1. EfficientNet
EfficientNet 系列模型是图片分类领域中精度最高的模型之一,由 Google 公司通过机器搜索技术开发而成。该模型以其快速且高精度的特点而闻名,其核心优势在于通过深度(depth)、宽度(width)和输入图片分辨率(resolution)的共同调节技术来优化性能。
谷歌利用这种技术开发了一系列版本,从 EfficientNet-B0 到 EfficientNet-B8,再到 EfficientNet-L2 和 Noisy Student,共 11 个系列版本。其中,Noisy Student 版本表现最为出色。以下是这些模型在 ImageNet 数据集上的精度对比结果:
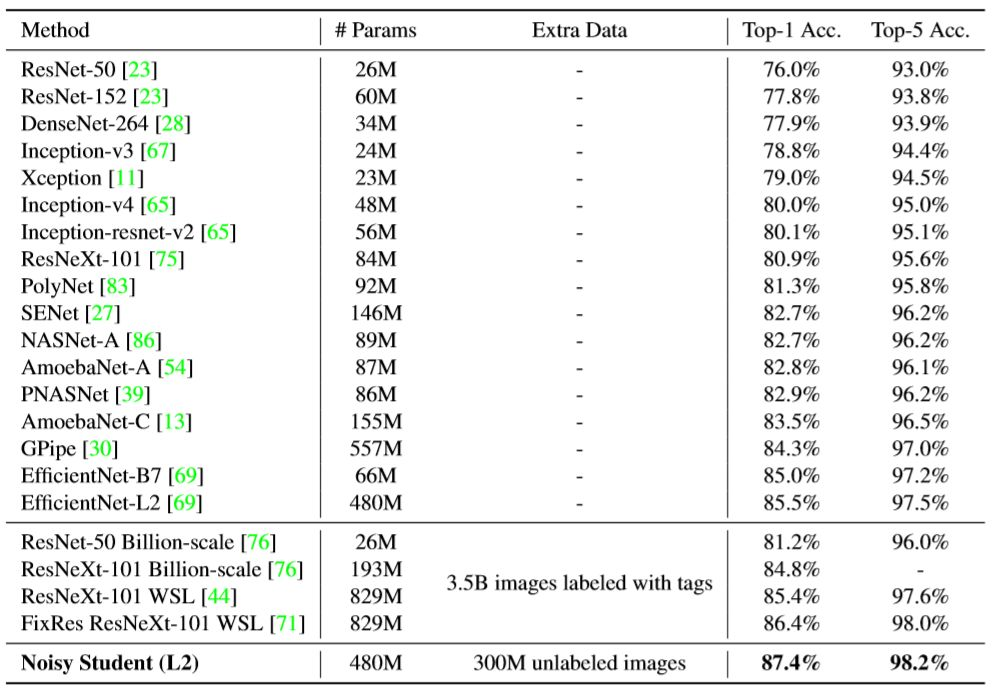
从上图可以看出,Noisy Student 模型在 ImageNet 数据集上达到了 87.4% 的 top1 准确性和 98.2% 的 top5 准确性,是目前精度最高的模型。
EfficientNet 系列模型的主要结构基于其独特的构建方法,主要包括以下两个步骤:
- 基线模型生成:使用强化学习算法实现的 MnasNet 模型生成基线模型 EfficientNet-B0。
- 复合缩放:在预先设定的内存和计算量限制条件下,对 EfficientNet-B0 模型的深度、宽度(特征图的通道数)和图片大小三个维度同时进行缩放。这三个维度的缩放比例是通过网格搜索得到的,最终输出了 EfficientNet 模型。
下图展示了 EfficientNet 模型的缩放过程:
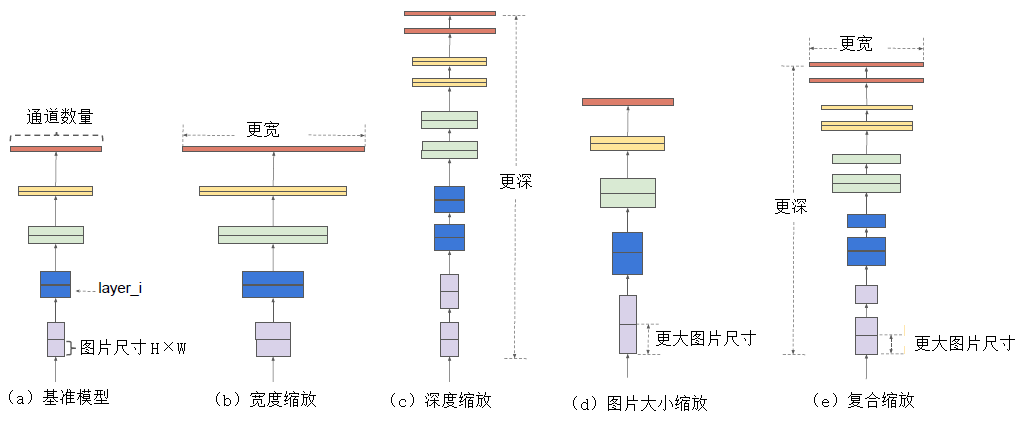
在上图中,各个子图的含义如下:
- 子图(1):基准模型。
- 子图(2):在基准模型的基础上进行宽度缩放,即增加图片的通道数量。
- 子图(3):在基准模型的基础上进行深度缩放,即增加网络的层数。
- 子图(4):在基准模型的基础上对图片的大小进行缩放。
- 子图(5):在基准模型的基础上对图片的深度、宽度和大小同时进行缩放。
2. Vision Transformer (ViT)
Vision Transformer(ViT)是成功将 Transformer 架构 应用于计算机视觉领域的开创性工作,由 Google 开发。ViT 被归类为 监督学习,其核心思想是将输入图像分割成多个小块(patch),并将这些小块输入到 Transformer Encoder 中进行处理。这些小块在 ViT 中的作用类似于自然语言处理中的 token。
对于分类任务,ViT 引入了一个特殊的 token——class-token。在最后一个注意力层的输出中,class-token 包含了整个图像的表示,可用于后续的分类任务。ViT 的架构示意图如下所示:
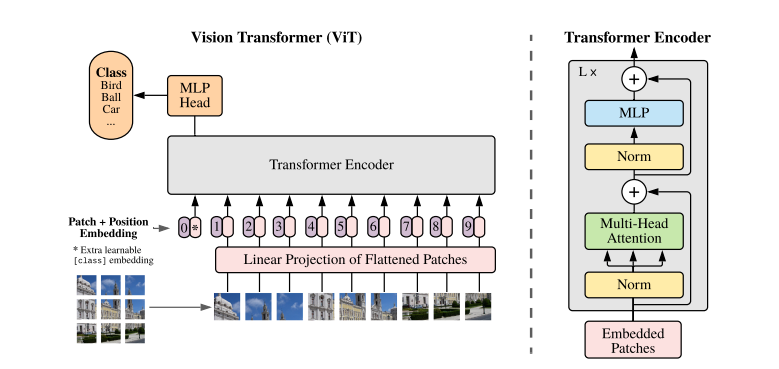
与传统的卷积神经网络(CNN)相比,ViT 的一个显著优势在于其能够通过自注意力机制利用图像的全局信息,从而更好地捕捉图像的整体特征。与 EfficientNet 类似,ViT 的性能也随着模型规模的增大而提升。
下表展示了不同规模 ViT 模型的性能对比:
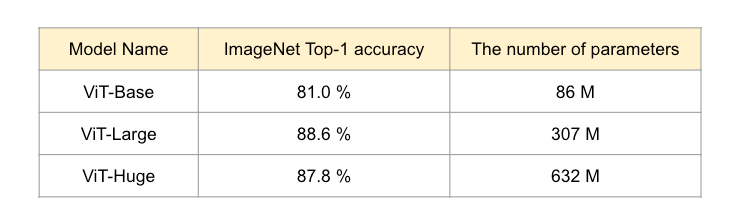
从表中可以看出,较大的 ViT 模型在精度上优于 EfficientNet。在实际应用中,提取的嵌入通常是 class-token 的输出,因为它包含了整个图像的语义信息。
3. DINO-v2
DINO-v2 是由 Meta 开发的一种用于生成通用视觉特征的基础模型。该模型的核心创新在于将 自监督学习方法 应用于 Vision Transformer(ViT)架构,从而能够理解图像和像素级别的特征。因此,DINO-v2 可以灵活应用于各种计算机视觉任务,如图像分类、目标检测和语义分割等。
在架构设计上,DINO-v2 基于其前身 DINO(“无标签知识蒸馏”的缩写)进行改进。DINO 的核心思想是通过协同蒸馏的方式,让两个网络(学生网络和教师网络)相互学习。这两个网络具有相同的架构,并且在训练过程中双向应用蒸馏机制,即从教师网络向学生网络传递知识,同时从学生网络向教师网络反馈信息。需要注意的是,学生到教师的蒸馏使用的是学生网络输出的平均值。
下图展示了 DINO 的架构示意图:
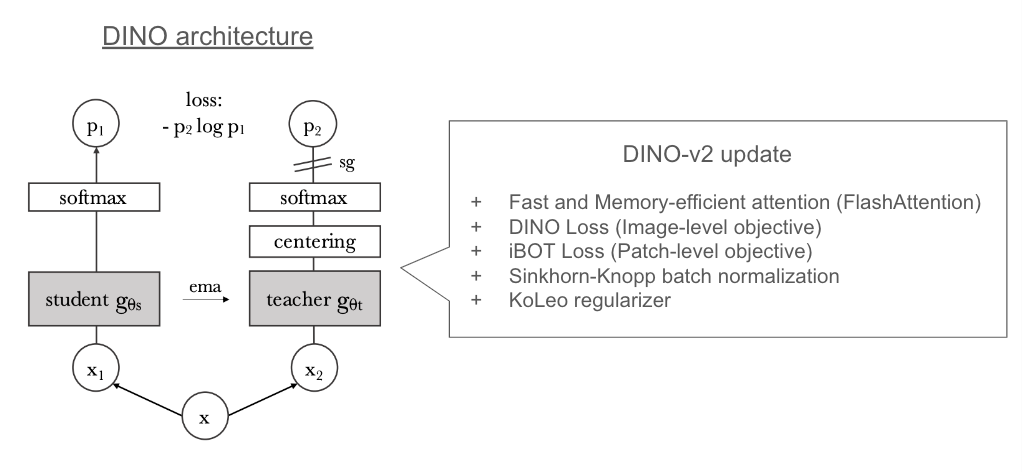
在 DINO-v2 中,作者对训练方法进行了更新,增加了新的损失函数和正则化项,以进一步提升模型性能。此外,他们还精心策划了一个高质量的数据集,用于训练更优秀的图像特征。
在实验中,我们通常使用 class-token 的输出作为特征提取结果,因为这些输出包含了整个图像的语义信息,类似于 ViT 的处理方式。
4. CLIP
CLIP 是由 OpenAI 开发的一种革命性的多模态模型,被归类为 弱监督学习。CLIP 的核心架构基于 Transformer,其创新之处在于能够将图像和文本特征对齐,从而实现零样本图像分类。CLIP 的架构示意图如下所示:
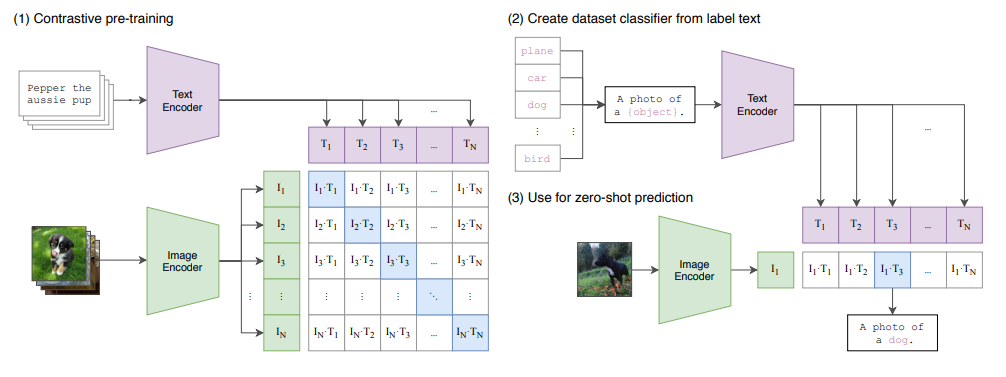
CLIP 的架构包含两个主要部分:文本编码器和图像编码器。通过对比损失函数,CLIP 能够将文本和图像特征对齐到同一个特征空间中。因此,它可以通过计算图像特征与文本特征之间的相似度,找到最匹配的文本描述,从而实现零样本分类。
在特征提取方面,CLIP 的图像编码器基于 Transformer 架构,其输出的 class-token 包含了整个图像的语义信息。因此,在实际应用中,我们通常使用图像编码器中 class-token 的输出作为特征提取结果。
5. BLIP-2
BLIP-2 是由 Salesforce 在 2023 年开发的一种开源多模态模型,被归类为 监督学习。BLIP-2 的核心目标是利用预训练的大型模型(如 FlanT5 和 CLIP)来实现高效的训练,因为从头开始训练大型模型在计算资源和时间成本上都非常高昂。
为了对齐不同预训练模型之间的特征空间,BLIP-2 引入了一种名为 Q-Former 的架构。Q-Former 的作用是将预训练图像编码器的图像特征与文本特征对齐,从而实现多模态融合。
BLIP-2 的训练过程分为两个阶段:
- 第一阶段:训练 Q-Former,使其能够对齐来自预训练图像编码器的图像特征和文本特征。这一阶段使用了多种损失函数,如图像-文本匹配损失、图像-文本对比损失和基于图像的文本生成损失。
- 第二阶段:再次训练 Q-Former,将其特征空间与大型语言模型(如 FlanT5)对齐。通过这种方式,Q-Former 能够同时理解来自文本和图像的特征。
在特征提取方面,我们通常使用 Q-Former 的输出作为特征提取层,因为这些输出能够融合图像和文本的语义信息。
6. 代码测试
6.1 环境设置
为了进行图像相似性搜索的实验,我们使用 Python 3.10 的 conda 环境,并在 Windows 10 系统上进行测试。测试环境配置如下:
- GPU:RTX 4060
- CUDA 版本:11.6
- GPU 内存:8 GB
- 系统内存:16 GB
以下是环境搭建的具体步骤:
conda create -n tf python=3.10 -y
conda activate tf
接下来,需要通过 conda 和 pip 安装以下库:
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
pip install faiss-cpu==1.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
在本实验中,我们使用 Faiss 库来测量图像相似性并进行图像相似性搜索。Faiss 是一个基于近似最近邻搜索算法的高效相似性搜索库。此外,我们将使用 Flickr30k 数据集进行实验。在正式开始图像相似性搜索之前,我们首先需要了解如何从每个模型中提取特征。
6.2 提取特征
我们将使用 Hugging Face 的 transformers 库来提取嵌入。与原始的 PyTorch 实现相比,transformers 库能够更轻松地提取隐藏状态。本节代码将检查输入和输出维度,因此我们将在 CPU 上运行它们。
EfficientNet
EfficientNet 的特征提取代码如下所示:
import torch
from transformers import AutoImageProcessor, EfficientNetModel
from PIL import Image
# 加载预训练的 EfficientNet-B7 图像处理器和模型权重
image_processor = AutoImageProcessor.from_pretrained("google/efficientnet-b7")
model = EfficientNetModel.from_pretrained("google/efficientnet-b7")
test_image = Image.open("1.jpeg") # 替换为你的图像路径
# 准备输入图像
inputs = image_processor(test_image, return_tensors='pt')
print('输入形状: ', inputs['pixel_values'].shape)
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
embedding = outputs.hidden_states[-1]
print('嵌入形状: ', embedding.shape)
embedding = torch.mean(embedding, dim=[2, 3])
print('降维后: ', embedding.shape)
### 输入形状: torch.Size([1, 3, 600, 600])
### 嵌入形状: torch.Size([1, 640, 19, 19])
### 降维后: torch.Size([1, 640])
首先,需要准备输入。预定义的 EfficientNet 图像处理器会自动将输入形状处理为 (batch_size, 3, 600, 600)。经过模型处理后,可以获得带有隐藏状态的输出。最后一个隐藏状态的维度为 (batch_size, 640, 19, 19),因此对获得的嵌入应用降维平均处理。
ViT
对于 ViT 的特征提取,代码如下所示:
import torch
from transformers import AutoImageProcessor, ViTModel
from PIL import Image
image_processor = AutoImageProcessor.from_pretrained("google/vit-large-patch16-224-in21k")
model = ViTModel.from_pretrained("google/vit-large-patch16-224-in21k")
test_image = Image.open("1.jpeg")
# 准备输入图像
inputs = image_processor(test_image, return_tensors='pt')
print('输入形状: ', inputs['pixel_values'].shape)
with torch.no_grad():
outputs = model(**inputs)
embedding = outputs.last_hidden_state
embedding = embedding[:, 0, :].squeeze(1)
print('嵌入形状: ', embedding.shape)
### 输入形状: torch.Size([1, 3, 224, 224])
### 嵌入形状: torch.Size([1, 1024])
同样,预定义的 ViT 图像处理器会自动将输入形状处理为 (batch_size, 3, 224, 224)。最后一个隐藏状态的维度为 (batch_size, 197, 1024),我们只需要 class-token,因此提取第二个维度(197)的第一个索引。
DINO-v2
DINO-v2 基于 ViT,因此基础代码几乎相同。区别在于我们加载 DINO-v2 的图像处理器和模型。提取代码如下所示:
import torch
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
# 加载图像
test_image = Image.open("image.jpg") # 替换为你的图像路径
# 加载预训练的 DINOv2 图像处理器和模型权重
image_processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model = AutoModel.from_pretrained('facebook/dinov2-base')
# 准备输入图像
inputs = image_processor(images=test_image, return_tensors='pt')
print('输入形状: ', inputs['pixel_values'].shape) # 输出: torch.Size([1, 3, 224, 224])
# 禁用梯度计算以提升推理速度
with torch.no_grad():
outputs = model(**inputs)
# 提取嵌入向量
embedding = outputs.last_hidden_state # 获取最后一层隐藏状态
embedding = embedding[:, 0, :].squeeze(1) # 提取 [CLS] token 的特征并压缩维度
print('嵌入形状: ', embedding.shape) # 输出: torch.Size([1, 768])
基本上,我们使用相同的图像处理器。预定义的 ViT 图像处理器会自动将输入形状处理为 (batch_size, 3, 224, 224)。最后一个隐藏状态的维度为 (batch_size, 197, 1024),我们只需要 class-token,因此提取第二个维度(197)的第一个索引。
CLIP
CLIP 也基于 ViT,因此过程相同。Hugging Face 的 transformers 库已经为 CLIP 提供了特征提取方法,因此实现更加直接。
import torch
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
# 加载图像
test_image = Image.open("image.jpg") # 替换为你的图像路径
# 加载预训练的 CLIP 图像处理器和模型权重
image_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
# 准备输入图像
inputs = image_processor(images=test_image, return_tensors='pt', padding=True)
print('输入形状: ', inputs['pixel_values'].shape) # 输出: torch.Size([1, 3, 224, 224])
# 禁用梯度计算以提升推理速度
with torch.no_grad():
outputs = model.get_image_features(**inputs)
print('嵌入形状: ', outputs.shape) # 输出: torch.Size([1, 512])
### 输入形状: torch.Size([1, 3, 224, 224])
### 嵌入形状: torch.Size([1, 512])
我们使用相同的图像处理器。预定义的 ViT 图像处理器会自动将输入形状处理为 (batch_size, 3, 224, 224)。get_image_features 方法可以提取给定图像的嵌入,输出维度为 (batch_size, 512)。这与 ViT 和 DINO-v2 的处理方式有所不同。
BLIP-2
对于 BLIP-2,我们可以从 ViT 和 Q-Former 的输出中提取图像嵌入。在这种情况下,Q-Former 的输出可以包含来自图像和文本视角的语义,因此我们将使用它。
from transformers import Blip2Processor, Blip2Model
from PIL import Image
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
# 准备输入图像
test_image = Image.open("image.jpg") # 替换为你的图像路径
inputs = processor(images=test_image, return_tensors='pt', padding=True)
print('输入形状: ', inputs['pixel_values'].shape)
with torch.no_grad():
outputs = model.get_qformer_features(**inputs)
print('嵌入形状: ', outputs.shape)
我们使用 BLIP-2 处理器,它可以处理图像和文本输入。它会自动将图像输入形状处理为 (batch_size, 3, 224, 224)。我们可以使用 get_qformer_features 提取 Q-Former 的输出,输出维度为 (batch_size, 32, 768)。我们通过取平均值来减少输出,嵌入维度将为 (batch_size, 768)。
6.3 图像相似性搜索
现在我们已经了解了如何从每个模型中提取嵌入。接下来,我们将使用 Faiss 库实现图像相似性搜索。Faiss 是一个基于近似最近邻搜索算法的高效相似性搜索库。我们将使用余弦相似度作为距离度量。
以下是实现图像相似性搜索的代码:
import numpy as np
import faiss
# 假设 features 是从模型中提取的特征向量
# 将特征类型转换为 np.float32
features = features.astype(np.float32)
# 获取嵌入维度
vector_dim = features.shape[1]
# 将嵌入注册到 Faiss 向量存储
index = faiss.IndexFlatIP(vector_dim)
faiss.normalize_L2(features)
index.add(features)
# 对于向量搜索,我们只需调用 search 方法
top_k = 5
# 假设 embed 是我们要搜索的嵌入向量
faiss.normalize_L2(embed)
distances, ann = index.search(embed, k=top_k)
6.4 图像相似性搜索结果的比较
在本节中,我们将比较使用五个模型进行图像相似性搜索的结果。为了进行实验,我们使用了从 Flickr30k 数据集中随机挑选的 10,000 张图像。以下是部分实验结果的展示和分析。
示例图像

从 Flickr30k 数据集中挑选的图像
3637013.jpg 的搜索结果

作者对 3637013.jpg 进行的图像相似性搜索
这种情况相对较简单,因此所有模型都可以挑选出语义相似的图像。
3662865.jpg 的搜索结果
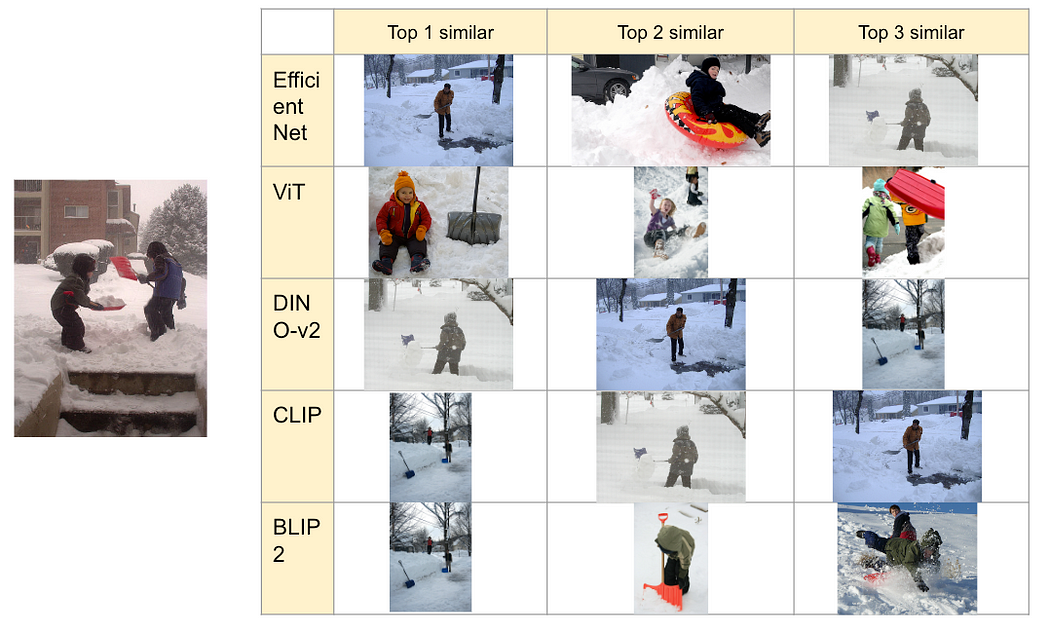
作者对 3662865.jpg 进行的图像相似性搜索
在这种情况下,DINO-v2 和 CLIP 可以捕捉到“铲雪”的语义,但其他模型有时只能捕捉到“雪”。
440375442.jpg 的搜索结果
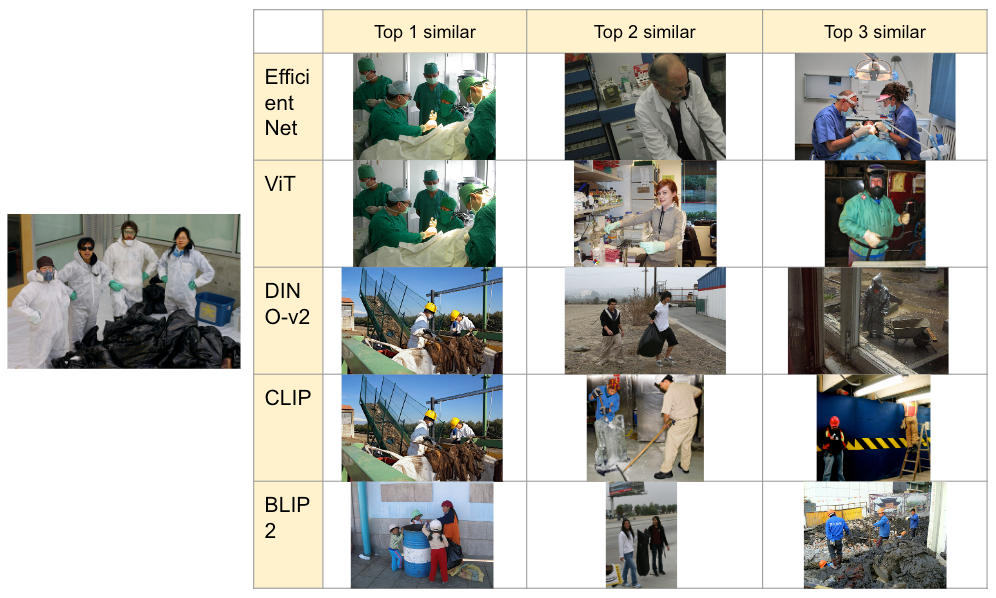
作者对 440375442.jpg 进行的图像相似性搜索
EfficientNet 和 ViT 可能会将工作服误解为手术服,因此它们无法捕捉到目标图像的语义。DINO-v2 可以理解“垃圾和穿工作服的人”的语义,CLIP 专注于穿工作服的人,而 BLIP-2 专注于垃圾。我们认为 DINO-v2、CLIP 和 BLIP-2 可以捕捉到语义。
1377428277.jpg 的搜索结果
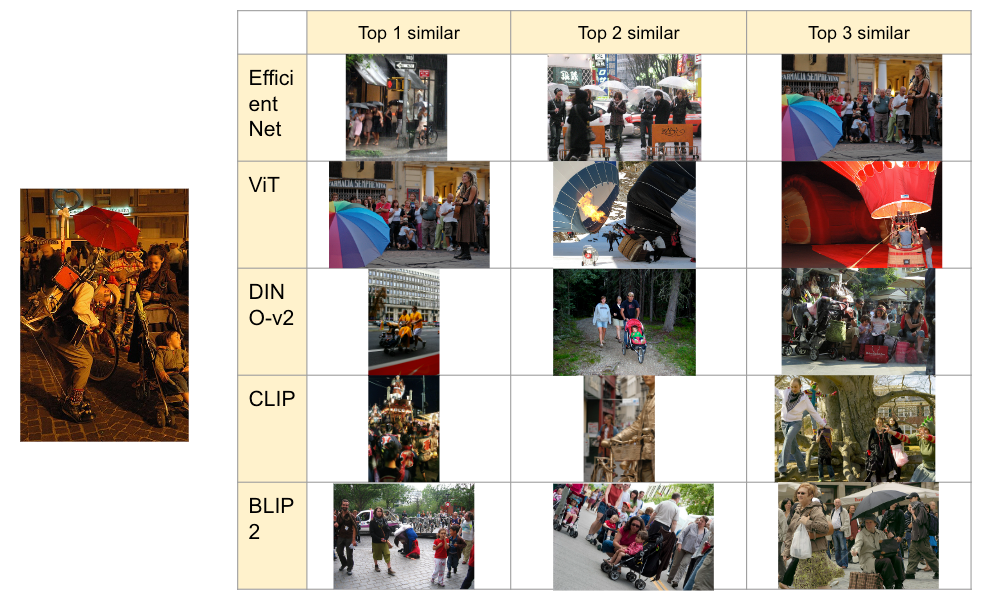
作者对 1377428277.jpg 进行的图像相似性搜索
这张图像的语义是:“街上有很多人在享受某个节日或街头表演。” EfficientNet 和 ViT 专注于雨伞,因此它们无法捕捉到语义。另一方面,DINO 专注于婴儿车,表现稍逊一筹。CLIP 试图捕捉节日和街头的部分,但也稍逊一筹。BLIP-2 可以捕捉到街头表演和婴儿车。
57193495.jpg 的搜索结果

作者对 57193495.jpg 进行的图像相似性搜索
在这种情况下,EfficientNet、ViT 和 CLIP 有时可以捕捉到“穿着戏服并涂白脸的女人”的语义。然而,它们相对不足。相比之下,DINO-v2 和 BLIP-2 可以捕捉到服装或角色扮演的语义。
1393947190.jpg 的搜索结果

作者对 1393947190.jpg 进行的图像相似性搜索
结果因架构(CNN 和 Transformer)而异。虽然 EfficientNet 可能专注于图像的白色和棕色,但其他模型可以捕捉到“人在纺丝”的语义。CLIP 可能专注于传统手工艺品,但其他模型可以捕捉到语义。
6.5 总结
通过对上述实验结果的分析,可以得出以下结论:
- EfficientNet(CNN 架构):不擅长捕捉超出像素信息的语义。
- Vision Transformer(ViT):比 CNN 更好,但仍然专注于像素信息而不是图像的含义。
- DINO-v2:可以捕捉图像的语义,并且倾向于专注于前景物体。
- CLIP:可以捕捉语义,但有时可能会受到可以从图像中读取的语言信息的强烈影响。
- BLIP-2:可以捕捉语义,是其他模型中最优越的结果。
综上所述,在进行图像相似性搜索时,应该优先选择 DINO-v2 或 BLIP-2 以获得更好的结果。具体选择取决于应用场景:
- 如果专注于图像中的物体,应该使用 DINO-v2。
- 如果更关注超出像素信息的语义(如情境),应该使用 BLIP-2。
通过以上分析和比较,可以更清晰地了解不同模型在图像相似性搜索任务中的优势和局限性,从而为实际应用提供有价值的参考。