一、数据回滚的定义
定义:数据回滚是一种数据库管理技术,它允许将数据库的状态恢复到之前的某个时间点或事务之前的状态。在数据库事务处理过程中,事务是一系列操作的逻辑单元,这些操作要么全部成功执行(提交),要么全部不执行(回滚)。例如,在一个银行转账系统中,从账户A转账到账户B是一个事务,它包括从账户A扣除金额和向账户B增加金额这两个操作。如果在执行过程中出现问题,比如账户A扣除金额后,由于系统故障无法向账户B增加金额,那么就需要进行数据回滚,将账户A的金额恢复到转账之前的状态,以保证数据的一致性。
二、数据回滚的实现原理
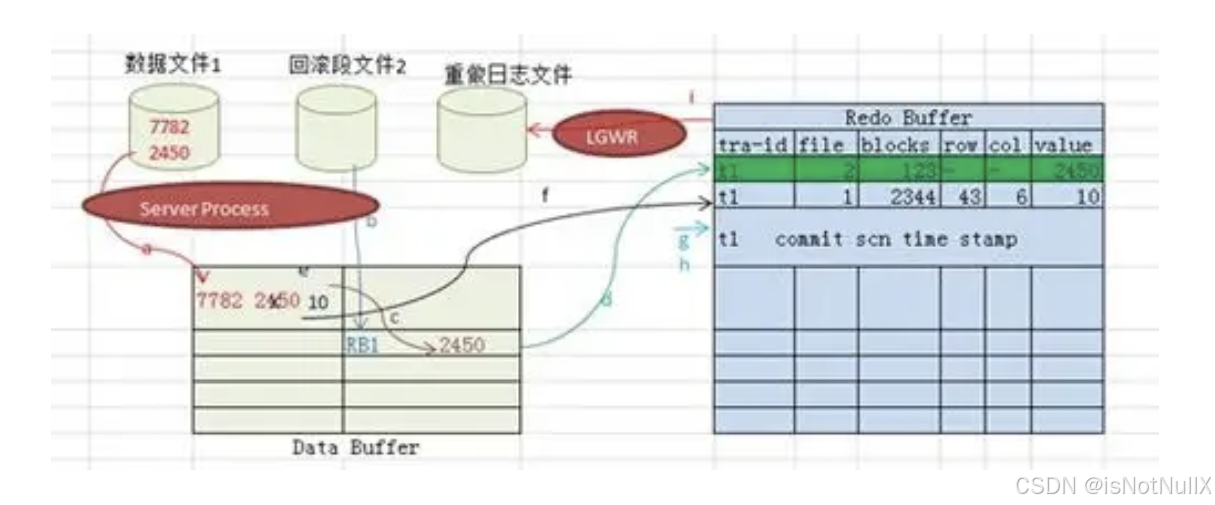
1、基于日志的回滚
数据库系统通常会维护一个事务日志(如MySQL的redo log和undo log)。redo log用于记录事务对数据库所做的修改,以便在系统崩溃后可以重做(redo)这些修改来恢复数据。undo log则用于记录如何撤销(undo)已经完成的操作。当需要进行数据回滚时,数据库管理系统会读取undo log中的信息。例如,在更新一条记录时,undo log中会记录该记录原来的值。如果要回滚这个更新操作,系统就会根据undo log中的记录将数据恢复到更新之前的状态。
2、保存点(Savepoint)机制
有些数据库支持保存点的设置。在一个复杂的事务中,可以设置多个保存点。例如,在一个包含多个子操作的存储过程中,可以在每个重要的子操作之前设置一个保存点。如果在某个子操作之后出现问题,就可以回滚到最近的保存点,而不是回滚整个事务。这提供了更精细的回滚控制。在SQL中,可以使用SAVEPOINT语句来设置保存点,使用ROLLBACK TO SAVEPOINT语句来回滚到指定的保存点。
三、数据回滚主要解决的问题
1、事务失败恢复
1)系统故障情况:当数据库系统遇到硬件故障(如硬盘损坏)、软件故障(如数据库进程崩溃)或其他意外情况(如突然断电)时,可能会导致正在进行的事务中断。通过数据回滚,可以将未完成的事务撤销,避免数据处于不一致的状态。例如,一个电商系统在处理订单时,正在更新库存和订单状态,如果系统在这个过程中崩溃,回滚机制可以确保库存和订单状态不会因为部分更新而出现错误。
2)数据一致性维护
并发事务冲突:在多用户或多线程环境下,多个事务可能同时访问和修改相同的数据。如果不进行适当的控制,可能会导致数据不一致。例如,两个用户同时对一个账户进行取款操作,如果没有合适的并发控制和回滚机制,可能会导致账户余额错误。通过回滚,可以在检测到并发冲突导致的数据不一致时,撤销部分事务的操作,以保证数据的一致性。
3)业务规则违反:当事务执行过程中违反了预先定义的业务规则时,也需要进行回滚。例如,在一个商品销售系统中,如果用户下单的商品数量超过了库存数量,按照业务规则这个订单应该是无效的,此时就需要回滚这个订单相关的操作,包括扣除库存、生成订单记录等操作,以确保系统数据符合业务逻辑。
4)数据丢失:数据回滚可以作为一种数据恢复手段。如果数据库系统或数据处理工具支持回滚功能,并且在数据丢失事件发生之前有合适的备份或日志记录,就可以通过回滚操作来还原被删除或覆盖的数据。例如,数据库的备份策略结合回滚日志,可以在数据丢失后将数据库恢复到最近一次完整备份的状态,然后利用回滚日志将后续的操作进行还原,从而避免数据的永久丢失。
借助工具实现数据回滚,确保数据一致性,FineDataLink是一个强大的数据处理工具,它不仅可以进行数据中断后的数据回滚,数据清洗和转换,还能轻松连接多种数据源,如数据库、文件和云存储等。通过使用FDL,确保数据的完整性、一致性和准确性。
了解更多数据仓库与数据集成关干货内容请关注>>>FineDataLink官网
免费试用、获取更多信息,点击了解更多>>>体验FDL功能