Qwen-VL基于预训练好的Qwen-7B,支持text recognition、document QA、bounding box detection、multi-image interleaved conversations等功能。
1.Qwen-VL
模型架构:
-
LLM:使用预训练好的Qwen-7B; -
Visual Encoder:使用预训练好的Openclip ViT-bigG; -
Vision-Language Adapter:为了缓解长visual embedding序列带来的效率问题,引入一个Adapter,由随机初始化的单层交叉注意力模块构成。该模块使用一组可学习query,将visual embedding作为key进行cross-attention,最终获得的visual embedding为长度。此外,考虑位置信息,将二维绝对位置编码加入query-key中,减少压缩过程中丢失位置细节。
输入输出格式:
-
图像通过
visual encoder和adapter变为固定长度的序列后,使用special token<img>, </img>作为图像特征序列的开始和结束; -
对于
bounding box,先归一化为[0, 1000),并转换为string格式(X_topleft, Y_topleft), (X_bottomright, Y_bottomright),不需要增加额外的positional vocabulary,并使用special token<box>, </box>进行区分; -
对于
bounding box和对应的descriptive words or sentences,使用special token<ref>, </ref>标记bounding box参考的内容。
训练策略:
如下图所示,分为三个阶段进行训练:
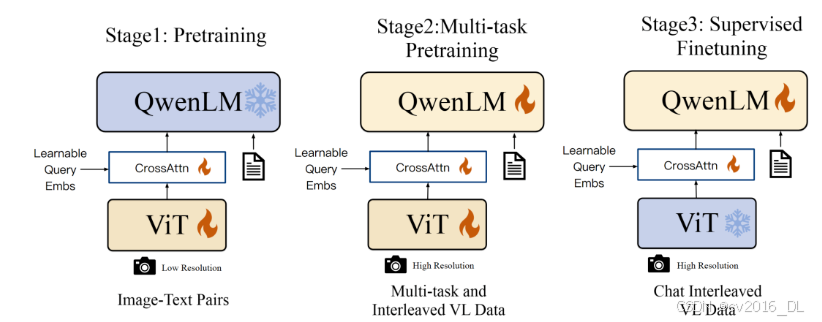
每个阶段的详细训练配置则如下图所示:
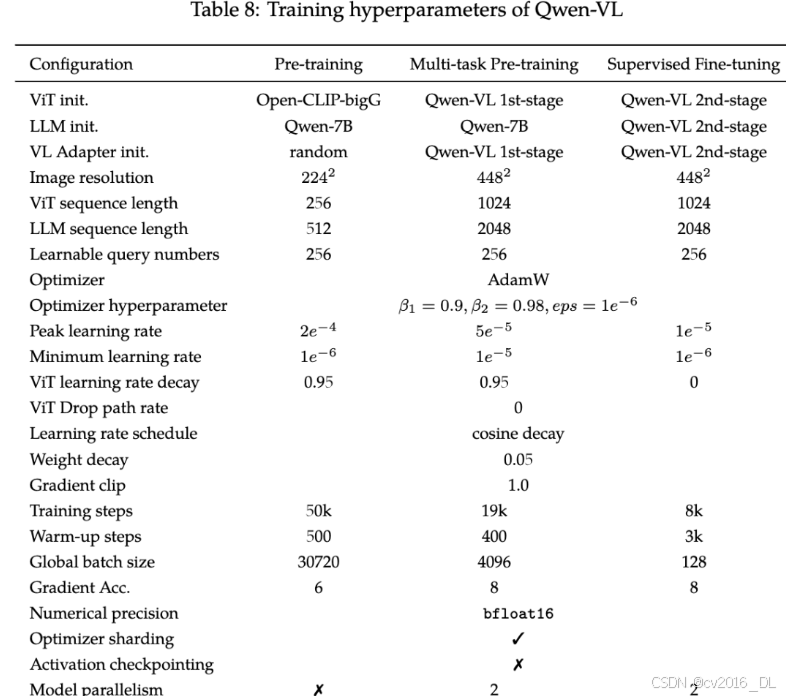
预训练:
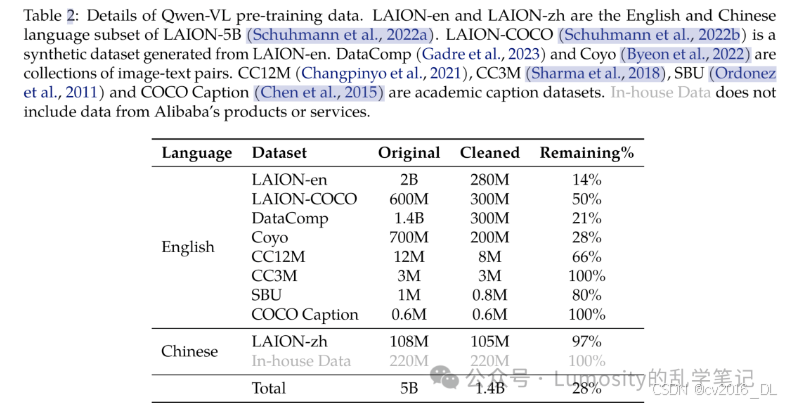
固定LLM,训练vision encoder和VL adapter,使用清洗后的约1.4b中英文image-text pairs数据;
多任务预训练:
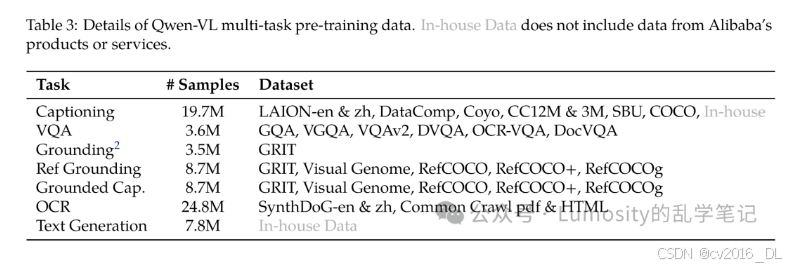
所有模型一起训练,引入具有更大分辨率448x448的高质量细粒度VL annotation data,和长度为2048的interleaved image-text data(通过将相同任务的数据packing)
监督微调:
固定vision encoder,训练VL adapter和LLM,通过instruction finetune增强指令遵循和对话能力,多模态指令微调数据通常来自于caption data和self-instruction的对话数据,但它通常只解决单图对话和推理,且仅限于图像内容理解。本文通过手动注释、模型生成、策略等构建额外的对话数据,包含定位信息和多图理解能力,在训练时则混合多模态以及纯文本对话数据,保证模型对话能力的普适性。
2.Qwen2-VL
Qwen2-VL基于预训练好的Qwen2,发布2B, 8B, 72B三个版本,算法上主要引入了Naive Dynamic Resolution mechanism,使得模型可以处理不同大小的图像,且集成Multimodal Rotary Position Embedding (M-RoPE),使得文本、图像、视频等位置信息可有效融合,并且统一处理文本、图像、视频的方式,增强了模型的视觉感知能力。
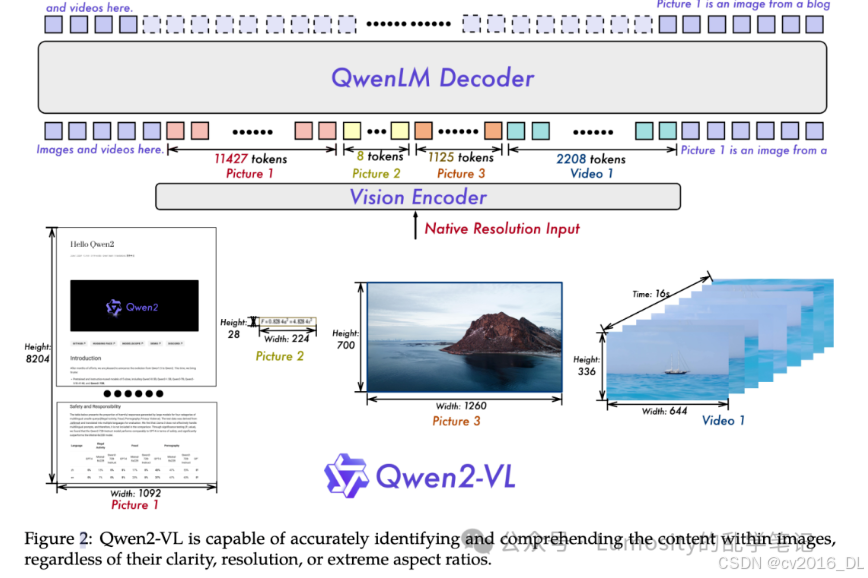
-
模型架构:
基本跟
Qwen-VL一致,由vision encoder和Qwen2 decoder组成,vison encoder可以同时处理图像和视频,主要创新点在于:
-
Naive Dynamic Resolution mechanism:可以处理任意分辨率图像,即将图像转变为不定长的
visual token,故去除了ViT原始的绝对位置编码,改为二维RoPE以捕捉位置信息;且为了减少每幅图像的visual token长度,在ViT后额外增加MLP将相邻的 2x2visual token进一步压缩为单token,即分辨率为224x224的图像使用patch_size=14的ViT编码后变为66 token(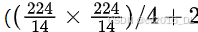 ,2为
,2为special token<|vision_start|>, <|vision_end|>) -
Multimodal Rotary Position Embedding (M-RoPE):如下所示,将原始的
rotary embedding拆分为三部分:temporal, height, width。对于text,则所有维度使用相同的position IDs,等价于1D-RoPE;对于image,则temporal维度为常数,height, width则使用图像的位置信息;对于video,则temporal根据时序关系增加。在输入包含多种模态的情况下,每种模态的位置编码使用前一模态的max position id + 1来初始化。

-
Unified Image and Video Understanding:Qwen2-VL采用混合训练策略。为了尽可能保留视频信息,每个视频每秒两帧采样,并使用3D convolution with depth=2去处理视频输入,可以在不增加序列长度的情况下处理更多的视频帧;为了一致性,则将图像视为两个相同的视频帧。此外,为了平衡长视频的计算复杂度和训练效率,动态调整视频帧的分辨率,每个视频的总token限制为16384。
-
训练策略:
如同
Qwen-VL分为三阶段训练:1)在第一阶段,只训练ViT部分,通过image-text pair增加LLM的语义理解和视觉对齐;2)在第二阶段,所有组件放开训练;3)在第三阶段,使用多模态对话数据,训练LLM部分。
3.Qwen2.5-VL
根据transformers库的PR,Qwen2.5-VL在Qwen2-VL的基础上,可支持的最大分辨率到2048x2048,主要优化的点在于:
-
LLM部分使用最新的Qwen2.5; -
ViT部分使用sliding window attention去加速(并不是所有层,仅后面的部分层),并使用SwiGLU和RMSNorm; -
Naive Dynamic Resolution mechanism新增temporal维度; -
Multimodal Rotary Position Embedding (M-RoPE)在temporal维度结合绝对时间对齐,提高模型在任意帧率情况下的信息捕捉能力,以实现更好的视频理解。