目录
- 字节
- java数据类型
- 单精度浮点数占用4个字节,为什么数值范围是-3.4E38到3.4E38,而不是像整数那样−2147483647到+2147483647
- float精度(7位):
- double精度(15位):
- 为什么浮点型精度确保只有7或15位置
- 单精度和双精度浮点数中的阶码最大值为什么是254和2046
- float和double精度缺失问题
- BigDecimal大小比较以及其余用法
- java基本数据类型对应的包装类以及java为什么要有包装类型?
- 自动装箱与拆箱
- 自动类型提升(隐式类型转换)
- 强制类型转换
- short s1 = 1; s1 = s1 + 1;有错吗
- float f=3.4;是否正确
- Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
字节
Bit是计算机中最小的数据单位,只能表示0或1,而Byte通常由8个bit组成,是计算机处理数据的基本单位。要强调它们的关系:1 Byte = 8 Bits
1.编程中一个字节取值大小
编码0111 1111
原码是最基础的二进制编码方式,规则为:
最高位(第8位):第一位为符号位
0 表示正数
1 表示负数
十进制值为 26+25+24+23+22+21+20=27−1=127
剩余7位:表示数值的绝对值(即实际大小)
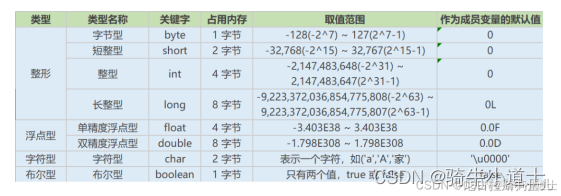
java数据类型
a.基本数据类型
整型
字节型 byte 1
短整型 short 2
整型int 4
长整型 long 8
浮点型 754标准
float 4个字节
double 8 个字节
字符型 char 2个字节
布尔型 boolen 1个字节 ture/false
b.引用数据类型
对象(类class)
数组 []
接口 interface
单精度浮点数占用4个字节,为什么数值范围是-3.4E38到3.4E38,而不是像整数那样−2147483647到+2147483647
用户可能没有区分整数和浮点数的存储方式。整数(如补码)直接存储二进制数值,而浮点数使用IEEE 754标准,将字节分为符号位、指数位和尾数位。需要解释浮点数的结构,以及这种结构如何允许更大的范围,尽管精度不同,根据IEEE 754标准,浮点数的二进制表示分为三部分:
符号位(1位):表示正负。
指数位(8或11位):表示数值的缩放比例(采用偏移编码)。
尾数位(23或52位):表示小数部分的精度。
类型 总位数 符号位 指数位 尾数位
float 32位 1位 8位 23位
double 64位 1位 11位 52位
单精度(float):32位(4字节) → 牺牲精度换取存储效率。
双精度(double):64位(8字节) → 通过更多位数提升精度和范围。
浮点型(Floating-Point)在计算机中是以二进制形式存储和表示的。尽管我们通常用十进制(如 3.14)来书写和理解浮点数,
但在计算机内部,浮点数遵循IEEE 754标准,使用二进制科学计数法来表示。
float精度(7位):
存储值:1234567.0 → 可以精确表示。
存储值:12345678.0 → 可能因精度丢失,表现为12345680.0。
double精度(15位):
存储值:123456789012345.0 → 可以精确表示。
存储值:1234567890123456.0 → 可能表现为1234567890123456.0或1234567890123457.0。
为什么浮点型精度确保只有7或15位置
- 精度定义
有效数字:指从第一个非零数字开始,到最后一个可靠数字结束的所有位数。
二进制限制:有限的尾数位数决定了能唯一表示的数值数量,超过该精度后无法避免舍入误差。精度的问题应该与尾数位的位数有关。尾数位决定了可以表示的有效数字的位数。
但为什么是7位和15位呢
- 先计算单精度浮点数的情况。单精度的尾数有23位,但实际有效位数是24位,因为有一个隐含的前导1(规格化数的情况下)。
因此,有效二进制位数是24位。那么十进制的有效数字位数大约是log10(2^24)。计算一下:
log10(2^24) = 24 * log10(2) ≈ 24 * 0.3010 ≈ 7.224 - 同样地,双精度浮点数的尾数是52位,隐含的前导1使有效二进制位数达到53位。计算十进制有效数字位数:
log10(2^53) = 53 * log10(2) ≈ 53 * 0.3010 ≈ 15.953
大约是15位,这对应double的15位精度。
单精度和双精度浮点数中的阶码最大值为什么是254和2046
IEEE 754标准中对浮点数的编码方式。首先这里需要明确的是,IEEE 754中阶码的范围并不是全0到全1。全0和全1有特殊的用途
- 全0用来表示非规格化数(denormalized numbers)和零
- 而全1用来表示无穷大(Infinity)和NaN(Not a Number)
单精度是32位,双精度是64位。它们的阶码部分位数不同,单精度是8位,双精度是11位
阶码部分在浮点数中是以偏移码(biased exponent)的形式存储的。
- 对于单精度来说,8位的阶码,偏移量是127,所以实际指数值应该是阶码的值减去这个偏移量。2^8 - 1 - 1 = 256-1 -1 = 254(减去全0和全1吧)。对应的实际指数是254 - 127 = 127
- 对于双精度来说,11位的阶码,偏移量是1023,所以实际指数值应该是阶码的值减去这个偏移量。2^11 - 1 - 1 = 2048-1 -1 = 2046(减去全0和全1吧)。对应的实际指数是2046- 1023= 1023
float和double精度缺失问题
对于那些不需要准确计算精度的数字,我们可以直接使用Float和Double处理,
但是Double.valueOf(String) 和Float.valueOf(String)会丢失精度
这是因为浮点数在计算机中是以二进制的形式存储的。所以明面上的数值 在实际计算时候会转换为double或者float存储时候,浮点数参与计算就会变得不可预知 从而造成精度缺失(浮点型精度确保只有7或15)
解决方法 bigdecimal 参与计算
先使用 Double.toString(double) 方法,然后使用 BigDecimal(String) 构造方法,将 double 转换为 String。
BigDecimal bigDecimal = new BigDecimal(Double.toString(number1));
要获取该结果static BigDecimal valueOf(double)方法
public static BigDecimal valueOf(double val) {
}
然后使用BigDecimal的方法进行解决
常用方法
- add(BigDecimal)BigDecimal对象中的值相加,返回BigDecimal对象
- subtract(BigDecimal)BigDecimal对象中的值相减,返回BigDecimal对象
- multiply(BigDecimal)BigDecimal对象中的值相乘,返回BigDecimal对象
- divide(BigDecimal)BigDecimal对象中的值相除,返回BigDecimal对象
- toString()将BigDecimal对象中的值转换成字符串
- doubleValue()将BigDecimal对象中的值转换成双精度数
- floatValue()将BigDecimal对象中的值转换成单精度数
- longValue()将BigDecimal对象中的值转换成长整数
- intValue()将BigDecimal对象中的值转换成整数
BigDecimal大小比较以及其余用法
BigDecimal大小比较
java中对BigDecimal比较大小一般用的是bigdemical的compareTo方法
int a = bigdemical.compareTo(bigdemical2)
BigDecimal格式化
由于NumberFormat类的format()方法可以使用BigDecimal对象作为其参数,
可以利用BigDecimal对超出16位有效数字的货币值,百分值,以及一般数值进行格式化控制
NumberFormat currency = NumberFormat.getCurrencyInstance(); //建立货币格式化引用
NumberFormat percent = NumberFormat.getPercentInstance(); //建立百分比格式化引用
percent.setMaximumFractionDigits(3); //百分比小数点最多3位
BigDecimal loanAmount = new BigDecimal("15000.48"); //贷款金额
BigDecimal interestRate = new BigDecimal("0.008"); //利率
BigDecimal interest = loanAmount.multiply(interestRate); //相乘
System.out.println("贷款金额:\t" + currency.format(loanAmount));
System.out.println("利率:\t" + percent.format(interestRate));
System.out.println("利息:\t" + currency.format(interest));
结果:贷款金额: ¥15,000.48 利率: 0.8% 利息: ¥120.00
java基本数据类型对应的包装类以及java为什么要有包装类型?
主要原因包括以下几点:
a.处理基本数据类型的 null 值:
基本数据类型(如 int,double 等)不能直接赋值为 null,而包装类型(如 Integer、Double)可以表示 null 值,这对于某些业务逻辑和数据处理来说非常有用。
private static Boolean b;
private static Integer i;
b.提供额外功能:包装类型提供了一些额外的方法和功能,这些方法可以用于对基本数据类型进行操作和处理。
例如,Integer 类提供了parselnt()方法用于将字符串转换为整数。
c**.泛型**(泛型其实就是将类型作为参数传递,ArrayList E就是泛型。 这种不确定的数据类型需要在使用这个类的时候才能够确定出来)
泛型支持:
泛型只能接受对象类型,无法直接使用基本数据类型。
因此,使用包装类型可以很方使地在泛型中使用基本数据类型。
class Point<T>{
private T x;
private T y;
public void setX(T x) {
this.x=x;
}
public void setY(T y) {
this.y=y;
}
public T getX() {
return this.x;
}
public T getY() {
return this.y;
}
}
public class Main {
public static void main(String[] args) {
// TODO 自动生成的方法存根
Point<Integer> point=new Point<Integer>();//设置Integer类型
point.setX(10);//自动装箱
point.setY(10);//
int x=point.getX();//获取内容
int y=point.getY();
System.out.println("x+y="+(x+y));
}
}
d.自动装箱与拆箱: Java 提供了自动装箱(autoboxing)和自动拆箱(unboxing)的功能,使得基本类型与其对应的包装类型之间的转换更加便捷。
e.与对象集合的兼容性: Java的集合类(如ArrayList, HashMap等)只能存储对象,不能直接存储基本数据类型。使用包装类型可以方便地将基本数据类型转换为对象类型,从而与集合类兼
List<Integer> list = new ArrayList<Integer>();
自动装箱与拆箱
把基本数据类型转换成包装类型就是自动封箱 如 Integer a = 5;
把包装数据类型自动转换成基本数据类型就是自动拆箱 int a = new Integer(5);
自动装箱与拆箱是指在需要的时候,Java编译器会自动地进行这些转换,
使得我们在编程过程中更加方便地使用基本数据类型和引用数据类型
源码方面,用一句话总结装箱和拆箱的实现过程:
装箱过程是通过调用包装器的valueOf方法实现的
而拆箱过程是通过调用包装器的 xxxValue方法实现的(xxx代表对应的基本数据类型)
public static Integer valueOf(int i) {
if(i >= -128 && i <= IntegerCache.high) // 没有设置的话,IngegerCache.high 默认是127
return IntegerCache.cache[i + 128];
else
return new Integer(i);//这里就看到了 超过一个字节大小的整数就变成了new一个对象
// Integer a = 1;
// Integer b = 1;
// System.out.println(a == b);//true 这里都是引用的常量池里面的1
// Integer c = 100000000;
// Integer d = 100000000;
// System.out.println(c==d);//false 使用了new嘛
}
public static Double valueOf(double d) {
return new Double(d);
}
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
自动类型提升(隐式类型转换)
取值范围小的数据类型与取值范围大的数据类型进行运算,会先将小的数据类型提升为大的数据类型,在进行运算
public static void main(String[] args) {
//自动类型提升(隐式类型转换)
int x=3;
byte b=4;
//在java中想要参与运算,必须保持两边的数据类型要保证一致,将byte类型的b自动提升为int类型
x=x+b;
System.out.println(x);
}
}
强制类型转换
将数据类型强制转换成别的类型数据,从小的转化为大的数据类型
数据类型转换总结:
①java编译器,在编译期间会将所有的字面量运算,优化为结果,例如:‘A’+1优化为66
int i ='杜';char c='a';i=c-'9';输出i=40
byte fd=(byte)'田';//byte fd =(byte)30000;是强转
②int字面量在不超byte/short/char范围的时候,可以直接给byte/short/char赋值,如上(byte) (x+y)
public static void main(String[] args) {
//强制类型转换
int x =126;
byte y =4;
y=(byte) (x+y);
//强制转换有风险 转换需谨慎
System.out.println(y);
}
③进行混合运算的时候,byte/short/char类型不会相互转换,都会自动提升int类型,
public static void main(String[] args) {
/*
*① b1和b2都是变量,变量存储的值是有可能变化的,在编译期间 jvm无法判读里面具体值的大小
* ②byte类型与byte类型进行混合运算时候,都会自动提升为int类型
*/
byte b1 = /*(byte)*/3;//自动强转的过程 隐藏式强转
byte b2 = 4;
byte b3 =(byte) (b1+b2);
System.out.println(b3);
}
④其他类型进行混运算的时候,是小的数据提升为大的数据类型
public static void main(String[] args) {
/*
* 将int类型的x自动提升为long类型
* long类型的5加上long类型的7 得到long类型的结果
* 将long类型的结果12赋值给long类型的变量l
*/
int x=5;
long l =7L;
l = x+7L;
System.out.println(l);
//溢出现象
l=Integer.MAX_VALUE+1;
System.out.println(l);
//不溢出 原因:已经转换为long类型的数字
l=Integer.MAX_VALUE+1L;
System.out.println(l);
}
short s1 = 1; s1 = s1 + 1;有错吗
对于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 类型,因此 s1+1 运算结果也是 int型,需要强制转换
类型才能赋值给 short 型。
而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short(s1 + 1);其中有隐含的强
制类型转换
float f=3.4;是否正确
不正确。3.4 是双精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down-casting,也称为窄化)会造成精度损失**,因此需要强制类型转换float f =(float)3.4; 或者写成 float f =3.4F**
Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
Math.round(11.5)的返回值是 12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在参数
上加 0.5 然后进行下取整