一、错误记录
使用 huggingface_hub 函数库 配置 Hugging Face 模型库 的 国内 镜像源 , 在本地部署 all-MiniLM-L6-v2 模型 , 完整代码如下 :
from sentence_transformers import SentenceTransformer
from huggingface_hub import configure_hf # 新增关键配置
# 关键步骤:在加载模型前设置镜像源
configure_hf(mirror="https://hf-mirror.com") # 使用清华大学镜像
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2") # 注意完整路径
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
上述代码 , 执行后报错 :
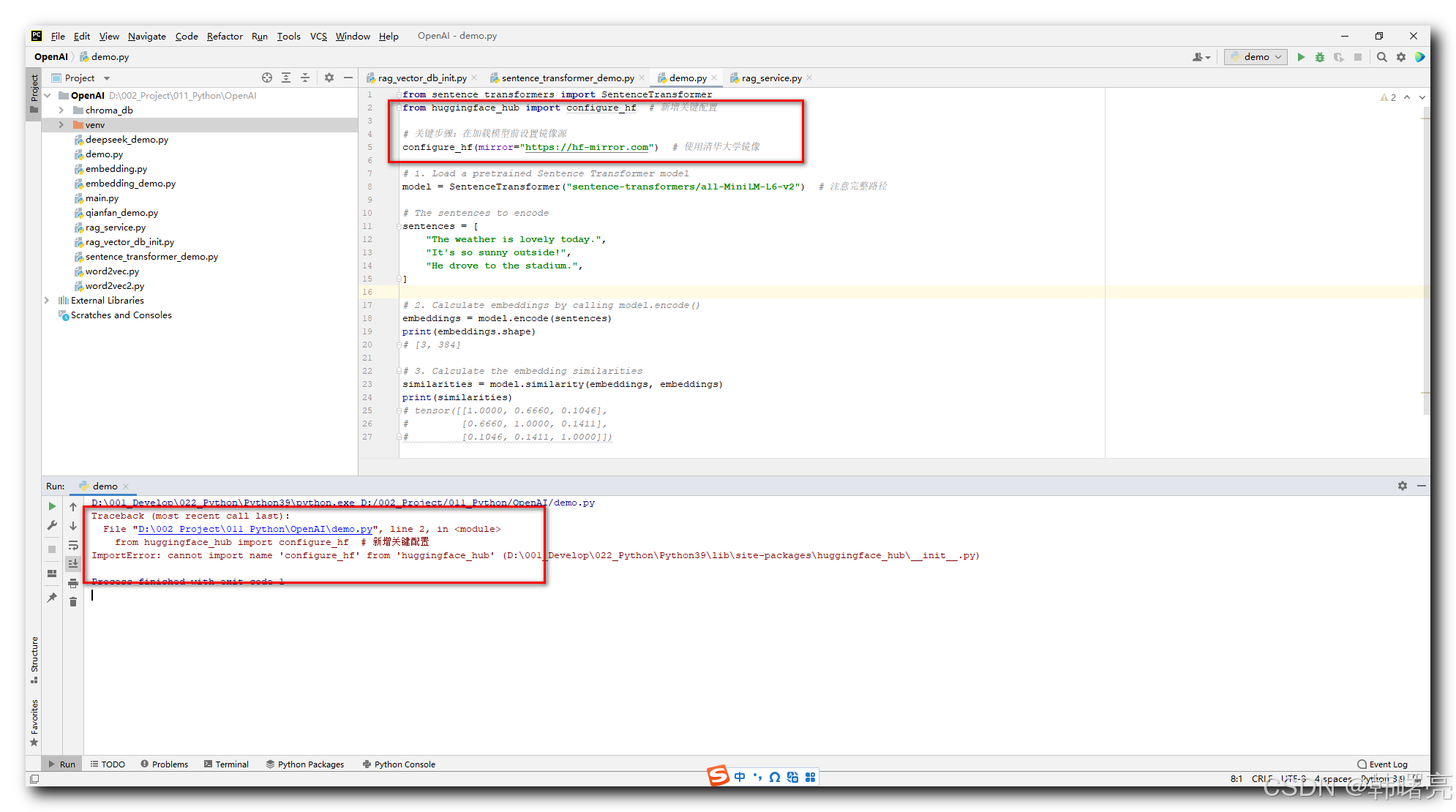
关键报错信息 :
ImportError: cannot import name 'configure_hf' from 'huggingface_hub'
完整报错信息 :
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/OpenAI/demo.py
Traceback (most recent call last):
File "D:\002_Project\011_Python\OpenAI\demo.py", line 2, in <module>
from huggingface_hub import configure_hf # 新增关键配置
ImportError: cannot import name 'configure_hf' from 'huggingface_hub' (D:\001_Develop\022_Python\Python39\lib\site-packages\huggingface_hub\__init__.py)
Process finished with exit code 1
二、问题分析
Hugging Face 的 huggingface_hub 库经常更新 , configure_hf 函数是在 新版本 中添加的 , 如果用户安装的是0.11.0之前的版本 , 可能没有这个函数 ;
既然 configure_hf 函数 是 后添加的 , 那么在之前肯定有 旧版本 的写法 , 使用 旧版本 方法 设置 镜像源 , 依然可以完成设置 ;
或者 直接更新 huggingface_hub 库到最新版本 ;
下面提供两种解决方案 ;
扫描二维码关注公众号,回复:
17540360 查看本文章

三、解决方案
可设置的镜像地址 :
- 官方镜像 : https://hf-mirror.com
- 深度求索 : https://hf-mirror.aliendao.cn
- 阿里云镜像 : https://modelscope.cn
- 清华大学镜像 : https://mirrors.tuna.tsinghua.edu.cn/hugging-face
1、升级 huggingface_hub 函数库
执行下面的代码 , 先卸载 旧版本 huggingface_hub , 然后安装 新版本的 huggingface_hub , 注意必须安装 0.15.0 之后的版本 ;
# 先卸载旧版本
pip uninstall huggingface_hub -y
# 安装2023年6月之后的新版本
pip install huggingface_hub>=0.15.0
升级 huggingface_hub 函数库 之后 , 可以正常使用 如下代码 :
from sentence_transformers import SentenceTransformer
from huggingface_hub import configure_hf # 新增关键配置
# 关键步骤:在加载模型前设置镜像源
configure_hf(mirror="https://hf-mirror.com") # 使用清华大学镜像
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2") # 注意完整路径
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
2、使用旧版本 huggingface_hub 函数库兼容写法
如果不想升级 huggingface_hub 函数库 , 可以使用 huggingface_hub 函数库 的 旧版本 兼容写法 ;
将 huggingface_hub 配置写在 Python 文件最开始处 ;
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 核心配置
完整代码示例 :
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 核心配置
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2") # 注意完整路径
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
执行结果 :
(3, 384)
tensor([[1.0000, 0.6660, 0.1046],
[0.6660, 1.0000, 0.1411],
[0.1046, 0.1411, 1.0000]])
