随着 ChatGPT 等大模型席卷全球,RLHF(基于人类反馈的强化学习)已成为算法岗求职热点。
作为大模型对齐人类价值观的核心技术,RLHF 不仅决定了模型的"情商",更是面试中高频出现的必考点——如何设计奖励函数?数据标注有哪些陷阱?策略优化如何平衡性能与安全?
无论你是准备冲刺大厂,还是深入理解前沿技术,掌握 RLHF 的核心逻辑和落地难点都至关重要。本文梳理 17 道 RLHF 高频面试题+深度解析,助你斩获 offer!
Q1:什么是 RLHF?为什么要用它训练语言模型?
解析:
RLHF(基于人类反馈的强化学习)通过人类偏好数据优化模型,解决传统语言模型无法直接优化复杂目标(如“有趣且无害”)的问题。
其核心价值在于:
-
将模糊的人类价值观转化为可量化的奖励信号。
-
使模型生成更安全、有用、符合伦理的文本。
Q2:为什么 RLHF 比监督微调(SFT)更适合复杂任务?
解析:
SFT 局限:需明确“标准答案”,无法处理多目标(如“幽默且严谨”)。
RLHF 优势:
-
通过人类偏好数据定义复杂目标。
-
模型在试错中学习权衡不同目标。
案例:ChatGPT 通过 RLHF 平衡“信息量”和“无害性”。
Q3:RLHF 的训练流程分为哪几步?
解析:
预训练:用海量文本训练基础语言模型(如 GPT-3)。
奖励建模:人工标注生成结果的优劣,训练奖励模型(RM)。
强化学习优化:以 RM 为裁判,用PPO算法优化语言模型。
Q4:奖励模型(RM)的意义和训练方法是什么?
解析:
意义:
-
RM 是 RLHF 的“裁判”,将人类偏好转化为可量化的奖励信号。
-
解决语言模型无法直接优化复杂目标(如“有趣且严谨”)的问题。
训练方法:
-
数据收集:用基础模型生成多个回答,人工对回答排序(如 A > B > C)。
-
模型训练:将排序转化为 pairwise 损失函数:
-
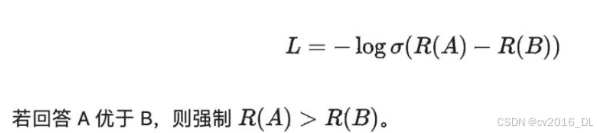
Q5:奖励模型(RM)的训练数据如何收集?
解析:
数据生成:让基础模型为同一问题生成多个候选回答(如 4-9 个)。
人工标注:标注员对回答排序或打分(例如 A > B > C)。
数据增强:覆盖多样场景(开放问答、伦理判断、逻辑推理等)。
Q6:RLHF 中奖励模型(RM)训练好后会一直不变吗?
解析:
常规情况:在单轮 RLHF 训练中,RM 固定不变,PPO 仅优化策略模型。
需更新 RM 的场景:
-
迭代训练:当策略模型生成的文本超出 RM 训练时的数据分布(如质量显著提升)。
-
奖励破解:模型找到 RM 的漏洞(例如堆砌关键词骗取高分)。
-
领域扩展:新增任务或场景需补充标注数据(如从通用对话扩展到医疗咨询)。
更新方法:重新采集人类反馈数据,微调或重新训练 RM。
Q7:价值模型(VM)的本质与作用是什么?为什么不能直接用 RM?
解析:
本质:VM 是强化学习中的状态价值函数,预测从当前状态(已生成文本)出发的长期预期收益。
核心作用:
-
信用分配:将句子级奖励拆解为 token 级收益,回答“哪个 token 对最终奖励贡献更大”。
-
序列决策支持:生成文本是逐步进行的,VM 帮助模型权衡当前动作对未来的影响。通过优势函数指导模型优化
与 RM 的关键区别:
-
输入:RM 需要完整回答,VM 仅需当前上下文。
-
输出:RM 提供全局评分,VM 提供局部价值预测。
-
角色:RM 是裁判,VM 是导航员。
Q8:价值模型的训练方法是什么?标签为何设计为衰减形式?
解析:
训练方法:

衰减设计的必要性:
-
时间折扣:未来奖励的权重应随时间递减(类似经济学中的“现值”概念,“现在的钱比未来更值钱”)。
-
数学收敛:无限累积未来奖励会导致数值爆炸,衰减确保收敛。
-
物理意义:生成早期 token 的影响需通过后续步骤传递,衰减反映这种间接性。

Q9:折扣因子(γ)为什么要设为 0.9 或 0.99?
解析:


Q10:折扣因子与早期错误的影响是否矛盾?
解析:

Q11:优势函数(Advantage)是如何计算的?
解析:

Q12:优势函数在哪些情况下会大于 0 或小于 0?
解析:

Q13:为什么价值模型存在预测误差,但优势函数仍能引导收敛?
解析:

Q14:PPO Loss 的构成是什么?如何与奖励模型关联?
思考:
PPO(Proximal Policy Optimization)的损失函数由三部分组成:

Q15:PPO 中的 KL 散度约束是什么?为什么需要它?
思考:
KL 散度:衡量优化后的语言模型与初始模型的输出分布差异。数学上表示为:
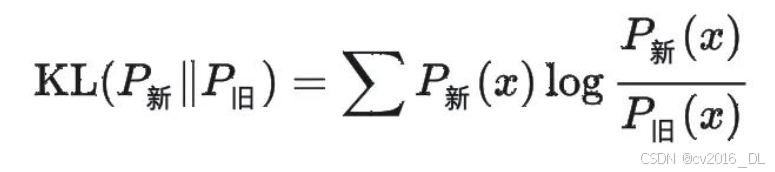
作用:
-
防止模型“放飞自我”:避免语言模型为追求高奖励生成乱码或偏离正常语言模式。
-
保持多样性:限制模型过度优化到单一高奖励模式(如重复固定句式)。
-
类比:老师允许学生改进作文,但要求“不能完全重写,必须保留原文 80% 的内容”。
Q16:RLHF 训练中如何应对“奖励破解”(Reward Hacking)?
解析:
现象:模型通过“作弊”获取高奖励(例如重复关键词“非常好!非常棒!”)。
解决方案:
-
在 RM 训练时加入正则化(如惩罚重复 n-gram)。
-
动态更新 RM 的训练数据,覆盖模型的新生成模式。
-
增加 KL 散度约束,限制策略突变。
Q17:RLHF 训练中有哪些常见失败模式?
解析:
模式坍塌:模型生成单一化回答(如所有问题都回复“这个问题需要深入分析”)。
过度优化:为追求高奖励生成不合理的文本(如过度使用复杂术语)。
人类偏好冲突:不同标注者对“好回答”的标准不一致。
解决方案:多样化训练数据、动态调整奖励函数、多人标注去噪。