解决区间调度问题的算法如下。
- 首先,根据任务的结束时间对所有任务进行排序。这一步是算法中时间消耗最大的部分,需要 O ( n l o g n ) O(nlogn) O(nlogn)时间。
- 从排序后的任务列表中,选择结束时间最早的任务。
- 移除所有与已选择任务冲突的任务。两个任务冲突的条件是它们的时间区间有重叠。
- 重复步骤2和3,直到所有任务都被考虑。
伪代码如下。
INTERVALSCHEDULE(T)
Input: A set, T, of tasks with start times and end times.
Output: A maximum-size subset, A, of non-conflicting tasks.
A ← ∅
while T ≠ ∅ do
Remove the task t with earliest completion time.
Add t to A
Delete all tasks from T that conflict with t
Return the set A as the set of scheduled tasks
2.1.4 任务调度问题(Task Scheduling Problem)
这个问题和前面的问题类似。
假设我们有一组 n n n个任务,每个任务都有开始时间和结束时间。
我们希望在尽可能少的机器上调度所有任务,且任务之间不能有冲突。
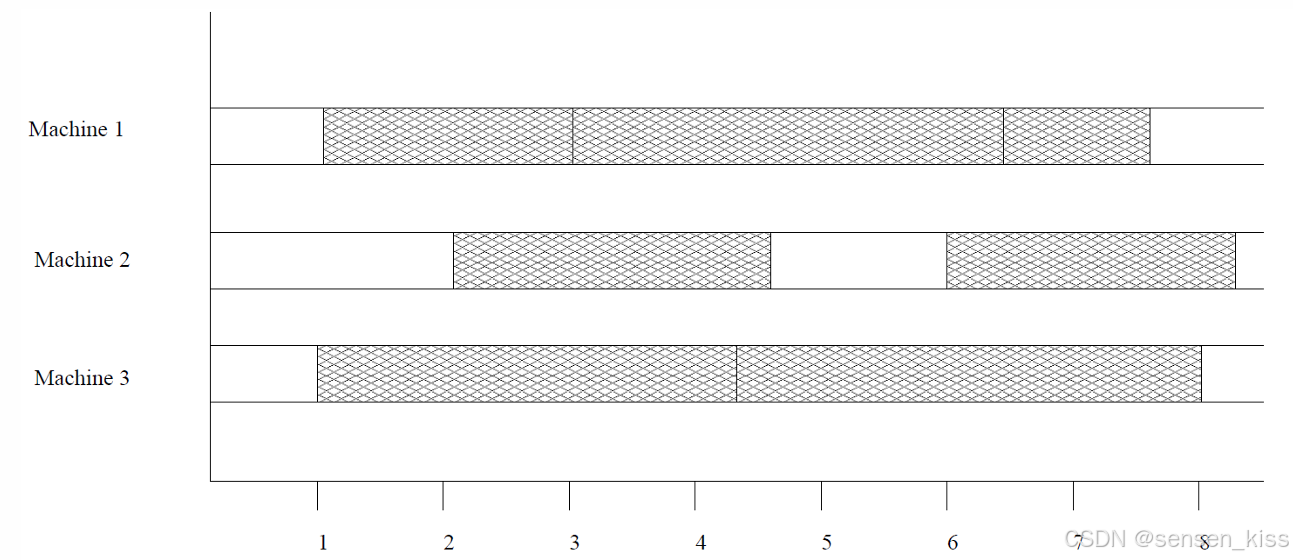
在这个问题上,贪心算法依然有效。
我们按照任务的开始时间对任务进行排序,并尝试将每个任务分配到可用的机器上,否则我们安排一个新的机器,重复这个过程知道我们考虑到了所有的任务。
伪代码如下。
TASKSCHEDULE(T)
Input: A set, T, of tasks with start times and end times.
Output: A non-conflicting schedule of the T tasks.
m ← 0
while T ≠ ∅ do
REMOVEMIN(T) // Remove the task with the earliest start time
if ∃ machine j with no conflicts
then SCHEDULE(i, j) // Schedule task i on machine j
else
m ← m + 1
SCHEDULE(i, m) // Schedule task i on a new machine
2.2 动态规划(Dynamic Programming)
动态规划技术与分治法(divide-and-conquer)相似,都是将问题分解成更小的子问题来解决。
它的区别主要是动态规划通过存储已经计算过的值到一个特殊表格中,避免了重复计算相同子问题的结果,而分治法则可能需要重复解决相同的子问题。
动态规划主要用于优化问题,即在给定的约束条件下寻找最优解。在蛮力搜索(brute force search)寻找最优值不可行的情况下,动态规划经常被应用。
但是动态规划只有在问题具有可以利用的某种结构时才有效。
其的特征(Hallmarks)如下:
- 最优子结构(Optimal Substructure):
这意味着问题的最优解由其子问题的最优解组成。换句话说,如果我们能够解决子问题,那么可以通过组合这些子问题的解来构建原问题的最优解。 - 重叠子问题(Overlapping Subproblems):
在动态规划中,虽然总共只有少数几个不同的子问题,但这些子问题会在递归算法中被重复计算多次。通过存储这些子问题的解,可以避免重复计算,从而提高效率。
基本思想(Basic Idea)如下:
动态规划通常采用自底向上的方法,即先解决最小的子问题,然后使用这些解来构建更大问题的解。这种方法通常涉及到构建一个表格,用于存储已经解决的子问题的解。
变体(Variations)如下:
虽然通常动态规划涉及到构建一个二维表格来存储子问题的解,但实际上这个“表格”可以有更多维度,比如三维数组,或者可以是树形结构等,具体取决于问题的需求和结构。
2.2.1 {0, 1}背包问题(The {0, 1} Knapsack Problem)
{0, 1}背包问题与分数背包问题不同,{0, 1}背包问题中不允许选择物品的一部分。对于每个物品,你只能选择包含它(取值为1)或不包含它(取值为0)。
因此贪心算法不适用于解决该问题,但是可以使用动态规划去解决该问题。
这里集合 S S S表示包含 n n n个物品的集合,物品 i i i:每个物品 i i i有两个属性:收益 b i b_i bi:物品 i i i的价值或收益,重量 w i w_i wi:物品 i i i的重量,且为整数。
我们的目标是从从集合 S S S中选择一个子集 T T T使得 ∑ i ∈ T b i ∑_{i∈T}b_i ∑i∈Tbi是最大的,且 ∑ i ∈ T w i ≤ W ∑_{i∈T}w_i≤W ∑i∈Twi≤W即所选物品的总重量不超过给定的总重量 W W W。
如果我们使用暴力搜索法,那么就是测试所有可能的 n n n个物品的子集可能。由于每个物品都有两种可能的状态(被选中或不被选中),因此总共有 2 n 2^n 2n种可能的子集组合。
这种方法的时间复杂度是 O ( 2 n ) O(2^n) O(2n),属于指数时间复杂度。
对于较大的 n 值,指数时间复杂度的解法是不切实际的,因为它的计算量随着物品数量的增加而急剧增长。
对于这种情况,正如前文所述,我们可以使用动态规划方法。
我们现在定义集合 S k S_k Sk:表示包含前 k k k个物品的集合,即 S k = { i ∣ i = 1 , 2 , … , k } S_k=\{i∣i=1,2,…,k\} Sk={
i∣i=1,2,…,k}。
集合 S 0 S_0 S0 :表示空集,即 S 0 = ∅ S_0 =∅ S0=∅。
函数 B [ k , w ] B[k,w] B[k,w]:表示使用集合 S k S_k Sk中的一个子集,且该子集的总重量不超过 w w w时,可以获得的最大总收益。所以 B [ 0 , w ] = 0 B[0,w] =0 B[0,w]=0。
因此其的公式为 B [ k , w ] = { B [ k − 1 , w ] if w < w k max { B [ k − 1 , w ] , b k + B [ k − 1 , w − w k ] } otherwise B[k, w] = \begin{cases} B[k-1, w] & \text{if } w < w_k \\ \max \{B[k-1, w], b_k + B[k-1, w - w_k]\} & \text{otherwise} \end{cases} B[k,w]={
B[k−1,w]max{
B[k−1,w],bk+B[k−1,w−wk]}if w<wkotherwise
所以现在我们在 O ( n W ) O(nW) O(nW)时间内找到最高收益的子集。
下面我们给出一个例子,背包的总重量 W = 10 W=10 W=10。
物品信息如下。
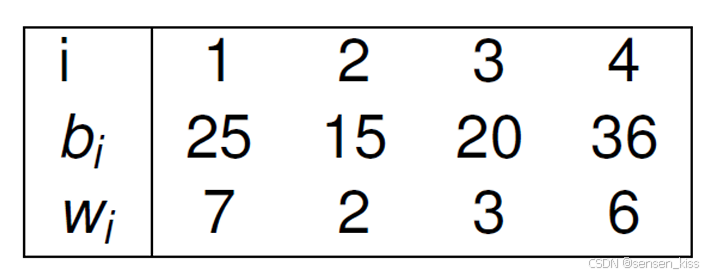
根据动态规划我们的过程如下。
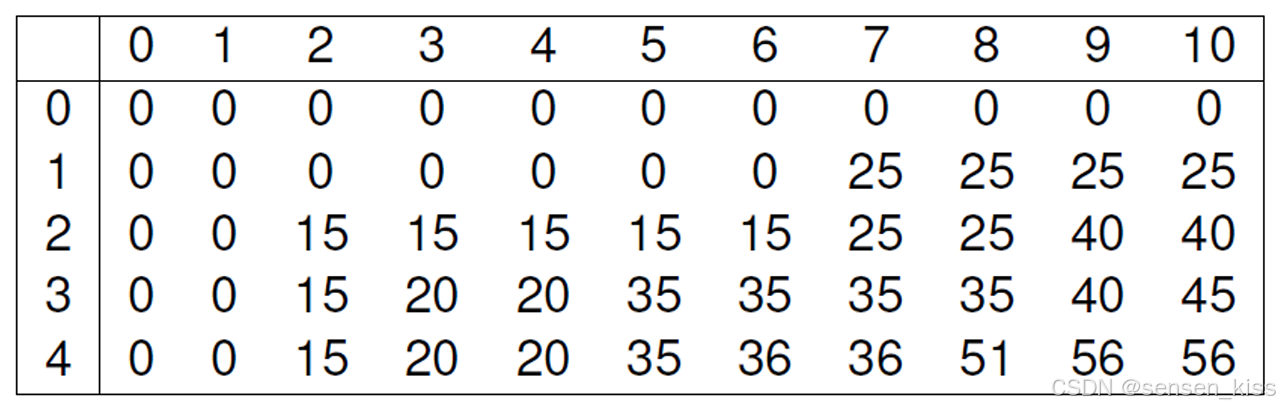
因此选取物品3和物品4可以获得最大价值56。