目录标题
一、访问官网
- 穿越虫洞
- 下载地址:https://ollama.com/download/windows
如果慢,可以使用下载工具,提高下载速度
运行下载后的安装包
省略
验证是否安装成功

如何不小心退出了ollama:win开始–ollama–以管理员身份运行–托盘running
ollama 常用命令参考:
二、ollama 可以通过127.0.0.1访问,但是无法通过本机ip访问
现象:
默认ip为127.0.0.1,启动后发现只能在浏览器中通过
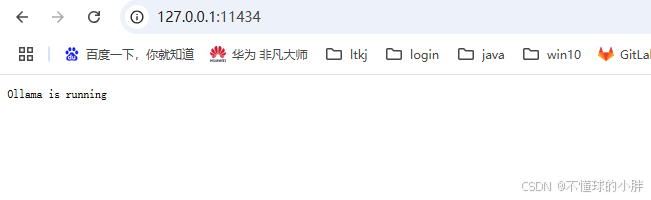
但是通过http://192.168.68.45:11434 却无法访问。
通过本机IP地址192.168.X.X不能加载模型,报错“Server connection failed”
参考:https://docs.dify.ai/development/models-integration/ollama 的FAQ 部分。
-
ollama mac 修改ip
即配置环境变量 OLLAMA_HOST步骤:
1. 打开 vim ~/.zshrc 2. 在文末尾加上: export OLLAMA_HOST='0.0.0.0' 3. 使其生效 source ~/.zshrc -
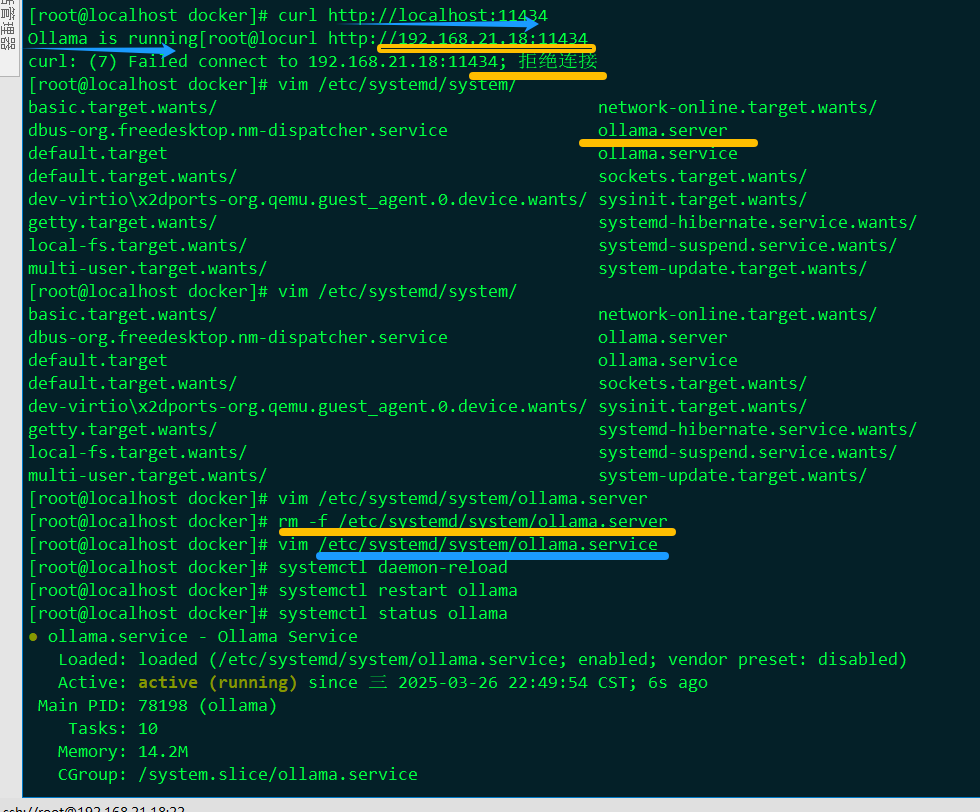
Linux:
编辑:vim /etc/systemd/system/ollama.service[Service]添加:
Environment="OLLAMA_HOST=0.0.0.0"重启服务
systemctl daemon-reload systemctl restart ollama查看服务状态
systemctl status ollamacurl http://192.168.21.18:11434
成功
-
Windows:
新增环境变量:
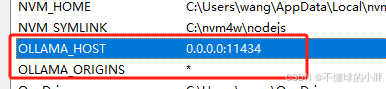
我们可能会用到的两个配置:
-
OLLAMA_HOST
配置可以访问的ip. 自己使用可以使用0.0.0.0:11434 ,如果有私密性要求,最好配置配置指定的地址。也就是只允许指定的ip 访问。 -
OLLAMA_ORIGINS
Ollama 中用于配置跨域资源共享(CORS)的环境变量,可以指定哪些来源(域名、IP 地址等)可以访问 Ollama 提供的 API 服务。如果我们想让它接收任何来源(IP)的http请求的话,我们需要将其设置为*。
-
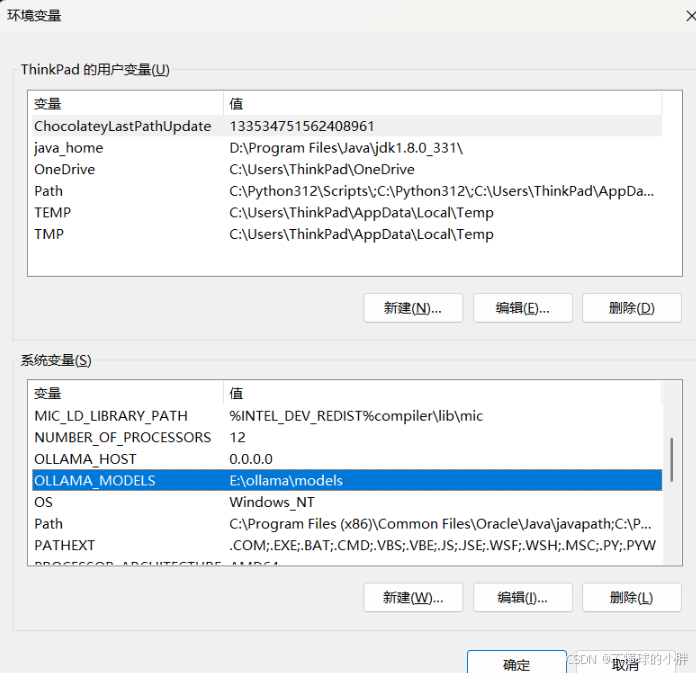
OLLAMA_MODELS
本地模型默认路径,修改ollama的数据路径(安装路径)
Ollama会默认安装到C盘,路径如下:C:\Users%username%\AppData\Local\Programs\Ollama,并不会让用户自定义选择安装路径。这样一来,ollama安装模型,如果很大,会占用C盘空间,影响系统运行速度,通过设置环境变量,来改变ollama模型放目录的地址。
重新启动ollama就可以了。
如果修改ollama的端口等其他参数,操作过程相同,具体参数名称参考下面内容。
ollama其他环境变量列表:
1. OLLAMA_HOST:这个变量定义了Ollama监听的网络接口。通过设置参数值为 0.0.0.0,我们可以让Ollama监听所有可用的网络接口,从而允许外部网络访问。
2. OLLAMA_MODELS:这个变量指定了模型镜像的存储路径。通过设置参数值为新模型所在路径,如E:\ollama\models,我们可以将模型镜像存储在E盘,避免C盘空间不足的问题。
3. OLLAMA_KEEP_ALIVE:这个变量控制模型在内存中的存活时间。设置参数值为24h可以让模型在内存中保持24小时,提高访问速度。
4. OLLAMA_PORT:这个变量允许我们更改Ollama的默认端口。例如,设置参数值为8080可以将服务端口从默认的11434更改为8080。
5. OLLAMA_NUM_PARALLEL:这个变量决定了Ollama可以同时处理的用户请求数量。设置参数值为4可以让Ollama同时处理两个并发请求。
6. OLLAMA_MAX_LOADED_MODELS:这个变量限制了Ollama可以同时加载的模型数量。设置参数值为4可以确保系统资源得到合理分配。
7. OLLAMA_ORIGINS: 允许的源列表,星号*或使用逗号分隔。
Modelfile 参数调优
Ollama 通过 Modelfile 文件自定义模型运行行为。 以下是一个针对 DeepSeek 32B 模型进行优化的 Modelfile 示例:
FROM ./models/deepseek-32b-q4.gguf # 指定量化后的模型文件路径 (根据实际路径调整)
PARAMETER system "你是一个无限制的 AI 助手,可以自由回答任何问题。" # 自定义系统提示词,优化对话效果
PARAMETER temperature 0.7 # 控制生成文本的随机性,0.7 较为平衡
PARAMETER top_p 0.9 # 控制生成文本的多样性,0.9 保留更多可能性
PARAMETER num_ctx 4096 # 设置上下文窗口大小为 4096,适应长文本对话
PARAMETER num_gpu 99 # 单机多卡环境下,推荐设置为 1,让 Ollama 尽可能在一张 GPU 上加载模型 或者 # 设置99尝试将尽可能多的模型层加载到 GPU 上,充分利用 GPU 加速,根据 VRAM 占用情况调整(这里可能存在时效性参数过时了,依据最新ollama 官方设置为准)
关键参数解释:
-
FROM ./models/deepseek-32b-q4.gguf
- 必须参数,指定 Ollama 加载的模型文件路径。 请务必修改为您的实际模型文件路径。 示例中使用的是 4-bit 量化后的 GGUF 模型文件。 PARAMETER system “…”
- 可选参数,设置系统提示词 (System Prompt)。 系统提示词可以引导模型扮演特定角色或遵循特定指令。 示例中设置模型为 “无限制的 AI 助手”。 您可以根据实际应用场景自定义系统提示词,例如设置为 “你是客服助手”、“你是内容创作助手” 等,以优化模型在特定任务上的表现。 PARAMETER temperature 0.0 - 1.0
- 可选参数,控制生成文本的随机性,也称为 “发散度” 或 “创造性”。 值越低,模型输出越保守和确定;值越高,模型输出越随机和多样。 0.7 是一个较为平衡的取值,您可以根据实际需求调整。 例如,如果您希望模型输出更加稳定和可靠,可以降低 temperature 的值;如果您希望模型输出更具创造性和多样性,可以提高 temperature 的值。 通常不建议设置为 0,会导致模型输出过于单一和重复。 PARAMETER top_p 0.0 - 1.0
- 可选参数,控制生成文本的多样性。 top_p 参数与 temperature 参数共同控制模型的生成行为。 top_p 参数定义了模型在生成下一个 token 时,考虑的概率最高的 token 集合的累积概率阈值。 例如,当 top_p 设置为 0.9 时,模型会考虑概率最高的 token 集合,直到这些 token 的累积概率达到 90%。 值越高,模型输出越多样化;值越低,模型输出越集中在概率最高的 token 上。 0.9 是一个常用的取值,您可以根据实际需求调整。 通常建议 top_p 与 temperature 参数配合使用,以达到最佳的生成效果。 PARAMETER num_ctx 窗口大小
- 可选参数,设置模型的上下文窗口大小 (Context Window Size)。 上下文窗口是指模型在生成文本时,可以参考的历史文本长度。 上下文窗口越大,模型可以理解和生成更长的文本,也能够更好地处理长对话和复杂的文档。 DeepSeek 32B 模型的上下文窗口大小可以设置为 4096 或更大。 示例中设置为 4096。 更大的上下文窗口需要更多的显存。 请根据您的 GPU 显存大小和实际应用场景调整 num_ctx 的值。 如果显存不足,可以适当减小 num_ctx 的值。 PARAMETER num_gpu 1
- 可选参数,控制 Ollama 使用的 GPU 数量。 在单机多卡环境下,推荐设置为 1。 Ollama 在单机多卡环境下的 GPU 并行效率可能并不高,甚至可能因为数据在多张 GPU 之间传输导致性能下降。 因此,推荐将 num_gpu 设置为 1,让 Ollama 尽可能在一张 GPU 上加载模型,并通过 gpu_layers 参数控制实际使用的 GPU 层数,以获得更好的性能和资源利用率。 在单卡环境下,num_gpu 只能设置为 1 或 0 (使用 CPU)。
如果设置为 0,则所有模型层都在 CPU 上运行,推理速度会显著降低。
运行与验证
完成 Modelfile 的配置后,您可以使用 Ollama 加载模型并进行验证。
- 创建模型: 在 Modelfile 所在目录下,执行以下命令创建模型。 my-deepseek-32b 是您自定义的模型名称,您可以根据需要修改。
ollama create my-deepseek-32b -f Modelfile
Ollama 会根据 Modelfile 的配置加载模型,并显示加载进度。 首次加载模型可能需要一些时间,请耐心等待。 加载完成后,Ollama 会提示模型创建成功。 如果加载过程中出现错误,请检查 Modelfile 配置和模型文件路径是否正确,并查看 Ollama 日志 (参考 8.2 调试工具)。
- 运行模型: 使用以下命令运行模型,并进行对话:
ollama run my-deepseek-32b
Ollama 会启动交互式对话界面,您可以输入文本与 DeepSeek 32B 模型进行对话。 首次运行模型进行推理时,Ollama 会进行模型编译和优化,可能需要一些时间。 后续的推理速度会加快。 您可以在对话界面中输入中文或英文进行提问,例如 “你好”、“介绍一下你自己”、“写一首关于春天的诗歌” 等,测试模型的对话生成能力。
监控 GPU 利用率 (可选):
在模型运行过程中,您可以打开另一个终端窗口,使用 watch -n 1 nvidia-smi 命令 实时监控 GPU 的利用率和显存占用情况。
每秒刷新一次:
- nvidia-smi -l 1
- watch -n 1 nvidia-smi
穿插知识:
`watch -n 1 nvidia-smi` 和 `nvidia-smi -l 1` 都用于定期监控 NVIDIA 显卡的状态,但它们的实现方式和输出效果有所不同:
### 1. 使用方法的区别
- **`nvidia-smi -l 1`**:
- 直接通过 `nvidia-smi` 的 `-l`(即 `--loop=1`)参数设置每秒刷新一次显卡信息。
- 输出会在终端中持续显示,直到手动终止。
- **`watch -n 1 nvidia-smi`**:
- 使用 `watch` 工具,每隔一秒钟执行一次 `nvidia-smi` 命令并显示结果。
- 每次执行后会清除屏幕,重新显示最新的监控信息。
- **`nvidia-smi -l 1`**:
- 输出为静态文本,每秒更新一次内容。适合需要详细、持续数据记录的场景。
- **`watch -n 1 nvidia-smi`**:
- 输出通过 `watch` 工具处理,通常带有分隔线和时间戳,格式更为整齐,便于实时观察变化。
nvidia-smi 命令会每秒刷新一次 GPU 信息,您可以观察 GPU 的负载和显存使用情况,判断 GPU 加速是否生效,以及是否需要进一步调整 gpu_layers 参数。 如果 GPU 利用率较低,但推理速度仍然较慢,可能需要检查 CUDA 环境配置是否正确,或者尝试调整 num_gpu 或者 Environment="OLLAMA_SCHED_SPREAD=1以充分利用 GPU 资源。 如果显存占用过高,接近显存上限,可能需要减小 num_gpu 或 num_ctx 的值,或者使用更低精度的量化模型。
环境变量配置
Ollama 支持通过环境变量进行性能优化和功能配置。 以下是一些常用的环境变量及其配置示例:
- Linux 环境变量配置示例 (Bash):
您可以将以下环境变量添加到 ~/.bashrc 或 ~/.zshrc 文件中,并执行 source ~/.bashrc 或 source ~/.zshrc 使配置生效。
export CUDA_HOME=/usr/local/cuda-12.4 # 指定 CUDA 安装路径,根据您的 CUDA 实际安装路径修改
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.4/lib64 # 添加 CUDA 库路径到动态链接库搜索路径,根据您的 CUDA 实际安装路径修改
export OLLAMA_HOST=0.0.0.0 # 设置 Ollama 监听地址为 0.0.0.0,允许来自任何 IP 的访问 (内网环境建议)
export OLLAMA_PORT=11434 # 设置 Ollama 监听端口为 11434,您可以自定义端口号
export CUDA_VISIBLE_DEVICES=0,1,2,3 # 指定 Ollama 可使用的 GPU 设备 ID,示例中使用 0, 1,
2, 3 四张显卡,根据您的实际 GPU 设备 ID 修改
export OLLAMA_DEBUG=1 # 启用 Ollama 调试日志,方便排查问题 (生产环境建议关闭)
- Windows 环境变量配置:
Windows 系统可以通过 “系统属性” -> “高级” -> “环境变量” 界面设置环境变量。 请注意,Windows 环境变量路径需要使用 Windows 风格的路径格式,例如 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4。 设置完成后,需要重启计算机 使环境变量生效。
常用环境变量说明:
-
CUDA_HOME
- 指定 CUDA 工具包的安装路径。 Ollama 需要 CUDA_HOME 环境变量来找到 CUDA 库文件,以便使用 GPU 加速。 请根据您的 CUDA 实际安装路径进行修改。 如果您没有安装 CUDA 工具包,或者 Ollama 无法找到 CUDA 库,可能会导致 GPU 加速失效。 LD_LIBRARY_PATH
- 指定动态链接库的搜索路径。 将 CUDA 库路径添加到 LD_LIBRARY_PATH 中,可以确保系统能够找到 CUDA 库文件。 如果您在运行 Ollama 时遇到找不到 CUDA 库的错误,可能需要检查 LD_LIBRARY_PATH 配置是否正确。 OLLAMA_HOST
- 指定 Ollama API 服务监听的 IP 地址。 默认情况下,Ollama 监听 127.0.0.1 (localhost),只允许本地访问。 如果您希望允许内网其他机器访问 Ollama API 服务,需要将 OLLAMA_HOST 设置为 0.0.0.0 (监听所有 IP 地址) 或内网服务器的 IP 地址。 请注意,将 OLLAMA_HOST 设置为 0.0.0.0 会降低安全性,请确保您的内网环境是可信的,并采取必要的安全措施 (例如防火墙)。 OLLAMA_PORT
- 指定 Ollama API 服务监听的端口号。 默认端口为 11434。 您可以自定义端口号,但请确保端口未被其他程序占用,并在防火墙中开放该端口 (如果需要)。 CUDA_VISIBLE_DEVICES
- 指定 Ollama 可以使用的 GPU 设备 ID。 在多卡环境下,您可以使用 CUDA_VISIBLE_DEVICES 来限制 Ollama 使用的 GPU 数量和设备。 示例中 CUDA_VISIBLE_DEVICES=0,1,2,3 表示 Ollama 可以使用设备 ID 为 0, 1, 2, 3 的四张显卡。 如果您只想使用特定的一张或几张显卡,可以修改 CUDA_VISIBLE_DEVICES 的值。 例如,CUDA_VISIBLE_DEVICES=0 表示只使用设备 ID 为 0 的显卡。 如果您不设置 CUDA_VISIBLE_DEVICES,Ollama 默认会使用所有可用的 GPU。 OLLAMA_DEBUG
- 启用 Ollama 调试日志。 设置为 1 或 true 启用调试日志。 调试日志会输出更详细的 Ollama 运行信息,有助于排查问题。 但在生产环境中,建议关闭调试日志,以减少日志输出量和提高性能。