陌生又熟悉的多年老友【Kafka】小记
这是一篇闲文小记,由参考多篇网友对kafka的理解,再回想自己的对kafka的应用不由得有感而谈。
Kafka 由 LinkedIn 开发,并于 2011 年开源,可以说是一个比较“老”的技术了,自己从2014接触到他。遗憾的是,自己一致拿他当作一个无差别消息队列,对其理解也是浅尝辄止,今日对其突生所感,查阅一些文档结合自己的感悟,一同分享。
随着产品应用的用户数量的增长,API 调用和数据库访问的频率必然会大幅提升。人工智能时代,智能体的开发与应用会进一步加剧计算机环境的资源占用。如果没有设计任何缓存机制,数据库等各项服务的负载将会持续增加,最终难以承受,导致系统性能下降甚至崩溃。
此外,随着详细的业务数据不断积累以及物联网设备的接入与扩展。系统需要建立实时监控机制,并可能整合外部资源。然而,如果数据流架构设计不合理,系统架构就会变得混乱,如下图所示:
是不是眼花缭乱,本次就说一说Kafka的魔力,为系统带来的优化与智慧。
标准的概念:
Apache Kafka 是一款分布式流处理平台,主要用于高吞吐量的消息队列,能够实现实时数据流的发布、订阅、存储和处理。Kafka 由 LinkedIn 开发,并于 2011 年开源,现由 Apache 基金会维护。
Kafka 的核心概念
- Producer(生产者):负责向 Kafka 发送消息的组件,通常由业务系统或数据采集程序充当。
- Broker(代理):Kafka 集群中的服务器节点,每个 Broker 负责存储部分数据并处理消息请求。
- Topic(主题):逻辑上的消息分类,生产者向某个 Topic 发送消息,消费者从相应 Topic 读取数据。
- Partition(分区):Kafka 通过将 Topic 分割成多个 Partition 来实现并行处理和高吞吐,每个分区的数据存储在多个 Broker 之间。
- Consumer(消费者):订阅 Kafka 主题并消费消息的应用,通常由多个消费者组成消费者组(Consumer Group),可以实现负载均衡。
- Zookeeper:负责管理 Kafka 集群的元数据、分区信息和节点状态,确保 Kafka 的高可用性。
(ps: zookeeper 來保存消息,但 Kafka 官方表示在不久後就不再支援 zookeeper)
Kafka 的特点
高吞吐量:Kafka 采用分布式架构,能够处理大量数据,单个 Kafka 服务器可支持百万级消息吞吐。
持久化与可靠性:消息存储在磁盘上,支持多副本机制,即使 Broker 故障也不会丢失数据。
可扩展性:Kafka 允许通过增加 Broker 来扩展集群,满足大规模数据流处理需求。
实时数据处理:与流处理框架(如 Apache Flink、Spark Streaming)结合,可实现实时数据分析。
解耦系统架构:生产者与消费者相互独立,降低系统耦合度,提升可维护性。
Kafka 的应用场景
日志收集:各类应用的日志、用户行为数据可通过 Kafka 统一收集并存储。
实时数据流处理:结合流计算引擎,实现用户行为分析、欺诈检测、指标监控等。
事件驱动架构:微服务架构中,Kafka 作为事件总线,实现异步通信,提高系统解耦能力。
数据管道:Kafka 作为 ETL(Extract-Transform-Load)中间层,连接数据库、数据仓库、大数据分析平台等。
消息队列:用于实现异步消息处理,类似于 RabbitMQ、ActiveMQ,但吞吐量更高。
调度的优化
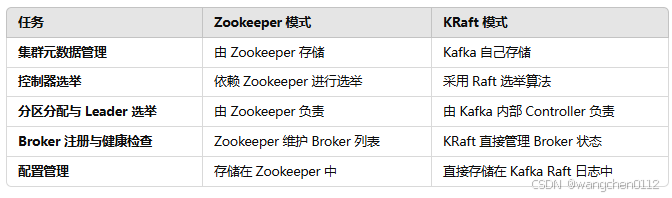
1. 传统 Kafka 依赖 Zookeeper 的问题
Kafka 早期架构依赖 Zookeeper 进行元数据管理、集群状态维护、分区分配等任务,但这种方式存在以下问题:
- 性能瓶颈:Zookeeper 需要处理大量元数据请求,Kafka 集群规模扩大后可能成为瓶颈。
- 运维复杂:Zookeeper 需要独立部署和维护,增加运维成本。
- 单点问题:如果 Zookeeper 集群出现故障,Kafka 可能无法正确处理元数据,影响可用性。
2. Kafka KRaft(Kafka Raft)模式
KRaft(Kafka Raft) 是 Kafka 2.8 版本引入的新模式,完全去除了 Zookeeper,并使用 Kafka 自己实现的 Raft 协议 来进行集群管理和元数据存储。Kafka 3.3.0 版 本后,KRaft 进入正式可用阶段,并预计在未来完全取代 Zookeeper。
3.KRaft 的核心特性
去中心化管理:Kafka 自身管理元数据,不再依赖外部组件。
更高效的元数据存储:使用 Raft 协议,数据变更通过日志复制保证一致性,减少同步延迟。
更强的扩展性:支持更大规模的 Kafka 集群,避免 Zookeeper 造成的性能瓶颈。
更简化的运维:减少组件数量,简化 Kafka 集群的部署和管理。
在 Kafka KRaft 模式下,Zookeeper 的调度功能由 Kafka 内部的控制节点(Controller)取代,主要体现在以下几个方面:
Kafka 为什么会快
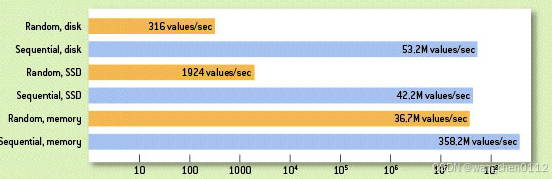
Kafka 将数据写入硬盘,通常我们会认为硬盘的读写性能不佳。但实际上,硬盘的性能取决于顺序读写还是随机读写。在某些情况下,硬盘的顺序读写性能甚至比内存的随机读写更高。
以下是 disk【硬盘】 ssd 【固态硬盘】 memory【内存】的随机访问与顺序访问的性能对比:
零拷贝:从 Producer 发送到 Broker,Kafka 采用 mmap(内存映射)方式将数据持久化到磁盘,将原本需要 两次 CPU 拷贝的操作减少为 一次,提升效率。而从 Broker 发送到 Consumer 时,Kafka 使用 sendFile 直接读取磁盘数据进行发送,实现零拷贝,进一步减少 CPU 和内存开销。
批量发送:Producer 发送消息时,可以累积到一定数量后再批量发送。例如,在 10MB/s 的网络带宽下,一次传输 10MB 的数据会比 将 1KB 的数据分成 10,000 次发送效率更高,能有效减少网络开销。
批量压缩:在某些情况下,系统的性能瓶颈不是 CPU 或磁盘,而是网络 IO。为了解决这个问题,可以在批量发送的基础上,对多条消息进行批量压缩,减少数据传输量,从而降低网络 IO 负担,提高整体吞吐量。
Redis与Kafka的分工:
在网上看到一个有趣的比喻,在这里分享给大家:
老板有一个好消息要告诉大家,有两种做法:
1、逐个通知:老板走到每个工位,挨个告诉大家好消息。什么?张三去厕所了?那他就只能错过这个消息了!
2、写在黑板上:老板把消息写在黑板上,谁想知道就自己来看。什么?张三请假了?没关系,我 一周后才擦掉,他总能看到!什么?张三请假两周?那就没办法了,我只保留 一周,不然黑板没地方写新消息了。
Redis 采用第一种方式,而 Kafka 采用第二种方式。
Redis vs. Kafka
- Redis 是内存数据库,它的 Pub/Sub(发布/订阅) 机制会将消息存储在内存中。如果消息不需要长期保存,并且消费速度快,那 Redis 是个不错的选择。
- Redis 也支持持久化,但它的可靠性相对较低,通常不作为长期存储的主要方案。
- Kafka 将数据存储在磁盘上,提供了持久化的消息队列。消费者可以按照顺序消费,甚至可以重新读取过去的消息(但磁盘空间有限,Kafka 仍然会根据时间或空间策略删除旧消息)。
感言汇总:
对此,Kafka 可以比喻成一个高效的物流配送中心,专门处理和管理大量包裹(数据)的分发。它不是普通的快递点,而是那种规模庞大、自动化程度极高的现代化物流枢纽。
想象一下,你是某个电商平台的后台,每天有成千上万的订单(数据)从全国各地发来。Kafka 就像这个物流中心的总指挥,它的工作是接收这些订单,把它们按类别整理好(分成不同的 topic,比如“支付订单”“物流信息”),然后快速分发给等着处理的下游部门(消费者,比如支付系统、库存系统)。每个包裹上都有个编号(offset),确保不会丢件,也方便查账。
这个物流中心有几个特别的地方:
- 分拣区(分区,partition):为了提高效率,Kafka 把包裹分成多个堆,每个堆由专门的工人(consumer)负责。这样就算订单量再大,也能并行处理,不至于挤成一团。
- 调度员(Zookeeper、KRaft):有个管家角色负责协调这些分店,确保它们知道谁该干啥活儿。没有这个调度员,物流中心就得停摆。
- 分店网络(分布式 broker):Kafka 不是单打独斗,它有一堆分中心(broker)联网运作。订单量太大时,可以加几个分店,分担压力,保证系统不崩。
- 仓库(持久化存储):不像普通快递点寄了就忘,Kafka 会把所有包裹记录在案,存在硬盘里,哪怕几天没人取走也能随时翻出来。这让它特别适合需要回溯数据的情况,比如查上周的订单。
用 Kafka 的场景也很直白。比如,你在实时监控服务器运行状况,日志数据像流水一样涌来,Kafka 就负责把这些日志收集起来,分发给分析部门,帮你实时找出问题。或者在金融系统里,交易数据需要又快又稳地传到各个模块,Kafka 就像条高速传送带,保证数据不丢、不乱。
总的来说,Kafka 是一个可靠、高效、可扩展的数据中转站。它不挑活儿,不管你扔多少数据,它都能接住、分好、送出去。不过用它得先规划好“分拣区”和“分店”,不然可能会忙得晕头转向。简单说,它就是数据世界的“超级邮局”,专为大场面设计!