
目录
1.概述
数据处理模块就是整个流计算的系统架构中流计算引擎工作的模块。计算本质上就是去数据上跑计算任务,流计算就是在流数据上跑计算任务。
什么是计算任务?诸如select * from info where tag>30,就是一个计算任务,即对数据集进行计算得出结果就是计算任务。
要进行计算首先就要提供一套操作,一套便于编写任务的api。其次流数据的数据量都很大,有些时候任务不能死板的串行执行,为了计算的时效性,一个大任务可以拆成多个小任务来执行,那么如何拆?如何进行拆解后的任务管理和调度也是要考虑到的。
以上就是流计算引擎要干的事情,总结一下流计算引擎在干什么?
- 提供一套打法,能高效的完成任务。
- 提供一套便于使用的API,能编写计算逻辑。
那其实接下来的2、3小节我们就去梳理一下流计算引擎需要怎么去高效的完成任务以及提供哪些对流的操作以及基本操作有哪些。
2.DAG
流计算既然是在跑一个个的任务,那么高效的调度任务就是核心点。
将大任务拆成有向无环图(DAG),从而使得有些没有依赖的任务可以并行的执行,这样可以拉快整个任务的速度。
以一个风控的场景为例:
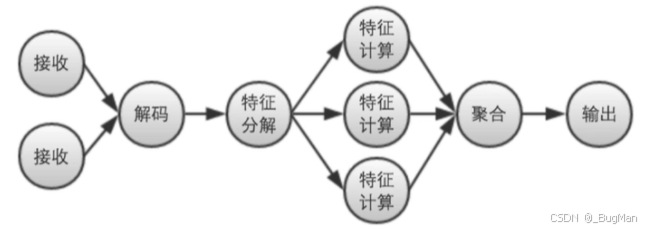
可以明显看到在接收、特征计算这些地方,大任务拆成了多个子任务进行并行计算。流计算引擎是如何将任务拆成DAG的?暂时不用关注,聊到具体流计算引擎的时候再来说。这里有个概念就行,就是大任务拆小任务(DAG),并行处理,拉高速率。
3.流计算的操作
3.1.基本操作
流计算中会用到的基本操作:
- filter:过滤数据,留下符合条件的数据。
- map:映射,对数据进行转换或操作。
- flatMap:摊平操作,将多个流合并成一个流。
- reduce:聚合操作,将流中的元素减少为一个单一的结果。
- groupby:按某个字段或条件对数据进行分组。
- keyby:按某个字段或条件对数据进行分组,生成键值对。
- join:将两个流或数据集按某个条件进行连接。
- union:将两个流或数据集合并成一个流。
- foreach:遍历流中的每个元素,执行某个操作。
flatmap是将一个输入转为一个列表,就是将单个对象的集合字段摊平:

3.2.如何在时间段内进行聚合
有一类数据是需要在一段时间段内进行聚合的,比如count、max、avg等,要完成这类聚合操作就需要驻留一段时间的数据,但是流式计算中的流数据往往都很大,留存数据会造成数据的挤压,如何处理这类问题?
当然就是分段聚合了,数据放走,只留下结果,最后聚合结果即可,以下以count操作为例:
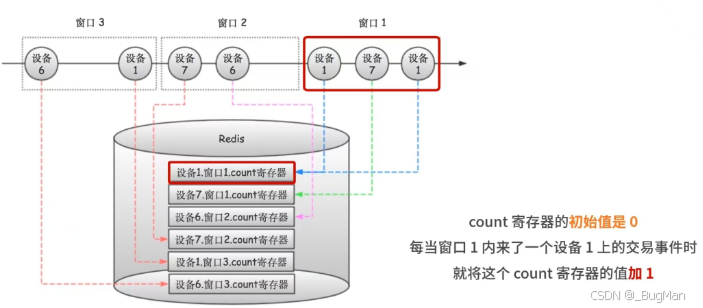
3.3.CEP
CEP,复杂事件处理。流的操作存在一些复杂处理,也就是对流的一套处理逻辑,一套处理逻辑封装成为一个模式(pattern),CEP就是多套模式的聚合形成一个系统。
通过定义事件模式(如连续发生的特定顺序的事件组合),CEP系统能够在事件流中识别这些模式并触发相应的动作或警报。可以理解为流计算引擎中允许将任务封装成一套套的CEP即可,是个任务的集合。这只是一个概念,便于后面去理解具体的流计算引擎。
4.性能调优
流计算的业务场景对最终的计算结果都有一些实时性的要求,所以尽可能的拉高计算速度,是使用流计算的关键点。一般是去调速度比较慢的一些节点上的处理程序。
三个维度入手来定位:
-
方测试
-
看是不是程序外部的问题
-
看是不是程序内部的问题
方便测试:
使用带有消息回放的MQ,比如Kafka,方便造数据来测试
看是不是程序外部的问题:
使用监控来监控环境,看看是不是CPU或者内存之类的资源不够用。监控可以使用Spring Boot那一套,也可以是Prometheus+Grafana。
看是不是程序内部的问题:
使用JDK自带的调优工具jvisualVM或者jconsole,去看线程dump、JVM情况
使用arthus去打出调用栈和耗时,去定位具体的耗时点。
5.批处理引擎和流计算引擎的区别
这是作者和chatGPT的一段对话:

诸如Spark之类的批处理引擎和诸如flink之类的流计算引擎最大的区别在于:
批处理引擎处理的数据都是在分布式文件系统中已经存好的历史数据,所以是建立好任务后,任务去找数据进行计算。
流计算引擎处理的流数据因为都是实时新产生的,所以是先把任务拆成DAG,将不同的处理步骤(子任务)分发到不同的节点上,然后数据流向任务,是数据去找任务。