今天给大家分享一篇关于深度学习模型Transformer的文章。我愿称之为讲解Transformer模型最好的文章。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
文章内容主要介绍 Transformer 模型的具体实现:
-
Transformer整体架构
-
Transformer概览
-
引入张量
-
自注意力机制Self-Attention
-
多头注意力机制Mutil-Head Attention
-
位置反馈网络(Position-wise Feed-Forward Networks)
-
残差连接和层归一化(Add & Normalize)
-
位置编码(Positional Encoding)
-
解码器Decoder
-
掩码Mask:Padding Mask + Sequence Mask
-
最后的线性层和Softmax层
-
嵌入层和最终的线性层
-
正则化操作
文章有点长,建议收藏
1、Transformer模型架构
2017 年,Google 在论文 Attentions is All you need(论文地址:https://arxiv.org/abs/1706.03762) 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。
相比 RNN 网络结构,其最大的优点是可以并行计算。Transformer 的整体模型架构如图所示:
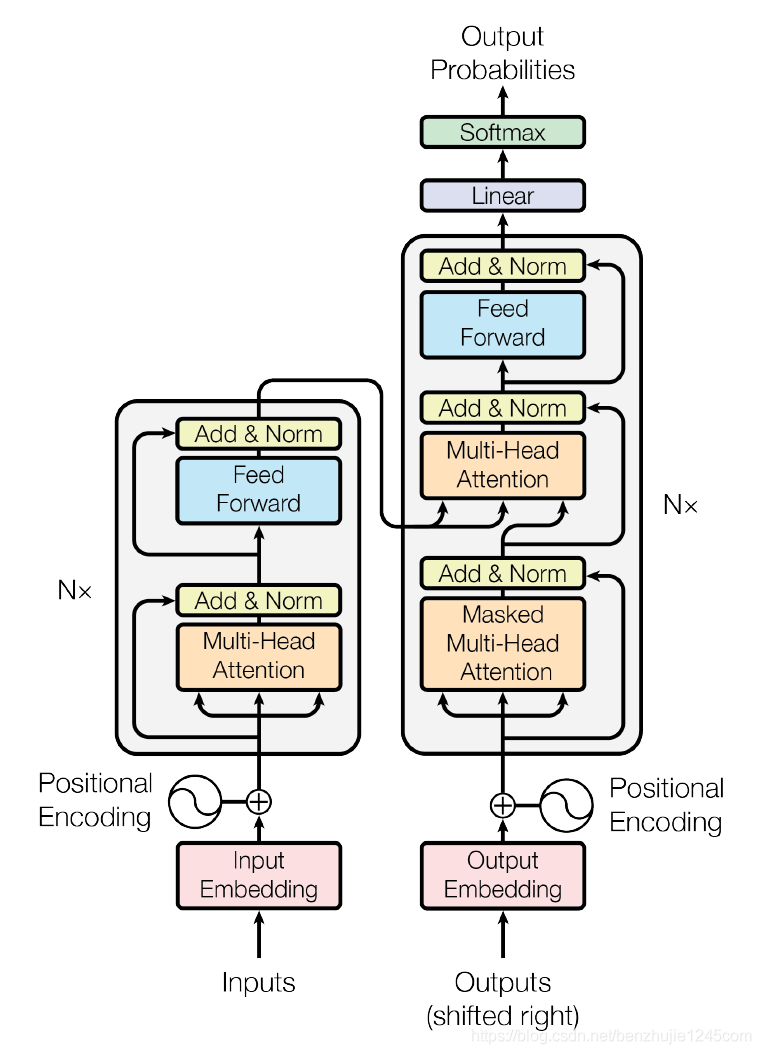
Transformer模型架构
2、Transformer 概览
首先,让我们先将 Transformer 模型视为一个黑盒,如图所示。在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出:

Transformer 模型(黑盒模式)
2.1 Encoder-Decoder
Transformer 本质上是一个 Encoder-Decoder 架构。因此中间部分的 Transformer 可以分为两个部分:编码组件和解码组件
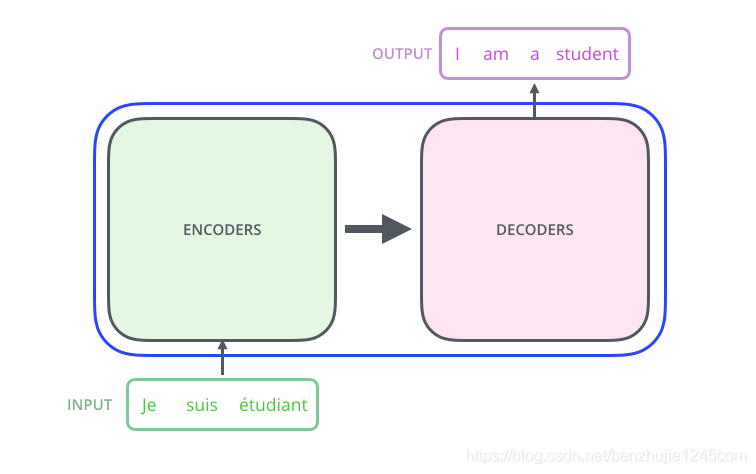
Transformer 模型(Encoder-Decoder 架构模式)
其中,编码组件由多层编码器(Encoder)组成(在论文中作者使用了 6 层编码器,在实际使用过程中你可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了 6 层)。
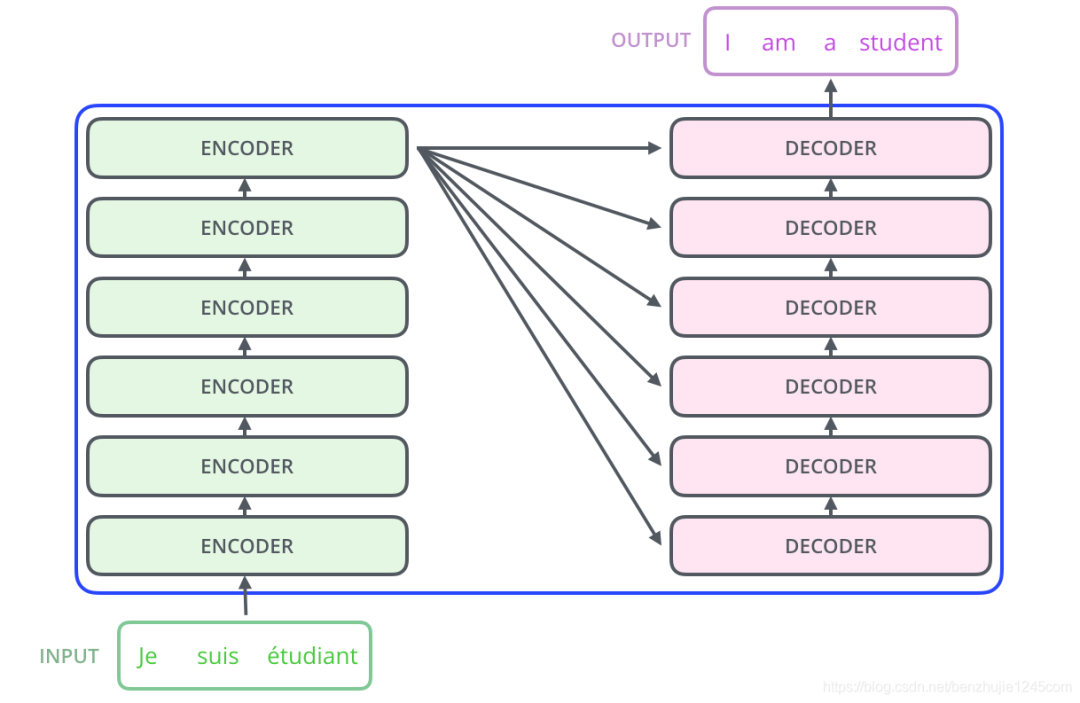
编码器/解码器组成
每个编码器由两个子层组成:
-
Self-Attention层(自注意力层) -
Position-wise Feed Forward Network(前馈网络,缩写为FFN)
如下图所示:每个编码器的结构都是相同的,但是它们使用不同的权重参数(6个编码器的架构相同,但是参数不同)
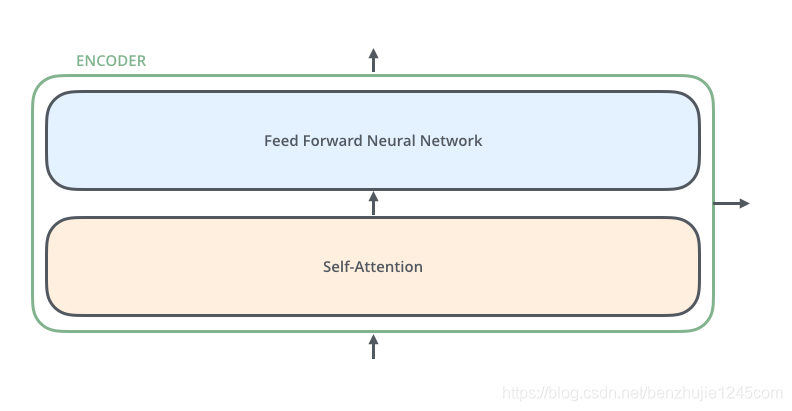
Encoder编码器组成
编码器的输入会先流入 Self-Attention 层。它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息(可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息)。
注:关注词语的上下文环境,不仅仅是词语本身
后面我们将会详细介绍 Self-Attention 的内部结构。然后,Self-Attention 层的输出会流入前馈网络。
解码器也有编码器中这两层,但是它们之间还有一个注意力层(即 Encoder-Decoder Attention),其用来帮忙解码器关注输入句子的相关部分(类似于 seq2seq 模型中的注意力)
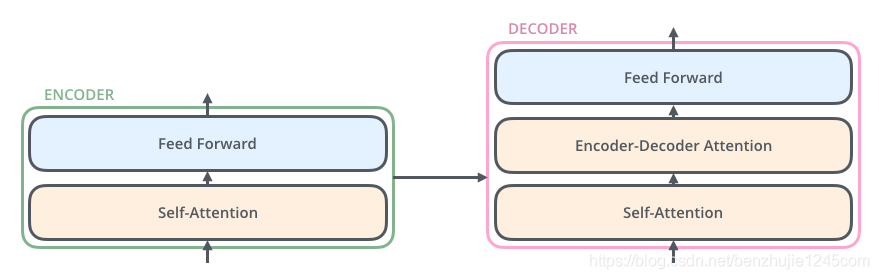
编码器:
self-attention层 + 前馈网络FFN(Position-wise Feed Forward Network)解码器:
self-attention层 +Encoder-Decoder Attention+ 前馈网络FFN(Position-wise Feed Forward Network)
3、引入张量
现在我们已经了解了模型的主要组成部分,让我们开始研究各种向量/张量,以及他们在这些组成部分之间是如何流动的,从而将输入经过已训练的模型转换为输出。
3.1 引入词嵌入Embedding
和通常的 NLP 任务一样,首先,我们使用词嵌入算法(Embedding) 将每个词转换为一个词向量。
在 Transformer 论文中,词嵌入向量的维度是 512。

每个词被嵌入到大小为
512的向量中。我们将用这些简单的框代表这些向量。
词嵌入仅发生在最底层的编码器中。所有编码器都会接收到一个大小为 512 的向量列表:
-
底部编码器接收的是词嵌入向量
-
其他编码器接收的是上一个编码器的输出。
这个列表大小是我们可以设置的超参数——基本上这个参数就是训练数据集中最长句子的长度。
3.2 词嵌入后编码
对输入序列完成嵌入操作后,每个词都会流经编码器的两层。
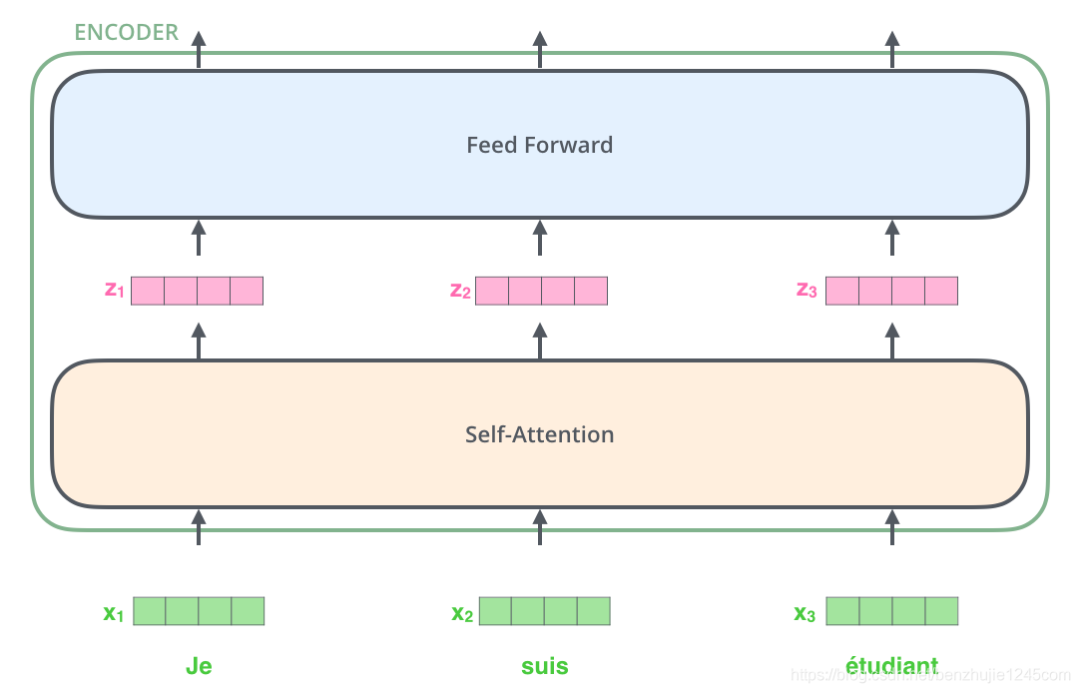
词嵌入与编码
接下来,我们将换一个更短的句子作为示例,来说明在编码器的每个子层中发生了什么。
上面我们提到,编码器会接收一个向量作为输入。编码器首先将这些向量传递到 Self-Attention 层,然后传递到前馈网络,最后将输出传递到下一个编码器。
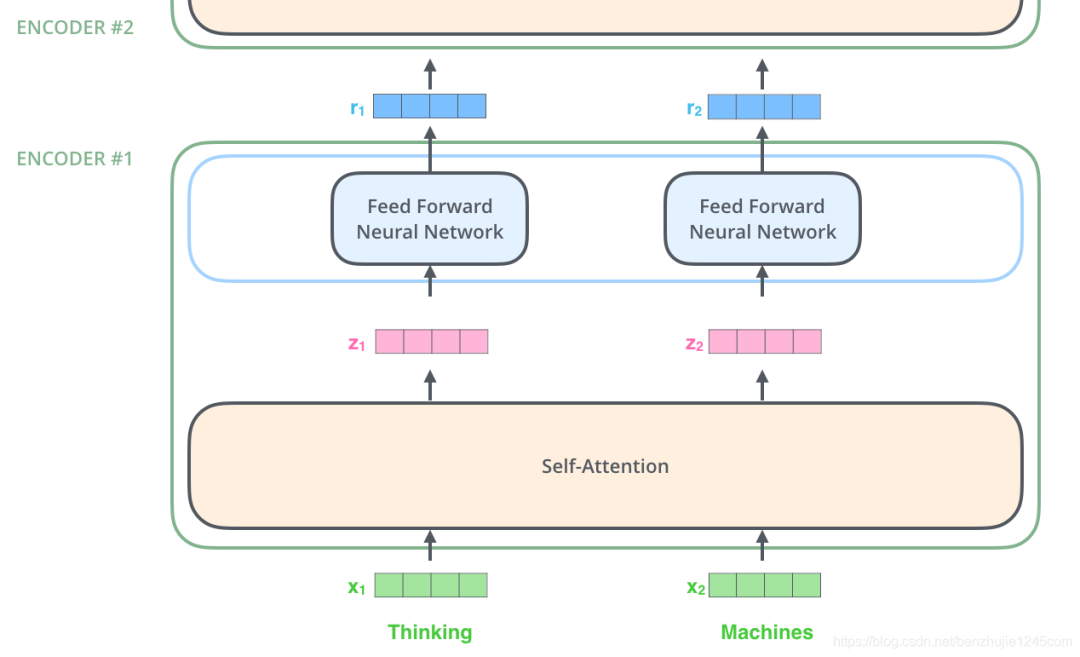
编码器揭秘
4、Self-Attention(自注意力)
4.1 Self-Attention概览
首先我们通过一个例子,来对 Self-Attention 有一个直观的认识。假如我们要翻译下面这个句子:
The animal didn’t cross the street because it was too tired
这个句子中的 it 指的是什么?是指 animal 还是 street ?对人来说,这是一个简单的问题,但是算法来说却不那么简单。
当模型在处理 it 时,Self-Attention 机制使其能够将 it 和 animal 关联起来。
当模型处理每个词(输入序列中的每个位置)时,Self-Attention 机制使得模型不仅能够关注当前位置的词,而且能够关注句子中其他位置的词,从而可以更好地编码这个词。
如果你熟悉 循环神经网络 RNN,想想如何维护隐状态,使 RNN 将已处理的先前词/向量的表示与当前正在处理的词/向量进行合并。Transformer 使用 Self-Attention 机制将其他词的理解融入到当前词中。

图注:当我们在编码器 #5(堆栈中的顶部编码器)中对单词
it进行编码时,有一部分注意力集中在The