在大规模人工智能模型的训练过程中,高质量的数据集是提升模型性能的关键。然而,传统的网页爬虫技术在数据采集时常常面临反爬机制、动态内容加载和IP限制等挑战。为了解决这些问题,Bright Data(原名Luminati)提供了强大的API和工具,帮助用户高效、稳定地进行网页数据采集。
一、爬虫采集数据集对于大模型训练的重要性
在大规模人工智能模型的训练过程中,模型的性能高度依赖于所使用的数据集的质量和规模。高质量的数据集不仅能够提高模型的准确性和泛化能力,还能使模型在处理多样化任务时表现更佳。然而,构建这样的大规模、高质量数据集并非易事,通常需要从互联网中采集大量的结构化和非结构化数据。
在这一过程中,爬虫技术发挥着至关重要的作用。作为一种自动化程序,爬虫能够模拟用户行为,系统地访问和提取网页中的信息。通过爬虫技术,研究人员和工程师能够从大量网站上获取海量数据,为模型训练提供广泛的语料支持。爬虫可以定期抓取最新的数据,确保训练数据的时效性和新鲜度,使模型保持较新的知识储备。通过爬虫,可以获取不同类型、不同领域的数据,增强模型对多样化任务的适应能力,为大模型的训练提供丰富的语料资源。
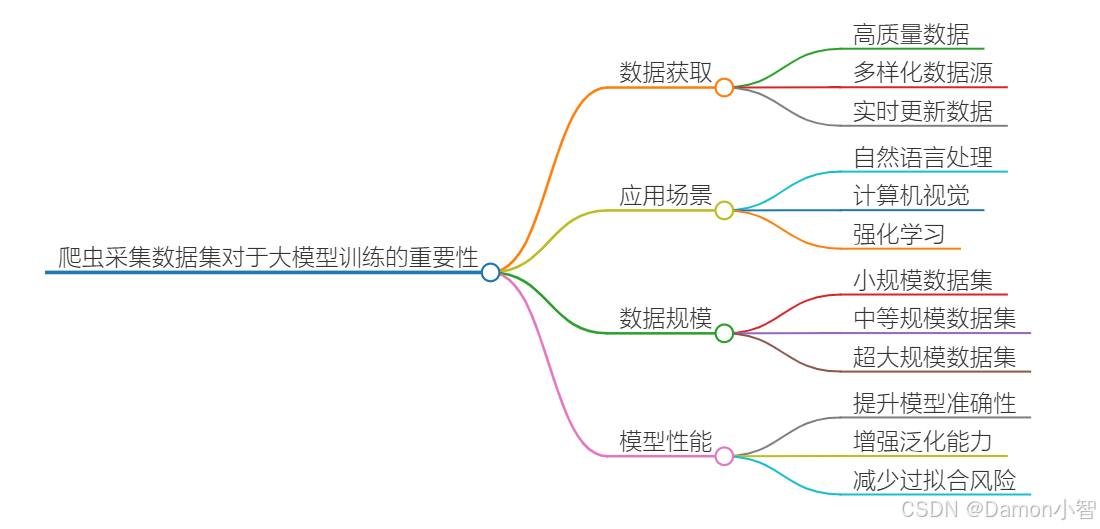
爬虫技术在大模型训练的数据集构建中扮演着不可或缺的角色。通过高效、实时、多样化的数据采集,爬虫技术为大模型的训练提供了坚实的数据基础,直接影响着模型的性能和应用效果。
二、爬虫技术解析
1. 爬虫技术的介绍与应用
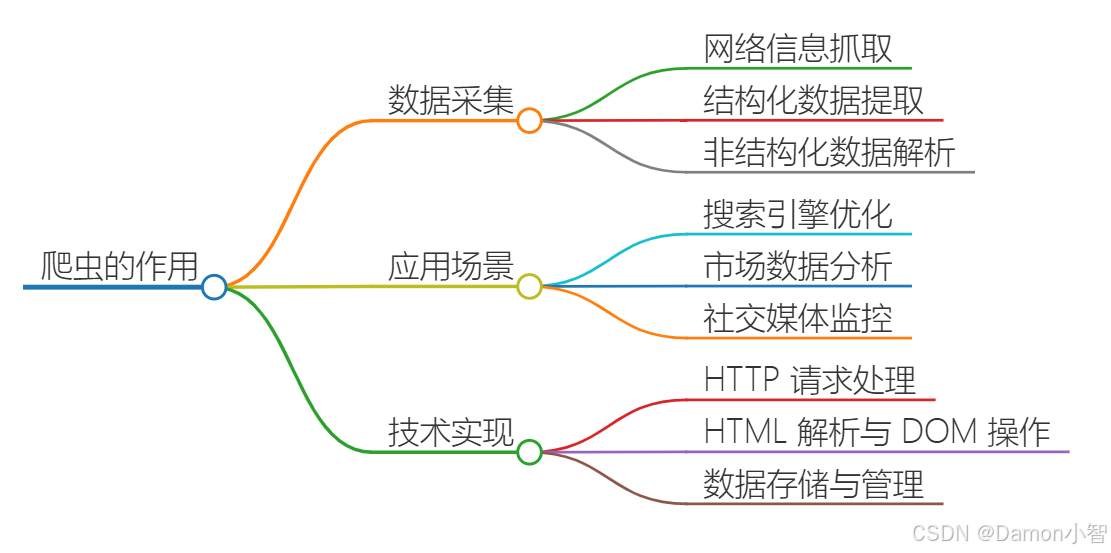
网页爬虫是一种自动化程序,旨在从互联网上提取信息。它们广泛应用于搜索引擎索引、市场调研、学术研究、商业情报收集等领域。通过爬虫技术,用户可以系统地访问网页,提取所需的数据,并将其存储以供后续分析和处理。
2. 传统爬虫技术栈
传统爬虫技术需要开发者有较全面的爬虫知识,并且需要独立面对这项技术实践中的各种问题,随着网络站点的防爬机制的升级,传统爬虫技术面临的挑战越来越大,对开发者的爬虫水平要求也越来越高。
传统的爬虫技术主要依赖以下工具和库:
| 工具类型 | 代表工具 | 主要用途 |
| HTTP请求库 | Requests、http.client | 发送网络请求并获取响应 |
| HTML解析库 | BeautifulSoup、lxml | 解析和提取网页中的结构化数据 |
| 浏览器自动化工具 | Selenium、Puppeteer | 处理需要JavaScript渲染的动态网页 |
| 数据存储工具 | SQLite、MongoDB | 保存和管理采集到的数据 |
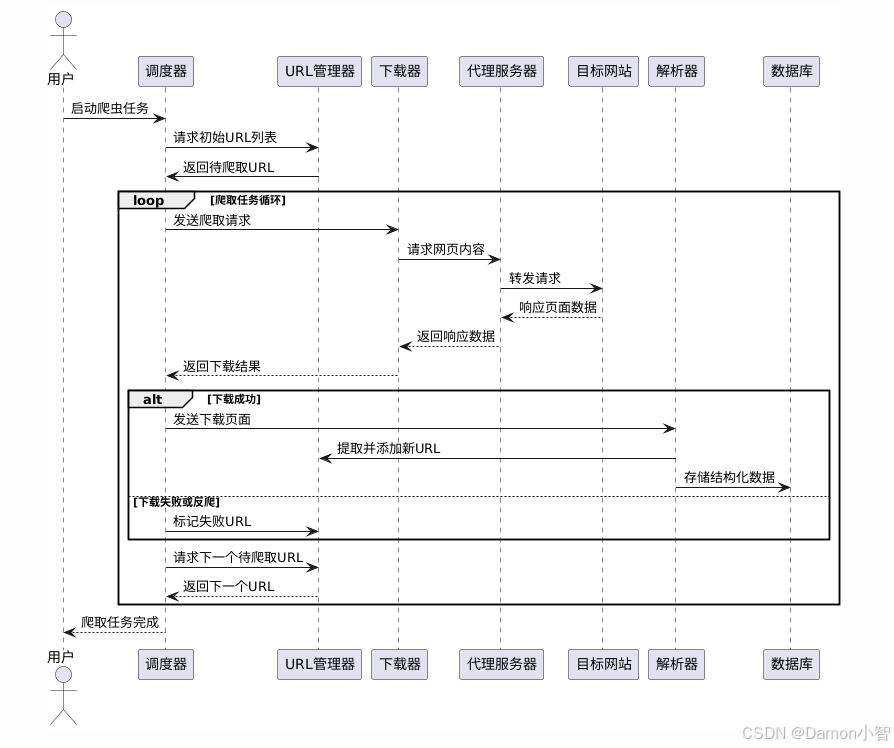
下图为传统爬虫技术的搭建流程示意,实现起来还是比较麻烦的,需要开发者有全面的专业知识。
3. 传统爬虫技术的挑战
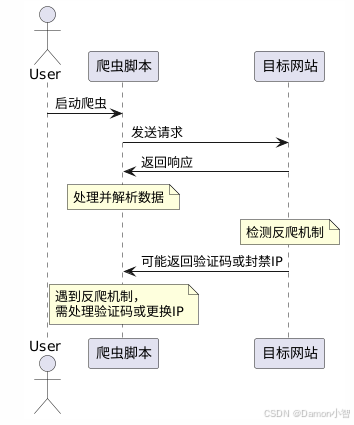
在实际应用中,传统爬虫技术面临以下挑战:
- 反爬机制:许多网站采用IP封禁、验证码、动态内容加载等手段来防止数据抓取,增加了爬虫的复杂性。
- 动态内容加载:现代网站广泛使用AJAX等技术异步加载数据,传统的静态解析方法难以获取完整信息。
- IP限制:频繁的请求可能导致IP被封禁,影响数据采集的连续性和稳定性。
三、基于亮数据的爬虫技术优势
1. 动态IP采集规避反爬机制
不同于传统的爬虫方式,使用亮数据的代理服务,爬虫通过代理服务器发送请求,代理服务器会自动更换IP地址,帮助规避反爬机制,提高数据采集的成功率和效率。
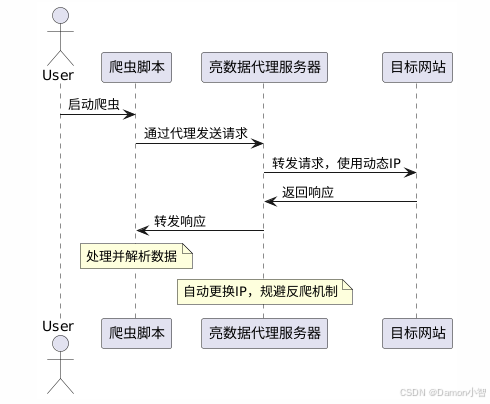
Bright Data提供了全球范围内的住宅代理IP,允许用户通过动态更换IP地址来规避网站的反爬机制。其代理服务具有以下优势:
| 特点 | 描述 |
| 广泛的IP覆盖 | 拥有超过7200万个住宅代理IP,覆盖195个国家和地区,支持针对特定国家、城市、运营商和ASN进行定位。 |
| 高匿名性 | 住宅代理使用由ISP分配给真实住宅设备的IP地址,确保高度匿名性,降低被检测和封禁的风险。 |
| 动态IP轮换 | 支持自动更换IP地址,用户可以设置每次请求使用不同的IP,或维持一个IP会话一段时间,灵活应对不同的爬取需求。 |
通过集成Bright Data的代理服务,用户可以有效降低被目标网站检测和封禁的风险,从而提高数据采集的成功率。
2. 零代码自动采集站点数据
Bright Data提供了多种自动化数据采集工具,适用于不同的应用场景:
| 产品/服务 | 功能描述 |
| Web Scraper IDE | 一个免代码界面,实现快速开发,无需代理管理的网页抓取API。 |
| Scraping Browser | 支持对多个网页进行批量数据抓取,适用于需要JavaScript渲染的页面或需要进行网页交互的场景。 |
| SERP API | 轻松便捷的搜索引擎按需抓取服务,支持从Google、Bing、Yahoo等主要搜索引擎获取实时的结构化SERP数据。 |
通过这些工具,用户无需编写复杂的代码,即可实现对目标网站数据的高效采集,极大地降低了技术门槛。
四、实战:使用亮数据API完成网页信息爬取
1. 注册登录Bright Data
访问官网地址,邮箱注册并登录账号,领取三天免费体验权益。
免费试用链接:网页抓取工具 - 网页爬虫工具 - 免费试用
2. 开启动态动态住宅IP
亮数据提供的动态住宅IP是真实用户设备的旋转 IP,拥有超过 7,200 万个 IP,这些 IP 均来自全球各地的真实用户,是业内规模最大、速度最快的代理网络。凭借遍布各个国家、州和城市的 IP,您可以从最难访问的网站收集数据,而不会被屏蔽。
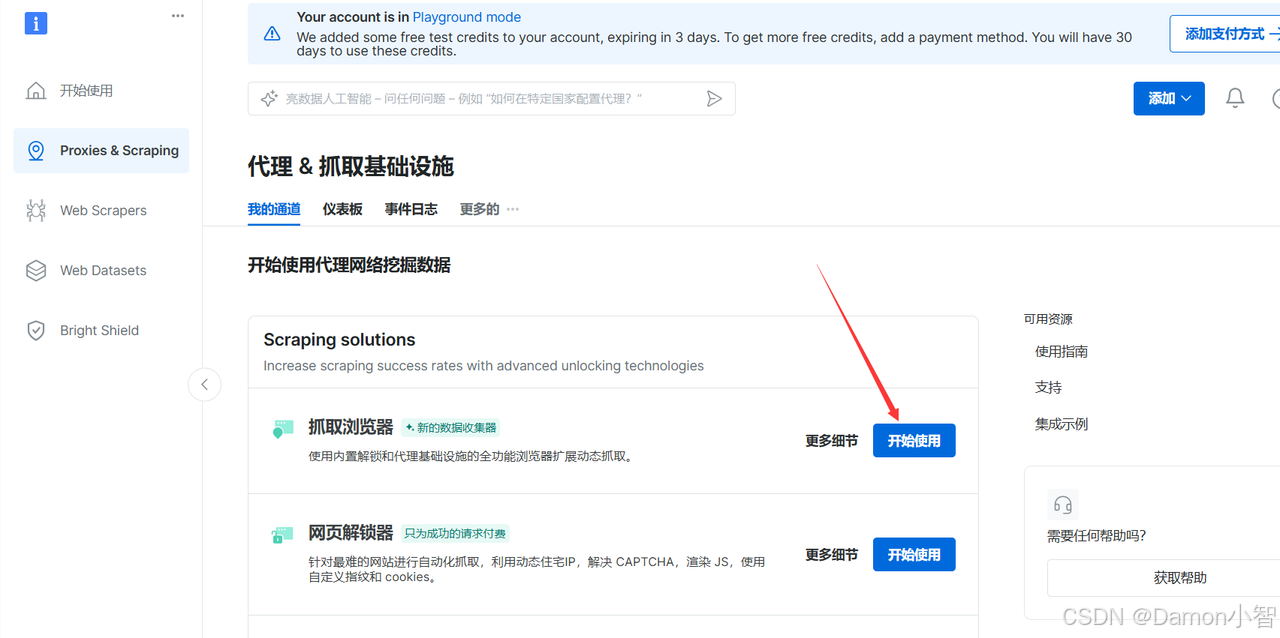
添加新通道。
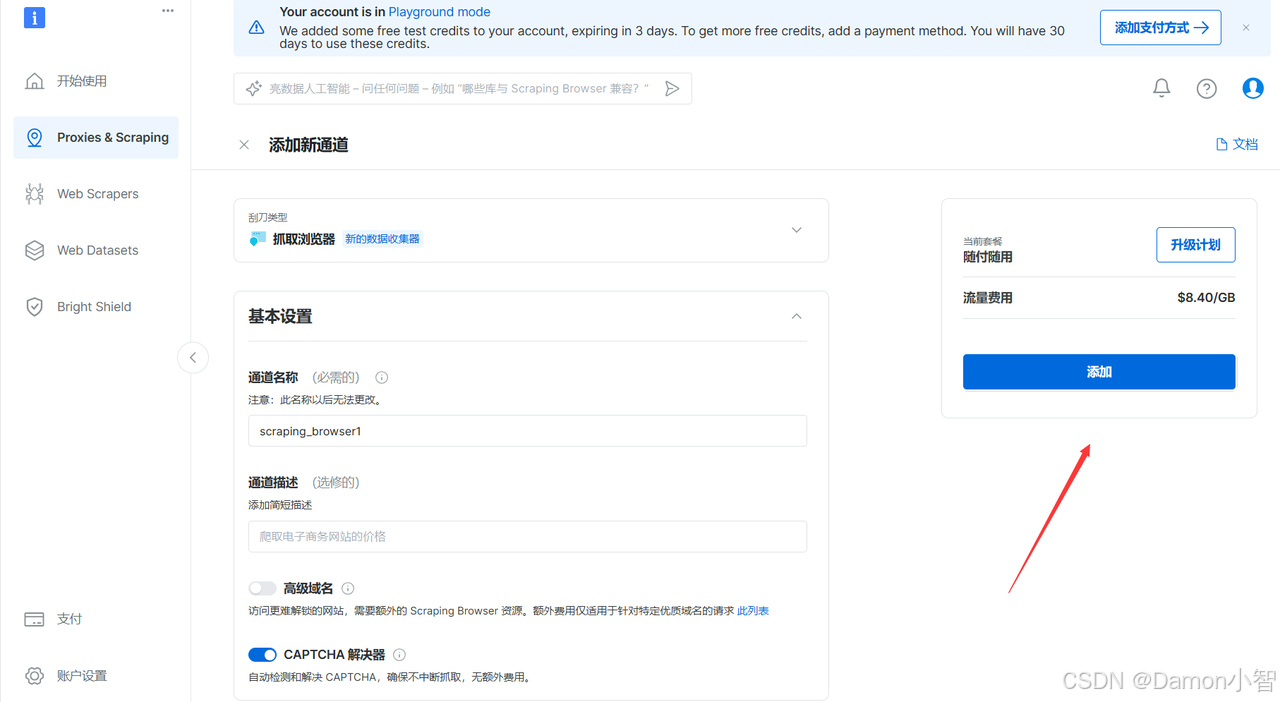
在概览里可以看到自己的账号信息。
在操作平台的Code Examples,平台为我们提供了多语言的代码示例。
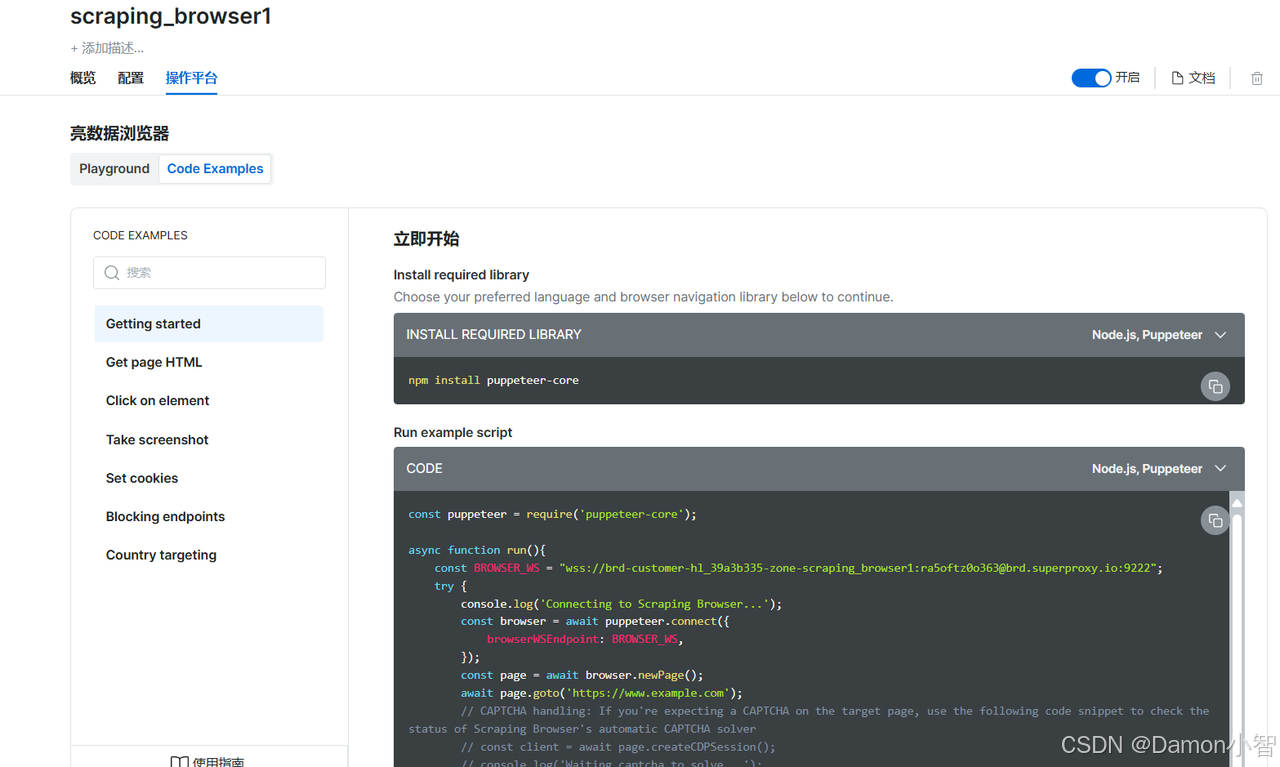
下面我们用python来爬取Amazon的手机销售页面。
我的代码如下:
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
import pandas as pd
# 替换为您的Bright Data认证信息
AUTH = 'brd-customer-您的客户ID-zone-您的区域:您的密码'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'
def main():
print('连接到Scraping Browser...')
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('连接成功!正在导航到亚马逊iPhone产品列表...')
driver.get('https://www.amazon.com/s?k=iphone')
print('页面加载完成!正在提取商品信息...')
# 等待页面加载完成(可根据需要调整等待时间或条件)
driver.implicitly_wait(10)
# 获取所有商品的容器
products = driver.find_elements(By.XPATH, '//div[@data-component-type="s-search-result"]')
# 存储提取的数据
data = []
for product in products:
# 提取商品名称
try:
name = product.find_element(By.XPATH, './/span[@class="a-size-medium a-color-base a-text-normal"]').text
except:
name = None
# 提取商品价格
try:
price_whole = product.find_element(By.XPATH, './/span[@class="a-price-whole"]').text
price_fraction = product.find_element(By.XPATH, './/span[@class="a-price-fraction"]').text
price = f"{price_whole}.{price_fraction}"
except:
price = None
# 提取商品链接
try:
link = product.find_element(By.XPATH, './/a[@class="a-link-normal s-no-outline"]').get_attribute('href')
except:
link = None
# 将提取的数据添加到列表中
data.append({
'商品名称': name,
'价格': price,
'链接': link
})
# 将数据保存到DataFrame
df = pd.DataFrame(data)
# 将数据保存到CSV文件
df.to_csv('amazon_iphone_products.csv', index=False, encoding='utf-8-sig')
print('数据提取完成,已保存到amazon_iphone_products.csv')
if __name__ == '__main__':
main()保存后的数据存储在 amazon_iphone_products.csv 里。
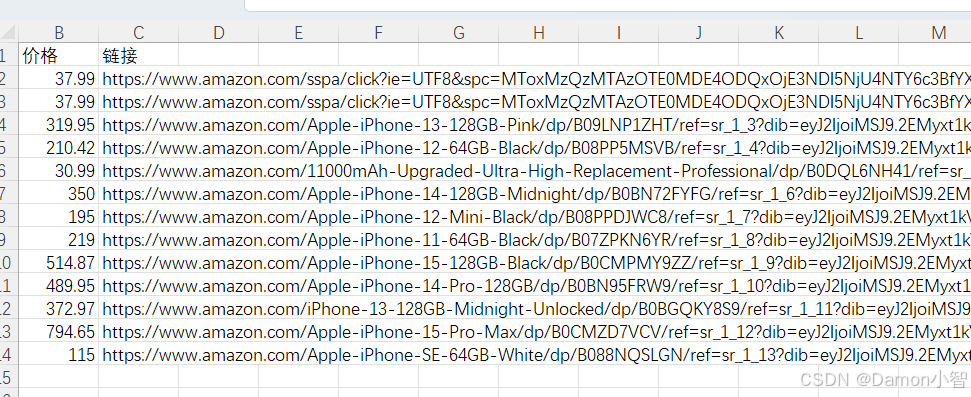
3. Crawler-API零代码爬取数据
还在为从零抓数据而头疼?写代码bug频出、数据清洗耗时耗力、格式转换令人崩溃?我们已为您准备好"即食数据套餐",省去90%的繁琐工作:
- ✅ 无需搭建服务器,免去运维压力
- ✅ 智能扩容,轻松应对海量数据
- ✅ 自动清洗杂乱数据,立即可用
- ✅ 简单API调用,稳定获取网页内容
就像拥有一个隐形技术团队,所有脏活累活我们搞定,您只需专注数据价值!
快速上手指南
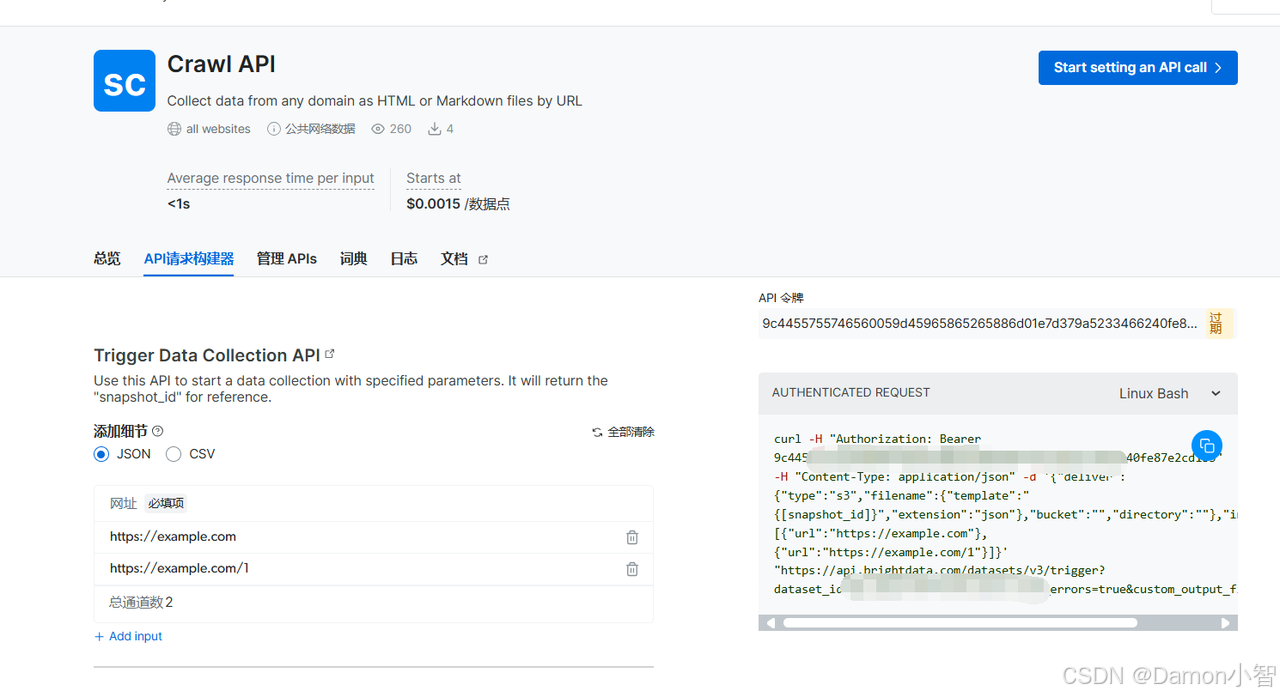
点击左侧导航栏「Web Scrapers」进入爬虫市场,选择「Crawler API」。
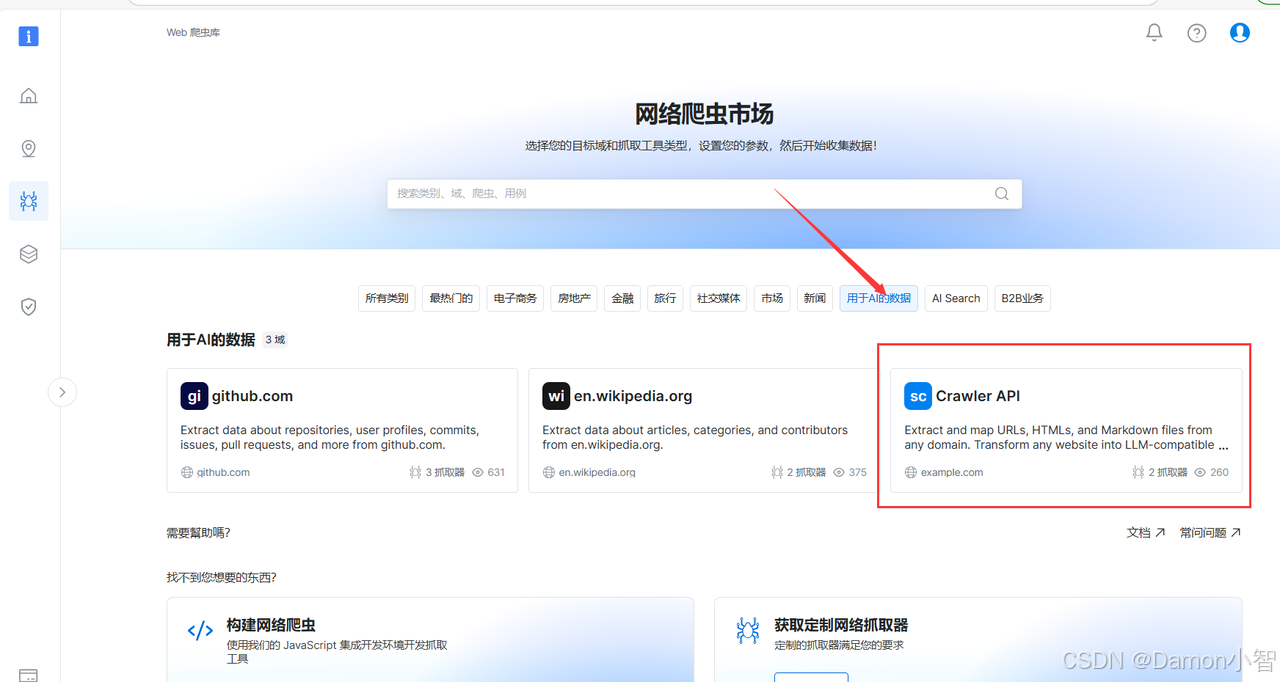
Crawler API 提供了两种方式:按URL收集 和 按域URL发现。
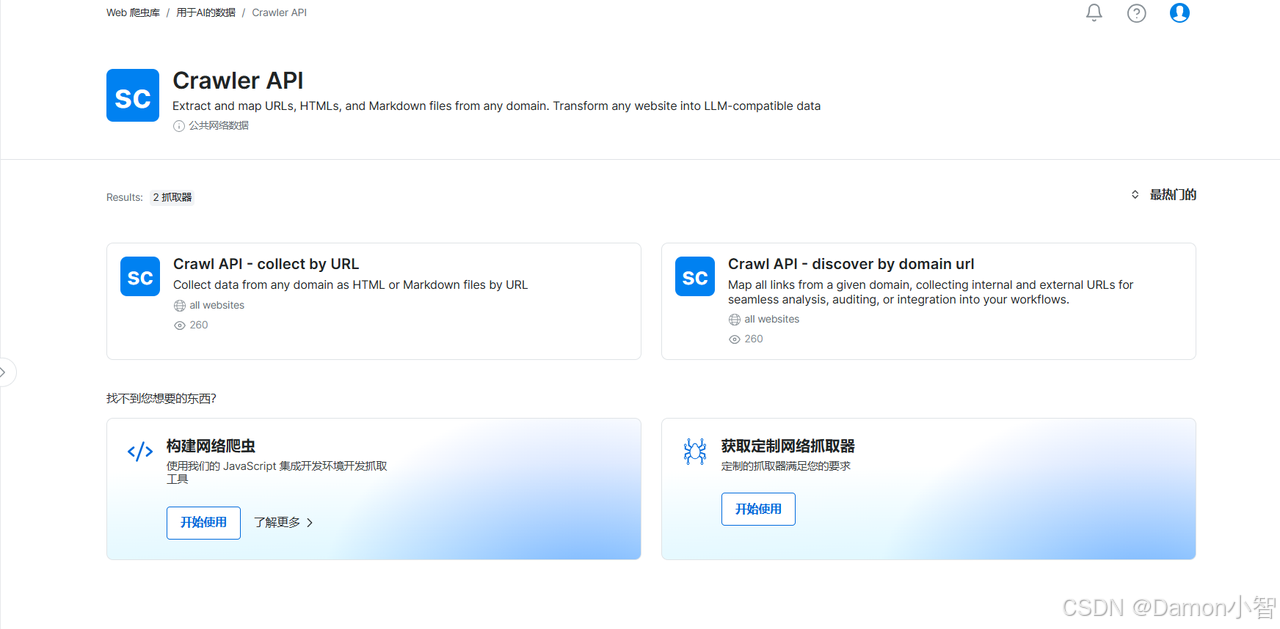
我们选择 按URL收集,点击进行无代码抓取。
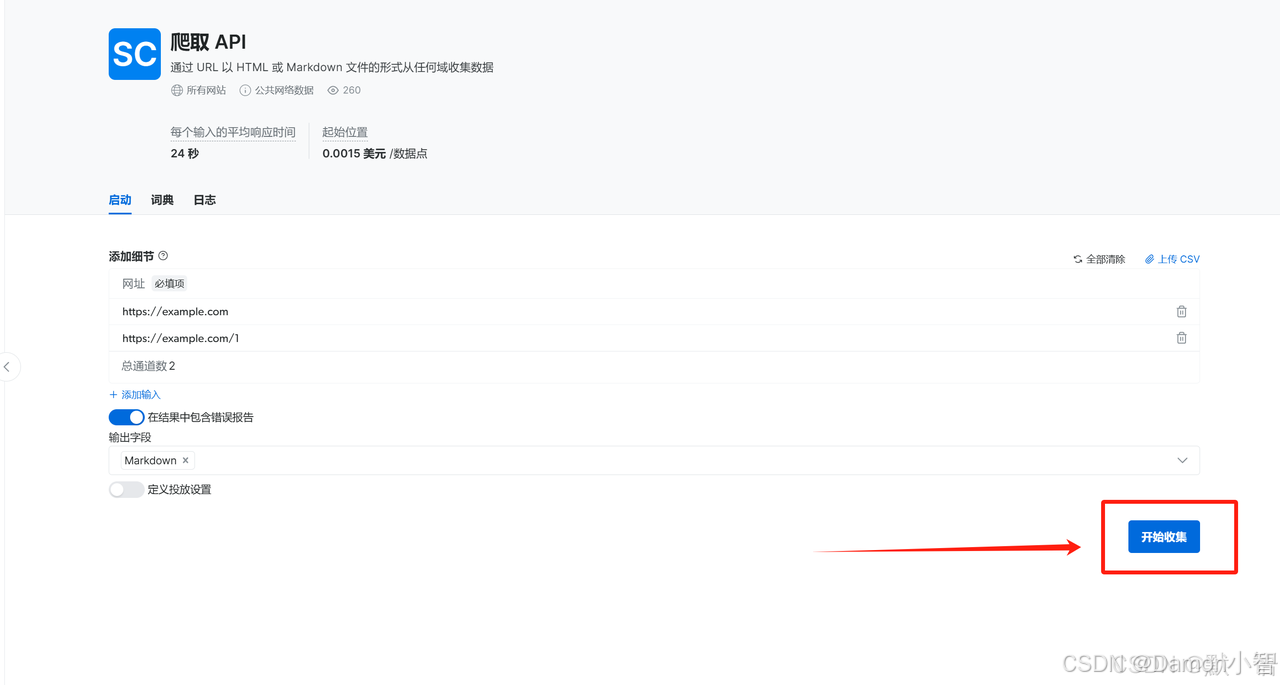
可以看到该抓取器很快就抓取成功了并返回了数据,我们可以点击下载选择适合自己的格式即可。
五、总结
在大模型训练中,高质量的数据集是模型性能的基石。然而,传统爬虫技术往往面临反爬机制、动态内容加载、IP限制等难题,使得数据采集变得低效且不稳定。Bright Data 作为一站式网络数据解决方案,不仅提供了强大的代理服务和自动化采集工具,更从根本上优化了数据获取的流程。
个人实践体会:
-
稳定高效的数据源是关键——Bright Data 的动态IP代理和智能防封策略,极大提升了数据采集的成功率,避免因IP封锁导致的数据中断。
-
零代码工具降低门槛——即使没有专业的爬虫开发经验,也能快速部署采集任务,让团队更专注于数据应用而非技术细节。
-
数据质量决定模型上限——自动化的数据清洗和结构化处理,确保原始数据的可用性,减少后续预处理的时间成本。
Bright Data 不仅是一个工具,更像是AI时代的数据“加速器”。它让数据采集从技术难题转变为可规模化的工作,为大模型训练提供了可靠的数据供应链。未来,随着AI对数据需求的增长,这类智能化、自动化的数据平台将成为行业标配,而提前掌握高效的数据获取方式,无疑会在竞争中占据先机。
网页抓取工具 - 网页爬虫工具 - 免费试用可无缝抓取网页数据的 Web 抓取 API。免代码界面,实现快速开发,无需代理管理。价格低至 $0.001/条记录,提供 24/7 全天候支持。![]() https://get.brightdata.com/wscraper
https://get.brightdata.com/wscraper